Machine Learning para principiantes – Capítulo 6: prediciendo el futuro
Ahora que hemos mejorado el modelo, es hora de aprovecharlo para predecir la valoración (Player Efficiency Rating) de los jugadores de la NBA en la próxima temporada. En este punto, todo lo que hemos creado es el experimento de entrenamiento, el que prepara los datos y entrena un modelo con datos históricos.
Vamos a llevarlo al siguiente nivel creando el experimento predictivo basado en el algoritmo que mejor funcionó después de los ajustes, la Neural Network Regression. Tendremos que configurar el Servicio Web predictivo, para que podamos usarlo como un módulo en Azure ML Studio o como un endpoint al que pedirle predicciones con algunos datos de entrada a través de una petición HTTP.
Para configurar el servicio web, selecciona el modulo "Train Model" conectado al algoritmo de Neural Network Regression (el que mejor rendimiento tuvo), busca el botón "SET UP WEB SERVICE" en la barra inferior y haz click en "Predictive Web Service [Recommended]" en el mini pop-up que aparece:
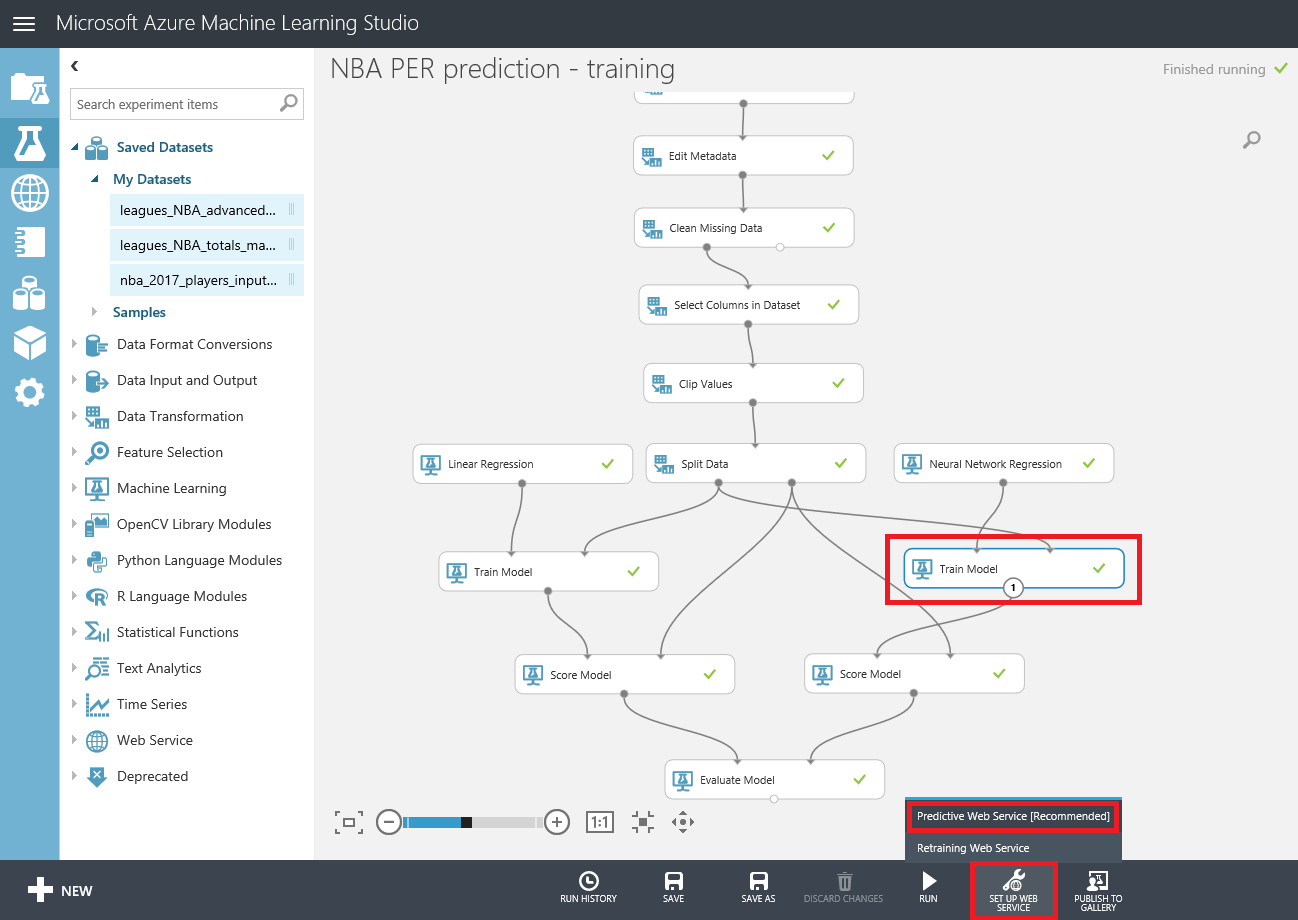
Una vez hecho esto, podrás ver algo parecido a lo siguiente:
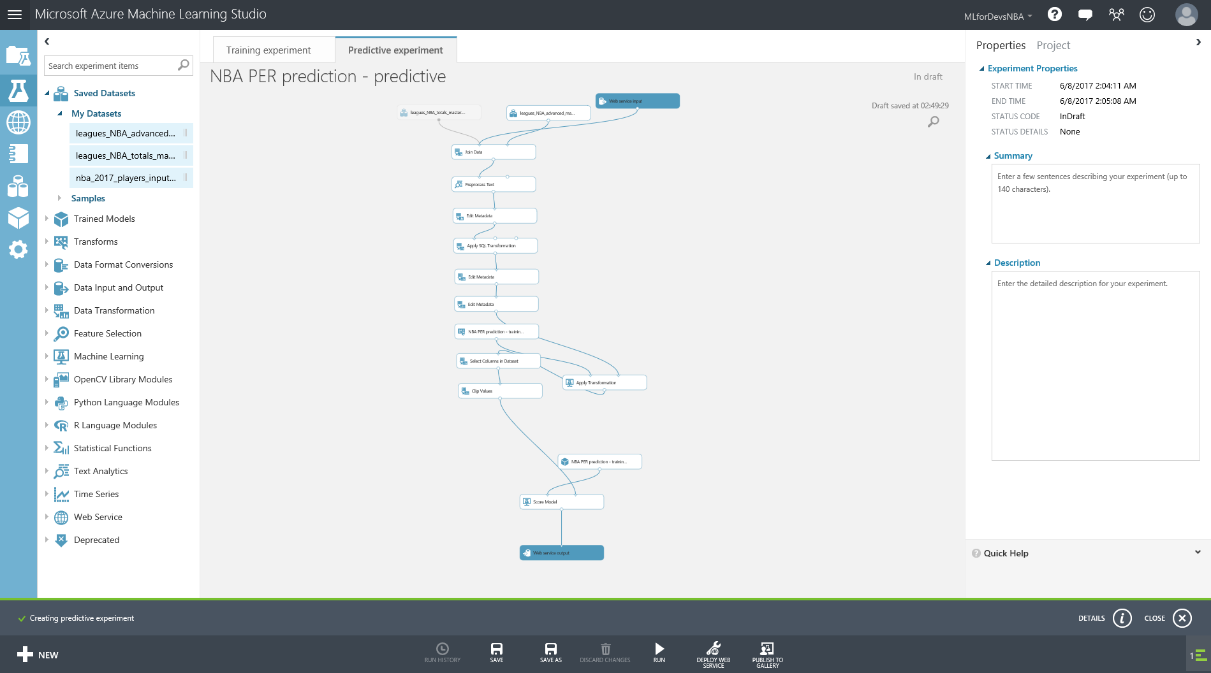
Este nuevo experimento es nuestro experimento de predicción (denominado como Predictive Experiment, y que se muestra en una pestaña diferente), que contiene algunos de los pasos de preparación del experimento de entrenamiento, así como los módulos de "Web service input" y "Web service output" , que nos servirán para fijar en qué punto entran y salen los datos de nuestro web service, como datos de entrada de la petición y como cuerpo de la respuesta. Fíjate también en que hay un nuevo módulo con el mismo nombre que diste al experimento de entrenamiento, conectado a un módulo de "Score Model". Este módulo representa nuestro modelo entrenado con todo el trabajo previo que hemos hecho en el experimento de entrenamiento, y por eso se conecta directamente al módulo de puntuación/anotación, que lo que hará será utilizar este modelo entrenado con un dataset de datos futuros para generar las predicciones.
