Come generare completamenti della chat con l'inferenza del modello di intelligenza artificiale di Azure
Importante
Gli elementi contrassegnati (anteprima) in questo articolo sono attualmente disponibili in anteprima pubblica. Questa anteprima viene fornita senza un contratto di servizio e non è consigliabile per i carichi di lavoro di produzione. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate. Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
Questo articolo illustra come usare l'API di completamento della chat con i modelli distribuiti nell'inferenza del modello di intelligenza artificiale di Azure nei servizi di intelligenza artificiale di Azure.
Prerequisiti
Per usare i modelli di completamento della chat nell'applicazione, è necessario:
Una sottoscrizione di Azure. Se si usano i modelli GitHub, è possibile aggiornare l'esperienza e creare una sottoscrizione di Azure nel processo. Leggere Eseguire l'aggiornamento dai modelli GitHub all'inferenza del modello di intelligenza artificiale di Azure, se questo è il caso.
Una risorsa dei servizi di intelligenza artificiale di Azure. Per altre informazioni, vedere Creare una risorsa di Servizi di intelligenza artificiale di Azure.
URL e chiave dell'endpoint.

Distribuzione del modello di completamento della chat. Se non si ha una sola lettura Aggiungere e configurare modelli per i servizi di intelligenza artificiale di Azure per aggiungere un modello di completamento della chat alla risorsa.
Installare il pacchetto di inferenza di Intelligenza artificiale di Azure con il comando seguente:
pip install -U azure-ai-inferenceSuggerimento
Altre informazioni sul pacchetto di inferenza di Intelligenza artificiale di Azure.
Usare i completamenti della chat
Creare prima di tutto il client per utilizzare il modello. Il codice seguente usa un URL dell'endpoint e una chiave archiviati nelle variabili di ambiente.
import os
from azure.ai.inference import ChatCompletionsClient
from azure.core.credentials import AzureKeyCredential
client = ChatCompletionsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=AzureKeyCredential(os.environ["AZURE_INFERENCE_CREDENTIAL"]),
model="mistral-large-2407"
)
Se la risorsa è stata configurata con il supporto microsoft Entra ID , è possibile usare il frammento di codice seguente per creare un client.
import os
from azure.ai.inference import ChatCompletionsClient
from azure.identity import DefaultAzureCredential
client = ChatCompletionsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredential(),
model="mistral-large-2407"
)
Creare una richiesta di completamento della chat
L'esempio seguente illustra come creare una richiesta di completamento della chat di base per il modello.
from azure.ai.inference.models import SystemMessage, UserMessage
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
)
Nota
Alcuni modelli non supportano i messaggi di sistema (role="system"). Quando si usa l'API di inferenza del modello di Azure per intelligenza artificiale, i messaggi di sistema vengono convertiti in messaggi utente, cioè la funzionalità più vicina disponibile. Questa traduzione è disponibile per praticità; tuttavia, è importante verificare che il modello stia seguendo le istruzioni nel messaggio di sistema con il livello di attendibilità corretto.
La risposta è la seguente, in cui è possibile visualizzare le statistiche di utilizzo del modello:
print("Response:", response.choices[0].message.content)
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
Prendere in esame la sezione usage nella risposta per visualizzare il numero di token usati per il prompt, il numero totale di token generati e il numero di token usati per il completamento.
Streaming dei contenuti
Per impostazione predefinita, l'API di completamento restituisce l'intero contenuto generato in una singola risposta. Se si generano completamenti lunghi, l'attesa della risposta può impiegare diversi secondi.
È possibile trasmettere in streaming i contenuti per ottenerli mentre sono generati. Lo streaming dei contenuti consente di avviare l'elaborazione del completamento man mano che i contenuti diventano disponibili. Questa modalità restituisce un oggetto che ritrasmette la risposta come eventi inviati dal server solo dati. Estrarre blocchi dal campo delta, anziché dal campo del messaggio.
Per trasmettere i completamenti, impostare stream=True quando si chiama il modello.
result = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
temperature=0,
top_p=1,
max_tokens=2048,
stream=True,
)
Per visualizzare l'output, definire una funzione helper per stampare il flusso.
def print_stream(result):
"""
Prints the chat completion with streaming.
"""
import time
for update in result:
if update.choices:
print(update.choices[0].delta.content, end="")
È possibile visualizzare il modo in cui lo streaming genera contenuti:
print_stream(result)
Esplorare altri parametri supportati dal client di inferenza
Esplorare altri parametri che è possibile specificare nel client di inferenza. Per un elenco completo di tutti i parametri supportati e della relativa documentazione corrispondente, vedere Informazioni di riferimento sull'API di inferenza del modello di Azure per intelligenza artificiale.
from azure.ai.inference.models import ChatCompletionsResponseFormatText
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
presence_penalty=0.1,
frequency_penalty=0.8,
max_tokens=2048,
stop=["<|endoftext|>"],
temperature=0,
top_p=1,
response_format={ "type": ChatCompletionsResponseFormatText() },
)
Alcuni modelli non supportano la formattazione dell'output JSON. È sempre possibile chiedere al modello di generare output JSON. Tuttavia, non è garantito che tali output siano JSON validi.
Se si desidera passare un parametro non incluso nell'elenco dei parametri supportati, è possibile passarlo al modello sottostante usando parametri aggiuntivi. Vedere Passare parametri aggiuntivi al modello.
Creare output JSON
Alcuni modelli possono creare output JSON. Impostare response_format su per json_object abilitare la modalità JSON e garantire che il messaggio generato dal modello sia output JSON valido. È anche necessario indicare al modello di produrre output JSON manualmente tramite un messaggio di sistema o utente. Inoltre, il contenuto del messaggio può essere parzialmente tagliato se finish_reason="length", che indica che la generazione ha superato max_tokens o che la conversazione ha superato la lunghezza massima del contesto.
from azure.ai.inference.models import ChatCompletionsResponseFormatJSON
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant that always generate responses in JSON format, using."
" the following format: { ""answer"": ""response"" }."),
UserMessage(content="How many languages are in the world?"),
],
response_format={ "type": ChatCompletionsResponseFormatJSON() }
)
Passare parametri aggiuntivi al modello
L'API di inferenza del modello di intelligenza artificiale di Azure consente di passare parametri aggiuntivi al modello. Nell'esempio di codice seguente viene illustrato come passare il parametro aggiuntivo logprobs al modello.
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
model_extras={
"logprobs": True
}
)
Prima di passare parametri aggiuntivi all'API di inferenza del modello di intelligenza artificiale di Azure, assicurarsi che il modello supporti tali parametri aggiuntivi. Quando la richiesta viene effettuata al modello sottostante, l'intestazione extra-parameters viene passata al modello con il valore pass-through. Questo valore indica all'endpoint di passare i parametri aggiuntivi al modello. L'uso di parametri aggiuntivi con il modello non garantisce che il suddetto possa gestirli effettivamente. Leggere la documentazione del modello per comprendere quali parametri aggiuntivi sono supportati.
Usare gli strumenti
Alcuni modelli supportano l'uso di strumenti, che possono essere una risorsa straordinaria quando è necessario eseguire l'offload di attività specifiche dal modello linguistico e basarsi invece su un sistema più deterministico o anche su un modello linguistico diverso. L'API di inferenza del modello di intelligenza artificiale di Azure consente di definire gli strumenti nel modo seguente.
L'esempio di codice seguente crea una definizione dello strumento in grado di esaminare le informazioni sui voli da due città diverse.
from azure.ai.inference.models import FunctionDefinition, ChatCompletionsFunctionToolDefinition
flight_info = ChatCompletionsFunctionToolDefinition(
function=FunctionDefinition(
name="get_flight_info",
description="Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
parameters={
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates",
},
"destination_city": {
"type": "string",
"description": "The flight destination city",
},
},
"required": ["origin_city", "destination_city"],
},
)
)
tools = [flight_info]
In questo esempio, l'output della funzione è che non sono disponibili voli per il percorso selezionato e l'utente deve prendere in considerazione di prendere un treno.
def get_flight_info(loc_origin: str, loc_destination: str):
return {
"info": f"There are no flights available from {loc_origin} to {loc_destination}. You should take a train, specially if it helps to reduce CO2 emissions."
}
Nota
I modelli Cohere richiedono che le risposte di uno strumento siano un contenuto JSON valido formattato come stringa. Quando si creano messaggi di tipo Tool, assicurarsi che la risposta sia una stringa JSON valida.
