Introducing a Modern Get Data Experience for SQL Server vNext on Windows CTP 1.1 for Analysis Services
Starting with SQL Server vNext on Windows CTP 1.1, Analysis Services features a modern connectivity stack similar to the one that users already appreciate in Microsoft Excel and Power BI Desktop. You are going to be able to connect to an enormous list of data sources, ranging from various file types and on-premises databases through Azure sources and other online services all the way to Big Data systems. You can perform data transformations and mashups directly into a Tabular model. You can also add data connections and M queries to a Tabular model programmatically by using the Tabular Object Model (TOM) and the Tabular Model Scripting Language (TMSL). The modern Get Data experience is adding exciting data access, transformation, and enrichment capabilities to Tabular models.
Taking a First Glance
In sync with the SQL Server vNext CTP 1.1 release, the December release of SSDT 17.0 RC2 for SQL Server vNext CTP 1.1 Analysis Services (SSDT Tabular) ships with a preview of the modern Get Data experience. You don’t necessarily need to deploy a CTP 1.1 instance of Analysis Services because the Integrated workspace mode in SSDT Tabular relies on and includes the same Analysis Services engine. You can choose that for taking a quick look at the new connectivity stack. To learn more about Integrated workspace mode, check out the blog article Introducing Integrated Workspace Mode for SQL Server Data Tools for Analysis Services Tabular Projects (SSDT Tabular).
Note that this SSDT Tabular release for CTP 1.1 is an early preview for evaluating the vNext capabilities of Analysis Services delivered with the 1400 compatibility level. It is not supported in production environments. Also, only install the Analysis Services, but not the Reporting Services and Integration Services components. Note also that upgrades from previous SSDT versions are not supported. Either install on a newly installed computer or VM or uninstall any previous versions first. Also, only work with Tabular 1400 models using this preview version of SSDT. For Multidimensional as well as Tabular 1100, 1103, and 1200 models, use SSDT version 16.5.
After downloading and installing the December release of SSDT that supports SQL Server vNext CTP 1.1, create a new Analysis Services Tabular Project. In the Tabular Model Designer dialog, make sure you select the SQL Server vNext (1400) compatibility level. The modern Get Data experience is only available at compatibility level 1400. Tabular 1200 models continue to use the legacy connectivity stack available with SQL Server 2016 and previous releases. 
Figure 1Creating a Tabular 1400 model to use the modern Get Data experience
Note: If you are using a previous version of Analysis Services as your workspace server or a previous version of SSDT Tabular in integrated workspace mode, you will not be able to create Tabular 1400 models or use the modern Get Data experience.
Once you’ve created a Tabular 1400 model, click the Model menu or right-click on Data Sources in Tabular Model Explorer and then click Import from Data Source. In Tabular Model Explorer, you can also click New Data Source. The difference between these two commands is that Import from Data Source leads you through both the definition of a data source and the import of data into one or multiple tables, while the New Data Source command only creates a new data source definition. In a subsequent step, you would right-click the resulting data source object and choose Import New Tables. Either way, the two commands display the same Get Data dialog box similar to the version you see in Power BI Desktop.
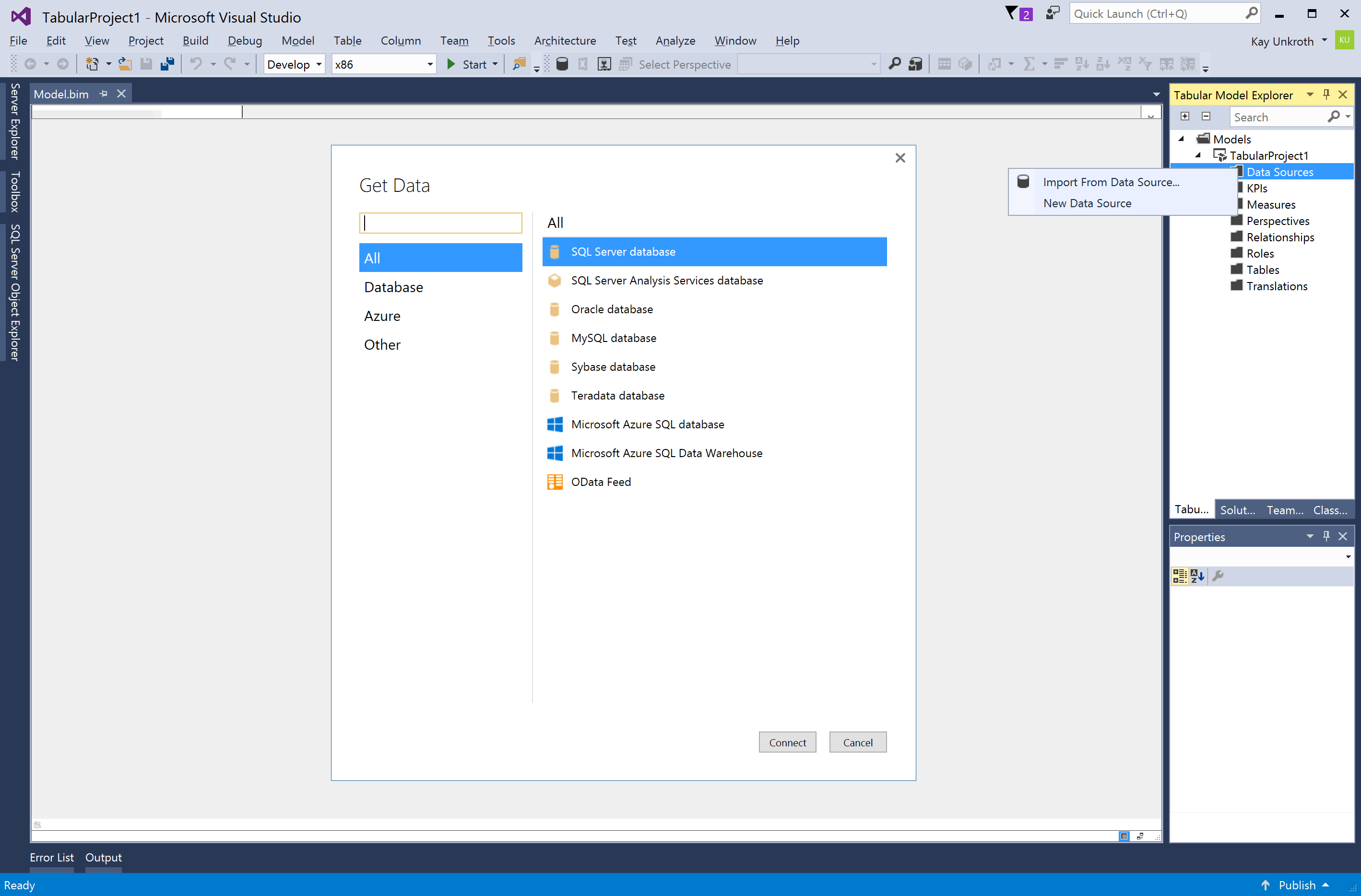
Figure 2Importing data into a Tabular 1400 model through the modern Get Data experience
Don’t be disappointed when you see a rather short list of data sources in the Get Data dialog box. CTP 1.1 is an early preview and exposes only a small set of tested options. Our plan for the SQL Server vNext release is to provide the same list of data sources that Power BI Desktop already supports, so the list will grow with subsequent CTPs.
