Rilevamento dei volti, attributi e dati di input
Attenzione
L'accesso al servizio Viso è limitato in base ai criteri di idoneità e utilizzo al fine di supportare i nostri principi di intelligenza artificiale responsabile. Il servizio Viso è disponibile solo per i clienti e i partner gestiti da Microsoft. Usare il modulo di acquisizione riconoscimento volto per richiedere l'accesso. Per altre informazioni, vedere la pagina Accesso limitato dalla funzione Viso.
Importante
Gli attributi relativi al viso vengono stimati tramite l'uso di algoritmi statistici. Potrebbero non essere sempre accurati. Prestare attenzione quando si effettuano decisioni basate sui dati degli attributi. Evitare di usare questi attributi per le operazioni anti-spoofing. È invece consigliabile usare il rilevamento della mimica facciale. Per altre informazioni, vedere Esercitazione: Rilevare la mimica facciale.
Questo articolo descrive i concetti associati ai dati relativi al rilevamento dei volti e all'attributo viso. Il rilevamento dei volti è il processo di individuazione dei visi umani in un'immagine e, facoltativamente, la restituzione di diversi tipi di dati correlati al viso.
Usare l'API Rileva per rilevare i visi in un'immagine. Per iniziare a usare l'API REST o un SDK client, seguire una guida introduttiva al servizio Viso. In alternativa, per una guida più approfondita, vedere Chiamare l'API di rilevamento.
Rettangolo del viso
Ogni viso rilevato corrisponde a un campo faceRectangle nella risposta. Si tratta di un set di coordinate pixel per lato sinistro, lato superiore, larghezza e altezza del viso rilevato. Usando queste coordinate, è possibile ottenere la posizione e le dimensioni del viso. Nella risposta API i visi sono elencati in ordine di dimensioni, dal più grande al più piccolo.
Provare le funzionalità di rilevamento dei volti in modo rapido e semplice usando Azure AI Vision Studio.
ID viso
L'ID viso è una stringa di identificatore univoco per ogni viso rilevato in un'immagine. L'ID viso richiede un'approvazione con accesso limitato, che è possibile richiedere compilando il modulo di acquisizione. Per altre informazioni, vedere la pagina Accesso limitato all'API Viso. È possibile richiedere un ID viso nella chiamata API Rileva.
Punti di riferimento del viso
I punti di riferimento del viso sono una serie di punti facili da trovare su un volto, come le pupille o la punta del naso. Per impostazione predefinita, esistono 27 punti di riferimento predefiniti. La figura seguente mostra tutti i 27 punti:
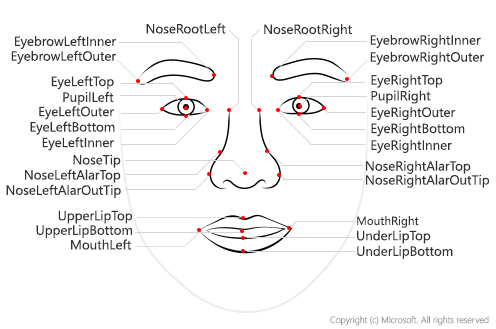
Le coordinate dei punti vengono restituite in unità di pixel.
Attualmente il modello Detection_03 ha il rilevamento dei punti di riferimento più accurato. I punti di riferimento degli occhi e della pupilla restituiti sono abbastanza precisi per consentire il tracciamento dello sguardo fisso del viso.
Attributi
Attenzione
Microsoft ha ritirato o limitato le funzionalità di riconoscimento facciale che possono essere usate per cercare di estrapolare gli stati emotivi e gli attributi dell'identità che, se usati in modo improprio, potrebbero comportare per le persone generalizzazioni, discriminazione o negazione ingiusta di servizi. Le capacità ritirata sono emozioni e sesso. Le funzionalità limitate sono età, sorriso, peli del viso, capelli e trucco. Inviare un messaggio di posta elettronica al team di Viso di Azure se si ha un caso d'uso responsabile che trarrà vantaggio dall'uso di una delle funzionalità limitate. Altre informazioni su questa decisione sono disponibili qui.
Gli attributi sono un set di funzionalità che possono facoltativamente essere rilevate dall'API Rileva. È possibile rilevare gli attributi seguenti:
Accessori: indica se il viso specificato ha accessori. Questo attributo restituisce i possibili accessori, tra cui capo, occhiali e maschera, con un punteggio di confidenza compreso tra zero e uno per ogni accessorio.
Sfocatura: indica la sfocatura del viso nell'immagine. Questo attributo restituisce un valore compreso tra zero e uno e una classificazione informale per sfocatura bassa, media o alta.
Esposizione: indica l'esposizione del viso nell'immagine. Questo attributo restituisce un valore compreso tra zero e uno e una classificazione informale di underExposure, goodExposure o overExposure.
Occhiali: indica se il viso specificato ha occhiali. I valori possibili sono NoGlasses, ReadingGlasses, Occhiali da sole e Occhiali da bagno.