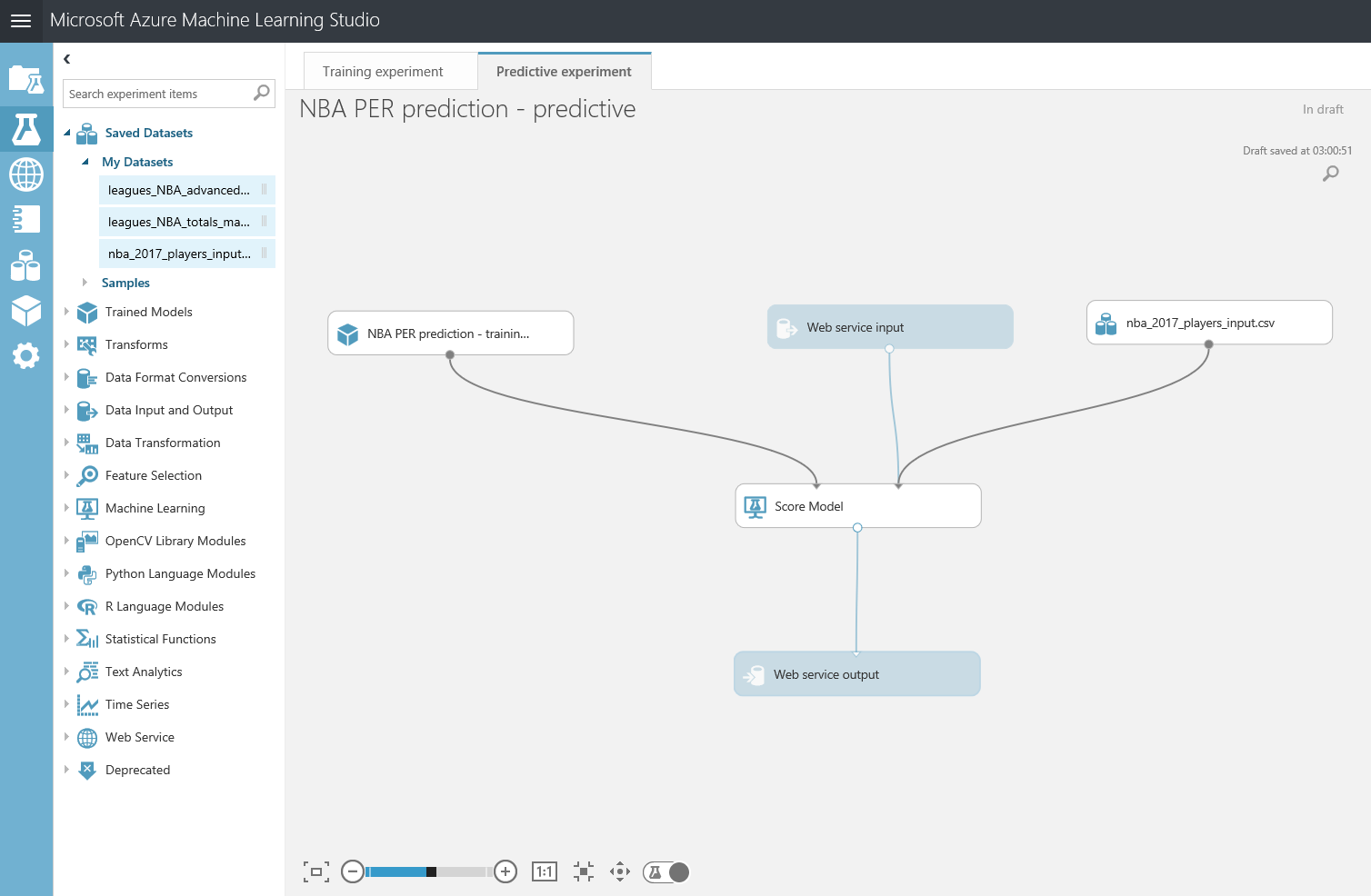
Para quedarnos solo con las partes necesarias y crear un experimento predictivo útil, vamos a conectar el módulo de "Web service input" como entrada de datos para el modulo "Score Model" , y a conectar el modulo "NBA PER prediction - training" como la otra entrada de nuestro "Score Model" . Mantengamos también el modulo "Score Model" y los módulos de entrada y salida del Web Service, eliminando todo lo demás. No necesitaremos todos los otros pasos involucrados, ya que nuestro conjunto de datos de entrada para la predicción futura ya contiene solo las columnas conocidas antes de que comience la temporada (Player, Position, Age, Team, Season) y no necesitamos realizar ninguna limpieza o procesamiento de estos datos, dado que ya vienen en el formato adecuado. Vamos a incluir también el conjunto de datos con los jugadores para la próxima temporada utilizando el tercer dataset que subimos al principio y que aún no hemos utilizado (nba_2017_players_input). Puedes encontrarlo en el menú de la izquierda, en la categoría "Saved Datasets > My Datasets" y, después de arrastrarlo al canvas, conéctalo también con el módulo de "Score Model" como entrada de datos. Tras hacer todo esto, el experimento predictivo debería quedar así:
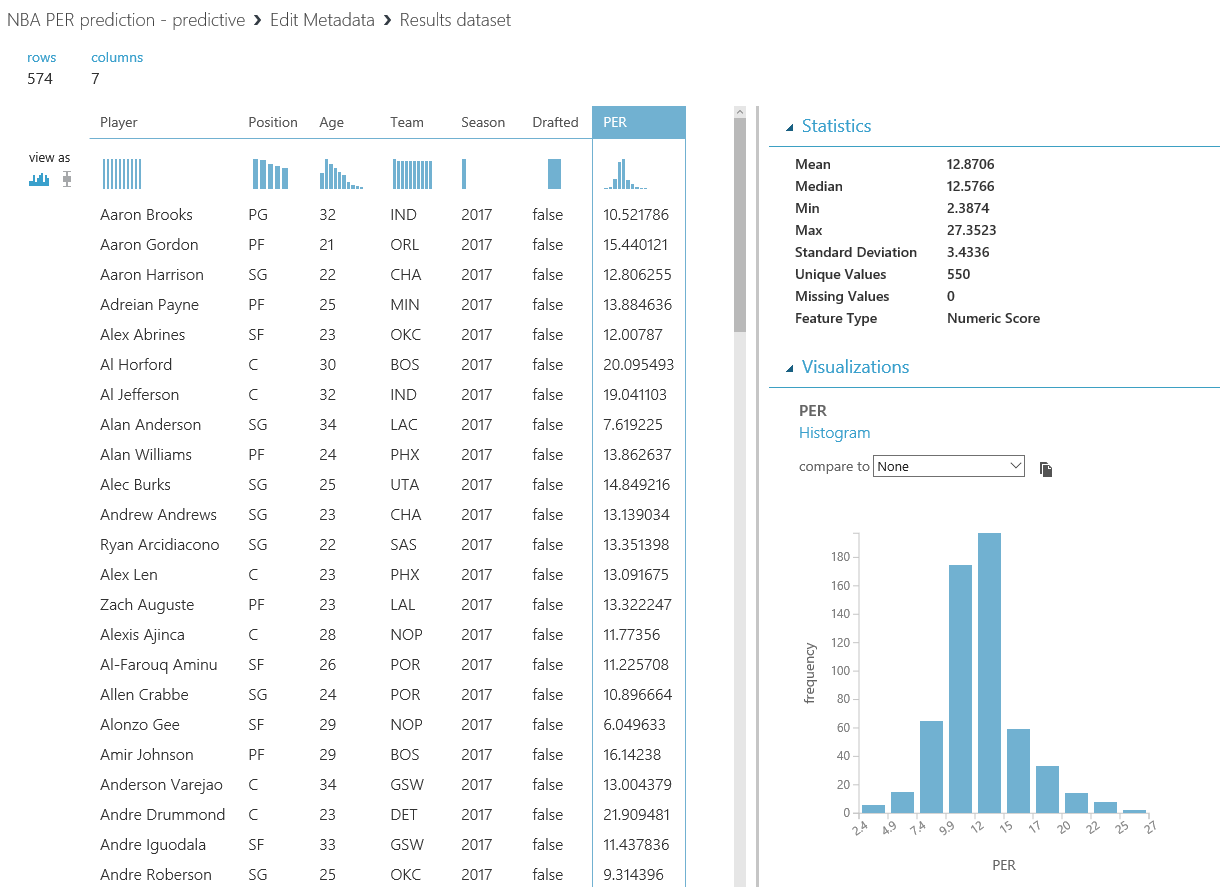
Si ejecutas el experiment, tendrás un conjunto de datos que contiene las predicciones del PER de cada jugador de la NBA para la temporada 2016/2017, denominado como "Scored Labels" . Pero, de nuevo, es mejor darle a las cosas su nombre descriptivo, así que vamos a añadir un módulo de "Edit Metadata" después del "Score Model" para cambiar el nombre de la columna "Scored Labels" a su nombre real "PER" :

¡Enhorabuena! Si echas un vistazo al conjunto de datos resultante, estarás "leyendo el futuro" y viendo la predicción del PER/valoración para cada jugador en activo de la NBA durante la temporada 2016/2017. Ten en cuenta que también hay una nueva columna denominada "Drafted" , que será útil para la última parte (y bonus track de esta serie de posts) sobre visualización y consumición de datos de este experimento de Machine Learning.
Un saludo,
Gorka Madariaga (@Gk_8)
Technical Evangelist
Comments
- Anonymous
March 28, 2018
The comment has been removed- Anonymous
April 09, 2018
Hola, asegurate de que borraste los modulos innecesarios y sobre todo que estas usando el dataset de entrada correcto, ya que segun el error al dataset le falta alguno de las columnas necesarias :)
- Anonymous