The steps to create a data source are the same as in Power BI Desktop. However, an important difference is noticeable in the Query Editor window that appears when you import one or more tables from a data source. Apart from the fact that the Query Editor window features a toolbar consistent with the Visual Studio user interface, instead of a collection of ribbons, you might notice that the Merge Queries and Append Queries commands are missing. These commands will be available in a subsequent CTP when SSDT implements full support for shared queries. 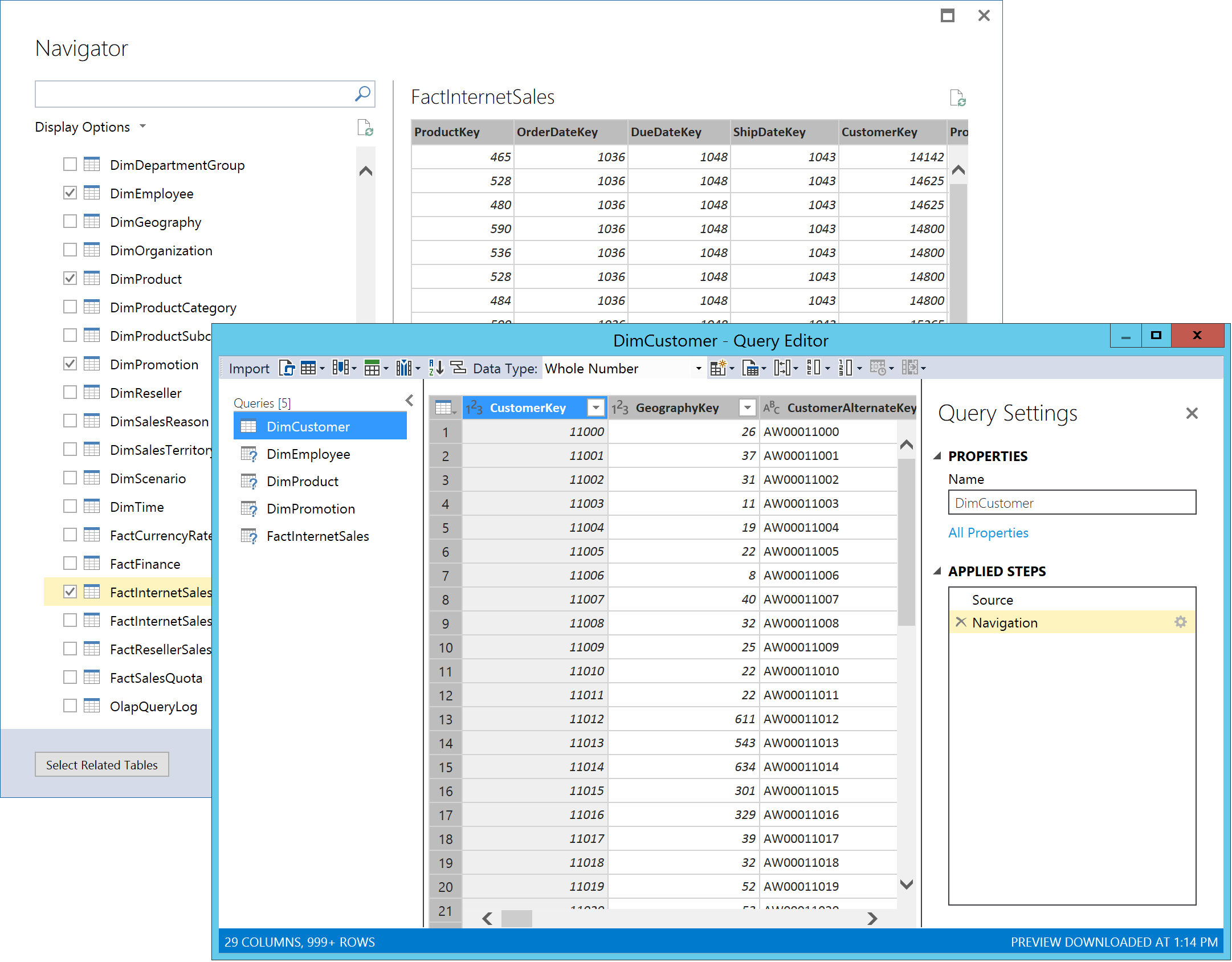
Figure 3The Query Editor dialog box in SSDT Tabular when importing tables into a Tabular 1400 model
For now, each table you choose to import in the Navigator window translates into an individual query in the Query Editor window, which will result in a corresponding table in the 1400 model when you click on Import in the Query Editor toolbar. Of course, you can define data transformation steps prior to importing the data, such as split columns, hide columns, change data types, and so on. Or, click on the Advanced Editor button (right next to Import on the toolbar) to display the Advanced Editor window, which lets you modify the import query in an unconstrained way based on the M query language. You can resize and maximize the Query Editor and Advanced Editor windows if necessary. Just be careful with advanced query authoring because SSDT does not yet capture all possible query errors. For the CTP 1.1 preview, a better approach might be to create and test advanced queries in Power BI Desktop and then paste the results into the Advanced Editor window in SSDT Tabular. 
Figure 4The Advanced Editor window is available to define advanced M queries
If you choose to copy queries from Power BI Desktop, note how the Source statement in Figure 4 refers to the AS_AdventureWorksDW data source object defined in the Tabular model. Instead of referring to the source directly by using a statement such as Source = Sql.Databases("<Name of SQL Server>"), M queries in Analysis Services can refer to a data source by using a statement such as Source = <Name of Data Source Object>. It’s relatively straightforward to adjust this line after posting a Power BI Desktop query into the Advanced Editor window.
Referring to data source objects helps to centralize data source settings for multiple queries and simplifies deployments and maintenance if data source definitions must be updated later on. When updating a data source definition, all M queries that refer to it automatically use the new settings.
Of course, you can also edit the M query of a table after the initial import. Just display the table properties by clicking on Table Properties in the Table menu or in the context menu of Tabular Model Explorer after right-clicking the table. In the CTP 1.1 preview, the Edit Table Properties dialog box immediately shows you the advanced view of the M query, but you can click on the Design button to launch the Query Editor window and apply changes more conveniently (see Figure 5). Just be cautious not to rename or remove any columns in the M source query at this stage. In the CTP 1.1 preview, SSDT doesn’t yet handle the remapping of source columns to table columns gracefully in tabular models. If you need to change the names, order, or number of columns, delete the table and recreate it from scratch or edit the TMSL code in the Model.bim file directly.