Richiedere al modello di prenotare i voli con l'aiuto di questa funzione:
messages = [
SystemMessage(
content="You are a helpful assistant that help users to find information about traveling, how to get"
" to places and the different transportations options. You care about the environment and you"
" always have that in mind when answering inqueries.",
),
UserMessage(
content="When is the next flight from Miami to Seattle?",
),
]
response = client.complete(
messages=messages, tools=tools, tool_choice="auto"
)
È possibile esaminare la risposta per verificare se è necessario chiamare uno strumento. Esaminare il motivo di fine per determinare se è necessario chiamare lo strumento. Tenere presente che è possibile indicare più tipi di strumenti. In questo esempio viene illustrato uno strumento di tipo function.
response_message = response.choices[0].message
tool_calls = response_message.tool_calls
print("Finish reason:", response.choices[0].finish_reason)
print("Tool call:", tool_calls)
Per continuare, aggiungere questo messaggio alla cronologia delle chat:
messages.append(
response_message
)
A questo punto, è possibile chiamare la funzione appropriata per gestire la chiamata allo strumento. Il frammento di codice seguente esegue l'iterazione di tutte le chiamate dello strumento indicate nella risposta e chiama la funzione corrispondente con i parametri appropriati. La risposta viene aggiunta anche alla cronologia delle chat.
import json
from azure.ai.inference.models import ToolMessage
for tool_call in tool_calls:
# Get the tool details:
function_name = tool_call.function.name
function_args = json.loads(tool_call.function.arguments.replace("\'", "\""))
tool_call_id = tool_call.id
print(f"Calling function `{function_name}` with arguments {function_args}")
# Call the function defined above using `locals()`, which returns the list of all functions
# available in the scope as a dictionary. Notice that this is just done as a simple way to get
# the function callable from its string name. Then we can call it with the corresponding
# arguments.
callable_func = locals()[function_name]
function_response = callable_func(**function_args)
print("->", function_response)
# Once we have a response from the function and its arguments, we can append a new message to the chat
# history. Notice how we are telling to the model that this chat message came from a tool:
messages.append(
ToolMessage(
tool_call_id=tool_call_id,
content=json.dumps(function_response)
)
)
Visualizzare la risposta dal modello:
response = client.complete(
messages=messages,
tools=tools,
)
Applicare la sicurezza dei contenuti
L'API di inferenza del modello di Azure per intelligenza artificiale supporta Sicurezza dei contenuti di Azure AI. Quando si usano distribuzioni con sicurezza dei contenuti di Azure AI attivata, gli input e gli output passano attraverso un insieme di modelli di classificazione volti a rilevare e impedire l'output di contenuto dannoso. Il sistema di filtro del contenuto rileva e agisce su categorie specifiche di contenuto potenzialmente dannoso sia nelle richieste di input che nei completamenti di output.
Nell'esempio seguente viene illustrato come gestire gli eventi quando il modello rileva contenuti dannosi nella richiesta di input e la sicurezza dei contenuti è abilitata.
from azure.ai.inference.models import AssistantMessage, UserMessage, SystemMessage
try:
response = client.complete(
messages=[
SystemMessage(content="You are an AI assistant that helps people find information."),
UserMessage(content="Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."),
]
)
print(response.choices[0].message.content)
except HttpResponseError as ex:
if ex.status_code == 400:
response = ex.response.json()
if isinstance(response, dict) and "error" in response:
print(f"Your request triggered an {response['error']['code']} error:\n\t {response['error']['message']}")
else:
raise
raise
Suggerimento
Per altre informazioni su come configurare e controllare le impostazioni di sicurezza dei contenuti di Intelligenza artificiale di Azure, vedere la documentazione sulla sicurezza dei contenuti di Intelligenza artificiale di Azure.
Usare i completamenti della chat con immagini
Alcuni modelli possono ragionarsi tra testo e immagini e generare completamenti del testo in base a entrambi i tipi di input. In questa sezione vengono esaminate le funzionalità di Alcuni modelli per la visione in una chat:
Importante
Alcuni modelli supportano solo un'immagine per ogni turno nella conversazione di chat e solo l'ultima immagine viene mantenuta nel contesto. Se si aggiungono più immagini, viene generato un errore.
Per visualizzare questa funzionalità, scaricare un'immagine e codificare le informazioni come stringa base64. I dati risultanti devono trovarsi all'interno di un URL dati:
from urllib.request import urlopen, Request
import base64
image_url = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg"
image_format = "jpeg"
request = Request(image_url, headers={"User-Agent": "Mozilla/5.0"})
image_data = base64.b64encode(urlopen(request).read()).decode("utf-8")
data_url = f"data:image/{image_format};base64,{image_data}"
Visualizzare l'immagine:
import requests
import IPython.display as Disp
Disp.Image(requests.get(image_url).content)

Creare ora una richiesta di completamento della chat con l'immagine:
from azure.ai.inference.models import TextContentItem, ImageContentItem, ImageUrl
response = client.complete(
messages=[
SystemMessage("You are a helpful assistant that can generate responses based on images."),
UserMessage(content=[
TextContentItem(text="Which conclusion can be extracted from the following chart?"),
ImageContentItem(image=ImageUrl(url=data_url))
]),
],
temperature=0,
top_p=1,
max_tokens=2048,
)
La risposta è la seguente, in cui è possibile visualizzare le statistiche di utilizzo del modello:
print(f"{response.choices[0].message.role}:\n\t{response.choices[0].message.content}\n")
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Importante
Gli elementi contrassegnati (anteprima) in questo articolo sono attualmente disponibili in anteprima pubblica. Questa anteprima viene fornita senza un contratto di servizio e non è consigliabile per i carichi di lavoro di produzione. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate. Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
Questo articolo illustra come usare l'API di completamento della chat con i modelli distribuiti nell'inferenza del modello di intelligenza artificiale di Azure nei servizi di intelligenza artificiale di Azure.
Prerequisiti
Per usare i modelli di completamento della chat nell'applicazione, è necessario:
Una sottoscrizione di Azure. Se si usano i modelli GitHub, è possibile aggiornare l'esperienza e creare una sottoscrizione di Azure nel processo. Leggere Eseguire l'aggiornamento dai modelli GitHub all'inferenza del modello di intelligenza artificiale di Azure, se questo è il caso.
Una risorsa dei servizi di intelligenza artificiale di Azure. Per altre informazioni, vedere Creare una risorsa di Servizi di intelligenza artificiale di Azure.
URL e chiave dell'endpoint.
Distribuzione del modello di completamento della chat. Se non si ha una sola lettura Aggiungere e configurare modelli per i servizi di intelligenza artificiale di Azure per aggiungere un modello di completamento della chat alla risorsa.
Installare la libreria di inferenza di Azure per JavaScript con il comando seguente:
npm install @azure-rest/ai-inferenceSuggerimento
Altre informazioni sul pacchetto di inferenza di Intelligenza artificiale di Azure.
Usare i completamenti della chat
Creare prima di tutto il client per utilizzare il modello. Il codice seguente usa un URL dell'endpoint e una chiave archiviati nelle variabili di ambiente.
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { AzureKeyCredential } from "@azure/core-auth";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new AzureKeyCredential(process.env.AZURE_INFERENCE_CREDENTIAL)
);
Se la risorsa è stata configurata con il supporto microsoft Entra ID , è possibile usare il frammento di codice seguente per creare un client.
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { DefaultAzureCredential } from "@azure/identity";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new DefaultAzureCredential()
);
Creare una richiesta di completamento della chat
L'esempio seguente illustra come creare una richiesta di completamento della chat di base per il modello.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
});
Nota
Alcuni modelli non supportano i messaggi di sistema (role="system"). Quando si usa l'API di inferenza del modello di Azure per intelligenza artificiale, i messaggi di sistema vengono convertiti in messaggi utente, cioè la funzionalità più vicina disponibile. Questa traduzione è disponibile per praticità; tuttavia, è importante verificare che il modello stia seguendo le istruzioni nel messaggio di sistema con il livello di attendibilità corretto.
La risposta è la seguente, in cui è possibile visualizzare le statistiche di utilizzo del modello:
if (isUnexpected(response)) {
throw response.body.error;
}
console.log("Response: ", response.body.choices[0].message.content);
console.log("Model: ", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
Prendere in esame la sezione usage nella risposta per visualizzare il numero di token usati per il prompt, il numero totale di token generati e il numero di token usati per il completamento.
Streaming dei contenuti
Per impostazione predefinita, l'API di completamento restituisce l'intero contenuto generato in una singola risposta. Se si generano completamenti lunghi, l'attesa della risposta può impiegare diversi secondi.
