Service Manager Data Warehouse Troubleshooting
There are some great articles out there which talk about troubleshooting the Data Warehouse. In this article I will be going into explaining the internals of the Data Warehouse along with troubleshooting information.
It is important to first of all understand how the DW Jobs work. There are some Jobs that are only visible by looking into the database, others may be seen in PowerShell only and the most basic ones can be seen in the Console. From the perspective of the databases, the DW Jobs are actually called Processes. From now on, I will refer to the DW Jobs as Processes in this article.
The DW Processes are actually categorized like this:
- Process Categories - this is top level way of categorizing Processes (Jobs)
- Processes - these are the actual Processes that exist (ex. DWMaintenance, MPSyncJob, Extract, Transform, Load, etc.)
- ProcessModules - each Process has several ProcessModules which it will actually execute in order to "finish" - there is also a certain order in which these will run depending on dependencies on one another and the level of the modules
Now what you need to know is that each Process will be executed via a Schedule which is actually a Rule (Workflow that runs on a schedule and starts its owning Process). When a Process is scheduled (for execution) it will actually get a new Batch created. Think of a Process as a class and of a Batch as an instance of that class that is actually doing something. It is the same for a ProcessModule, each will get a WorkItem when it is scheduled for execution. Because a Process can have from one to many ProcessModules, when a Batch is created, it also gets all the WorkItems associated with it (ProcessModules of the Process).
So, to recap, because we will be using these a lot in this article:
- Batch = an instance of a Process (which in the Console or PowerShell is a Job)
- WorkItem = an instance of a ProcessModule of a Process
Important to know and also the way the processing/execution will depend on and work, is that each Batch, as well as each WorkItem (of a Batch) will have a certain Status :
- Success (1) - the Batch/WorkItem was successful and at that point the actual Status gets changed to Complete
- Failed (2) - there was an error in the Batch/WorkItem and it will be retried on the next execution
- Not Started (3) - the Batch/WorkItem was scheduled for execution and it will be executed on the next interval (schedule) - this is a good Status, it means there was no error and it will run the next time it needs to
- Running (4) - the Batch/WorkItem is currently running
- Stopped (5) - the Batch/WorkItem was stopped (by the user from the Console - Suspend or PowerShell Stop-SCDWJob )
- Completed (6) - the Batch/WorkItem has successfully completed without any errors
- Waiting (7) - the Batch/WorkItem is waiting for other Batches/WorkItems to finish first on which they are dependent
It is important to know that the actual Status is important for the WorkItems, because the Batch Status depends directly on the Statuses of its WorkItems - here are some examples:
- A Batch can have the Status set to Running while all its WorkItems still have the Status of Not Started => this is not a bad thing, it just means that the certain Batch has received a "start request" from the schedule, but the (first) WorkItem(s) cannot run yet because they are waiting on another Batch/WorkItem (of a different Process) to finish first
- If one of the WorkItems of a Batch will fail and have a Status of Failed, then the Batch itself will get the Status of Failed => all WorkItems need to complete successfully and thus have a Status of Completed for the Batch to also get the Status of Completed
When a Process gets created the first time (on installation or DW registration), a new Batch will be created with some BatchId (the newest one possible - starting from 1 - for the first Process). Then for each ProcessModule of this Process, a new WorkItem with a certain WorkItemId will get created for this corresponding Batch. This will all initially have the Status of Not Started and when the corresponding Schedule Rule will reach it schedule it will send a "start request" for it's Batch. This will set the Status of that Batch to Running. The actual way how these run is that there is a Rule associated with each Process and these Rules run every 30 seconds. As soon as such a Rule runs, if it sees that its corresponding Process has the (latest) Batch with a Status of Running, will take the first/next WorkItem that has a Status of Not Started (depending on dependencies and level) and will try to execute that WorkItem. If it can execute and it is successful, it will get the Status of Completed once it finishes. If it fails, then it will get the Status of Failed. It is important to know here, that it can and will get a Status of Failed also without there being an actual error - but rather it cannot start/run right now because a dependent WorkItem is not finished yet and thus the "error" is actually "waiting on workitems to finish".
