Modello di cluster Kubernetes a disponibilità elevata
Questo articolo descrive come progettare e gestire un'infrastruttura a disponibilità elevata basata su Kubernetes usando il motore del servizio Azure Kubernetes nell'hub di Azure Stack. Questo scenario è comune per le organizzazioni con carichi di lavoro cruciali in ambienti con restrizioni e altamente regolamentati, ad esempio in domini come finanze, difesa e pubblica amministrazione.
Contesto e problema
Molte organizzazioni sviluppano soluzioni native del cloud che sfruttano servizi e tecnologie all'avanguardia come Kubernetes. Anche se per Azure sono disponibili data center nella maggior parte delle aree geografiche del mondo, a volte casi d'uso e scenari limite impongono l'esecuzione di applicazioni business critical in una specifica località. Ecco gli aspetti da considerare:
- Restrizioni per la località
- Latenza tra l'applicazione e i sistemi locali
- Conservazione della larghezza di banda
- Connettività
- Requisiti normativi o di legge
Azure, in combinazione con l'hub di Azure Stack, risolve la maggior parte di questi aspetti. Di seguito è riportato un ampio set di opzioni, decisioni e considerazioni per il successo di un'implementazione di Kubernetes in esecuzione nell'hub di Azure Stack.
Soluzione
Questo modello presuppone che sia necessario far fronte a un set rigoroso di vincoli. L'applicazione deve essere eseguita in locale e i dati personali non devono essere spostati in servizi cloud pubblici. I dati di monitoraggio e altre informazioni non personali possono essere inviati ad Azure per l'elaborazione. Servizi esterni come un registro contenitori pubblico o di altro tipo possono essere accessibili ma potrebbero essere filtrati tramite un firewall o un server proxy.
L'applicazione di esempio illustrata di seguito è progettata per usare le soluzioni native di Kubernetes quando possibile. La scelta di usare servizi nativi della piattaforma evita la dipendenza da un singolo fornitore. Ad esempio, l'applicazione usa un back-end di database MongoDB self-hosted invece di un servizio PaaS o di un servizio di database esterno. Per altre informazioni, vedere il percorso di apprendimento Introduzione a Kubernetes in Azure.

Il diagramma precedente illustra l'architettura dell'applicazione di esempio in esecuzione in Kubernetes nell'hub di Azure Stack. L'app è costituita da diversi componenti:
- Un cluster Kubernetes basato sul motore del servizio Azure Kubernetes nell'hub di Azure Stack.
- cert-manager, che include una serie di strumenti per la gestione dei certificati in Kubernetes, usati per richiedere automaticamente i certificati a Let's Encrypt.
- Uno spazio dei nomi di Kubernetes che contiene i componenti dell'applicazione per front-end (ratings-web), API (ratings-api) e database (ratings-mongodb).
- Il controller in ingresso che instrada il traffico HTTP/HTTPS agli endpoint all'interno del cluster Kubernetes.
L'applicazione di esempio viene usata per illustrare questa architettura. Tutti i componenti sono esempi. L'architettura contiene solo la distribuzione di una singola applicazione. Ai fini della disponibilità elevata, la distribuzione verrà eseguita almeno due volte in due istanze diverse dell'hub di Azure Stack, che possono essere eseguite nella stessa posizione oppure in due o più siti diversi:
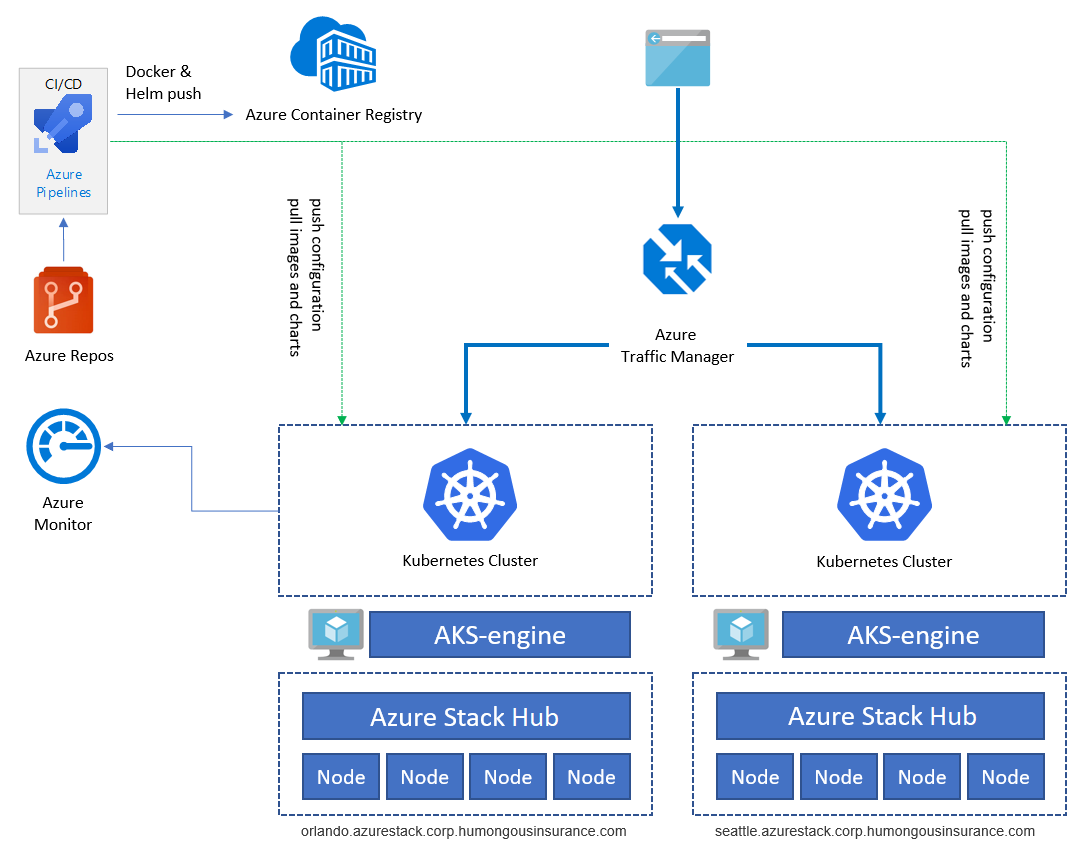
Servizi come Registro Azure Container, Monitoraggio di Azure e altri sono ospitati all'esterno dell'hub di Azure Stack in Azure o in locale. Questo modello ibrido protegge la soluzione in caso di interruzione di una singola istanza dell'hub di Azure Stack.