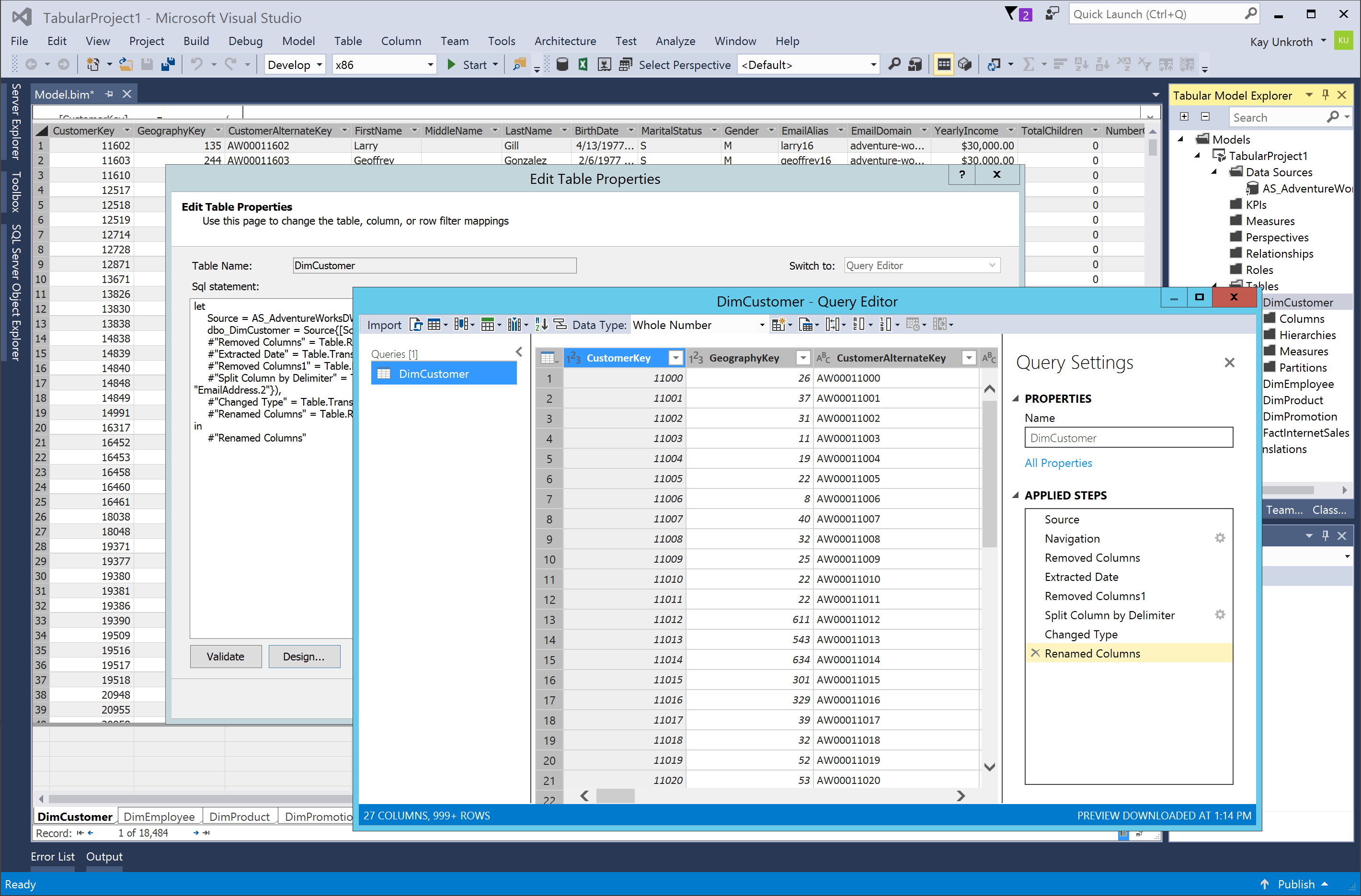
Figure 5Editing an existing table in a Tabular 1400 model via Table Properties
One very useful scenario for editing an M source query without changing column mappings revolves around the definition of multiple partitions for a table. For example, by using the Table.Range M function, you can define a subset of rows for any given partition. Table 1 and Figure 6 show a partitioning scheme for the FactInternetSales table that relies on this function. You could also define entirely different M queries. As long as a partition’s M query adheres to the column mappings of the table, you are free to perform any transformations and pull in data from any data source defined in the model. Partitioning is an exclusive Analysis Services feature. It is not available in Excel or Power BI Desktop.
Table 1A simple partitioning scheme for the AdventureWorks FactInternetSales table based on the Table.Range function
| Partition | M Query Expression |
| FactInternetSalesP1 | letSource = AS_AdventureWorksDW,dbo_FactInternetSales = Source{[Schema="dbo",Item="FactInternetSales"]}[Data],#"Kept Range of Rows" = Table.Range(dbo_FactInternetSales,0,20000)in#"Kept Range of Rows" |
| FactInternetSalesP2 | letSource = AS_AdventureWorksDW,dbo_FactInternetSales = Source{[Schema="dbo",Item="FactInternetSales"]}[Data],#"Kept Range of Rows" = Table.Range(dbo_FactInternetSales,20000,20000)in#"Kept Range of Rows" |
| FactInternetSalesP3 | letSource = AS_AdventureWorksDW,dbo_FactInternetSales = Source{[Schema="dbo",Item="FactInternetSales"]}[Data],#"Kept Range of Rows" = Table.Range(dbo_FactInternetSales,40000,20000)in#"Kept Range of Rows" |
| FactInternetSalesP4 | letSource = AS_AdventureWorksDW,dbo_FactInternetSales = Source{[Schema="dbo",Item="FactInternetSales"]}[Data],#"Kept Range of Rows" = Table.Range(dbo_FactInternetSales,60000,20000)in#"Kept Range of Rows" |
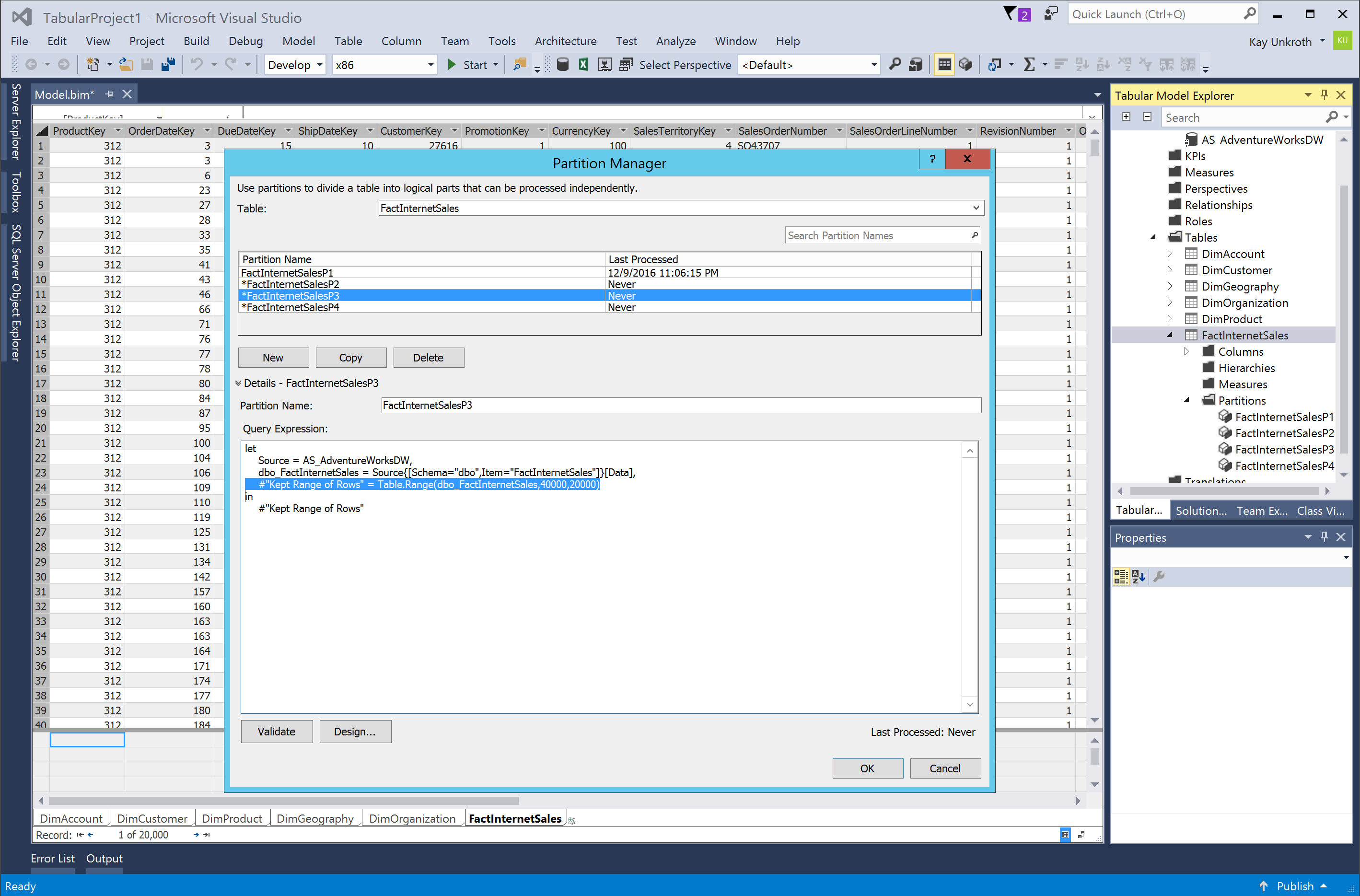
Figure 6A simple partitioning scheme based on the Table.Range function
Upgrading a Tabular Model to the 1400 Compatibility Level