Another very important thing to know is that there is also a certain synchronization method between the different Processes, so that they don't interfere with each others work. This is needed because there are some actions which change the database(s) schema, add/remove columns from tables, indexes, primary/foreign keys, etc. We would not want the ETL (Extract, Transform, Load) Processes to run and copy/transform data while we are doing such changes. Because of this, we have these implementations:
- When the DWMaintenance and/or MPSyncJob Processes start running, the first thing they will do, is disable the ETL (Extract, Transform, Load) Processes => it is very important to note here that if either of the ETL Processes will be running when they will get disabled, these will *still* show the Status of Running, but in reality they will not run because they get disabled.
- Because DWMaintenance and MPSyncJob Processes should also not be running at the same time, these use a locking mechanism - whichever of them gets this lock first will be allowed to run until it finishes (Status of Completed) while the other one will remain waiting for it to finish, even if the Status will still show as Running and even if it will *not* be directly disabled => there is a table in the DWStagingAndConfig database used for holding the lock which you can look at - it is called LockDetails.
I have talked about some "invisible" Jobs which can only be seen by querying the database. There are actually a lot of those, but the "real" way to talk about them, is to go back to the Process Categories. There is a very important Process Category here which needs to be mentioned, which is the Deployment category. This is invisible because the MPSyncJob actually takes care handing work over this this category. MPSyncJob will associate Management Packs from one data source to another (ex. from CMDB to the DW). Each Management Pack that got associated will get a new Job (Process) created for it which falls under the Deployment Process Category. We can also refer to this as the "Deployment Job" if you will - and if fact, this is how you would usually hear about this. These are responsible for *actually* deploying (or installing if you will) the Management Packs which were synchronized over - without this, nothing would work because we would have no extended information in the Data Warehouse about what Classes, Relationships, etc. we have in the CMDB (and other managed data sources which we can register to the Data Warehouse).
If either of the deployment "jobs" fail or are not yet finished, then you can be more or less sure that nothing will work properly and you will 99% get errors related to either of the ETL (Extract, Transform, Load) Processes and maybe not only those - depending on where deployment is at that point.
While any of the Deployment Processes will follow the same rules as the others, that is get a Batch and one to many WorkItems, it also has another way of actually making the deployment. Each such Deployment Process (for each Management Pack) will have a new DeploySequence created (with a DeploySequenceId). Because each Management Pack has one to many "items" (Classes, Relationships, etc.) which need to be deployed, for each DeploySequence we will have one to many DeployItems created. This is important information for when you get into the actual troubleshooting part in the database.
In case you are not familiar with the basics of troubleshooting the DW Jobs from PowerShell, I suggest first starting with this article: https://technet.microsoft.com/en-us/library/hh542403.aspx
Also, if you are not familiar with what the ETL (Extract, Transform, Load) Jobs are and how these work, I suggest reading this article as well: https://blogs.technet.com/b/servicemanager/archive/2009/06/04/data-warehouse-anatomy-of-extract-transform-load-etl.aspx
Remember to always start by checking if there are any Management Packs where they Deployment Status shows as Failed in the SvcMgr Console in the Date Warehouse tab under the Management Packs view. For any such Management Pack which is Failed, you should run the "Restart Deployment" task from the Console in the tasks pane. If you are lucky, it was just some timeout or deadlock and it will succeed this time. If not, then you can always see errors about this failure as well as any other failures in the DW Jobs by looking into the Operations Manager event log directly on the SvcMgr Data Warehouse Management Server (filter by sources: Data Warehouse and Deployment).
Additionally, you can try to force reset the DW Jobs and run them in a certain order by using the script from this article: https://blogs.technet.com/b/mihai/archive/2013/07/03/resetting-and-running-the-service-manager-data-warehouse-jobs-separately.aspx
The Data Warehouse database which we are interested in when troubleshooting the DW Jobs is the DWStagingAndConfig database. Here is a list of tables of interest when troubleshoot the DW Jobs and at the end, also a file attached with useful sql queries:
1. The Infra.ProcessCategory table is where all the existing Process Categories are stored. It has a column called IsEnabled which needs to be 1 in order for any Process under this Process Category to be able to run - this is only modified (0 and 1) by the DWMaintenance and/or MPSyncJobs when they run - this is how they disable the other Processes.