Componenti
L'architettura generale è costituita dai componenti seguenti:
L'hub di Azure Stack è un'estensione di Azure che consente di eseguire i carichi di lavoro in un ambiente locale fornendo i servizi di Azure nel data center. Per altre informazioni, vedere la panoramica dell'hub di Azure Stack.
Il motore del servizio Azure Kubernetes è il motore alla base dell'offerta di servizio Kubernetes gestito, il servizio Azure Kubernetes, già disponibile in Azure. Per l'hub di Azure Stack, il motore del servizio Azure Kubernetes consente di distribuire, dimensionare e aggiornare cluster Kubernetes completi e autogestiti usando le funzionalità IaaS dell'hub di Azure Stack. Per altre informazioni, vedere la panoramica del motore del servizio Azure Kubernetes.
Per altre informazioni sulle differenze tra il motore del servizio Azure Kubernetes in Azure e quello nell'hub di Azure Stack, vedere Problemi noti e limitazioni.
Il servizio Rete virtuale di Azure viene usato per fornire l'infrastruttura di rete in ogni hub di Azure Stack per le macchine virtuali (VM) che ospitano l'infrastruttura del cluster Kubernetes.
Azure Load Balancer viene usato per l'endpoint API di Kubernetes e per il controller in ingresso Nginx. Questo servizio instrada il traffico esterno (ad esempio Internet) ai nodi e alle VM che offrono uno specifico servizio.
Registro Azure Container viene usato per archiviare le immagini Docker private e i grafici Helm, che vengono distribuiti nel cluster. Il motore del servizio Azure Kubernetes può eseguire l'autenticazione con Registro Azure Container usando un'identità di Azure AD. Kubernetes non richiede Registro Azure Container. È possibile usare altri registri di contenitori, ad esempio l'hub Docker.
Azure Repos è un set di strumenti di controllo della versione che è possibile usare per gestire il codice. È anche possibile usare GitHub o altri repository basati su git. Per altre informazioni, vedere la panoramica di Azure Repos.
Azure Pipelines fa parte di Azure DevOps Services ed esegue compilazioni, test e distribuzioni automatizzati. È inoltre possibile usare soluzioni CI/CD di terze parti come Jenkins. Per altre informazioni, vedere la panoramica di Azure Pipelines.
Monitoraggio di Azure raccoglie e archivia log e metriche, tra cui le metriche della piattaforma per i servizi di Azure nella soluzione e i dati di telemetria dell'applicazione. Usare questi dati per monitorare l'applicazione, configurare avvisi e dashboard ed eseguire l'analisi delle cause principali di errore. Monitoraggio di Azure si integra con Kubernetes per raccogliere le metriche da controller, nodi e contenitori, nonché dai log di contenitori e nodi master. Per altre informazioni, vedere la panoramica di Monitoraggio di Azure.
Gestione traffico di Azure è un servizio di bilanciamento del carico basato su DNS che consente di ottimizzare la distribuzione del traffico ai servizi in aree di Azure o in distribuzioni dell'hub di Azure Stack diverse. Gestione traffico offre anche disponibilità elevata e tempi di risposta rapidi. Gli endpoint applicazione devono essere accessibili dall'esterno. Sono disponibili anche altre soluzioni locali.
Il controller in ingresso di Kubernetes espone route HTTP(S) ai servizi in un cluster Kubernetes. A questo scopo è possibile usare Nginx o qualsiasi altro controller in ingresso appropriato.
Helm è un'utilità di gestione pacchetti per la distribuzione di Kubernetes, che offre la possibilità di raggruppare diversi oggetti di Kubernetes, come distribuzioni, servizi e segreti, in un singolo "grafico". È possibile pubblicare, distribuire, controllare la gestione delle versioni e aggiornare un oggetto grafico. Come repository per archiviare i pacchetti di grafici Helm è possibile usare Registro Azure Container.
Considerazioni sulla progettazione
Questo modello segue alcune considerazioni generali descritte in maggior dettaglio nelle sezioni successive dell'articolo:
- L'applicazione usa soluzioni native di Kubernetes per evitare la dipendenza da un singolo fornitore.
- L'applicazione usa un'architettura di microservizi.
- L'hub di Azure Stack non richiede connettività Internet in ingresso ma consente quella in uscita.
Queste procedure consigliate si applicano anche a carichi di lavoro e scenari reali.
Considerazioni sulla scalabilità
La scalabilità è importante per offrire agli utenti l'accesso coerente, affidabile e funzionante alle applicazioni.
Lo scenario di esempio illustra la scalabilità su più livelli dello stack dell'applicazione. Ecco una panoramica generale dei diversi livelli:
| Livello dell'architettura | Impatto | Come si procede? |
|---|---|---|
| Applicazione | Applicazione | Scalabilità orizzontale in base al numero di pod/repliche/istanze di contenitore* |
| Cluster | Cluster Kubernetes | Numero di nodi (compreso tra 1 e 50), dimensioni degli SKU di VM e pool di nodi (il motore del servizio Azure Kubernetes nell'hub di Azure Stack supporta attualmente solo un pool a nodo singolo); uso del comando scale (manuale) del motore del servizio Azure Kubernetes |
| Infrastruttura | Hub di Azure Stack | Numero di nodi, capacità e unità di scala all'interno di una distribuzione dell'hub di Azure Stack |
* Uso della scalabilità automatica orizzontale dei pod di Kubernetes (HPA); ridimensionamento automatico basato su metriche o ridimensionamento verticale ridimensionando le istanze del contenitore (CPU/memoria).
Hub di Azure Stack (livello dell'infrastruttura)
L'infrastruttura dell'hub di Azure Stack è la base di questa implementazione, perché l'hub di Azure Stack viene eseguito su hardware fisico in un data center. Quando si seleziona l'hardware dell'hub, è necessario scegliere CPU, densità di memoria, configurazione dell'archiviazione e numero di server. Per altre informazioni sulla scalabilità dell'hub di Azure Stack, vedere le risorse seguenti:
- Panoramica della pianificazione della capacità per l'hub di Azure Stack
- Aggiungere altri nodi di unità di scala aggiuntivi nell'hub di Azure Stack
Cluster Kubernetes (livello del cluster)
Il cluster Kubernetes è costituito da ed è basato su componenti dell'infrastruttura IaaS di Azure Stack, tra cui risorse di calcolo, archiviazione e rete. Le soluzioni Kubernetes includono nodi master e di lavoro, che vengono distribuiti come VM in Azure (e nell'hub di Azure Stack).