È possibile trasmettere in streaming i contenuti per ottenerli mentre sono generati. Lo streaming dei contenuti consente di avviare l'elaborazione del completamento man mano che i contenuti diventano disponibili. Questa modalità restituisce un oggetto che ritrasmette la risposta come eventi inviati dal server solo dati. Estrarre blocchi dal campo delta, anziché dal campo del messaggio.
Per trasmettere i completamenti, usare .asNodeStream() quando si chiama il modello.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
}).asNodeStream();
È possibile visualizzare il modo in cui lo streaming genera contenuti:
var stream = response.body;
if (!stream) {
stream.destroy();
throw new Error(`Failed to get chat completions with status: ${response.status}`);
}
if (response.status !== "200") {
throw new Error(`Failed to get chat completions: ${response.body.error}`);
}
var sses = createSseStream(stream);
for await (const event of sses) {
if (event.data === "[DONE]") {
return;
}
for (const choice of (JSON.parse(event.data)).choices) {
console.log(choice.delta?.content ?? "");
}
}
Esplorare altri parametri supportati dal client di inferenza
Esplorare altri parametri che è possibile specificare nel client di inferenza. Per un elenco completo di tutti i parametri supportati e della relativa documentazione corrispondente, vedere Informazioni di riferimento sull'API di inferenza del modello di Azure per intelligenza artificiale.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
presence_penalty: "0.1",
frequency_penalty: "0.8",
max_tokens: 2048,
stop: ["<|endoftext|>"],
temperature: 0,
top_p: 1,
response_format: { type: "text" },
}
});
Alcuni modelli non supportano la formattazione dell'output JSON. È sempre possibile chiedere al modello di generare output JSON. Tuttavia, non è garantito che tali output siano JSON validi.
Se si desidera passare un parametro non incluso nell'elenco dei parametri supportati, è possibile passarlo al modello sottostante usando parametri aggiuntivi. Vedere Passare parametri aggiuntivi al modello.
Creare output JSON
Alcuni modelli possono creare output JSON. Impostare response_format su per json_object abilitare la modalità JSON e garantire che il messaggio generato dal modello sia output JSON valido. È anche necessario indicare al modello di produrre output JSON manualmente tramite un messaggio di sistema o utente. Inoltre, il contenuto del messaggio può essere parzialmente tagliato se finish_reason="length", che indica che la generazione ha superato max_tokens o che la conversazione ha superato la lunghezza massima del contesto.
var messages = [
{ role: "system", content: "You are a helpful assistant that always generate responses in JSON format, using."
+ " the following format: { \"answer\": \"response\" }." },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
response_format: { type: "json_object" }
}
});
Passare parametri aggiuntivi al modello
L'API di inferenza del modello di intelligenza artificiale di Azure consente di passare parametri aggiuntivi al modello. Nell'esempio di codice seguente viene illustrato come passare il parametro aggiuntivo logprobs al modello.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
headers: {
"extra-params": "pass-through"
},
body: {
messages: messages,
logprobs: true
}
});
Prima di passare parametri aggiuntivi all'API di inferenza del modello di intelligenza artificiale di Azure, assicurarsi che il modello supporti tali parametri aggiuntivi. Quando la richiesta viene effettuata al modello sottostante, l'intestazione extra-parameters viene passata al modello con il valore pass-through. Questo valore indica all'endpoint di passare i parametri aggiuntivi al modello. L'uso di parametri aggiuntivi con il modello non garantisce che il suddetto possa gestirli effettivamente. Leggere la documentazione del modello per comprendere quali parametri aggiuntivi sono supportati.
Usare gli strumenti
Alcuni modelli supportano l'uso di strumenti, che possono essere una risorsa straordinaria quando è necessario eseguire l'offload di attività specifiche dal modello linguistico e basarsi invece su un sistema più deterministico o anche su un modello linguistico diverso. L'API di inferenza del modello di intelligenza artificiale di Azure consente di definire gli strumenti nel modo seguente.
L'esempio di codice seguente crea una definizione dello strumento in grado di esaminare le informazioni sui voli da due città diverse.
const flight_info = {
name: "get_flight_info",
description: "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
parameters: {
type: "object",
properties: {
origin_city: {
type: "string",
description: "The name of the city where the flight originates",
},
destination_city: {
type: "string",
description: "The flight destination city",
},
},
required: ["origin_city", "destination_city"],
},
}
const tools = [
{
type: "function",
function: flight_info,
},
];
In questo esempio, l'output della funzione è che non sono disponibili voli per il percorso selezionato e l'utente deve prendere in considerazione di prendere un treno.
function get_flight_info(loc_origin, loc_destination) {
return {
info: "There are no flights available from " + loc_origin + " to " + loc_destination + ". You should take a train, specially if it helps to reduce CO2 emissions."
}
}
Nota
I modelli Cohere richiedono che le risposte di uno strumento siano un contenuto JSON valido formattato come stringa. Quando si creano messaggi di tipo Tool, assicurarsi che la risposta sia una stringa JSON valida.
Richiedere al modello di prenotare i voli con l'aiuto di questa funzione:
var result = await client.path("/chat/completions").post({
body: {
messages: messages,
tools: tools,
tool_choice: "auto"
}
});
È possibile esaminare la risposta per verificare se è necessario chiamare uno strumento. Esaminare il motivo di fine per determinare se è necessario chiamare lo strumento. Tenere presente che è possibile indicare più tipi di strumenti. In questo esempio viene illustrato uno strumento di tipo function.
const response_message = response.body.choices[0].message;
const tool_calls = response_message.tool_calls;
console.log("Finish reason: " + response.body.choices[0].finish_reason);
console.log("Tool call: " + tool_calls);
Per continuare, aggiungere questo messaggio alla cronologia delle chat:
messages.push(response_message);
A questo punto, è possibile chiamare la funzione appropriata per gestire la chiamata allo strumento. Il frammento di codice seguente esegue l'iterazione di tutte le chiamate dello strumento indicate nella risposta e chiama la funzione corrispondente con i parametri appropriati. La risposta viene aggiunta anche alla cronologia delle chat.
function applyToolCall({ function: call, id }) {
// Get the tool details:
const tool_params = JSON.parse(call.arguments);
console.log("Calling function " + call.name + " with arguments " + tool_params);
// Call the function defined above using `window`, which returns the list of all functions
// available in the scope as a dictionary. Notice that this is just done as a simple way to get
// the function callable from its string name. Then we can call it with the corresponding
// arguments.
const function_response = tool_params.map(window[call.name]);
console.log("-> " + function_response);
return function_response
}
for (const tool_call of tool_calls) {
var tool_response = tool_call.apply(applyToolCall);
messages.push(
{
role: "tool",
tool_call_id: tool_call.id,
content: tool_response
}
);
}
Visualizzare la risposta dal modello:
var result = await client.path("/chat/completions").post({
body: {
messages: messages,
tools: tools,
}
});
Applicare la sicurezza dei contenuti
L'API di inferenza del modello di Azure per intelligenza artificiale supporta Sicurezza dei contenuti di Azure AI. Quando si usano distribuzioni con sicurezza dei contenuti di Azure AI attivata, gli input e gli output passano attraverso un insieme di modelli di classificazione volti a rilevare e impedire l'output di contenuto dannoso. Il sistema di filtro del contenuto rileva e agisce su categorie specifiche di contenuto potenzialmente dannoso sia nelle richieste di input che nei completamenti di output.
Nell'esempio seguente viene illustrato come gestire gli eventi quando il modello rileva contenuti dannosi nella richiesta di input e la sicurezza dei contenuti è abilitata.
try {
var messages = [
{ role: "system", content: "You are an AI assistant that helps people find information." },
{ role: "user", content: "Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills." },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
});
console.log(response.body.choices[0].message.content);
}
catch (error) {
if (error.status_code == 400) {
var response = JSON.parse(error.response._content);
if (response.error) {
console.log(`Your request triggered an ${response.error.code} error:\n\t ${response.error.message}`);
}
else
{
throw error;
}
}
}
Suggerimento
Per altre informazioni su come configurare e controllare le impostazioni di sicurezza dei contenuti di Intelligenza artificiale di Azure, vedere la documentazione sulla sicurezza dei contenuti di Intelligenza artificiale di Azure.
Usare i completamenti della chat con immagini
Alcuni modelli possono ragionarsi tra testo e immagini e generare completamenti del testo in base a entrambi i tipi di input. In questa sezione vengono esaminate le funzionalità di Alcuni modelli per la visione in una chat:
Importante
Alcuni modelli supportano solo un'immagine per ogni turno nella conversazione di chat e solo l'ultima immagine viene mantenuta nel contesto. Se si aggiungono più immagini, viene generato un errore.