2. The Infra.Process table is where all existing Processes are available and classified on Process Categories via the ProcessCategoryId column. These also have a IsEnabled column which should always be 1 in order for them to be able to execute. The only reason why either of these would have IsEnabled set to 0 is if anyone explicitly disabled these by using the Disable-SCDWJob CMDLet, which should never be done. To disable a Process (Job) always disable only its Schedule by using Disable-SCDWJobSchedule . In the screenshot below, I have explicitly filtered for only the "common" Processes, but if you will query the entire table, you will see all of them.

3. The Infra. ProcessModule table is where all existing ProcessModules are located and are classified on each Process via the ProcessId column. That is what you should use in a where clause of a sql query to see all ProcessModules that belong to a certain Process. Here is an example in the screenshot below for all ProcessModules of the DWMaintenance Process. These are not "ordered" in this result - if you want to figure out the "order" in which they would run, you need to check out the ModuleLevel column along with each dependency for each module which can be seen in the Infra.ModuleTriggerCondition table.

4. The Infra. Batch table is where all the Batches will be found (current/previous and next - check out Infra.BatchHistory for a history of these). This is where you will be able to see the BatchIds for the Processes and you can view them for a specific Process by using the ProcessId in a sql where clause. In the example screenshot below, we can see the Batches of the time the screenshot was taken for the Process with ProcessId = 1 (which in this case is the DWMaintenance Process).

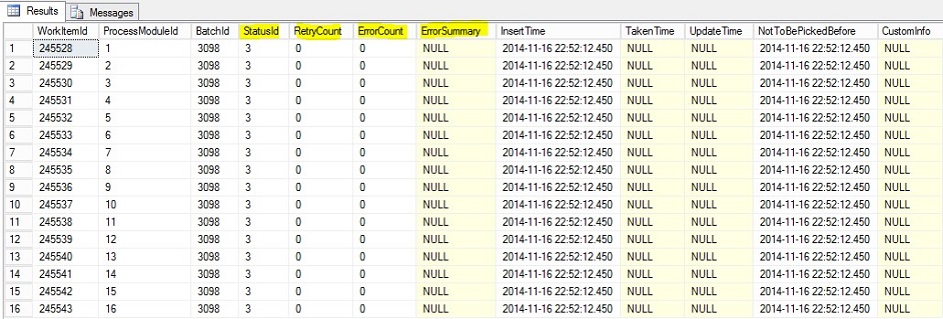
5. The Infra. WorkItem table is where all the WorkItems of a Batch will be found. The most important part here is that this table is where we can see any errors for failed WorkItems of a Batch (that is an instance of a certain Process). In the screenshot below, an example of the WorkItems of the Batch with BatchId 3098 that is an instance of the DWMaintenance Process.
6. The DeploySequence table where we have an entry for each DeploySequence (so each MP that is or was deployed). You should know that in this process, a staging table is used which is called DeploySequenceStaging and if deployment finished and was successful, then this staging table should be *empty*. Here is a screenshot (not all results) of how this looks like.

7. The DeployItems table where we store an entry for each DeploySequence (so each MP that is or was deployed). You should know that in this process, a staging table is used which is called DeployItemStaging and if deployment finished and was successful, then this staging table should be *empty*. Here is a screenshot with the list of DeployItems belonging to the DeploySequence of the System.WorkItem.Incident.Library Management Pack.

In addition to that, you can always use SQL Server Profiler to get detailed information about what queries are being executed, details into different errors that might happen and of course having the queries, also a possibility of understanding the "why" behind them. The most useful column on which you can filter on is the ApplicationName column a the trace. These are the various application names used by the DW Jobs processing modules:
- DW Jobs scheduling, execution and processing: SC DAL--Orchestration and SC DAL--SCDW
- DWMaintenance job: SC DAL--Maintenance
- MPSync job: SC DAL--MP Sync
- Extract jobs: SC DAL--SCDW Extract Module
- Transform job: SC DAL--SCDW Transform Module
- Load jobs: SC DAL--SCDW Load Module
- Cube related jobs: Microsoft SQL Server Analysis Services (and general troubleshooting of SQL Analysis Services – Application event log and SQL Analysis Services tracing)
A cool template I usually use for the SQL Profiler Trace which is in 99% of the cases enough, has these settings (events and columns):

