Avvio rapido: Inserire dati con un clic (anteprima)
L'inserimento di dati con un clic è un processo semplice, rapido e intuitivo. L'inserimento con un clic consente di iniziare rapidamente a inserire dati, creare tabelle di database ed eseguire il mapping di strutture. Selezionare i dati da vari tipi di origini in formati di dati diversi, in un processo di inserimento una tantum o continuo.
Ecco le funzionalità per cui l'inserimento con un clic è particolarmente utile:
- Esperienza intuitiva grazie all'inserimento guidato
- Inserimento di dati in una questione di minuti
- Inserimento di dati da vari tipi di origini: file locali, BLOB e contenitori (fino a 10.000 BLOB)
- Inserimento di dati in un'ampia varietà di formati
- Inserimento di dati in tabelle nuove o esistenti
- Il mapping e lo schema delle tabelle vengono suggeriti automaticamente e sono facili da cambiare
L'inserimento con un clic è particolarmente utile quando si inseriscono i dati per la prima volta o quando non si ha familiarità con lo schema dei dati.
Prerequisiti
Una sottoscrizione di Azure. Creare un account Azure gratuito.
Creare un pool di Esplora dati usando Synapse Studio o il portale di Azure
Creare un database di Esplora dati.
Nel riquadro sinistro di Synapse Studio selezionare Dati.
Selezionare + (Aggiungi nuova risorsa) >Pool di Esplora dati e usare le informazioni seguenti:
Impostazione Valore suggerito Descrizione Nome pool contosodataexplorer Nome del pool di Esplora dati da usare Nome TestDatabase Il nome del database deve essere univoco all'interno del cluster. Periodo di conservazione predefinito 365 Intervallo di tempo (in giorni) per cui è garantito che i dati rimangano disponibili per le query. L'intervallo di tempo viene misurato dal momento in cui i dati vengono inseriti. Periodo cache predefinito 31 L'intervallo di tempo (in giorni) per cui mantenere i dati sottoposti frequentemente a query disponibili nell'archiviazione su unità SSD o nella RAM, invece che nell'archiviazione a lungo termine. Selezionare Crea per creare il database. Per la creazione è in genere necessario meno di un minuto.
Crea una tabella
- Nel riquadro sinistro di Synapse Studio selezionare Sviluppo.
- In Script KQL selezionare + (Aggiungi nuova risorsa) >Script KQL. Nel riquadro a destra è possibile assegnare un nome allo script.
- Nel menu Connetti a selezionare contosodataexplorer.
- Nel menu Usa database selezionare TestDatabase.
- Incollare il comando seguente e selezionare Esegui per creare la tabella.
.create table StormEvents (StartTime: datetime, EndTime: datetime, EpisodeId: int, EventId: int, State: string, EventType: string, InjuriesDirect: int, InjuriesIndirect: int, DeathsDirect: int, DeathsIndirect: int, DamageProperty: int, DamageCrops: int, Source: string, BeginLocation: string, EndLocation: string, BeginLat: real, BeginLon: real, EndLat: real, EndLon: real, EpisodeNarrative: string, EventNarrative: string, StormSummary: dynamic)Suggerimento
Verificare che la tabella è stata creata correttamente. Nel riquadro a sinistra selezionare Dati, selezionare il contosodataexplorer nel menu Altro e quindi selezionare Aggiorna. In contosodataexplorer espandere Tabelle e assicurarsi che la tabella StormEvents venga visualizzata nell'elenco.
Accedere alla procedura guidata con un clic
L'inserimento guidato con un clic illustra i passaggi dell'intero processo.
Per accedere alla procedura guidata da Azure Synapse:
Nel riquadro sinistro di Synapse Studio selezionare Dati.
In Database di Esplora dati fare clic con il pulsante destro del mouse sul database pertinente e quindi scegliere Apri in Esplora dati di Azure.

Fare clic con il pulsante destro del mouse sul pool pertinente e quindi scegliere Inserisci nuovi dati.
Per accedere alla procedura guidata dal portale di Azure:
Nel portale di Azure cercare e selezionare l'area di lavoro Synapse pertinente.
In Pool di Esplora dati selezionare il pool pertinente.
Nella schermata iniziale del pool di Esplora dati selezionare Inserire nuovi dati.