Per visualizzare questa funzionalità, scaricare un'immagine e codificare le informazioni come stringa base64. I dati risultanti devono trovarsi all'interno di un URL dati:
const image_url = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg";
const image_format = "jpeg";
const response = await fetch(image_url, { headers: { "User-Agent": "Mozilla/5.0" } });
const image_data = await response.arrayBuffer();
const image_data_base64 = Buffer.from(image_data).toString("base64");
const data_url = `data:image/${image_format};base64,${image_data_base64}`;
Visualizzare l'immagine:
const img = document.createElement("img");
img.src = data_url;
document.body.appendChild(img);
Creare ora una richiesta di completamento della chat con l'immagine:
var messages = [
{ role: "system", content: "You are a helpful assistant that can generate responses based on images." },
{ role: "user", content:
[
{ type: "text", text: "Which conclusion can be extracted from the following chart?" },
{ type: "image_url", image:
{
url: data_url
}
}
]
}
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
temperature: 0,
top_p: 1,
max_tokens: 2048,
}
});
La risposta è la seguente, in cui è possibile visualizzare le statistiche di utilizzo del modello:
console.log(response.body.choices[0].message.role + ": " + response.body.choices[0].message.content);
console.log("Model:", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Importante
Gli elementi contrassegnati (anteprima) in questo articolo sono attualmente disponibili in anteprima pubblica. Questa anteprima viene fornita senza un contratto di servizio e non è consigliabile per i carichi di lavoro di produzione. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate. Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
Questo articolo illustra come usare l'API di completamento della chat con i modelli distribuiti nell'inferenza del modello di intelligenza artificiale di Azure nei servizi di intelligenza artificiale di Azure.
Prerequisiti
Per usare i modelli di completamento della chat nell'applicazione, è necessario:
Una sottoscrizione di Azure. Se si usano i modelli GitHub, è possibile aggiornare l'esperienza e creare una sottoscrizione di Azure nel processo. Leggere Eseguire l'aggiornamento dai modelli GitHub all'inferenza del modello di intelligenza artificiale di Azure, se questo è il caso.
Una risorsa dei servizi di intelligenza artificiale di Azure. Per altre informazioni, vedere Creare una risorsa di Servizi di intelligenza artificiale di Azure.
URL e chiave dell'endpoint.
Distribuzione del modello di completamento della chat. Se non si ha una sola lettura Aggiungere e configurare modelli per i servizi di intelligenza artificiale di Azure per aggiungere un modello di completamento della chat alla risorsa.
Aggiungere il pacchetto di inferenza di Intelligenza artificiale di Azure al progetto:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-ai-inference</artifactId> <version>1.0.0-beta.1</version> </dependency>Suggerimento
Altre informazioni sul pacchetto di inferenza di Intelligenza artificiale di Azure.
Se si usa Entra ID, è necessario anche il pacchetto seguente:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-identity</artifactId> <version>1.13.3</version> </dependency>Importare lo spazio dei nomi seguente:
package com.azure.ai.inference.usage; import com.azure.ai.inference.EmbeddingsClient; import com.azure.ai.inference.EmbeddingsClientBuilder; import com.azure.ai.inference.models.EmbeddingsResult; import com.azure.ai.inference.models.EmbeddingItem; import com.azure.core.credential.AzureKeyCredential; import com.azure.core.util.Configuration; import java.util.ArrayList; import java.util.List;
Usare i completamenti della chat
Creare prima di tutto il client per utilizzare il modello. Il codice seguente usa un URL dell'endpoint e una chiave archiviati nelle variabili di ambiente.
Se la risorsa è stata configurata con il supporto microsoft Entra ID , è possibile usare il frammento di codice seguente per creare un client.
Creare una richiesta di completamento della chat
L'esempio seguente illustra come creare una richiesta di completamento della chat di base per il modello.
Nota
Alcuni modelli non supportano i messaggi di sistema (role="system"). Quando si usa l'API di inferenza del modello di Azure per intelligenza artificiale, i messaggi di sistema vengono convertiti in messaggi utente, cioè la funzionalità più vicina disponibile. Questa traduzione è disponibile per praticità; tuttavia, è importante verificare che il modello stia seguendo le istruzioni nel messaggio di sistema con il livello di attendibilità corretto.
La risposta è la seguente, in cui è possibile visualizzare le statistiche di utilizzo del modello:
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
Prendere in esame la sezione usage nella risposta per visualizzare il numero di token usati per il prompt, il numero totale di token generati e il numero di token usati per il completamento.
Streaming dei contenuti
Per impostazione predefinita, l'API di completamento restituisce l'intero contenuto generato in una singola risposta. Se si generano completamenti lunghi, l'attesa della risposta può impiegare diversi secondi.
È possibile trasmettere in streaming i contenuti per ottenerli mentre sono generati. Lo streaming dei contenuti consente di avviare l'elaborazione del completamento man mano che i contenuti diventano disponibili. Questa modalità restituisce un oggetto che ritrasmette la risposta come eventi inviati dal server solo dati. Estrarre blocchi dal campo delta, anziché dal campo del messaggio.
È possibile visualizzare il modo in cui lo streaming genera contenuti:
Esplorare altri parametri supportati dal client di inferenza
Esplorare altri parametri che è possibile specificare nel client di inferenza. Per un elenco completo di tutti i parametri supportati e della relativa documentazione corrispondente, vedere Informazioni di riferimento sull'API di inferenza del modello di Azure per intelligenza artificiale. Alcuni modelli non supportano la formattazione dell'output JSON. È sempre possibile chiedere al modello di generare output JSON. Tuttavia, non è garantito che tali output siano JSON validi.
Se si desidera passare un parametro non incluso nell'elenco dei parametri supportati, è possibile passarlo al modello sottostante usando parametri aggiuntivi. Vedere Passare parametri aggiuntivi al modello.
Creare output JSON
Alcuni modelli possono creare output JSON. Impostare response_format su per json_object abilitare la modalità JSON e garantire che il messaggio generato dal modello sia output JSON valido. È anche necessario indicare al modello di produrre output JSON manualmente tramite un messaggio di sistema o utente. Inoltre, il contenuto del messaggio può essere parzialmente tagliato se finish_reason="length", che indica che la generazione ha superato max_tokens o che la conversazione ha superato la lunghezza massima del contesto.
Passare parametri aggiuntivi al modello
L'API di inferenza del modello di intelligenza artificiale di Azure consente di passare parametri aggiuntivi al modello. Nell'esempio di codice seguente viene illustrato come passare il parametro aggiuntivo logprobs al modello.
Prima di passare parametri aggiuntivi all'API di inferenza del modello di intelligenza artificiale di Azure, assicurarsi che il modello supporti tali parametri aggiuntivi. Quando la richiesta viene effettuata al modello sottostante, l'intestazione extra-parameters viene passata al modello con il valore pass-through. Questo valore indica all'endpoint di passare i parametri aggiuntivi al modello. L'uso di parametri aggiuntivi con il modello non garantisce che il suddetto possa gestirli effettivamente. Leggere la documentazione del modello per comprendere quali parametri aggiuntivi sono supportati.
Usare gli strumenti
Alcuni modelli supportano l'uso di strumenti, che possono essere una risorsa straordinaria quando è necessario eseguire l'offload di attività specifiche dal modello linguistico e basarsi invece su un sistema più deterministico o anche su un modello linguistico diverso. L'API di inferenza del modello di intelligenza artificiale di Azure consente di definire gli strumenti nel modo seguente.
L'esempio di codice seguente crea una definizione dello strumento in grado di esaminare le informazioni sui voli da due città diverse.
In questo esempio, l'output della funzione è che non sono disponibili voli per il percorso selezionato e l'utente deve prendere in considerazione di prendere un treno.
Nota
I modelli Cohere richiedono che le risposte di uno strumento siano un contenuto JSON valido formattato come stringa. Quando si creano messaggi di tipo Tool, assicurarsi che la risposta sia una stringa JSON valida.
Richiedere al modello di prenotare i voli con l'aiuto di questa funzione:
È possibile esaminare la risposta per verificare se è necessario chiamare uno strumento. Esaminare il motivo di fine per determinare se è necessario chiamare lo strumento. Tenere presente che è possibile indicare più tipi di strumenti. In questo esempio viene illustrato uno strumento di tipo function.