- I nodi del piano di controllo (master) forniscono i servizi Kubernetes di base e l'orchestrazione dei carichi di lavoro dell'applicazione.
- I nodi di lavoro eseguono i carichi di lavoro dell'applicazione.
Per la selezione delle dimensioni delle VM per la distribuzione iniziale, è necessario considerare gli aspetti seguenti:
Costo: quando si pianificano i nodi di lavoro, tenere presente il costo complessivo in cui si incorrerà per ogni macchina virtuale. Se ad esempio i carichi di lavoro dell'applicazione richiedono risorse limitate, è consigliabile pianificare la distribuzione di VM di dimensioni inferiori. L'hub di Azure Stack, come Azure, viene in genere fatturato a consumo, quindi per ottimizzare i costi a consumo, è fondamentale dimensionare in modo appropriato le VM per i ruoli di Kubernetes.
Scalabilità: la scalabilità del cluster si ottiene tramite l'aumento e la riduzione del numero di nodi master e di lavoro oppure con l'aggiunta di altri pool di nodi (opzioni attualmente non disponibile per l'hub di Azure Stack). Il dimensionamento del cluster può essere eseguito in base ai dati sulle prestazioni, raccolti tramite Informazioni dettagliate contenitore (Monitoraggio di Azure + Log Analytics).
Se l'applicazione necessita di più o meno risorse, è possibile aumentare o ridurre i nodi correnti orizzontalmente (tra 1 e 50 nodi). Se sono necessari più di 50 nodi, è possibile creare un cluster aggiuntivo in una sottoscrizione separata. Non è possibile scalare verticalmente le VM effettive passando ad altre dimensioni di VM senza ridistribuire il cluster.
La scalabilità viene applicata manualmente tramite la VM helper del motore del servizio Azure Kubernetes usata per la distribuzione iniziale del cluster Kubernetes. Per altre informazioni, vedere Scalabilità dei cluster Kubernetes
Quote: considerare le quote configurate durante la pianificazione di una distribuzione del servizio Azure Kubernetes nell'hub di Azure Stack. Assicurarsi che per ogni sottoscrizione siano stati configurati piani e quote appropriati. La sottoscrizione dovrà supportare l'aumento della quantità di risorse di calcolo e di archiviazione e degli altri servizi necessari per i cluster.
Carichi di lavoro dell'applicazione: vedere la sezione sui concetti di cluster e carichi di lavoro nel documento sui concetti di base di Kubernetes per il servizio Azure Kubernetes. Questo articolo consentirà di definire le dimensioni appropriate per le VM in base alle esigenze di calcolo e memoria dell'applicazione.
Applicazione (livello dell'applicazione)
Nel livello dell'applicazione viene usato lo strumento Horizontal Pod Autoscaler (HPA) di Kubernetes. HPA consente di aumentare o ridurre il numero di repliche (istanze di pod/contenitori) nella distribuzione in base a metriche differenti, ad esempio l'utilizzo della CPU.
Un'altra opzione consiste nel dimensionare le istanze di contenitori verticalmente. A questo scopo, è necessario cambiare le quantità di CPU e memoria richieste e disponibili per una specifica distribuzione. Per altre informazioni, vedere Gestione delle risorse per i contenitori in kubernetes.io.
Considerazioni su rete e connettività
Anche la rete e la connettività influiscono sui tre livelli citati in precedenza per Kubernetes nell'hub di Azure Stack. La tabella seguente illustra i livelli e i servizi che contengono:
| Livello | Impatto | Cosa? |
|---|---|---|
| Applicazione | Applicazione | Come si accede all'applicazione? Verrà esposta su Internet? |
| Cluster | Cluster Kubernetes | API Kubernetes, VM del motore del servizio Azure Kubernetes, pull di immagini di contenitori (in uscita), invio di dati di monitoraggio e di telemetria (in uscita) |
| Infrastruttura | Hub di Azure Stack | Accessibilità degli endpoint di gestione dell'hub di Azure Stack, come il portale e gli endpoint di Azure Resource Manager. |
Applicazione
Per il livello dell'applicazione, l'aspetto più importante da considerare è se l'applicazione è esposta e accessibile da Internet. Dal punto di vista di Kubernetes, l'accessibilità tramite Internet significa esporre una distribuzione o un pod usando un servizio Kubernetes o un controller in ingresso.
L'esposizione di un'applicazione usando un indirizzo IP pubblico tramite un servizio di bilanciamento del carico o un controller in ingresso non implica necessariamente che l'applicazione sia accessibile tramite Internet. È possibile che l'hub di Azure Stack abbia un indirizzo IP pubblico visibile solo nella Intranet locale. Non tutti gli indirizzi IP pubblici sono infatti accessibili da Internet.