The modern Get Data experience is one of the key features of the 1400 compatibility level. Others are support for ragged hierarchies and detail rows. As long as your workspace server is at the CTP 1.1 level, you can upgrade Tabular 1200 models to 1400 in SSDT by changing the Compatibility Level in the Properties window, as illustrated in Figure 7. Just remember to take a backup of your Tabular project prior to the upgrade because the compatibility level cannot be downgraded afterwards. 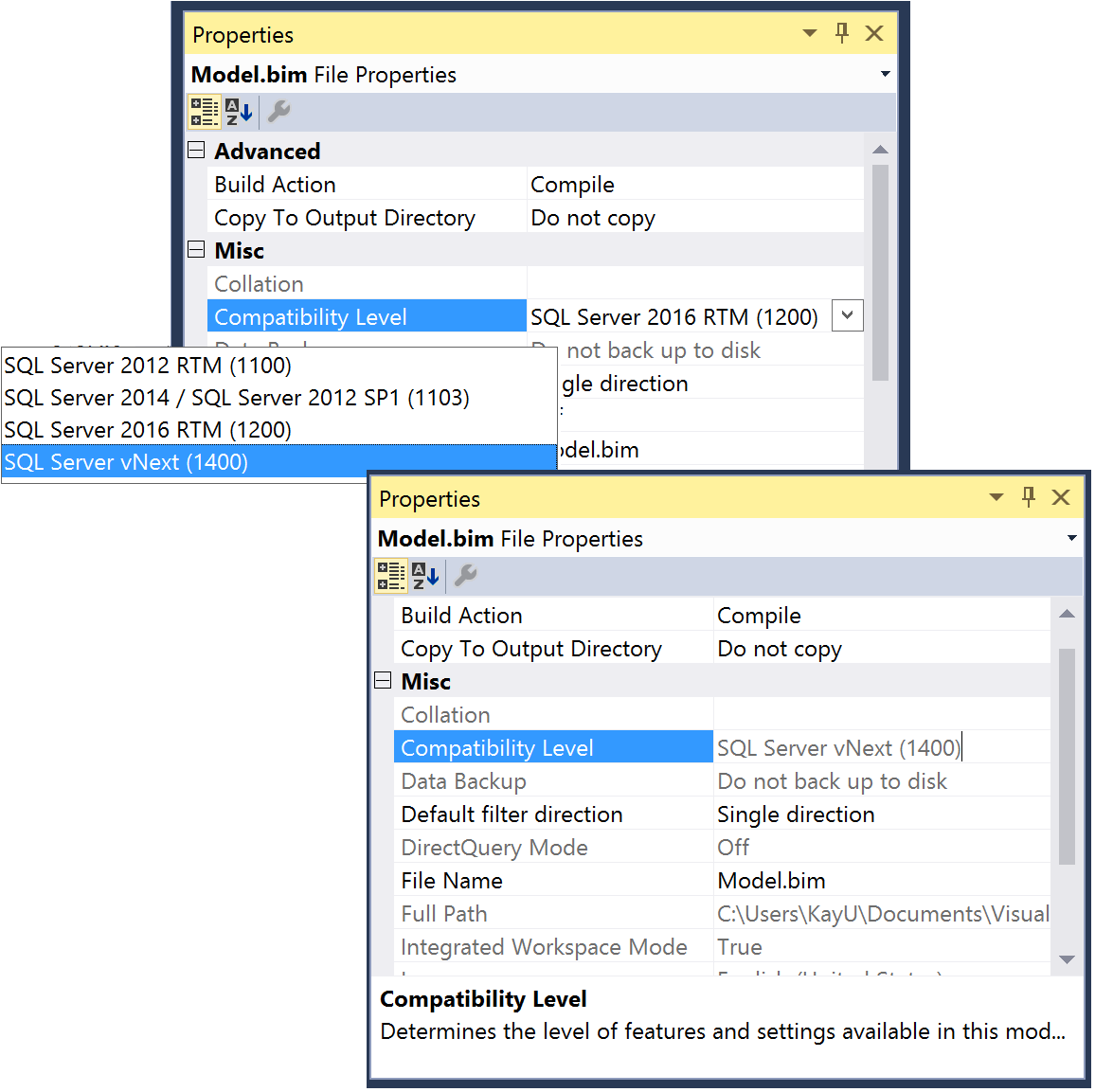
Figure 7Upgrading a Tabular 1200 model to the 1400 compatibility level. Downgrade is not supported.
If you are planning to upgrade a Tabular 1103 (or earlier) model to 1400, make sure you upgrade first to the 1200 compatibility level. In the CTP 1.1 preview, SSDT is not yet able to upgrade these older models to 1400 directly. Like all other known issues, we plan to address this in one of the next preview releases. Also, be sure to see the Known Issues in CTP 1.1 section later in this article.
Working with Legacy and Modern Data Sources
By default, SSDT creates modern data source definitions in Tabular 1400 models. On the other hand, if you upgrade a 1200 model, the existing data source definitions remain unchanged. For these existing data source definitions, known as provider data sources, SSDT currently continues to show the legacy user interface. However, the plan is to replace the legacy interface with the modern Get Data experience. Furthermore, importing new tables from an existing provider data source brings up the legacy user interface. Importing from a modern data source brings up the modern Get Data experience.
In the CTP 1.1 preview specifically, you can configure SSDT to enable the legacy user interface even for creating new data sources by setting a DWORD registry parameter called Enable Legacy Import to a value of 1, as in the following Registration Entries (.reg) file. This might be useful if you only want to try out certain tabular 1400 specific features such as detail rows without switching to modern data source definitions. After setting the Enable Legacy Import parameter to 1, you can find additional commands in the data source context menu in Tabular Model Editor. You can use these commands to create and manage provider data sources (see Figure 8). Setting this parameter to any other value than 1 or removing it altogether disables these additional commands again.