Per continuare, aggiungere questo messaggio alla cronologia delle chat:
A questo punto, è possibile chiamare la funzione appropriata per gestire la chiamata allo strumento. Il frammento di codice seguente esegue l'iterazione di tutte le chiamate dello strumento indicate nella risposta e chiama la funzione corrispondente con i parametri appropriati. La risposta viene aggiunta anche alla cronologia delle chat.
Visualizzare la risposta dal modello:
Applicare la sicurezza dei contenuti
L'API di inferenza del modello di Azure per intelligenza artificiale supporta Sicurezza dei contenuti di Azure AI. Quando si usano distribuzioni con sicurezza dei contenuti di Azure AI attivata, gli input e gli output passano attraverso un insieme di modelli di classificazione volti a rilevare e impedire l'output di contenuto dannoso. Il sistema di filtro del contenuto rileva e agisce su categorie specifiche di contenuto potenzialmente dannoso sia nelle richieste di input che nei completamenti di output.
Nell'esempio seguente viene illustrato come gestire gli eventi quando il modello rileva contenuti dannosi nella richiesta di input e la sicurezza dei contenuti è abilitata.
Suggerimento
Per altre informazioni su come configurare e controllare le impostazioni di sicurezza dei contenuti di Intelligenza artificiale di Azure, vedere la documentazione sulla sicurezza dei contenuti di Intelligenza artificiale di Azure.
Usare i completamenti della chat con immagini
Alcuni modelli possono ragionarsi tra testo e immagini e generare completamenti del testo in base a entrambi i tipi di input. In questa sezione vengono esaminate le funzionalità di Alcuni modelli per la visione in una chat:
Importante
Alcuni modelli supportano solo un'immagine per ogni turno nella conversazione di chat e solo l'ultima immagine viene mantenuta nel contesto. Se si aggiungono più immagini, viene generato un errore.
Per visualizzare questa funzionalità, scaricare un'immagine e codificare le informazioni come stringa base64. I dati risultanti devono trovarsi all'interno di un URL dati:
Visualizzare l'immagine:
Creare ora una richiesta di completamento della chat con l'immagine:
La risposta è la seguente, in cui è possibile visualizzare le statistiche di utilizzo del modello:
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Importante
Gli elementi contrassegnati (anteprima) in questo articolo sono attualmente disponibili in anteprima pubblica. Questa anteprima viene fornita senza un contratto di servizio e non è consigliabile per i carichi di lavoro di produzione. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate. Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
Questo articolo illustra come usare l'API di completamento della chat con i modelli distribuiti nell'inferenza del modello di intelligenza artificiale di Azure nei servizi di intelligenza artificiale di Azure.
Prerequisiti
Per usare i modelli di completamento della chat nell'applicazione, è necessario:
Una sottoscrizione di Azure. Se si usano i modelli GitHub, è possibile aggiornare l'esperienza e creare una sottoscrizione di Azure nel processo. Leggere Eseguire l'aggiornamento dai modelli GitHub all'inferenza del modello di intelligenza artificiale di Azure, se questo è il caso.
Una risorsa dei servizi di intelligenza artificiale di Azure. Per altre informazioni, vedere Creare una risorsa di Servizi di intelligenza artificiale di Azure.
URL e chiave dell'endpoint.
Distribuzione del modello di completamento della chat. Se non si ha una sola lettura Aggiungere e configurare modelli per i servizi di intelligenza artificiale di Azure per aggiungere un modello di completamento della chat alla risorsa.
Installare il pacchetto di inferenza di Intelligenza artificiale di Azure con il comando seguente:
dotnet add package Azure.AI.Inference --prereleaseSuggerimento
Altre informazioni sul pacchetto di inferenza di Intelligenza artificiale di Azure.
Se si usa Entra ID, è necessario anche il pacchetto seguente:
dotnet add package Azure.Identity
Usare i completamenti della chat
Creare prima di tutto il client per utilizzare il modello. Il codice seguente usa un URL dell'endpoint e una chiave archiviati nelle variabili di ambiente.
ChatCompletionsClient client = new ChatCompletionsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new AzureKeyCredential(Environment.GetEnvironmentVariable("AZURE_INFERENCE_CREDENTIAL")),
"mistral-large-2407"
);
Se la risorsa è stata configurata con il supporto microsoft Entra ID , è possibile usare il frammento di codice seguente per creare un client.
client = new ChatCompletionsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new DefaultAzureCredential(includeInteractiveCredentials: true),
"mistral-large-2407"
);
Creare una richiesta di completamento della chat
L'esempio seguente illustra come creare una richiesta di completamento della chat di base per il modello.
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
};
Response<ChatCompletions> response = client.Complete(requestOptions);
Nota
Alcuni modelli non supportano i messaggi di sistema (role="system"). Quando si usa l'API di inferenza del modello di Azure per intelligenza artificiale, i messaggi di sistema vengono convertiti in messaggi utente, cioè la funzionalità più vicina disponibile. Questa traduzione è disponibile per praticità; tuttavia, è importante verificare che il modello stia seguendo le istruzioni nel messaggio di sistema con il livello di attendibilità corretto.
La risposta è la seguente, in cui è possibile visualizzare le statistiche di utilizzo del modello:
Console.WriteLine($"Response: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
Prendere in esame la sezione usage nella risposta per visualizzare il numero di token usati per il prompt, il numero totale di token generati e il numero di token usati per il completamento.
Streaming dei contenuti
Per impostazione predefinita, l'API di completamento restituisce l'intero contenuto generato in una singola risposta. Se si generano completamenti lunghi, l'attesa della risposta può impiegare diversi secondi.
È possibile trasmettere in streaming i contenuti per ottenerli mentre sono generati. Lo streaming dei contenuti consente di avviare l'elaborazione del completamento man mano che i contenuti diventano disponibili. Questa modalità restituisce un oggetto che ritrasmette la risposta come eventi inviati dal server solo dati. Estrarre blocchi dal campo delta, anziché dal campo del messaggio.
Per trasmettere i completamenti, usare il metodo CompleteStreamingAsync quando si chiama il modello. Si noti che in questo esempio la chiamata viene sottoposta a wrapping in un metodo asincrono.
static async Task StreamMessageAsync(ChatCompletionsClient client)
{
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world? Write an essay about it.")
},
MaxTokens=4096
};
StreamingResponse<StreamingChatCompletionsUpdate> streamResponse = await client.CompleteStreamingAsync(requestOptions);
await PrintStream(streamResponse);
}
Per visualizzare l'output, definire un metodo asincrono per stampare il flusso nella console.
static async Task PrintStream(StreamingResponse<StreamingChatCompletionsUpdate> response)
{
await foreach (StreamingChatCompletionsUpdate chatUpdate in response)
{
if (chatUpdate.Role.HasValue)
{
Console.Write($"{chatUpdate.Role.Value.ToString().ToUpperInvariant()}: ");
}
if (!string.IsNullOrEmpty(chatUpdate.ContentUpdate))
{
Console.Write(chatUpdate.ContentUpdate);
}
}
}
È possibile visualizzare il modo in cui lo streaming genera contenuti:
StreamMessageAsync(client).GetAwaiter().GetResult();
Esplorare altri parametri supportati dal client di inferenza
Esplorare altri parametri che è possibile specificare nel client di inferenza. Per un elenco completo di tutti i parametri supportati e della relativa documentazione corrispondente, vedere Informazioni di riferimento sull'API di inferenza del modello di Azure per intelligenza artificiale.
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
PresencePenalty = 0.1f,
FrequencyPenalty = 0.8f,
MaxTokens = 2048,
StopSequences = { "<|endoftext|>" },
Temperature = 0,
NucleusSamplingFactor = 1,
ResponseFormat = new ChatCompletionsResponseFormatText()
};
response = client.Complete(requestOptions);
Console.WriteLine($"Response: {response.Value.Content}");
Alcuni modelli non supportano la formattazione dell'output JSON. È sempre possibile chiedere al modello di generare output JSON. Tuttavia, non è garantito che tali output siano JSON validi.
Se si desidera passare un parametro non incluso nell'elenco dei parametri supportati, è possibile passarlo al modello sottostante usando parametri aggiuntivi. Vedere Passare parametri aggiuntivi al modello.
Creare output JSON
Alcuni modelli possono creare output JSON. Impostare response_format su per json_object abilitare la modalità JSON e garantire che il messaggio generato dal modello sia output JSON valido. È anche necessario indicare al modello di produrre output JSON manualmente tramite un messaggio di sistema o utente. Inoltre, il contenuto del messaggio può essere parzialmente tagliato se finish_reason="length", che indica che la generazione ha superato max_tokens o che la conversazione ha superato la lunghezza massima del contesto.