Il blocco precedente considera il traffico in ingresso nell'applicazione. Un altro aspetto da considerare per il successo di una distribuzione di Kubernetes è il traffico in uscita. Ecco alcuni casi d'uso che richiedono il traffico in uscita:
- Pull di immagini di contenitori archiviate in DockerHub o in Registro Azure Container
- Recupero di grafici Helm
- Invio di dati di Application Insights (o altri dati di monitoraggio)
Alcuni ambienti aziendali potrebbero richiedere l'uso di server proxy trasparenti o non trasparenti. Per questi server è necessaria una configurazione specifica di vari componenti del cluster. La documentazione del motore del servizio Azure Kubernetes contiene varie informazioni su come gestire i proxy di rete. Per informazioni più dettagliate, vedere Motore del servizio Azure Kubernetes e server proxy
Infine, il traffico tra cluster deve fluire tra le istanze dell'hub di Azure Stack. La distribuzione di esempio è costituita da singoli cluster Kubernetes in esecuzione in singole istanze dell'hub di Azure Stack. Il traffico tra questi componenti, ad esempio il traffico di replica tra due database, è considerato "traffico esterno". Il traffico esterno deve essere instradato tramite una VPN da sito a sito o tramite indirizzi IP pubblici dell'hub di Azure Stack per connettere Kubernetes in due istanze dell'hub di Azure Stack:
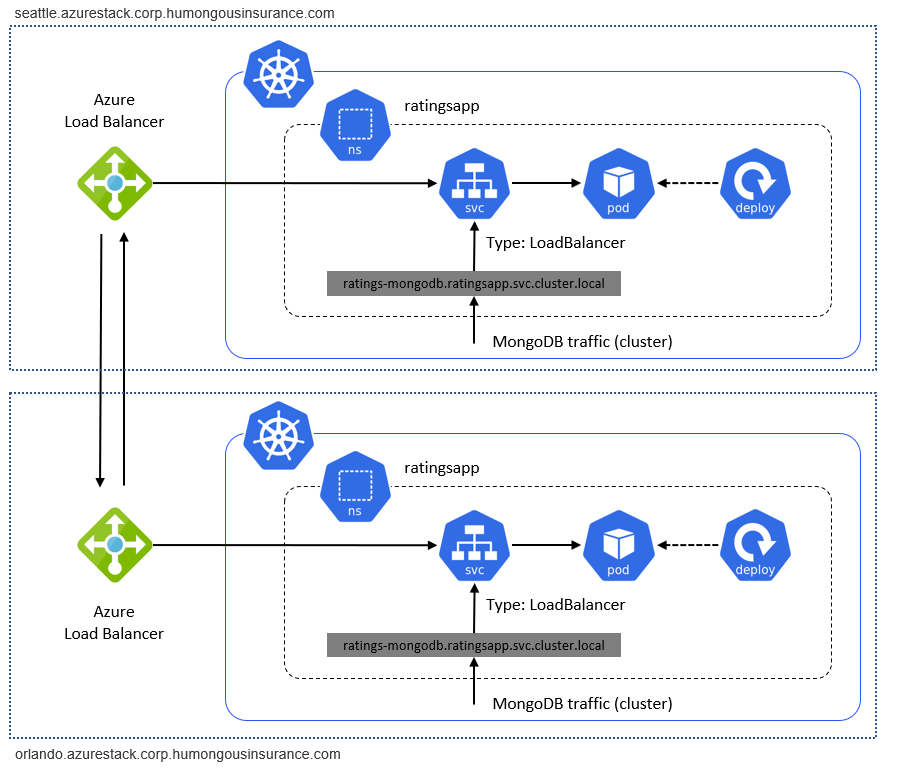
Cluster
Il cluster Kubernetes non deve necessariamente essere accessibile tramite Internet. La parte pertinente è l'API Kubernetes usata per gestire un cluster, ad esempio tramite kubectl. L'endpoint API di Kubernetes deve essere accessibile a tutti gli utenti che gestiscono il cluster o che vi distribuiscono applicazioni e servizi. Questo aspetto viene trattato in maggior dettaglio dal punto di vista di DevOps nella sezione Considerazioni sulla distribuzione (CI/CD) di seguito.
Nel livello del cluster esistono anche alcune considerazioni sul traffico in uscita:
- Aggiornamenti dei nodi (per Ubuntu)
- Dati di monitoraggio (inviati ad Azure LogAnalytics)
- Altri agenti che richiedono il traffico in uscita (specifico per l'ambiente di ogni distribuzione)
Prima di distribuire il cluster Kubernetes usando il motore del servizio Azure Kubernetes, pianificare l'architettura finale della rete. Invece di creare una rete virtuale dedicata, può risultare più efficiente distribuire un cluster in una rete esistente. Ad esempio, è possibile usare una connessione VPN da sito a sito esistente già configurata nell'ambiente dell'hub di Azure Stack.
Infrastruttura
L'infrastruttura si riferisce all'accesso agli endpoint di gestione dell'hub di Azure Stack. Gli endpoint includono i portali di tenant e amministrazione e gli endpoint di tenant e amministrazione di Azure Resource Manager. Questi endpoint sono necessari per il funzionamento dell'hub di Azure Stack e dei relativi servizi di base.
Considerazioni su dati e archiviazione
Verranno distribuite due istanze dell'applicazione in due singoli cluster Kubernetes tra due istanze dell'hub di Azure Stack. Per questo modello è necessario valutare come replicare e sincronizzare i dati tra i componenti.
Azure include la funzionalità predefinita per la replica dell'archiviazione tra più aree e zone all'interno del cloud. Attualmente con l'hub di Azure Stack non sono disponibili modalità native per replicare l'archiviazione tra due diverse istanze dell'hub di Azure Stack, perché formano due cloud indipendenti che non è possibile gestire come set. La pianificazione della resilienza delle applicazioni in esecuzione nell'hub di Azure Stack impone di tenere conto di questa indipendenza nella progettazione e nelle distribuzioni dell'applicazione.
Nella maggior parte dei casi, la replica dell'archiviazione non è necessaria per un'applicazione resiliente e a disponibilità elevata distribuita nel servizio Azure Kubernetes. Tuttavia, è necessario considerare l'archiviazione indipendente per ogni istanza dell'hub di Azure Stack nella progettazione dell'applicazione. Se questo aspetto rappresenta un problema o un ostacolo per la distribuzione della soluzione nell'hub di Azure Stack, sono disponibili soluzioni dei partner Microsoft che forniscono connessioni all'archiviazione. Le connessioni all'archiviazione offrono una soluzione di replica dell'archiviazione tra più hub di Azure Stack e Azure. Per altre informazioni, vedere le soluzioni dei partner.
In questa architettura vengono considerati i livelli seguenti:
Configuration
La configurazione riguarda l'hub di Azure Stack, il motore del servizio Azure Kubernetes e il cluster Kubernetes stesso. La configurazione deve essere automatizzata il più possibile e archiviata come Infrastructure-as-Code in un sistema di controllo della versione basato su Git come Azure DevOps o GitHub. Queste impostazioni non possono essere facilmente sincronizzate tra più distribuzioni. È quindi consigliabile archiviare e applicare la configurazione dall'esterno e usare la pipeline DevOps.
Applicazione
L'applicazione dovrà essere archiviata in un repository basato su Git. In caso di nuove distribuzioni, di modifiche dell'applicazione o di scenari di ripristino di emergenza, è più facile usare Azure Pipelines.
Dati
I dati rappresentano il fattore più importante da considerare nella progettazione di applicazioni. I dati devono rimanere sincronizzati tra le diverse istanze dell'applicazione. È anche necessario definire una strategia di backup e ripristino di emergenza in caso di interruzione del servizio.