Windows Registry Editor Version 5.00
[HKEY_CURRENT_USER\Software\Microsoft\Microsoft SQL Server\14.0\Microsoft Analysis Services\Settings]
"Enable Legacy Import"=dword:00000001
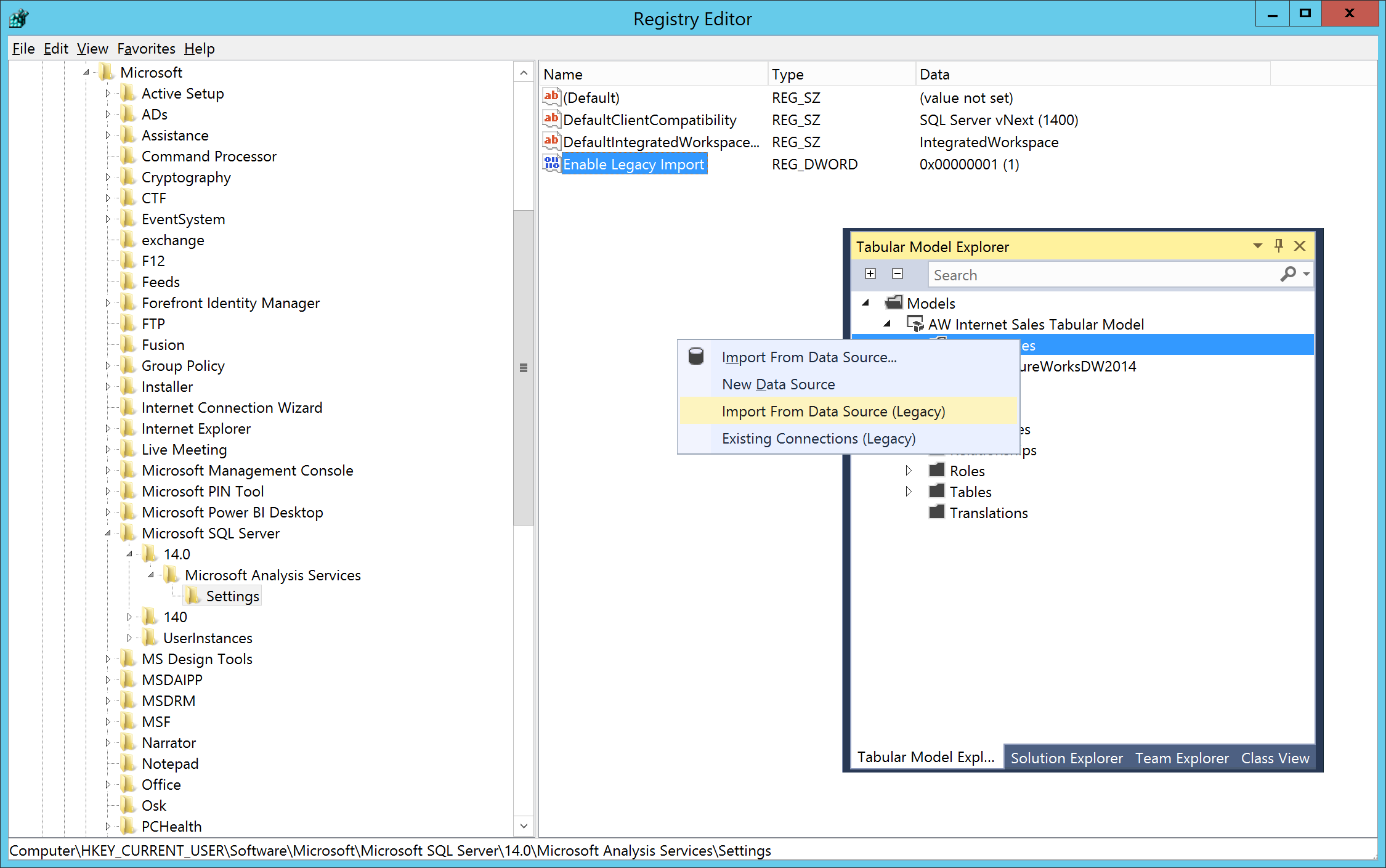
Figure 8Enabling legacy data import commands in the CTP 1.1 preview release of SSDT Tabular
Regardless of the user interface, Table 2 lists the various data connectivity related objects that can coexist in a Tabular 1400 model. Ideally, you can mix and match any data source type with any partition source type, but there are limitations in the CTP 1.1 preview. For example, it should be possible to create a partition with an M expression over an existing provider data source. This does not work yet. Equally, it should be possible to have a partition with a native query over a modern data source. This can be accomplished programmatically or in TMSL, but processing such a query partition fails in SSDT with an error stating the data source is of an unsupported type for determining the connection string. This is an issue in the December 2016 release of SSDT Tabular, but processing succeeds in SSMS (see the Working with a Tabular 1400 Model in SSMS section later in this article). For the CTP 1.1 preview, we recommended you use query partitions over legacy (provider) data sources and M partitions over modern (structured) data sources. In a later preview release, you will be able to mix and match these resources more freely so you don’t have to create redundant data source definitions for models that contain both query and M partitions.
Table 2Data Source and corresponding partition types supported in Tabular 1400 models
| Level | Data Source Type | Partition Type | Source Query Type |
| 1200 and 1400 | Provider Data Source | Query Partition | Native Query, such as T-SQL |
| 1400 only | Structured Data Source | M Partition | M Expression |
Working with a Tabular 1400 Model in SSMS
SQL Server Management Studio (SSMS) does not yet provide a user interface for the modern Get Data experience, but don’t let that stop you from managing your Tabular 1400 models. Although you cannot yet change the settings of a modern data source in the Connection Properties dialog box or conveniently manage partitions for a table, you can script out the desired objects and apply your changes in the TMSL code (Be sure to also read the Working with TOM and TMSL section later in this article). Just right-click the desired object, such as a modern data source, click on Script Connection as, and then choose any applicable option, such as Create or Replace To a New Query Editor Window, as shown in Figure 9.