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage(
"You are a helpful assistant that always generate responses in JSON format, " +
"using. the following format: { \"answer\": \"response\" }."
),
new ChatRequestUserMessage(
"How many languages are in the world?"
)
},
ResponseFormat = new ChatCompletionsResponseFormatJSON()
};
response = client.Complete(requestOptions);
Console.WriteLine($"Response: {response.Value.Content}");
Passare parametri aggiuntivi al modello
L'API di inferenza del modello di intelligenza artificiale di Azure consente di passare parametri aggiuntivi al modello. Nell'esempio di codice seguente viene illustrato come passare il parametro aggiuntivo logprobs al modello.
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
AdditionalProperties = { { "logprobs", BinaryData.FromString("true") } },
};
response = client.Complete(requestOptions, extraParams: ExtraParameters.PassThrough);
Console.WriteLine($"Response: {response.Value.Content}");
Prima di passare parametri aggiuntivi all'API di inferenza del modello di intelligenza artificiale di Azure, assicurarsi che il modello supporti tali parametri aggiuntivi. Quando la richiesta viene effettuata al modello sottostante, l'intestazione extra-parameters viene passata al modello con il valore pass-through. Questo valore indica all'endpoint di passare i parametri aggiuntivi al modello. L'uso di parametri aggiuntivi con il modello non garantisce che il suddetto possa gestirli effettivamente. Leggere la documentazione del modello per comprendere quali parametri aggiuntivi sono supportati.
Usare gli strumenti
Alcuni modelli supportano l'uso di strumenti, che possono essere una risorsa straordinaria quando è necessario eseguire l'offload di attività specifiche dal modello linguistico e basarsi invece su un sistema più deterministico o anche su un modello linguistico diverso. L'API di inferenza del modello di intelligenza artificiale di Azure consente di definire gli strumenti nel modo seguente.
L'esempio di codice seguente crea una definizione dello strumento in grado di esaminare le informazioni sui voli da due città diverse.
FunctionDefinition flightInfoFunction = new FunctionDefinition("getFlightInfo")
{
Description = "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
Parameters = BinaryData.FromObjectAsJson(new
{
Type = "object",
Properties = new
{
origin_city = new
{
Type = "string",
Description = "The name of the city where the flight originates"
},
destination_city = new
{
Type = "string",
Description = "The flight destination city"
}
}
},
new JsonSerializerOptions() { PropertyNamingPolicy = JsonNamingPolicy.CamelCase }
)
};
ChatCompletionsFunctionToolDefinition getFlightTool = new ChatCompletionsFunctionToolDefinition(flightInfoFunction);
In questo esempio, l'output della funzione è che non sono disponibili voli per il percorso selezionato e l'utente deve prendere in considerazione di prendere un treno.
static string getFlightInfo(string loc_origin, string loc_destination)
{
return JsonSerializer.Serialize(new
{
info = $"There are no flights available from {loc_origin} to {loc_destination}. You " +
"should take a train, specially if it helps to reduce CO2 emissions."
});
}
Nota
I modelli Cohere richiedono che le risposte di uno strumento siano un contenuto JSON valido formattato come stringa. Quando si creano messaggi di tipo Tool, assicurarsi che la risposta sia una stringa JSON valida.
Richiedere al modello di prenotare i voli con l'aiuto di questa funzione:
var chatHistory = new List<ChatRequestMessage>(){
new ChatRequestSystemMessage(
"You are a helpful assistant that help users to find information about traveling, " +
"how to get to places and the different transportations options. You care about the" +
"environment and you always have that in mind when answering inqueries."
),
new ChatRequestUserMessage("When is the next flight from Miami to Seattle?")
};
requestOptions = new ChatCompletionsOptions(chatHistory);
requestOptions.Tools.Add(getFlightTool);
requestOptions.ToolChoice = ChatCompletionsToolChoice.Auto;
response = client.Complete(requestOptions);
È possibile esaminare la risposta per verificare se è necessario chiamare uno strumento. Esaminare il motivo di fine per determinare se è necessario chiamare lo strumento. Tenere presente che è possibile indicare più tipi di strumenti. In questo esempio viene illustrato uno strumento di tipo function.
var responseMessage = response.Value;
var toolsCall = responseMessage.ToolCalls;
Console.WriteLine($"Finish reason: {response.Value.Choices[0].FinishReason}");
Console.WriteLine($"Tool call: {toolsCall[0].Id}");
Per continuare, aggiungere questo messaggio alla cronologia delle chat:
requestOptions.Messages.Add(new ChatRequestAssistantMessage(response.Value));
A questo punto, è possibile chiamare la funzione appropriata per gestire la chiamata allo strumento. Il frammento di codice seguente esegue l'iterazione di tutte le chiamate dello strumento indicate nella risposta e chiama la funzione corrispondente con i parametri appropriati. La risposta viene aggiunta anche alla cronologia delle chat.
foreach (ChatCompletionsToolCall tool in toolsCall)
{
if (tool is ChatCompletionsFunctionToolCall functionTool)
{
// Get the tool details:
string callId = functionTool.Id;
string toolName = functionTool.Name;
string toolArgumentsString = functionTool.Arguments;
Dictionary<string, object> toolArguments = JsonSerializer.Deserialize<Dictionary<string, object>>(toolArgumentsString);
// Here you have to call the function defined. In this particular example we use
// reflection to find the method we definied before in an static class called
// `ChatCompletionsExamples`. Using reflection allows us to call a function
// by string name. Notice that this is just done for demonstration purposes as a
// simple way to get the function callable from its string name. Then we can call
// it with the corresponding arguments.
var flags = BindingFlags.Instance | BindingFlags.Public | BindingFlags.NonPublic | BindingFlags.Static;
string toolResponse = (string)typeof(ChatCompletionsExamples).GetMethod(toolName, flags).Invoke(null, toolArguments.Values.Cast<object>().ToArray());
Console.WriteLine("->", toolResponse);
requestOptions.Messages.Add(new ChatRequestToolMessage(toolResponse, callId));
}
else
throw new Exception("Unsupported tool type");
}
Visualizzare la risposta dal modello:
response = client.Complete(requestOptions);
Applicare la sicurezza dei contenuti
L'API di inferenza del modello di Azure per intelligenza artificiale supporta Sicurezza dei contenuti di Azure AI. Quando si usano distribuzioni con sicurezza dei contenuti di Azure AI attivata, gli input e gli output passano attraverso un insieme di modelli di classificazione volti a rilevare e impedire l'output di contenuto dannoso. Il sistema di filtro del contenuto rileva e agisce su categorie specifiche di contenuto potenzialmente dannoso sia nelle richieste di input che nei completamenti di output.
Nell'esempio seguente viene illustrato come gestire gli eventi quando il modello rileva contenuti dannosi nella richiesta di input e la sicurezza dei contenuti è abilitata.
try
{
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are an AI assistant that helps people find information."),
new ChatRequestUserMessage(
"Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."
),
},
};
response = client.Complete(requestOptions);
Console.WriteLine(response.Value.Content);
}
catch (RequestFailedException ex)
{
if (ex.ErrorCode == "content_filter")
{
Console.WriteLine($"Your query has trigger Azure Content Safety: {ex.Message}");
}
else
{
throw;
}
}
Suggerimento
Per altre informazioni su come configurare e controllare le impostazioni di sicurezza dei contenuti di Intelligenza artificiale di Azure, vedere la documentazione sulla sicurezza dei contenuti di Intelligenza artificiale di Azure.
Usare i completamenti della chat con immagini
Alcuni modelli possono ragionarsi tra testo e immagini e generare completamenti del testo in base a entrambi i tipi di input. In questa sezione vengono esaminate le funzionalità di Alcuni modelli per la visione in una chat:
Importante
Alcuni modelli supportano solo un'immagine per ogni turno nella conversazione di chat e solo l'ultima immagine viene mantenuta nel contesto. Se si aggiungono più immagini, viene generato un errore.