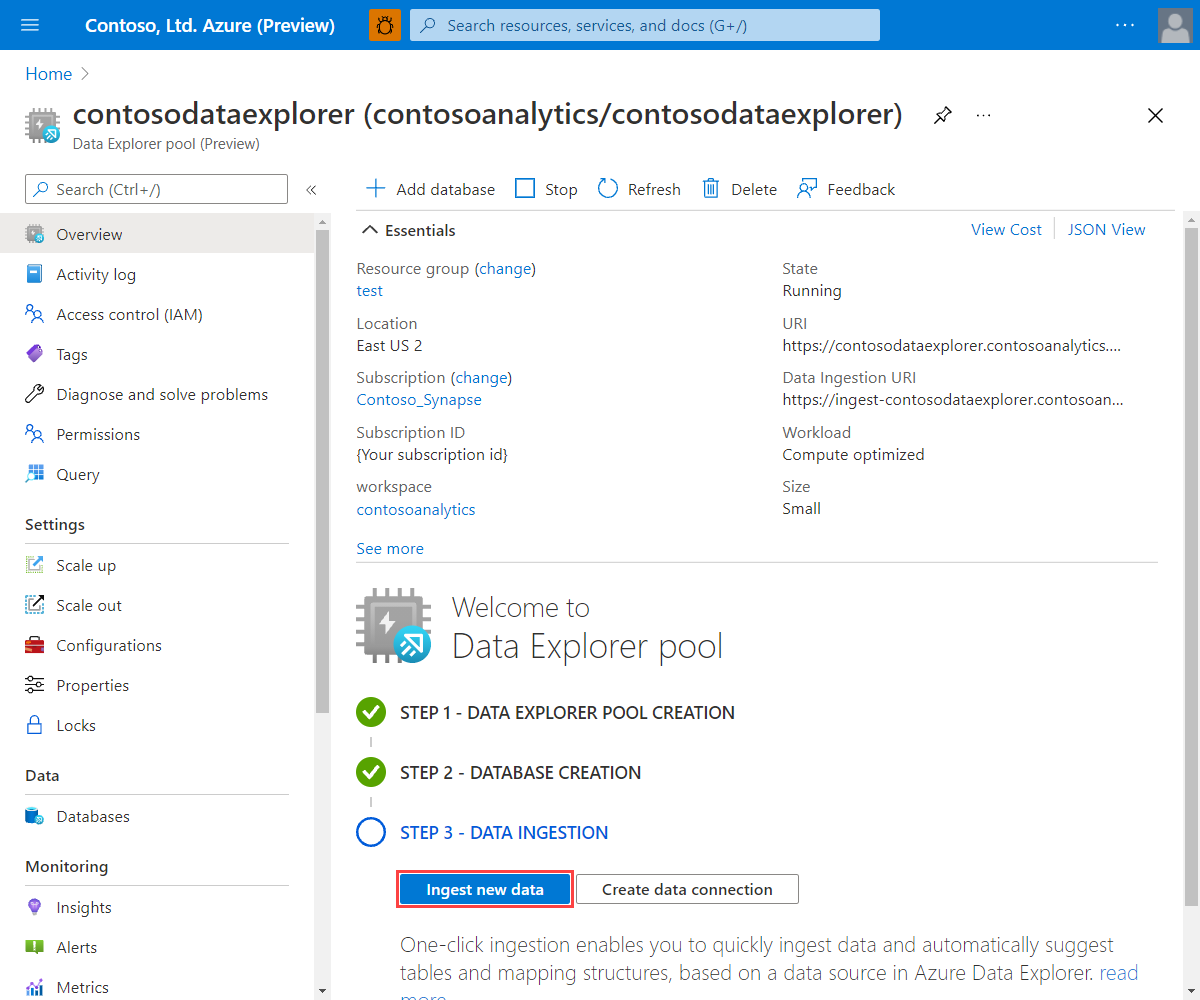
Per accedere alla procedura guidata dall'interfaccia utente Web di Esplora dati di Azure:
- Prima di iniziare, seguire questa procedura per ottenere gli endpoint di query e inserimento dati.
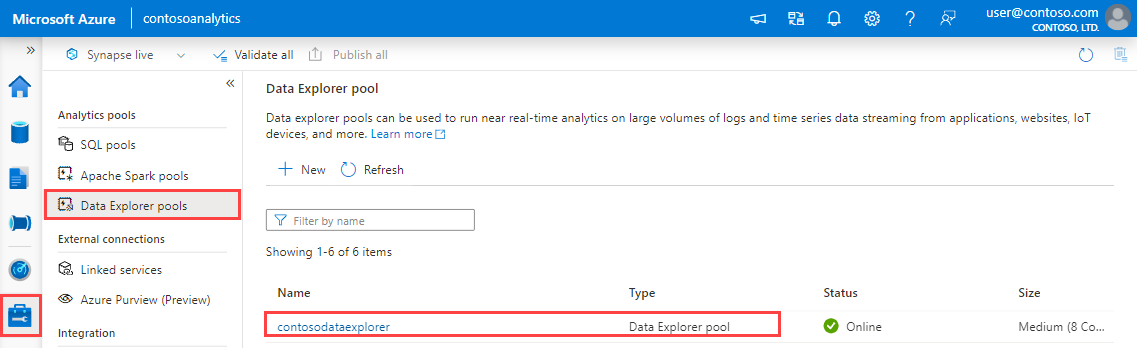
Nel riquadro sinistro di Synapse Studio selezionare Gestisci>Pool di Esplora dati.
Selezionare il pool di Esplora dati da usare per visualizzarne i dettagli.