Posizione della testa: indica l'orientamento del viso nello spazio 3D. Questo attributo è definito dagli angoli di rotazione intorno all'asse Z (rollio), rotazione intorno all'asse Y(imbardata) e rotazione intorno all'asse X (beccheggio) in gradi, definiti in base alla regola della mano destra. L'ordine di tre angoli è roll-yaw-pitch e l'intervallo di valori di ogni angolo è compreso tra -180 gradi e +180 gradi. L'orientamento 3D del viso viene stimato in base agli angoli di rotazione intorno all'asse Z, all'asse Y e all'asse X, in questo ordine. Per i mapping degli angoli, vedere il diagramma seguente:
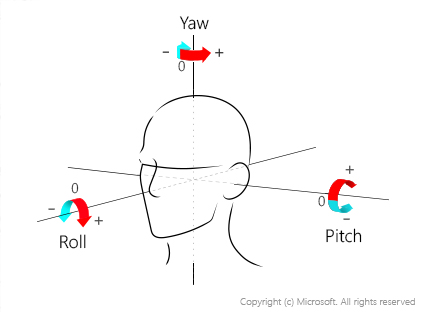
Per altre informazioni su come usare questi valori, vedere Usare l'attributo HeadPose.
Maschera: indica se il viso indossa una maschera. Questo attributo restituisce un possibile tipo di maschera e un valore booleano per indicare se il naso e la bocca sono coperti.
Rumore: indica il rumore visivo rilevato nell'immagine del viso. Questo attributo restituisce un valore compreso tra zero e uno e una classificazione informale di bassa, media o alta.
Occlusione: indica se sono presenti oggetti che bloccano parti del viso. Questo attributo restituisce un valore booleano per eyeOccluded, foreheadOccluded e mouthOccluded.
QualityForRecognition: indica la qualità complessiva dell'immagine per determinare se l'immagine utilizzata nel rilevamento è di qualità sufficiente per tentare il riconoscimento del viso. Il valore è una classificazione informale per qualità bassa, media o alta. Per gli scenari di identificazione è consigliabile usare solo immagini di alta qualità per la registrazione delle persone e qualità superiore o superiore a quella media .
Nota
La disponibilità di ogni attributo dipende dal modello di rilevamento specificato. L'attributo QualityForRecognition dipende anche dal modello di riconoscimento, poiché è attualmente disponibile solo quando si usa una combinazione di modelli di rilevamento detection_01 o detection_03 e il modello di riconoscimento recognition_03 o recognition_04.
Requisiti di input
Usare i suggerimenti seguenti per assicurarsi che le immagini di input restituiscano i risultati di rilevamento più accurati:
- I formati di immagine di input supportati sono JPEG, PNG, GIF (il primo frame), BMP.
- La dimensione del file di immagine selezionato deve essere minore di 6 MB.
- La dimensione minima del viso rilevabile è pari a 36 x 36 pixel per un'immagine non superiore a 1920 x 1080 pixel. Le immagini con dimensioni superiori a 1920 x 1080 pixel hanno dimensioni minime proporzionalmente maggiori. La riduzione delle dimensioni del viso potrebbe causare il mancato rilevamento di alcuni visi, anche se questi hanno dimensioni maggiori di quelle minime rilevabili.
- La dimensione massima del viso rilevabile è 4096 x 4096 pixel.
- I visi non compresi nell'intervallo di dimensioni da 36 x 36 a 4096 x 4096 pixel non verranno rilevati.
Dati di input con informazioni sull'orientamento
Alcune immagini di input con formato JPEG possono contenere informazioni sull'orientamento nei metadati EXIF (Exchangeable Image File Format). Se l'orientamento EXIF è disponibile, le immagini vengono ruotate automaticamente in base all'orientamento corretto prima dell'invio per il rilevamento volto. Il rettangolo del viso, i punti di riferimento e la posizione della testa per ogni viso rilevato vengono stimati in base all'immagine ruotata.
Per visualizzare correttamente il rettangolo del viso e i punti di riferimento, è necessario assicurarsi che l'immagine sia ruotata correttamente. La maggior parte degli strumenti di visualizzazione delle immagini ruota automaticamente l'immagine in base al relativo orientamento EXIF per impostazione predefinita. Per gli altri strumenti, potrebbe essere necessario applicare la rotazione usando codice personalizzato. Gli esempi seguenti mostrano un rettangolo del viso su un'immagine ruotata (sinistra) e un'immagine non ruotata (a destra).

Input video
Se stai rilevando i visi da un feed video, potresti essere in grado di migliorare le prestazioni modificando determinate impostazioni nella videocamera:
Smussamento: molte videocamere applicano un effetto di smussamento. Se possibile, è consigliabile disattivare questa opzione perché crea una sfocatura tra fotogrammi e riduce la chiarezza.
Velocità otturatore: una velocità di otturatore più veloce riduce la quantità di movimento tra fotogrammi e rende più chiaro ogni fotogramma. È consigliabile usare velocità dell'otturatore pari a 1/60 secondi o superiore.
Angolo di otturatore: alcune fotocamere specificano l'angolo di otturatore anziché la velocità dell'otturatore. È consigliabile usare un angolo di otturatore inferiore, se possibile, che comporta fotogrammi video più chiari.
Nota
Un sensore fotocamera con un angolo di otturatore inferiore riceve meno luce in ogni fotogramma, quindi l'immagine è più scura. È necessario determinare il livello corretto da usare.
Passaggio successivo
Dopo aver familiarizzato con i concetti di rilevamento dei volti, è necessario scoprire come scrivere uno script che rileva i visi in una determinata immagine.