Questa progettazione dipende in larga misura da scelte tecnologiche. Ecco alcuni esempi di soluzioni per l'implementazione di un database in modalità a disponibilità elevata nell'hub di Azure Stack:
- Distribuire un gruppo di disponibilità di SQL Server 2016 in Azure e nell'hub di Azure Stack
- Distribuire una soluzione MongoDB a disponibilità elevata in Azure e nell'hub di Azure Stack
Se i dati risiedono in più località, la scelta di una soluzione resiliente e a disponibilità elevata implica aspetti ancora più complessi da considerare. Tenere in considerazione:
- Latenza e connettività di rete tra hub di Azure Stack.
- Disponibilità di identità per servizi e autorizzazioni. Ogni istanza dell'hub di Azure Stack integra una directory esterna. Durante la distribuzione, si sceglie se usare Azure Active Directory (Azure AD) o Active Directory Federation Services (ADFS). Di conseguenza, è possibile usare una singola identità in grado di interagire con più istanze indipendenti dell'hub di Azure Stack.
Continuità aziendale e ripristino di emergenza
La continuità aziendale e il ripristino di emergenza sono aspetti importanti sia nell'hub di Azure Stack che in Azure. La differenza principale consiste nel fatto che nell'hub di Azure Stack l'operatore deve gestire l'intero processo di continuità aziendale e ripristino di emergenza. In Azure parti di questo processo vengono gestite automaticamente da Microsoft.
Il processo di continuità aziendale e ripristino di emergenza influisce sulle stesse aree citate nella precedente sezione Considerazioni su dati e archiviazione:
- Infrastruttura/configurazione
- Disponibilità dell'applicazione
- Dati applicazione
Come indicato nella sezione precedente, queste aree sono di responsabilità dell'operatore dell'hub di Azure Stack e possono variare da un'organizzazione all'altra. Pianificare la continuità aziendale e il ripristino di emergenza in base agli strumenti e ai processi disponibili.
Infrastruttura e configurazione
Questa sezione descrive l'infrastruttura fisica e logica e la configurazione dell'hub di Azure Stack. Riguarda le azioni da eseguire negli ambiti di amministrazione e tenant.
L'operatore o l'amministratore dell'hub di Azure Stack è responsabile della manutenzione delle istanze dell'hub di Azure Stack, inclusi componenti come rete, archiviazione, identità e altri che esulano dall'ambito di questo articolo. Per altre informazioni sulle specifiche delle operazioni dell'hub di Azure Stack, vedere le risorse seguenti:
- Recuperare i dati nell'hub di Azure Stack con il servizio Backup infrastruttura
- Abilitare il backup per l'hub di Azure Stack nel portale dell'amministratore
- Eseguire il ripristino da una grave perdita di dati
- Procedure consigliate per il servizio Backup infrastruttura
L'hub di Azure Stack rappresenta la piattaforma e l'infrastruttura in cui verranno distribuite le applicazioni Kubernetes. Il proprietario dell'applicazione Kubernetes sarà un utente dell'hub di Azure Stack, con accesso concesso per distribuire l'infrastruttura dell'applicazione necessaria per la soluzione. In questo caso l'infrastruttura dell'applicazione indica il cluster Kubernetes, distribuito usando il motore del servizio Azure Kubernetes e i servizi circostanti. Questi componenti verranno distribuiti nell'hub di Azure Stack, vincolati da un'offerta dell'hub di Azure Stack. Assicurarsi che l'offerta accettata dal proprietario dell'applicazione Kubernetes abbia la capacità sufficiente (espressa in quote dell'hub di Azure Stack) per distribuire l'intera soluzione. Come consigliato nella sezione precedente, la distribuzione dell'applicazione deve essere automatizzata tramite Infrastructure-as-Code e pipeline di distribuzione come Azure DevOps Azure Pipelines.
Per altre informazioni sulle offerte e sulle quote dell'hub di Azure Stack, vedere Panoramica di servizi, piani, offerte e sottoscrizioni dell'hub di Azure Stack
È importante salvare e archiviare in modo sicuro la configurazione del motore del servizio Azure Kubernetes, inclusi i relativi output. Questi file contengono informazioni riservate usate per accedere al cluster Kubernetes, pertanto è necessario proteggerli dall'esposizione ai non amministratori.
Disponibilità dell'applicazione
L'applicazione non deve basarsi sui backup di un'istanza distribuita. Come procedura standard, ridistribuire completamente l'applicazione seguendo i modelli di Infrastructure-as-Code. Ad esempio, ridistribuirla con Azure DevOps o Azure Pipelines. La procedura di continuità aziendale e ripristino di emergenza deve implicare la ridistribuzione dell'applicazione nello stesso cluster Kubernetes o in un altro.
Dati dell'applicazione
È particolarmente importante ridurre al minimo la perdita di dati dell'applicazione. Nella sezione precedente sono state descritte le tecniche per replicare e sincronizzare i dati tra due o più istanze dell'applicazione. A seconda dell'infrastruttura di database (MySQL, MongoDB, MSSQL o altri) usata per archiviare i dati, saranno disponibili diverse tecniche di disponibilità e backup del database tra cui scegliere.
Per ottenere l'integrità è consigliabile usare:
- Una soluzione di backup nativa per il database specifico.
- Una soluzione di backup che supporta ufficialmente il backup e il ripristino del tipo di database usato dall'applicazione.
Importante
Non archiviare i dati di backup nella stessa istanza dell'hub di Azure Stack in cui risiedono i dati dell'applicazione. Un'interruzione completa dell'istanza dell'hub di Azure Stack comprometterebbe anche i backup.
Considerazioni sulla disponibilità
Kubernetes nell'hub di Azure Stack distribuito tramite il motore del servizio Azure Kubernetes non è un servizio gestito. Si tratta di una procedura automatizzata di distribuzione e configurazione di un cluster Kubernetes tramite infrastruttura distribuita come servizio (IaaS) di Azure. Di conseguenza, fornisce la stessa disponibilità dell'infrastruttura sottostante.
L'infrastruttura dell'hub di Azure Stack è già resiliente agli errori e fornisce funzionalità come i set di disponibilità per distribuire i componenti in più domini di errore e di aggiornamento. Tuttavia, la tecnologia sottostante (clustering di failover) può comunque comportare tempi di inattività per le VM in un server fisico interessato, in caso di errore hardware.
È consigliabile distribuire il cluster Kubernetes di produzione e il carico di lavoro in due o più cluster. Questi cluster devono essere ospitati in località o data center diversi e devono usare tecnologie come Gestione traffico di Azure per instradare gli utenti in base al tempo di risposta del cluster o all'area geografica.