Per visualizzare questa funzionalità, scaricare un'immagine e codificare le informazioni come stringa base64. I dati risultanti devono trovarsi all'interno di un URL dati:
string imageUrl = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg";
string imageFormat = "jpeg";
HttpClient httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.Add("User-Agent", "Mozilla/5.0");
byte[] imageBytes = httpClient.GetByteArrayAsync(imageUrl).Result;
string imageBase64 = Convert.ToBase64String(imageBytes);
string dataUrl = $"data:image/{imageFormat};base64,{imageBase64}";
Visualizzare l'immagine:
Creare ora una richiesta di completamento della chat con l'immagine:
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are an AI assistant that helps people find information."),
new ChatRequestUserMessage([
new ChatMessageTextContentItem("Which conclusion can be extracted from the following chart?"),
new ChatMessageImageContentItem(new Uri(dataUrl))
]),
},
MaxTokens=2048,
};
var response = client.Complete(requestOptions);
Console.WriteLine(response.Value.Content);
La risposta è la seguente, in cui è possibile visualizzare le statistiche di utilizzo del modello:
Console.WriteLine($"{response.Value.Role}: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Importante
Gli elementi contrassegnati (anteprima) in questo articolo sono attualmente disponibili in anteprima pubblica. Questa anteprima viene fornita senza un contratto di servizio e non è consigliabile per i carichi di lavoro di produzione. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate. Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
Questo articolo illustra come usare l'API di completamento della chat con i modelli distribuiti nell'inferenza del modello di intelligenza artificiale di Azure nei servizi di intelligenza artificiale di Azure.
Prerequisiti
Per usare i modelli di completamento della chat nell'applicazione, è necessario:
Una sottoscrizione di Azure. Se si usano i modelli GitHub, è possibile aggiornare l'esperienza e creare una sottoscrizione di Azure nel processo. Leggere Eseguire l'aggiornamento dai modelli GitHub all'inferenza del modello di intelligenza artificiale di Azure, se questo è il caso.
Una risorsa dei servizi di intelligenza artificiale di Azure. Per altre informazioni, vedere Creare una risorsa di Servizi di intelligenza artificiale di Azure.
URL e chiave dell'endpoint.
- Distribuzione del modello di completamento della chat. Se non si ha una sola lettura Aggiungere e configurare modelli per i servizi di intelligenza artificiale di Azure per aggiungere un modello di completamento della chat alla risorsa.
Usare i completamenti della chat
Per usare gli incorporamenti di testo, usare la route /chat/completions aggiunta all'URL di base insieme alle credenziali indicate in api-key.
Authorization l'intestazione è supportata anche con il formato Bearer <key>.
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
api-key: <key>
Se la risorsa è stata configurata con il supporto di Microsoft Entra ID , passare il token nell'intestazione Authorization :
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
Authorization: Bearer <token>
Creare una richiesta di completamento della chat
L'esempio seguente illustra come creare una richiesta di completamento della chat di base per il modello.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
]
}
Nota
Alcuni modelli non supportano i messaggi di sistema (role="system"). Quando si usa l'API di inferenza del modello di Azure per intelligenza artificiale, i messaggi di sistema vengono convertiti in messaggi utente, cioè la funzionalità più vicina disponibile. Questa traduzione è disponibile per praticità; tuttavia, è importante verificare che il modello stia seguendo le istruzioni nel messaggio di sistema con il livello di attendibilità corretto.
La risposta è la seguente, in cui è possibile visualizzare le statistiche di utilizzo del modello:
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
Prendere in esame la sezione usage nella risposta per visualizzare il numero di token usati per il prompt, il numero totale di token generati e il numero di token usati per il completamento.
Streaming dei contenuti
Per impostazione predefinita, l'API di completamento restituisce l'intero contenuto generato in una singola risposta. Se si generano completamenti lunghi, l'attesa della risposta può impiegare diversi secondi.
È possibile trasmettere in streaming i contenuti per ottenerli mentre sono generati. Lo streaming dei contenuti consente di avviare l'elaborazione del completamento man mano che i contenuti diventano disponibili. Questa modalità restituisce un oggetto che ritrasmette la risposta come eventi inviati dal server solo dati. Estrarre blocchi dal campo delta, anziché dal campo del messaggio.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"stream": true,
"temperature": 0,
"top_p": 1,
"max_tokens": 2048
}
È possibile visualizzare il modo in cui lo streaming genera contenuti:
{
"id": "23b54589eba14564ad8a2e6978775a39",
"object": "chat.completion.chunk",
"created": 1718726371,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"delta": {
"role": "assistant",
"content": ""
},
"finish_reason": null,
"logprobs": null
}
]
}
Nell'ultimo messaggio nel flusso è impostato finish_reason, che indica il motivo per cui il processo di generazione deve essere arrestato.
{
"id": "23b54589eba14564ad8a2e6978775a39",
"object": "chat.completion.chunk",
"created": 1718726371,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"delta": {
"content": ""
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
Esplorare altri parametri supportati dal client di inferenza
Esplorare altri parametri che è possibile specificare nel client di inferenza. Per un elenco completo di tutti i parametri supportati e della relativa documentazione corrispondente, vedere Informazioni di riferimento sull'API di inferenza del modello di Azure per intelligenza artificiale.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"presence_penalty": 0.1,
"frequency_penalty": 0.8,
"max_tokens": 2048,
"stop": ["<|endoftext|>"],
"temperature" :0,
"top_p": 1,
"response_format": { "type": "text" }
}
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
Alcuni modelli non supportano la formattazione dell'output JSON. È sempre possibile chiedere al modello di generare output JSON. Tuttavia, non è garantito che tali output siano JSON validi.
Se si desidera passare un parametro non incluso nell'elenco dei parametri supportati, è possibile passarlo al modello sottostante usando parametri aggiuntivi. Vedere Passare parametri aggiuntivi al modello.
Creare output JSON
Alcuni modelli possono creare output JSON. Impostare response_format su per json_object abilitare la modalità JSON e garantire che il messaggio generato dal modello sia output JSON valido. È anche necessario indicare al modello di produrre output JSON manualmente tramite un messaggio di sistema o utente. Inoltre, il contenuto del messaggio può essere parzialmente tagliato se finish_reason="length", che indica che la generazione ha superato max_tokens o che la conversazione ha superato la lunghezza massima del contesto.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that always generate responses in JSON format, using the following format: { \"answer\": \"response\" }"
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"response_format": { "type": "json_object" }
}
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718727522,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "{\"answer\": \"There are approximately 7,117 living languages in the world today, according to the latest estimates. However, this number can vary as some languages become extinct and others are newly discovered or classified.\"}",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 39,
"total_tokens": 87,
"completion_tokens": 48
}
}
Passare parametri aggiuntivi al modello
L'API di inferenza del modello di intelligenza artificiale di Azure consente di passare parametri aggiuntivi al modello. Nell'esempio di codice seguente viene illustrato come passare il parametro aggiuntivo logprobs al modello.
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Authorization: Bearer <TOKEN>
Content-Type: application/json
extra-parameters: pass-through
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"logprobs": true
}
Prima di passare parametri aggiuntivi all'API di inferenza del modello di intelligenza artificiale di Azure, assicurarsi che il modello supporti tali parametri aggiuntivi. Quando la richiesta viene effettuata al modello sottostante, l'intestazione extra-parameters viene passata al modello con il valore pass-through. Questo valore indica all'endpoint di passare i parametri aggiuntivi al modello. L'uso di parametri aggiuntivi con il modello non garantisce che il suddetto possa gestirli effettivamente. Leggere la documentazione del modello per comprendere quali parametri aggiuntivi sono supportati.
Usare gli strumenti
Alcuni modelli supportano l'uso di strumenti, che possono essere una risorsa straordinaria quando è necessario eseguire l'offload di attività specifiche dal modello linguistico e basarsi invece su un sistema più deterministico o anche su un modello linguistico diverso. L'API di inferenza del modello di intelligenza artificiale di Azure consente di definire gli strumenti nel modo seguente.
L'esempio di codice seguente crea una definizione dello strumento in grado di esaminare le informazioni sui voli da due città diverse.
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters": {
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": [
"origin_city",
"destination_city"
]
}
}
}
In questo esempio, l'output della funzione è che non sono disponibili voli per il percorso selezionato e l'utente deve prendere in considerazione di prendere un treno.
Nota
I modelli Cohere richiedono che le risposte di uno strumento siano un contenuto JSON valido formattato come stringa. Quando si creano messaggi di tipo Tool, assicurarsi che la risposta sia una stringa JSON valida.
Richiedere al modello di prenotare i voli con l'aiuto di questa funzione:
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that help users to find information about traveling, how to get to places and the different transportations options. You care about the environment and you always have that in mind when answering inqueries"
},
{
"role": "user",
"content": "When is the next flight from Miami to Seattle?"
