Eseguire un'applicazione a più livelli in più aree dell'hub di Azure Stack per la disponibilità elevata
Questa architettura di riferimento mostra un set di procedure comprovate per l'esecuzione in un'applicazione a più livelli di più aree dell'hub di Azure Stack, al fine di ottenere disponibilità e un'infrastruttura di ripristino di emergenza affidabile. In questo documento, Traffic Manager viene utilizzato per ottenere un'alta disponibilità, tuttavia, se Traffic Manager non è una scelta preferita nel vostro ambiente, si potrebbe anche sostituire con una coppia di bilanciatori del carico ad alta disponibilità.
Nota
Si noti che Gestione traffico usato nell'architettura seguente deve essere configurato in Azure e gli endpoint usati per configurare il profilo di Gestione traffico devono essere indirizzi IP instradabili pubblicamente.
Architettura
Questa architettura si basa su quella illustrata in 'applicazione a più livelli con SQL Server.
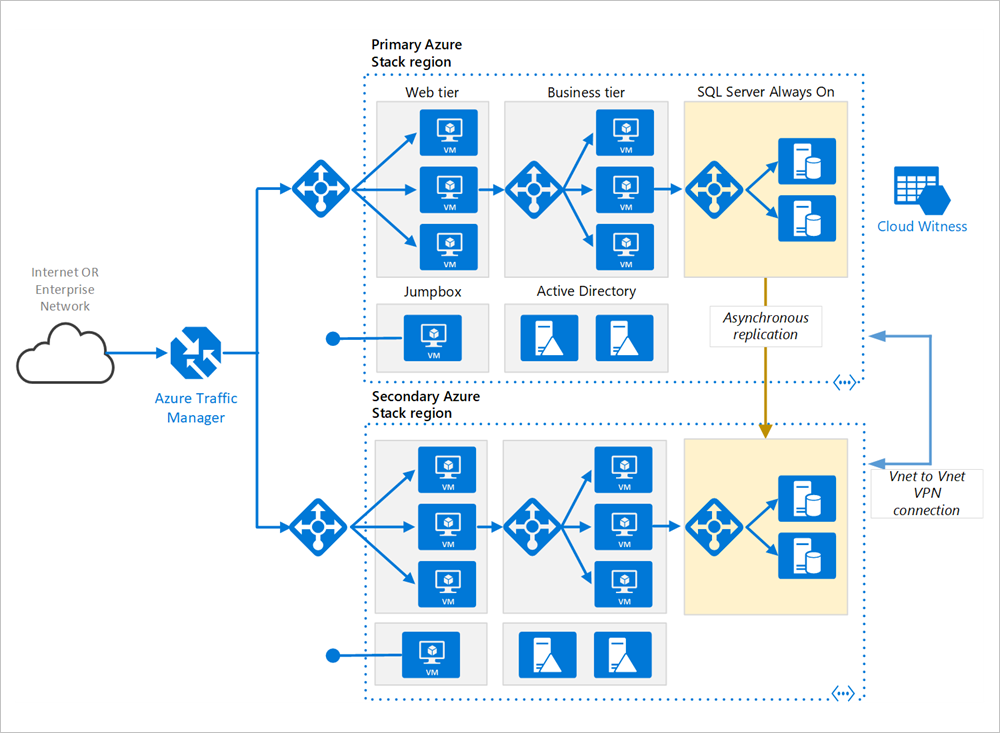
aree primarie e secondarie. Usare due aree per ottenere una disponibilità più elevata. Una è la regione primaria. L'altra regione è per il failover.
Gestione traffico di Azure. Gestore del traffico instrada le richieste in ingresso a una delle regioni. Durante le normali operazioni, instrada le richieste all'area primaria. Se tale area non è più disponibile, Gestione traffico esegue il failover nell'area secondaria. Per altre informazioni, vedere la sezione Configurazione di Gestione Traffico.
gruppi di risorse. Creare gruppi di risorse separati per l'area primaria, l'area secondaria. In questo modo è possibile gestire ogni area come singola raccolta di risorse. Ad esempio, è possibile ridistribuire una regione, senza arrestare l'altra. Collegare i gruppi di risorse, in modo da poter eseguire una query per elencare tutte le risorse per l'applicazione.
Reti virtuali. Creare una rete virtuale separata per ogni area. Assicurarsi che gli spazi degli indirizzi non si sovrappongano.
gruppo di disponibilità Always On di SQL Server. Se si usa SQL Server, è consigliabile gruppi di disponibilità AlwaysOn di SQL per la disponibilità elevata. Creare un singolo gruppo di disponibilità che includa le istanze di SQL Server in entrambe le aree.
connessione VPN da VNET a VNET. Poiché il peering VNET non è ancora disponibile nell'hub di Azure Stack, usare la connessione VPN da rete virtuale a rete virtuale per connettere le due reti virtuali. Per ulteriori informazioni, vedere da rete virtuale a rete virtuale nell'Azure Stack Hub.