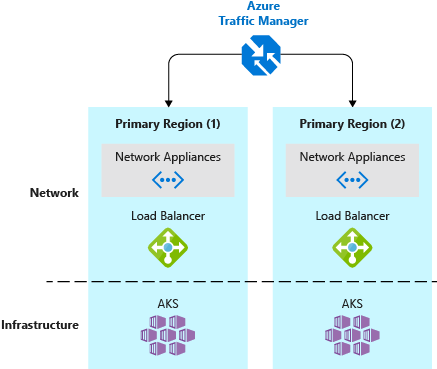
I clienti con un singolo cluster Kubernetes in genere si connettono all'indirizzo IP del servizio o al nome DNS di una determinata applicazione. Nelle distribuzioni con più cluster, i clienti dovrebbero connettersi a un nome DNS di Gestione traffico che punta ai servizi/in ingresso in ogni cluster Kubernetes.
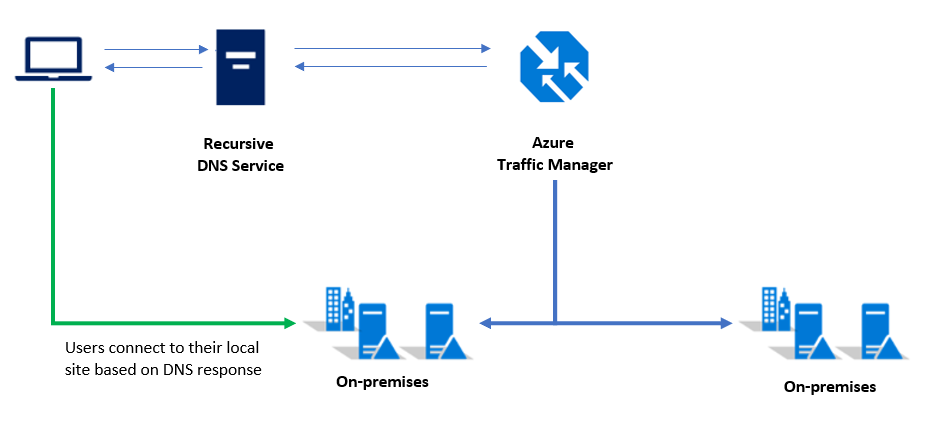
Nota
Questo modello è anche una procedura consigliata per i cluster del servizio Azure Kubernetes (gestiti) in Azure.
Il cluster Kubernetes stesso, distribuito tramite il motore del servizio Azure Kubernetes, deve essere costituito da almeno tre nodi master e due nodi di lavoro.
Considerazioni su identità e sicurezza
Identità e sicurezza sono aspetti importanti, in particolare quando la soluzione si estende in istanze indipendenti dell'hub di Azure Stack. Kubernetes e Azure (incluso l'hub di Azure Stack) includono meccanismi distinti per il controllo degli accessi in base al ruolo:
- Il controllo degli accessi in base al ruolo di Azure controlla l'accesso alle risorse di Azure (e all'hub di Azure Stack), inclusa la possibilità di creare nuove risorse di Azure. Questi ruoli possono essere assegnati a utenti, gruppi o entità servizio (un'entità servizio è un'identità di sicurezza usata dalle applicazioni).
- I controlli degli accessi in base al ruolo di Kubernetes consentoni di controllare le autorizzazioni per l'API di Kubernetes. Ad esempio, la creazione e inserzione dei pod sono azioni che possono essere autorizzate (o negate) a un utente tramite controlli degli accessi in base al ruolo. Per assegnare le autorizzazioni di Kubernetes agli utenti, creare ruoli e binding di ruoli.
Identità dell'hub di Azure Stack e controllo degli accessi in base al ruolo
L'hub di Azure Stack prevede due opzioni per il provider di identità. Il provider che si usa varia in base al tipo di ambiente e al fatto che sia connesso o disconnesso:
- Azure AD può essere usato solo in un ambiente connesso.
- ADFS in una foresta di Active Directory tradizionale può essere usato in un ambiente connesso o disconnesso.
Il provider di identità gestisce utenti e gruppi, tra cui l'autenticazione e l'autorizzazione per l'accesso alle risorse. L'accesso può essere concesso a risorse dell'hub di Azure Stack, ad esempio sottoscrizioni o gruppi di risorse, e a singole risorse come VM o servizi di bilanciamento del carico. Per un modello di accesso coerente, è consigliabile usare gli stessi gruppi, sia diretti che annidati, per tutti gli hub di Azure Stack. Ecco un esempio di configurazione:
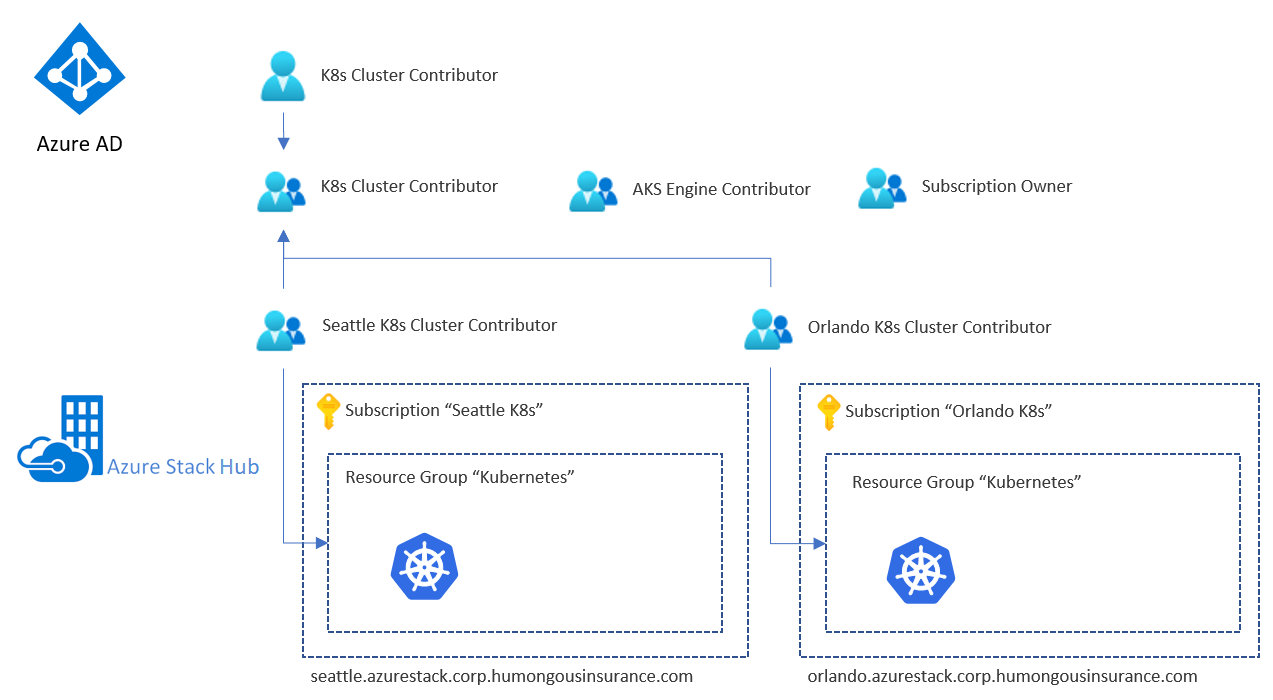
L'esempio contiene un gruppo dedicato (che usa AAD o ADFS) per uno scopo specifico, ad esempio per fornire le autorizzazioni di collaboratore per il gruppo di risorse che contiene l'infrastruttura del cluster Kubernetes in una specifica istanza dell'hub di Azure Stack (in questo caso "Seattle K8s Cluster Contributor"). Questi gruppi vengono quindi annidati in un gruppo generale che contiene i sottogruppi per ogni hub di Azure Stack.