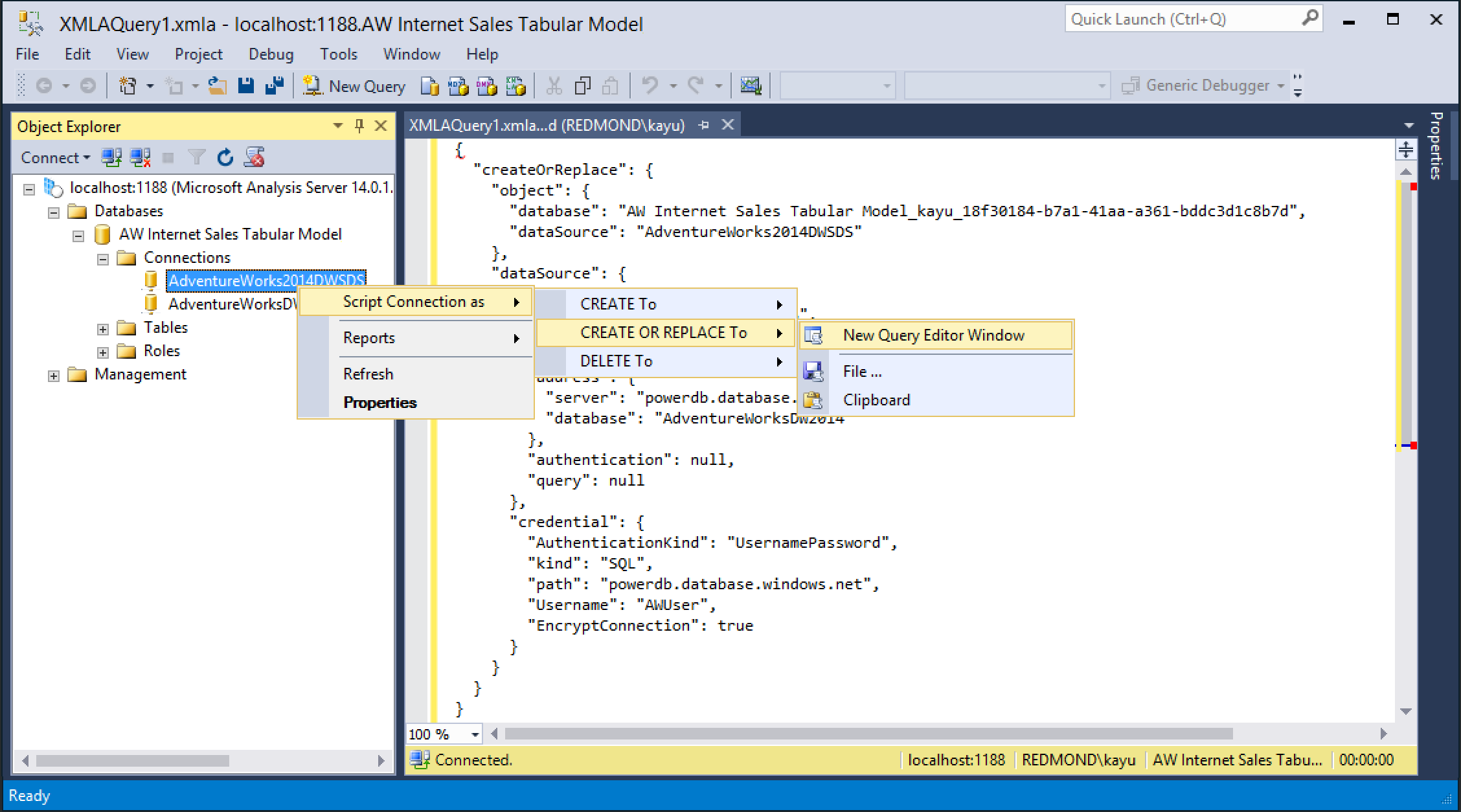
Figure 9Scripting out a modern data source
You can also script out tables and roles, process the database or individual tables, and perform any other management actions as you would for Tabular 1200 models.
Working with TOM and TMSL
In addition to the metadata objects you already know from Tabular 1200 models, 1400 models introduce three important new object types: StructuredDataSource, MPartitionSource, and NamedExpression. The StructuredDataSource type defines the properties that describe a modern data source. MPartitionSource takes an M expression as the source query and can be assigned to the Source property of a partition. And, NamedExpression is a class to define shared queries. SSDT does not yet support shared queries, but the AS engine and TOM already do. Creating and using shared queries programmatically is going to be the subject of a separate article.
Editing the Model.bim file
Whenever you cannot perform a desired action in the user interface of SSDT, consider switching to Code View and performing the action at the TMSL level. For example, SSDT does not yet support renaming of modern data sources. If you don’t find the default name assigned to a data source intuitive, such as Query1, switch to Code View, and then perform a Find and Replace operation. Keep in mind that expressions in M partition sources refer to modern data sources by name, so don’t forget to update these expressions together with the data source name. Figure 10 shows an example. Also, as always, make sure you first backup the Model.bim file before editing it manually. 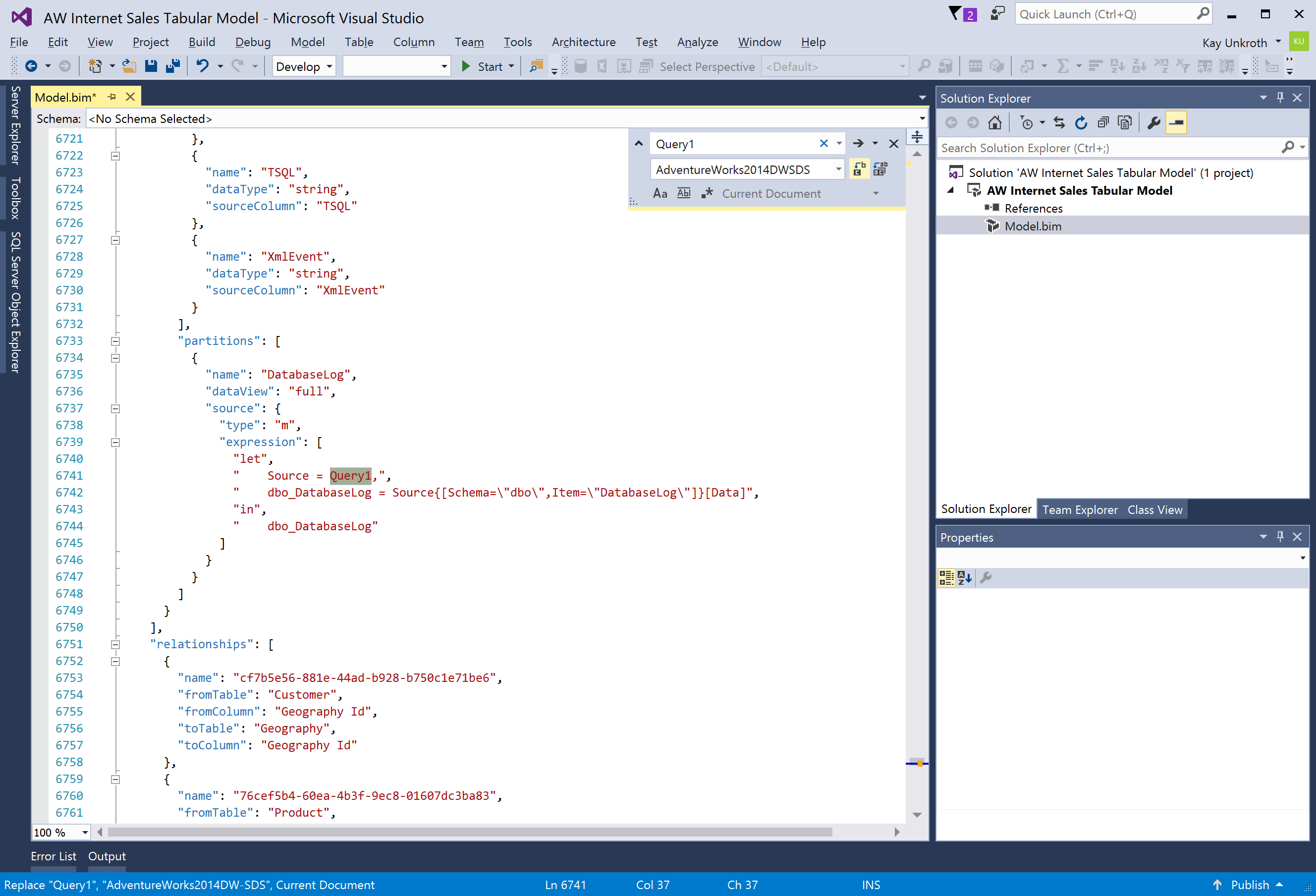
Figure 10Updating the data source reference in an M expression
After changing data source properties and affected M expressions, switch back to Designer View and process the affected tables to ensure the model is still in a consistent state. If you receive an error stating “The given credential is missing a required property. Data source kind: SQL. Authentication kind: UsernamePassword. Property name: Password. The exception was raised by the IDbConnection interface. ” you could switch back to Code View and provide the missing password although it is usually easier to use the user interface via the Edit Permissions command on the data source object in Tabular Model Explorer. If you prefer the Code View, use the following TMSL code as a reference to provide the missing password for a modern (structured) data source.