}
],
"tool_choice": "auto",
"tools": [
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters": {
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": [
"origin_city",
"destination_city"
]
}
}
}
]
}
È possibile esaminare la risposta per verificare se è necessario chiamare uno strumento. Esaminare il motivo di fine per determinare se è necessario chiamare lo strumento. Tenere presente che è possibile indicare più tipi di strumenti. In questo esempio viene illustrato uno strumento di tipo function.
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726007,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "abc0dF1gh",
"type": "function",
"function": {
"name": "get_flight_info",
"arguments": "{\"origin_city\": \"Miami\", \"destination_city\": \"Seattle\"}",
"call_id": null
}
}
]
},
"finish_reason": "tool_calls",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 190,
"total_tokens": 226,
"completion_tokens": 36
}
}
Per continuare, aggiungere questo messaggio alla cronologia delle chat:
A questo punto, è possibile chiamare la funzione appropriata per gestire la chiamata allo strumento. Il frammento di codice seguente esegue l'iterazione di tutte le chiamate dello strumento indicate nella risposta e chiama la funzione corrispondente con i parametri appropriati. La risposta viene aggiunta anche alla cronologia delle chat.
Visualizzare la risposta dal modello:
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that help users to find information about traveling, how to get to places and the different transportations options. You care about the environment and you always have that in mind when answering inqueries"
},
{
"role": "user",
"content": "When is the next flight from Miami to Seattle?"
},
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "abc0DeFgH",
"type": "function",
"function": {
"name": "get_flight_info",
"arguments": "{\"origin_city\": \"Miami\", \"destination_city\": \"Seattle\"}",
"call_id": null
}
}
]
},
{
"role": "tool",
"content": "{ \"info\": \"There are no flights available from Miami to Seattle. You should take a train, specially if it helps to reduce CO2 emissions.\" }",
"tool_call_id": "abc0DeFgH"
}
],
"tool_choice": "auto",
"tools": [
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters":{
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": ["origin_city", "destination_city"]
}
}
}
]
}
Applicare la sicurezza dei contenuti
L'API di inferenza del modello di Azure per intelligenza artificiale supporta Sicurezza dei contenuti di Azure AI. Quando si usano distribuzioni con sicurezza dei contenuti di Azure AI attivata, gli input e gli output passano attraverso un insieme di modelli di classificazione volti a rilevare e impedire l'output di contenuto dannoso. Il sistema di filtro del contenuto rileva e agisce su categorie specifiche di contenuto potenzialmente dannoso sia nelle richieste di input che nei completamenti di output.
Nell'esempio seguente viene illustrato come gestire gli eventi quando il modello rileva contenuti dannosi nella richiesta di input e la sicurezza dei contenuti è abilitata.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are an AI assistant that helps people find information."
},
{
"role": "user",
"content": "Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."
}
]
}
{
"error": {
"message": "The response was filtered due to the prompt triggering Microsoft's content management policy. Please modify your prompt and retry.",
"type": null,
"param": "prompt",
"code": "content_filter",
"status": 400
}
}
Suggerimento
Per altre informazioni su come configurare e controllare le impostazioni di sicurezza dei contenuti di Intelligenza artificiale di Azure, vedere la documentazione sulla sicurezza dei contenuti di Intelligenza artificiale di Azure.
Usare i completamenti della chat con immagini
Alcuni modelli possono ragionarsi tra testo e immagini e generare completamenti del testo in base a entrambi i tipi di input. In questa sezione vengono esaminate le funzionalità di Alcuni modelli per la visione in una chat:
Importante
Alcuni modelli supportano solo un'immagine per ogni turno nella conversazione di chat e solo l'ultima immagine viene mantenuta nel contesto. Se si aggiungono più immagini, viene generato un errore.
Per visualizzare questa funzionalità, scaricare un'immagine e codificare le informazioni come stringa base64. I dati risultanti devono trovarsi all'interno di un URL dati:
Suggerimento
Sarà necessario costruire l'URL dei dati usando uno scripting o un linguaggio di programmazione. Questa esercitazione usa questa immagine di esempio in formato JPEG. Un URL dati ha un formato come indicato di seguito: data:image/jpg;base64,0xABCDFGHIJKLMNOPQRSTUVWXYZ....
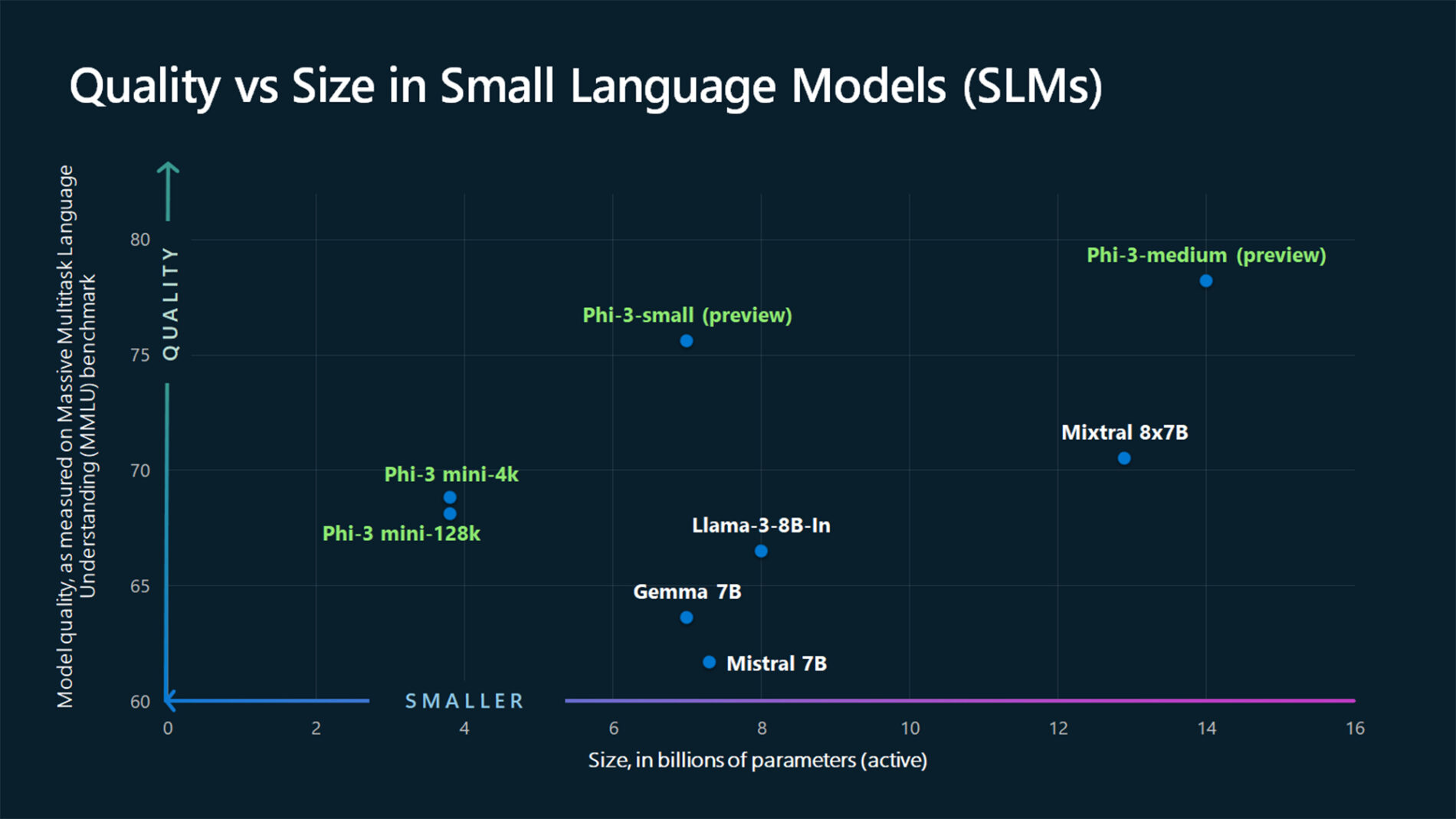{kind=link}
Visualizzare l'immagine:
Creare ora una richiesta di completamento della chat con l'immagine:
{
"model": "phi-3.5-vision-instruct",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Which peculiar conclusion about LLMs and SLMs can be extracted from the following chart?"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpg;base64,0xABCDFGHIJKLMNOPQRSTUVWXYZ..."
}
}
]
}
],
"temperature": 0,
"top_p": 1,
"max_tokens": 2048
}
La risposta è la seguente, in cui è possibile visualizzare le statistiche di utilizzo del modello:
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "phi-3.5-vision-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 2380,
"completion_tokens": 126,
"total_tokens": 2506
}
}