L'utente di esempio avrà ora le autorizzazioni collaboratore per entrambi i gruppi di risorse che contengono l'intero set di risorse dell'infrastruttura Kubernetes. L'utente avrà accesso alle risorse in entrambe le istanze dell'hub di Azure Stack, perché tali istanze condividono lo stesso provider di identità.
Importante
Queste autorizzazioni hanno effetto solo sull'hub di Azure Stack e su alcune risorse distribuite insieme. Un utente con questo livello di accesso può provocare danni enormi, ma non può accedere alle VM IaaS di Kubernetes né all'API Kubernetes senza ulteriori autorizzazioni di accesso alla distribuzione di Kubernetes.
Identità di Kubernetes e controllo dell'accesso in base al ruolo
Per impostazione predefinita, un cluster Kubernetes non usa lo stesso provider di identità dell'hub di Azure Stack sottostante. Le VM che ospitano il cluster Kubernetes, i nodi master e i ruoli di lavoro usano la chiave SSH specificata durante la distribuzione del cluster. Questa chiave SSH è necessaria per connettersi a questi nodi tramite SSH.
L'API Kubernetes (ad esempio accessibile tramite kubectl) è protetta anche dagli account del servizio, incluso un account di amministratore del cluster predefinito. Le credenziali per questo account del servizio vengono inizialmente archiviate nel file .kube/config nei nodi master di Kubernetes.
Gestione dei segreti e credenziali dell'applicazione
Per archiviare segreti come le stringhe di connessione o le credenziali del database sono disponibili diverse opzioni, tra cui:
- Insieme di credenziali chiave di Azure
- Segreti di Kubernetes
- Soluzioni di terze parti come HashiCorp Vault (in esecuzione in Kubernetes)
Non archiviare segreti o credenziali in testo non crittografato nei file di configurazione, nel codice dell'applicazione o negli script e neanche in un sistema di controllo della versione. L'automazione della distribuzione dovrebbe recuperare i segreti se necessario.
Applicazione di patch e aggiornamenti
Il processo di applicazione di patch e aggiornamenti nel servizio Azure Kubernetes è parzialmente automatizzato. Gli aggiornamenti della versione di Kubernetes vengono attivati manualmente, mentre gli aggiornamenti della sicurezza vengono applicati automaticamente. Questi aggiornamenti possono includere correzioni di sicurezza del sistema operativo o aggiornamenti del kernel. Il servizio Azure Kubernetes non riavvia automaticamente i nodi Linux per completare il processo di aggiornamento.
Il processo di applicazione di patch e aggiornamenti per un cluster Kubernetes distribuito con il motore del servizio Azure Kubernetes nell'hub di Azure Stack non è gestito ed è di responsabilità dell'operatore del cluster.
Il motore del servizio Azure Kubernetes supporta le due attività più importanti:
- Aggiornamento a una nuova versione di Kubernetes e dell'immagine del sistema operativo di base
- Aggiornamento della sola immagine del sistema operativo di base
Le nuove immagini del sistema operativo di base contengono gli ultimi aggiornamenti di sicurezza e del kernel.
Il meccanismo di aggiornamento automatico installa automaticamente gli aggiornamenti della sicurezza rilasciati prima che sia disponibile una nuova versione dell'immagine del sistema operativo di base nel marketplace dell'hub di Azure Stack. L'aggiornamento automatico è abilitato per impostazione predefinita e installa automaticamente gli aggiornamenti della sicurezza, ma non riavvia i nodi del cluster Kubernetes. Il riavvio dei nodi può essere automatizzato tramite KUbernetes REboot Daemon (kured)). Kured controlla i nodi Linux che richiedono un riavvio, quindi gestisce automaticamente la ripianificazione del processo di riavvio dei nodi e dei pod in esecuzione.
Considerazioni sulla distribuzione (CI/CD)
Azure e l'hub di Azure Stack espongono le stesse API REST di Azure Resource Manager. Queste API vengono gestite come qualsiasi altro cloud di Azure (Azure, Azure China 21Vianet, Azure per enti pubblici). Potrebbero esserci differenze nelle versioni delle API tra i cloud, e l'hub di Azure Stack fornisce solo un sottoinsieme di servizi. Anche l'URI dell'endpoint di gestione è diverso per ogni cloud e per ogni istanza dell'hub di Azure Stack.
A parte le differenze minime citate, le API REST di Azure Resource Manager offrono un modo coerente per interagire con Azure e con l'hub di Azure Stack. Lo stesso set di strumenti può essere usato in questo caso come in qualsiasi altro cloud di Azure. Per distribuire e orchestrare i servizi nell'hub di Azure Stack, è possibile usare Azure DevOps, strumenti come Jenkins oppure PowerShell.
Considerazioni
Una delle principali differenze per quanto riguarda le distribuzioni dell'hub di Azure Stack è la questione dell'accessibilità a Internet. L'accessibilità a Internet determina se selezionare un agente di compilazione ospitato da Microsoft o self-hosted per i processi CI/CD.
Un agente self-hosted può essere eseguito nell'hub di Azure Stack (come VM IaaS) o in una subnet di rete che può accedere all'hub di Azure Stack. Per altre informazioni sulle differenze, vedere Agenti di Azure Pipelines.