{
"type": "structured",
"name": "AdventureWorks2014DWSDS",
"connectionDetails": {
"protocol": "tds",
"address": {
"server": "<Server Name>",
"database": "AdventureWorksDW2014"
},
"authentication": null,
"query": null
},
"credential": {
"AuthenticationKind": "UsernamePassword",
"kind": "SQL",
"path": "<Server Name>",
"Username": "<User>",
" Password " : "<Password>" ,
"EncryptConnection": true
}
}
Note: For security reasons, Analysis Services does not return sensitive information such as passwords when scripting out a Tabular model or tracing commands and responses in SQL Profiler. Even though you don’t see the password, the server may have it and can perform processing successfully. You only need to provide the password if an error message informs you that it is missing.
Working with Tabular 1400 models programmatically
If you want to work with modern data sources and M partitions programmatically, you need to use the CTP 1.1 version of Analysis Management Objects (AMO). The AMO libraries are part of the SQL Server Feature Pack, yet a Feature Pack for CTP 1.1 is not available. As a workaround for CTP 1.1, you can use the server version of the AMO libraries, Microsoft.AnalysisServices.Server.Core.dll, Microsoft.AnalysisServices.Server.Tabular.dll, and Microsoft.AnalysisServices.Server.Tabular.Json.dll. These libraries are included with SSDT. By default, these libraries are located in the C:\Program Files (x86)\Microsoft Visual Studio 14.0\Common7\IDE\PrivateAssemblies\Business Intelligence Semantic Model\LocalServer folder. However, you cannot redistribute these libraries with your client application. For CTP 1.1, this means that your code can only run on a machine with SSDT installed, which should suffice for a first evaluation of the TOM objects for the modern Get Data experience.
Figure 11 shows a sample application that creates a Tabular 1400 model on a server running SQL Server vNext CTP 1.1 Analysis Services. It uses StructuredDataSource and MPartitionSource objects to add a modern data source and an M partition to the model. See the attachment to this article for the full Sample Code. The ConnectionDetails and Credential properties that you must set for the StructuredDataSource object are not yet documented, but you can glean examples for these strings from a Model.bim file that contains a modern data source. The MPartitionSource object on the other hand takes an M query in its Expression property. As explained earlier in this article, make sure the M query refers to a data source defined in the model by name.
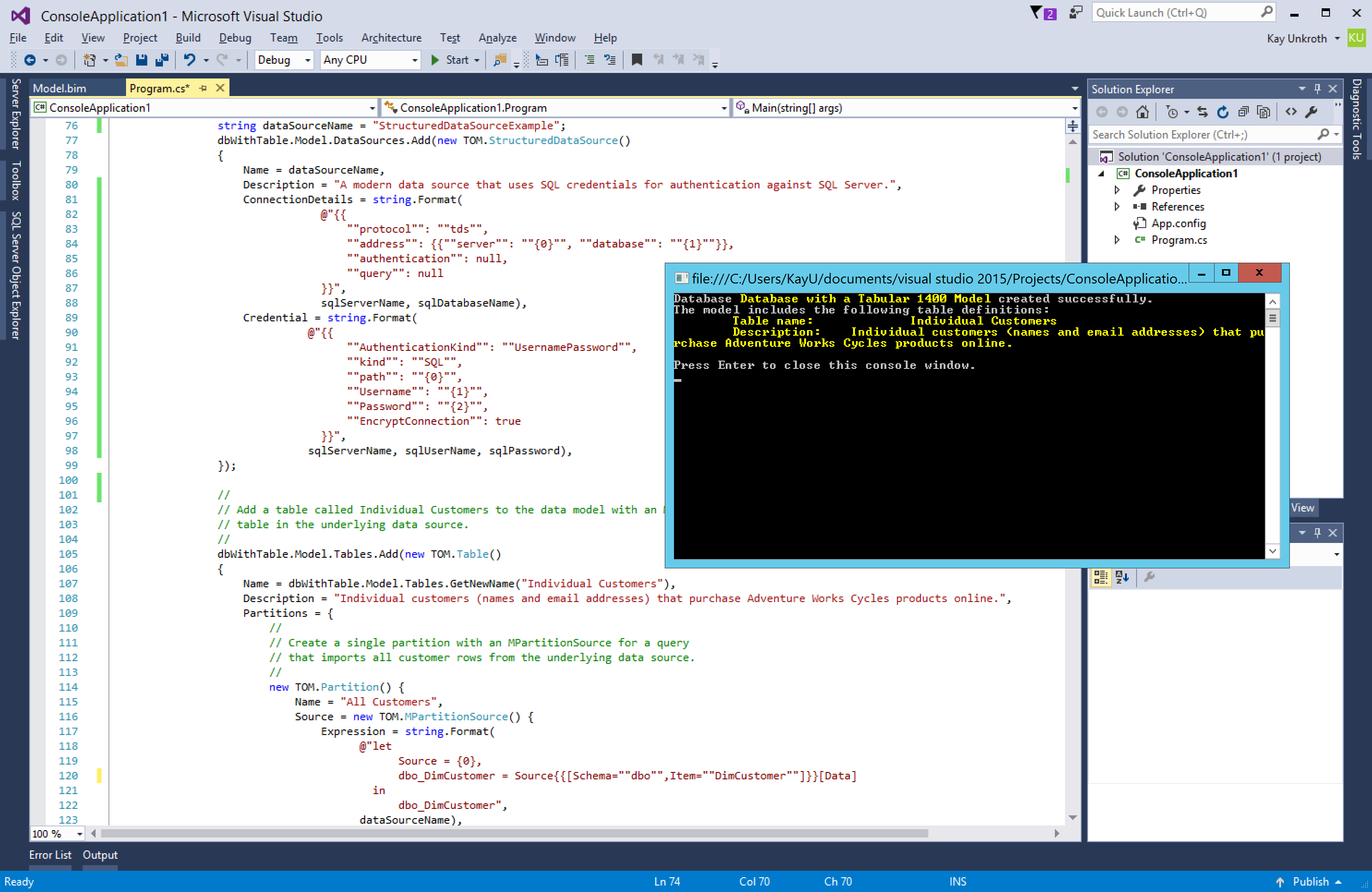
Figure 11Creating a Tabular 1400 model with a modern data source and a table based on an M partition source programmatically.