Consigli
Un'architettura in più aree può offrire una disponibilità più elevata rispetto alla distribuzione in una singola area. Se un'interruzione a livello di area influisce sull'area primaria, è possibile usare Traffic Manager per eseguire il failover nell'area secondaria. Questa architettura può essere utile anche se un singolo sottosistema dell'applicazione ha esito negativo.
Esistono diversi approcci generali per ottenere la disponibilità elevata tra aree:
Attivo/passivo con standby attivo. Il traffico passa a una regione, mentre l'altra è in attesa di emergenza. Hot standby indica che le macchine virtuali nell'area secondaria vengono allocate e in esecuzione in qualsiasi momento.
attivo/passivo conriserva a freddo. Il traffico passa a una regione, mentre l'altra attende in standby a freddo. Standby freddo indica che le macchine virtuali nell'area secondaria non vengono allocate fino a quando sono necessarie per il failover. Questo approccio costa meno per l'esecuzione, ma in genere richiederà più tempo per essere online durante un errore.
attivo/attivo. Entrambe le aree sono attive e le richieste vengono bilanciate tra di esse. Se un'area non è più disponibile, viene estratta dalla rotazione.
Questa architettura di riferimento è incentrata su attivo/passivo con hot standby, usando Gestione traffico per il failover. Puoi distribuire un numero contenuto di macchine virtuali per standby attivo, e poi espandere la infrastruttura secondo necessità.
Configurazione del Gestore del traffico
Quando si configura Gestione traffico, tenere presente quanto segue:
Routing. Il Gestore del Traffico supporta diversi algoritmi di instradamento . Per lo scenario descritto in questo articolo, usare routing con priorità (in precedenza denominato routing failover). Con questa impostazione, Gestione traffico invia tutte le richieste all'area primaria, a meno che l'area primaria non diventi non raggiungibile. A questo punto, esegue automaticamente un failover nell'area secondaria. Vedere Configurare il metodo di routing del failover.
sonda di salute. Traffic Manager utilizza una probe HTTP (o HTTPS) per monitorare la disponibilità di ogni regione. Il probe verifica la presenza di una risposta HTTP 200 per un percorso URL specificato. Come miglior pratica, creare un endpoint che segnala l'integrità complessiva dell'applicazione e utilizzare questo endpoint per la sonda di integrità. In caso contrario, la sonda potrebbe segnalare un endpoint integro quando le parti critiche dell'applicazione stanno effettivamente fallendo. Per ulteriori informazioni, consulta il modello di monitoraggio degli endpoint della salute .
Quando il Gestore del Traffico esegue il failover, si verifica un periodo di tempo in cui i client non riescono a raggiungere l'applicazione. La durata è influenzata dai fattori seguenti:
Il controllo di stato deve rilevare che la regione primaria è diventata irraggiungibile.
I server DNS devono aggiornare i record DNS memorizzati nella cache per l'indirizzo IP, che dipende dal time-to-live (TTL) DNS. Il valore TTL predefinito è 300 secondi (5 minuti), ma è possibile configurare questo valore quando si crea il profilo di Gestione traffico.
Per informazioni dettagliate, vedere Informazioni sul monitoraggio di Traffic Manager.
Se si verifica un failover di Traffic Manager, consigliamo di eseguire un failback manuale anziché implementare un failback automatico. In caso contrario, è possibile creare una situazione in cui l'applicazione passa da un'area all'altra. Verificare che tutti i sottosistemi dell'applicazione siano integri prima del failback.
Si noti che Gestione traffico esegue automaticamente il failback per impostazione predefinita. Per evitare questo problema, abbassare manualmente la priorità dell'area primaria dopo un evento di failover. Si supponga, ad esempio, che l'area primaria sia priorità 1 e l'area secondaria sia priorità 2. Dopo un failover, impostare l'area primaria sulla priorità 3 per impedire il failback automatico. Quando si è pronti per passare, tornare indietro, aggiornare la priorità su 1.
Il seguente comando dell'interfaccia della riga di comando di Azure aggiorna la priorità.
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type externalEndpoints --priority 3
Un altro approccio consiste nel disabilitare temporaneamente l'endpoint fino a quando non si è pronti a eseguire il failback:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type externalEndpoints --endpoint-status Disabled
A seconda della causa di un failover, potrebbe essere necessario ridistribuire le risorse all'interno di un'area. Prima di eseguire il failback, eseguire un test di prontezza operativa. Il test deve verificare gli elementi seguenti:
Le macchine virtuali sono configurate correttamente. (Tutto il software necessario è installato, IIS è in esecuzione e così via).
I sottosistemi dell'applicazione sono integri.
Test funzionali. Ad esempio, il livello di database è raggiungibile dal livello Web.
Configurare i gruppi di disponibilità AlwaysOn di SQL Server
Prima di Windows Server 2016, i gruppi di disponibilità AlwaysOn di SQL Server richiedono un controller di dominio e tutti i nodi del gruppo di disponibilità devono trovarsi nello stesso dominio di Active Directory (AD).