L'immagine seguente aiuta a decidere se è necessario un agente di compilazione self-hosted o ospitato da Microsoft:
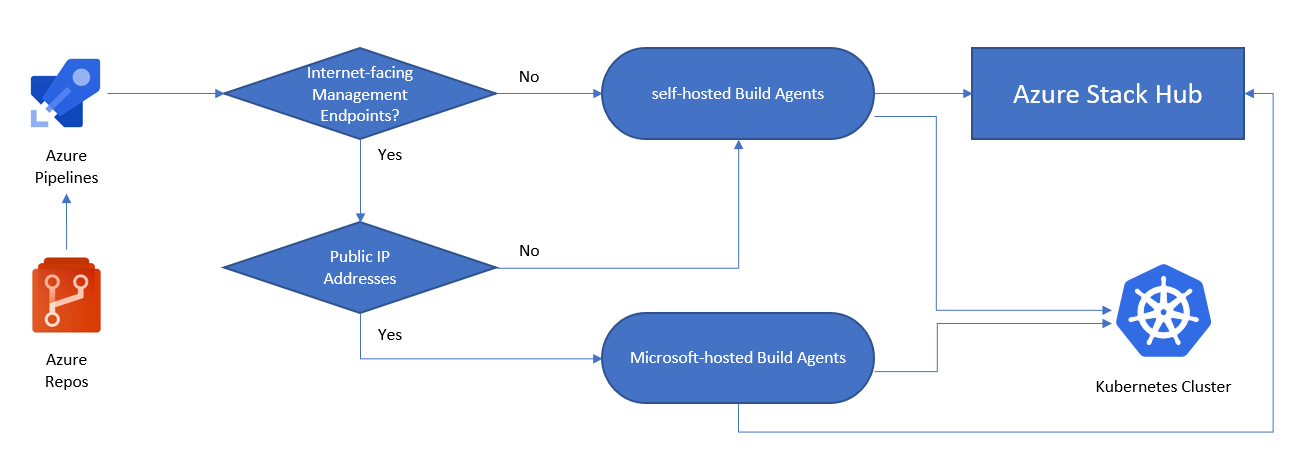
- Gli endpoint di gestione dell'hub di Azure Stack sono accessibili tramite Internet?
- Sì: è possibile usare Azure Pipelines con agenti ospitati da Microsoft per connettersi all'hub di Azure Stack.
- No: sono necessari agenti self-hosted in grado di connettersi agli endpoint di gestione dell'hub di Azure Stack.
- Il cluster Kubernetes è accessibile tramite Internet?
- Sì: è possibile usare Azure Pipelines con agenti ospitati da Microsoft per interagire direttamente con l'endpoint API di Kubernetes.
- No: sono necessari agenti self-hosted in grado di connettersi all'endpoint API del cluster Kubernetes.
Negli scenari in cui gli endpoint di gestione dell'hub di Azure Stack e l'API Kubernetes sono accessibili tramite Internet, per la distribuzione è possibile usare un agente ospitato da Microsoft. Questa distribuzione genera l'architettura dell'applicazione seguente:

Se gli endpoint di Azure Resource Manager, l'API Kubernetes o entrambi non sono direttamente accessibili tramite Internet, è possibile usare un agente di compilazione self-hosted per eseguire i passaggi della pipeline. Questa architettura richiede meno connettività e può essere distribuita con la sola connettività di rete locale negli endpoint di Azure Resource Manager e nell'API Kubernetes:

Nota
Informazioni sugli scenari disconnessi. Negli scenari in cui l'hub di Azure Stack, Kubernetes o entrambi non hanno endpoint di gestione con connessione Internet, è comunque possibile usare Azure DevOps per le distribuzioni. È possibile usare un pool di agenti self-hosted (ovvero un agente DevOps in esecuzione in locale o nell'hub di Azure Stack) o un istanza di Azure DevOps Server completamente self-hosted in locale. L'agente self-hosted deve avere solo connettività Internet HTTPS (TCP/443) in uscita.
Il modello può usare un cluster Kubernetes (distribuito e orchestrato con il motore del servizio Azure Kubernetes) in ogni istanza dell'hub di Azure Stack. Include un'applicazione costituita da un front-end, un servizio back-end di livello intermedio, ad esempio MongoDB, e un controller in ingresso basato su nginx. Invece di usare un database ospitato nel cluster K8s, è possibile sfruttare archivi dati esterni. Le opzioni di database includono MySQL, SQL Server o qualsiasi tipo di database ospitato all'esterno dell'hub di Azure Stack o in IaaS. Configurazioni come questa esulano dall'ambito di questo articolo.
Soluzioni partner
Sono disponibili soluzioni dei partner Microsoft che possono estendere le funzionalità dell'hub di Azure Stack. Queste soluzioni sono risultate utili nelle distribuzioni di applicazioni in esecuzione nei cluster Kubernetes.
Soluzioni di archiviazione e dati
Come descritto nella sezione Considerazioni su dati e archiviazione, l'hub di Azure Stack attualmente non include una soluzione nativa per replicare l'archiviazione tra più istanze. Diversamente da Azure, la funzionalità di replica dell'archiviazione tra più aree non esiste. Nell'hub di Azure Stack ogni istanza corrisponde a uno specifico cloud distinto. Sono tuttavia disponibili soluzioni dei partner Microsoft che consentono la replica dell'archiviazione tra hub di Azure Stack e Azure.
SCALITY
Scality offre archiviazione su scala Web che supporta aziende digitali dal 2009. Scality RING, la soluzione di archiviazione software-defined, trasforma i comuni server x86 in un pool di archiviazione illimitato per qualsiasi tipo di dati (file e oggetto) su scala petabyte.
CLOUDIAN
Cloudian semplifica l'archiviazione aziendale con una soluzione scalabile illimitata che consolida enormi set di dati in un singolo ambiente facilmente gestibile.
Passaggi successivi
Per altre informazioni sui concetti presentati in questo articolo, vedere:
- Scalabilità tra cloud e Modelli di app con distribuzione geografica nell'hub di Azure Stack.
- Architettura di microservizi nel servizio Azure Kubernetes.
Quando si è pronti a testare l'esempio di soluzione, continuare con la guida alla distribuzione del cluster a disponibilità elevata. Questa guida contiene istruzioni dettagliate per la distribuzione e il test dei componenti.