Known Issues in CTP 1.1
SQL Server vNext CTP 1.1 provides an early preview of the modern Get Data experience. It is not fully tested and not supported in production environments. The following are known issues in CTP 1.1 Analysis Services and the corresponding SSDT release:
- The SSDT Tabular release for CTP 1.1 is an early preview for evaluating the vNext capabilities of Analysis Services. It is not supported in production environments and must be installed without the Reporting Services and Integration Services components. Upgrades from previous SSDT versions are not supported. Either install on a newly installed computer or VM or uninstall any previous versions first. Also, only work with Tabular 1400 models. For Multidimensional as well as Tabular 1100, 1103, and 1200 models, use SSDT version 16.5.
- SSDT does not yet support all required operations on modern data sources and M partitions through the user interface. For example, renaming data source objects or changing the column mappings for a table. It’s also not yet possible to define shared mashups through the user interface. You must edit the Model.bim file manually.
- SSMS can script out Tabular 1400 models and individual objects, but the user interface is not yet 1400 aware. For example, you cannot manage partitions if the model contains a structured data source and you cannot change the settings of a modern data source through the Connection Properties dialog box. You must script out these objects and apply the changes that the TMSL level.
- Creating a new tabular project in SSDT by using the option to Import from Server (Tabular) does not work. You get an error message stating the model is not recognized as compatible with SQL Server 2012 or higher. You can script out the database in SSMS and copy the TMSL code into the Model.bim file of an empty Tabular project created from scratch.
- Erroneous M queries and changes to M queries that affect the column mapping of an existing table after the initial import may cause SSDT Tabular to become unresponsive. If you must change the column mapping, delete and recreate the table.
- Tables with M partition sources don’t work over legacy (provider) data sources. You must use modern data sources for these tables.
- Tables with query partition sources don’t fully work over modern data sources. SSDT cannot process these tables. You must process these tables in SSMS or programmatically.
- Processing individual partitions does not succeed. Process the full model or the table.
- Direct upgrades of Tabular 1103 or earlier models to the 1400 compatibility level does not finish successfully. You must first upgrade these models to the 1200 compatibility level and then perform the upgrade to 1400.
- DirectQuery mode is not yet supported at the 1400 compatibility level. To preview the modern Get Data experience, you must import the data into the Tabular model.
- Out-Of-Line Bindings are not yet supported. It’s not possible to override a structured data source or M partition source on a request basis in a Tabular 1400 model yet.
- All modern data sources are considered private data sources to avoid disclosing sensitive or confidential information. A private data source is completely isolated from other data sources. The privacy settings for data sources cannot be changed in CTP 1.1.
- Impersonation options such as ImpersonateWindowsUserAccount are not yet supported for modern data sources. You must specify credentials explicitly when defining the data source.
- Localization is not supported. CTP 1.1 is available in English (US) only.
Give us Feedback
Your feedback is critical for delivering a high-quality product! Deploy SQL Server vNext CTP 1.1 and the December 2016 release of SSDT Tabular in a lab environment or on a virtual machine in Azure and let us know what you think. Report issues and send us your suggestions to SSASPrev here at Microsoft.com. Or use any other available communication channels such as UserVoice or MSDN forums. You can influence the evolution of the Analysis Services connectivity stack to the benefit of all our customers.
Comments
- Anonymous
December 16, 2016
Power Query in SSAS Tabular is the top wish list I have in my mind for a while now, I'm very excited to see that wish list is being implemented :)I'm not an expert in M, and don't bother to learn it seriously like I'm with DAX, partly because of the user interface (ribbon) has already provided so much. And if that is not enough, then I'll get my hand dirty in the Advanced Query just to tweak it a little bit to get what I want. So, the feedback I'm giving will be: "Please add the Power BI - Power Query User Interface into SSAS Tabular". It doesn't have to be in a form of Ribbon, I just want the rich UI functionality.- Anonymous
December 16, 2016
Thanks for the feedback, Leo, the plan is to be as aligned as possible. Let us know what you like and don't like via SSASPrev. We won't have the resources to reply to every message, but we are reading all feedback and take it into consideration. This is the right time to influence things. That's the purpose of this early preview.- Anonymous
December 17, 2016
Based on first impressions, I agree with Leo - the UI should match the Power Query/Power BI UI. Consistency with Visual Studio is all very well, but consistency with Power Query/Power BI is even more important.- Anonymous
December 19, 2016
It actually is the same UI, Chris, except the toolbar.- Anonymous
December 20, 2016
The toolbar is 90% of the UI, in this case :-)- Anonymous
December 20, 2016
How about a menu in addition to the toolbar?
- Anonymous
- Anonymous
December 22, 2016
Hmm, maybe the best compromise would be an option to toggle between a Visual Studio look-and-feel and the original ribbon UI. I really do think the ribbon needs to be there somewhere.On another topic, you have mentioned SSASPrev several times here but I don't know what it is and there aren't any links. Is it an email alias or a feedback site?- Anonymous
December 22, 2016
The comment has been removed
- Anonymous
- Anonymous
- Anonymous
- Anonymous
- Anonymous
- Anonymous
December 17, 2016
A-M-A-Z-I-N-G !!!Can't wait for GA release to make MS BI rock everywhere!!BTW can you please give more details about implementation of ragged hierarchies and detail rows?Thank you!!- Anonymous
December 19, 2016
Christian blogged about these features here: https://blogs.msdn.microsoft.com/analysisservices/2016/12/16/whats-new-for-sql-server-vnext-on-windows-ctp-1-1-for-analysis-services/
- Anonymous
- Anonymous
December 17, 2016
The comment has been removed- Anonymous
December 19, 2016
In this early preview, structured data sources are slower than provider data sources, but it's one of the top priorities to get them up to par. Not easy. It'll take some time. We'll blog about when we are ready.
- Anonymous
- Anonymous
December 17, 2016
The comment has been removed- Anonymous
December 19, 2016
Perf optimizations are an important goal for vNext because it's essential to support the large data sets that SSAS customers have.
- Anonymous
- Anonymous
December 17, 2016
This increased scale out functionality from Power BI to Analysis Services to Tabular by Tabular having M support is awesome! I can't wait to give this a try! - Anonymous
December 17, 2016
Are sqlserver vnext and sqlserver 2016 both the same or is it like visual studio vs visual studio code ?- Anonymous
December 19, 2016
SQL Server vNext is the version that comes after SQL Server 2016.
- Anonymous
- Anonymous
December 19, 2016
The most awesome Christmas gift ever! Our patience is finally being rewarded! - Anonymous
December 19, 2016
A nice feature, but I'm assuming this is specific to TAB mode... is MD mode getting any improvements at this point, or should the general public start viewing it as deprecated? I only ask because this seems to be the case for the last three releases of SQL.- Anonymous
December 19, 2016
The comment has been removed
- Anonymous
- Anonymous
March 09, 2017
Link is dead...- Anonymous
March 09, 2017
Mh, the links to download Setup.exe seem to be working for me. Where exactly do you see the issue?- Anonymous
March 22, 2017
Same issue - t redirects to the default download page https://www.microsoft.com/en-us/download- Anonymous
March 22, 2017
The following link should get you to the bits: https://go.microsoft.com/fwlink/?linkid=842523
- Anonymous
- Anonymous
- Anonymous
- Anonymous
March 31, 2017
This is a long awaited capability improvement that will add significant agility to enterprise data supply chains, with reduced data processing and storage footprint (read: eliminate relational semantic layer storage and processing build and sustainment cost and overhead, in particular for reference data & hierarchies). Keep it coming & separate AS update cycles (if possible) from overall data platform to move towards enterprise DevOps model.