Per configurare il gruppo di disponibilità:
Inserire almeno due controller di dominio in ciascuna area.
Assegnare a ogni controller di dominio un indirizzo IP statico.
Creare VPN per abilitare la comunicazione tra due reti virtuali.
Per ogni rete virtuale, aggiungere gli indirizzi IP dei controller di dominio (da entrambe le aree) all'elenco dei server DNS. È possibile usare il comando dell'interfaccia della riga di comando (CLI) seguente. Per altre informazioni, vedere Modificare i server DNS.
az network vnet update --resource-group <resource-group> --name <vnet-name> --dns-servers "10.0.0.4,10.0.0.6,172.16.0.4,172.16.0.6"Creare un cluster Windows Server Failover Clustering (WSFC) che include le istanze di SQL Server in entrambe le aree.
Creare un gruppo di disponibilità AlwaysOn di SQL Server che include le istanze di SQL Server nelle aree primarie e secondarie. Per i passaggi, vedere l'estensione del gruppo di disponibilità AlwaysOn al data center di Azure remoto (PowerShell).
Inserire la replica primaria nell'area primaria.
Inserire una o più repliche secondarie nell'area primaria. Configurarle in modo da usare il commit sincrono con failover automatico.
Inserire una o più repliche secondarie nell'area secondaria. Configurarli in modo da usare commit asincrono, per motivi di performance. In caso contrario, tutte le transazioni T-SQL devono attendere il tempo di andata e ritorno sulla rete verso l'area secondaria.
Nota
Le repliche di commit asincrono non supportano il failover automatico.
Considerazioni sulla disponibilità
Con un'app complessa a più livelli, potrebbe non essere necessario replicare l'intera applicazione nell'area secondaria. È invece possibile replicare semplicemente un sottosistema critico necessario per supportare la continuità aziendale.
Gestione traffico è un possibile punto di errore nel sistema. Se il servizio Gestione traffico non riesce, i client non possono accedere all'applicazione durante il tempo di inattività. Esaminare il contratto di servizio di Gestione traffico e determinare se l'uso di Gestione traffico da solo soddisfa i requisiti aziendali per la disponibilità elevata. In caso contrario, prendere in considerazione l'aggiunta di un'altra soluzione di gestione del traffico come sistema di backup. Se il servizio Gestione del traffico Azure fallisce, modificare i record CNAME nei DNS per puntare all'altro servizio di gestione del traffico. Questo passaggio deve essere eseguito manualmente e l'applicazione non sarà disponibile fino a quando non vengono propagate le modifiche DNS.
Per il cluster SQL Server, esistono due scenari di failover da considerare:
Tutte le repliche di database di SQL Server nell'area primaria hanno esito negativo. Ad esempio, questo problema può verificarsi durante un'interruzione a livello di area. In tal caso, è necessario eseguire manualmente il failover del gruppo di disponibilità, anche se il Gestore del traffico esegue automaticamente il failover sul front-end. Seguire i passaggi descritti in Eseguire un failover manuale forzato di un gruppo di disponibilità di SQL Server, che descrive come eseguire un failover forzato usando SQL Server Management Studio, Transact-SQL o PowerShell in SQL Server 2016.
Traffic Manager effettua il failover nell'area secondaria, ma la replica primaria del database di SQL Server è ancora disponibile. Ad esempio, il livello front-end potrebbe non riuscire, senza influire sulle macchine virtuali di SQL Server. In tal caso, il traffico Internet viene instradato all'area secondaria e tale area può comunque connettersi alla replica primaria. Tuttavia, ci sarà una maggiore latenza, perché le connessioni di SQL Server passano tra aree. In questo caso, è consigliabile eseguire un failover manuale come indicato di seguito:
Passare temporaneamente una replica del database SQL Server nell'area secondaria a commit sincrono . In questo modo non si verifica alcuna perdita di dati durante il failover.
Eseguire failover su quella replica.
Quando esegui il failback nell'area primaria, devi ripristinare il commit asincrono.
Considerazioni sulla gestibilità
Quando si aggiorna la distribuzione, aggiornare un'area alla volta per ridurre la probabilità di un errore globale da una configurazione non corretta o da un errore nell'applicazione.
Testare la resilienza del sistema in caso di errori. Ecco alcuni scenari di errore comuni da testare:
Spegnere le istanze di macchina virtuale.
Risorse sotto pressione, come CPU e memoria.
Disconnettere/ritardare la rete.
Processi di crash.
Scadenza dei certificati.
Simulare gli errori hardware.
Arrestare il servizio DNS nei controller di dominio.
Misurare i tempi di ripristino e verificare che soddisfino i requisiti aziendali. Testare anche le combinazioni di modalità di errore.
Passaggi successivi
- Per altre informazioni sui modelli cloud di Azure, vedere Modelli di progettazione cloud.