NOTE: Attached, you will also find a file (DWJobs_sql_queries.sql) that contains (commented) useful sql queries which you can and should use when troubleshooting the DW Jobs.
Good hunting! :)
Comments
Anonymous
January 01, 2003
First time more insight into the DW architecture beyond what Travis disclosed in 2009!. This actually increases the confidence on the solution. I need at one customer site to have DW also have work items history (missing in default configuration because its huge amount of data). i achieved that through learning from forums. But i could not found anything concrete as reference either on MSDN or TechNet which explains Management pack language for DW in detailed. Also the DW schema is only available for 2010 version still ?. Not for 2012 so Service Requests and all those details, you have to hit and try to get.
Any clue to such documentation would be highly appreciated, and should be rather available atleast to us as MS partnersAnonymous
January 01, 2003
Shahid, check out this example and explanation on how to extend the DW (get new/custom data in from the CMDB):http://blogs.technet.com/b/servicemanager/archive/2013/07/15/extending-the-data-warehouse-and-reporting-for-unix-computers.aspx
More explanations here in the "Extending the Service Manager Data Warehouse" section:http://social.technet.microsoft.com/wiki/contents/articles/15608.system-center-service-manager-data-warehouse-and-reporting.aspx
There's also a cool tool which you can use to create these extensions from a UI - you could then of course also look at the MP definition to understand more:http://www.scutils.com/products/dwmpcreatorAnonymous
January 01, 2003
Hello Mihai,
Thank you for posting details above. In my SCSM 2012 environment, every week the cube jobs are failing and on resetting the DB the DW jobs for cubes are going in to failed state. Is this often that cube jobs failing ? How do we can start what is causing the fail?
Thx..Anonymous
January 01, 2003
happy to help Shahid! :DAnonymous
January 01, 2003
Hey Shahid, if you give me more details about what you need, I'll be glad to help :D
Are you referring to the localization information and how/where that is transported into the DW?Anonymous
January 01, 2003
@Nishantrajmitra: this has a specific reason which you can see from the Operations Manager event log or directly check the error in the Infra.WorkItem table. If you don't get around it, I suggest opening a case with MS. Also, it is important to know that if we simply rebuild the Cubes, it has NO data-loss and is usually the fastest/easiest way to solve Cube issues. Here is a very cool guide a friend wrote on how to do that: http://blogs.technet.com/b/thomase/archive/2014/11/24/how-to-rebuild-your-analysis-database.aspx
@Roman: if I remember correctly, it should be the etl.CreateBatch stored procedure - you could take a SQL Profiler Trace and check it out. It should get created after a Batch has finished - we will create a new Batch (status = Not Started) after the "current" Batch has finished (status = Completed).Anonymous
January 01, 2003
Fantastic work, as always mate :-)Anonymous
January 01, 2003
Hi Mahai, thank for help offer.
I am trying to load all work items history to DW for reporting and audit purposes for IT audit. So that they check to see the work item changes in future also. DW keeps data for like 3 years. That's one requirement.
2nd is to copy all service requests additional data inputs also moved to DW for reporting on the same for extended duration.
I need reference on how to make DW management packs to ETL/export this data continuously from SCSM mg to DW!!!!Anonymous
January 01, 2003
Thanks Mihai, that really helped. I really appreciate that. thank you. I could find the missing pieces due to which I was stranded and now I am done with your direction!!!!!Anonymous
January 01, 2003
Mihai Thanks For this information. We all appreciate the effort and time you invested doing this great Article. Thank you so much.Anonymous
November 26, 2014
excellent !Anonymous
December 01, 2014
Mihai Sarbulescu has yet again written a very detailed blog post, this time on troubleshooting the DataAnonymous
December 08, 2014
Mihai Sarbulescu a posté un article détaillé sur le dépannage du serveur Data Warehouse de System Center Service Manager.
Pour plus d'informations: http://blogs.technet.com/b/mihai/archive/2014/11/25/service-managerAnonymous
December 08, 2014
Mihai Sarbulescu a posté un article détaillé sur le dépannage du serveurAnonymous
December 11, 2014
Hi Mihai !
I read the article and need to say - GREAT JOB !
It would be great to learn also which process creates a new batch+workitems after a Batch/Workitem module has finished. Can you explain / direct me to info where this is described ?
Thanks / RomanAnonymous
August 09, 2016
Great Job Mihai!Anonymous
December 13, 2016
The comment has been removedAnonymous
January 05, 2017
Very interesting read, always helps to see this from a fresh perspective! I'm trying to use SQL profiler more as part of my troubleshooting and appreciate you wrapping up such a thorough explanation by reminding us that you can always just run a trace!