AlwaysOn: Challenges with statistics on ReadOnly database, Database Snapshot and Secondary Replica
I am sure you all have dealt with situations when the statistics on one or more columns is either missing or not up-to date. When user submits a query for execution, the SQL Server goes through logical (simplifying or restructuring a query) and physical optimization that considers various query plans based on statistical information and then picks the one that has the least estimated cost. The key to physical optimization is the accurate estimation of data distribution (i.e. statistical information) of the input tables and intermediate results (e.g. output of JOIN operator). When optimizing a query, the optimizer generates, the statistical information on one or more tables/indexes, if not available and auto-stats has not been explicitly disabled by the user. It uses statistics generate the optimized query plan. It is not recommended to generate a query plan without the statistics because you may end up with a sub-optimal plan that can take many orders of magnitude longer to execute. There are customer reported cases where a good query plan allows a query execution to complete in minutes while a bad query plan can take hours.
The challenge for readable secondary is that that statistical information cannot be created or updated as this will amount to modifying the data on the secondary replica in the context of a read-only access. One common question that comes up in the context of readable secondary is ‘if the statistics created on the primary replica are automatically available on the secondary replica, why do I care about creating/updating statistics on the secondary?’ While it is true that any statistics that is created on the primary replica is automatically available on the secondary replica however the queries that you will run on the secondary replica are, in all likelihood, very different than the ones you run on the primary replica. For this reason, the statistics may either be missing or possibly stale when a query is run on the secondary replica. Interestingly, this issue is not limited to readable secondary. You can experience the same issues on a database snapshot or to a lesser degree on databases that are marked as read-only. The reason I say is to a lesser degree for read-only databases is because, in theory, a customer can mark a database read-only after creating all possible statistical information and since the data never changes, there will never be stale statistics. However, in reality, it is hard to predict what read-only workload will be executed which can lead to poor execution plan due to missing statistical information.
Example: Here is one example that illustrates this issue using a Read-Only database
create database test
go
use test
go
create table t1 (c1 int, c2 int, c3 char (50))
go
create nonclustered index t1_nci on t1(c1)
go
-- show statistics
select * from sys.stats where object_id = object_id('t1')

If you look at the stats, it will show 1 statistics that got created as part of creating an index. Note, it shows that there are 0 rows as you would expect.
-- show the statistics
dbcc show_statistics('t1', 't1_nci')

Now, let us insert 1 row into the table
--insert 1 row
insert into t1 values (1,1,'hello')
-- show the statistics
dbcc show_statistics('t1', 't1_nci')

You will notice that the above statistics does not show that a new row has been inserted. The reason is that statistics are not automatically updated when one or more rows are inserted. The statistics are updated either using an explicit command to update them or automatically if needed by optimizer assuming the compute threshold has been crossed. Let us now do a query that requires statistics on the T1.C1 and then re-check the statistics as follows
--do a simple select and show the query plan
select c2 from t1 where c1 between 1 and 20
-- show the statistics
dbcc show_statistics('t1', 't1_nci')
Here is the output. You will notice that the statistics now shows that there is now 1 row

Another interesting thing to note here is to see the query plan. Note, that optimizer chooses a table scan because it has determined that if there is only 1 row, it is cheaper to scan the table instead of going through the non-clustered index.

So far so good. Now, let us insert 10,000 rows into table T1 and then mark the database as ReadOnly.
declare @i int = 0
while ( @i < 10000)
begin
insert into t1 values (@i, @i+100000, 'sunil')
set @i = @i + 1
end
ALTER DATABASE [test] SET READ_ONLY WITH NO_WAIT
GO
Now let us do the query and see the statistics.
--do a simple select and show the query plan
select c2 from t1 where c1 between 1 and 20
-- show the statistics
dbcc show_statistics('t1', 't1_nci')

The statistics still shows that there is only 1 row even though we had inserted 10000 rows before marking the database as read-only. The reason is that before the database was marked read-only, we did not issue any query that would have required statistics on column C1 therefore the statistics could not be updated.
If you look at the query plan, it still shows the table scan. Clearly, this would be very inefficient plan as it will require a table scan checking each row that meets the search predicate. This is the key problem with read-only database or for that matter with database snapshot for if the statistics were either stale, as in the case here, or missing, optimizer will not be able to generate an efficient plan. The only recourse will be mark the database as R/W and update/create the statistics before marking it read-only but it is not really practical. You could get away with this limitation if you knew in advance all possible queries that will be run against this read-only database or you create the statistics on all columns of all tables. As you can see that this can take significant time for large databases computing statistics that may never be needed. This becomes even more impractical for database snapshot.
Just for the kicks, let us now mark the database as R/W and re-issue the same query and look at the query plan. As you might have guessed, in this case, the optimizer chose the non-clustered index.
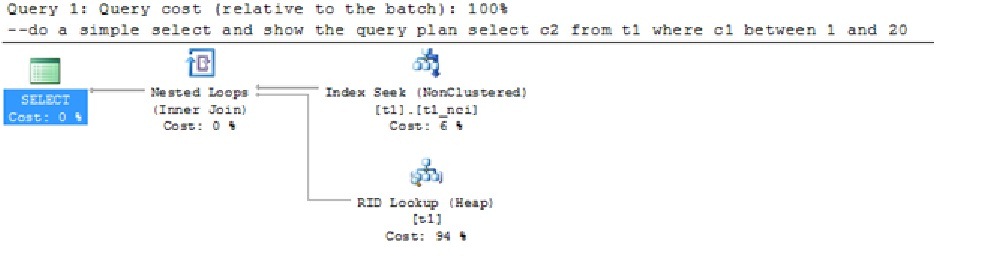
Now that you understand the issue, you will be happy to know that you will never run into stale or missing statistics when running queries on readable secondary. For details, please refer to https://blogs.msdn.com/b/sqlserverstorageengine/archive/2011/12/22/alwayson-making-upto-date-statistics-available-on-readable-secondary-read-only-database-and-database-snapshot.aspx. As an added bonus, we have applied the same solution for Read-Only database and database snapshot independent of whether these databases are used in the context of AlwaysOn or not.
Thanks
Sunil Agarwal
Comments
Anonymous
November 23, 2013
Great article :)Anonymous
December 13, 2016
So you mean once the db is set to read only, the statistics will not be updated any more on it, right? Even for a always on secondary replica DB? So we have to create a schedule job to make update the statistics on the primary DB, then it will be sync to the secondary one automatically? Right?