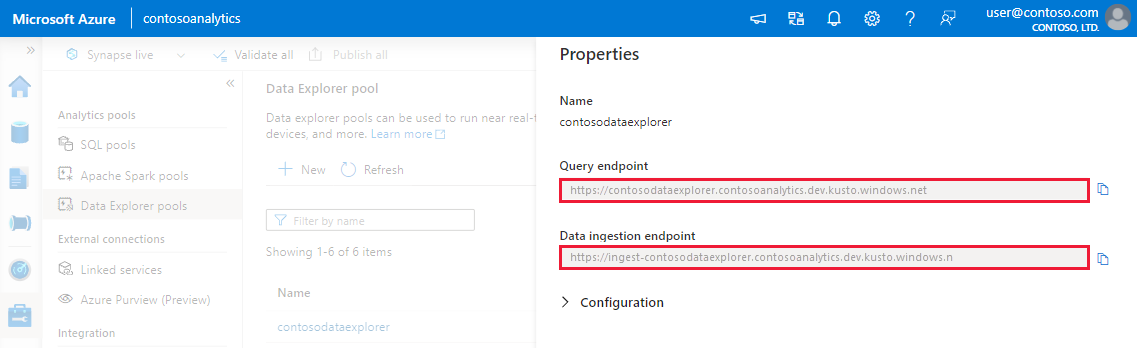
Prendere nota degli endpoint di query e inserimento dati. Usare l'endpoint di query come cluster durante la configurazione delle connessioni al pool di Esplora dati. Quando si configurano gli SDK per l'inserimento dati, usare l'endpoint di inserimento dati.
- Nell'interfaccia utente Web di Esplora dati di Azure aggiungere una connessione all'endpoint di query.
- Selezionare Query dal menu a sinistra, fare clic con il pulsante destro del mouse sul database o sulla tabella e selezionare Inserisci nuovi dati.
- Prima di iniziare, seguire questa procedura per ottenere gli endpoint di query e inserimento dati.
Inserimento guidato con un clic
Nota
Questa sezione descrive la procedura guidata quando si usa l'hub eventi come origine dati. È anche possibile usare questi passaggi per inserire dati da un BLOB, un file, un contenitore BLOB e un contenitore ADLS Gen2.
Sostituire i valori di esempio con i valori effettivi per l'area di lavoro Synapse in uso.
Nella scheda Destinazione scegliere il database e la tabella per i dati inseriti.
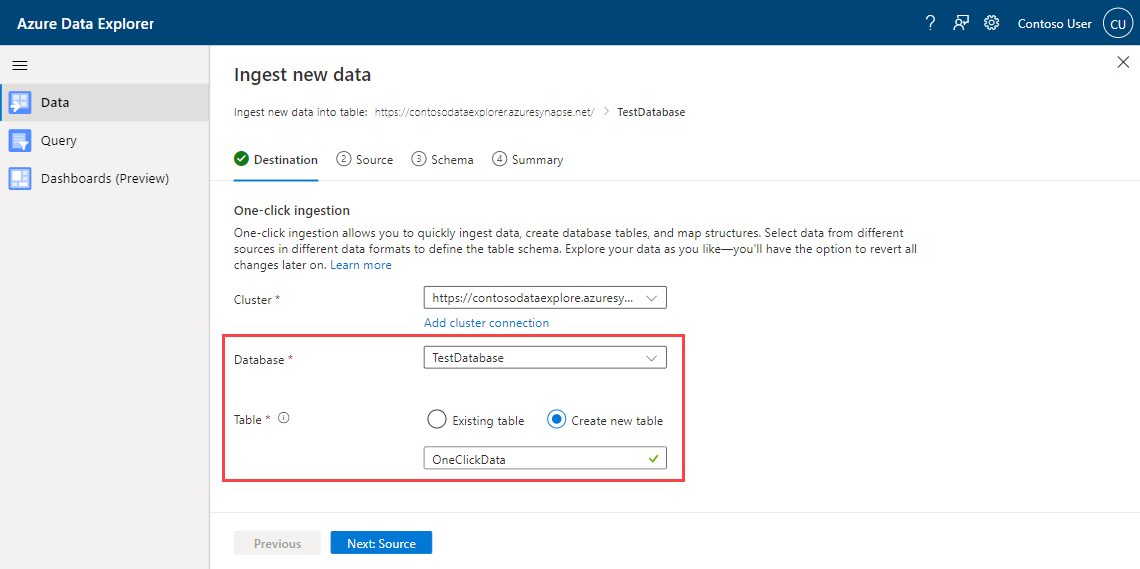
Nella scheda Origine:
Selezionare Hub eventi in Tipo di origine come tipo di origine per l'inserimento.

Compilare i dettagli della connessione dati dell'hub eventi usando le informazioni seguenti:
Impostazione Valore di esempio Descrizione Nome connessione dati ContosoDataConnection Nome della connessione dati dell'hub eventi Abbonamento Contoso_Synapse Sottoscrizione in cui si trova l'hub eventi. Spazio dei nomi dell'hub eventi contosoeventhubnamespace Spazio dei nomi dell'hub eventi. Gruppo di consumer contosoconsumergroup Nome del gruppo di consumer dell'hub eventi. 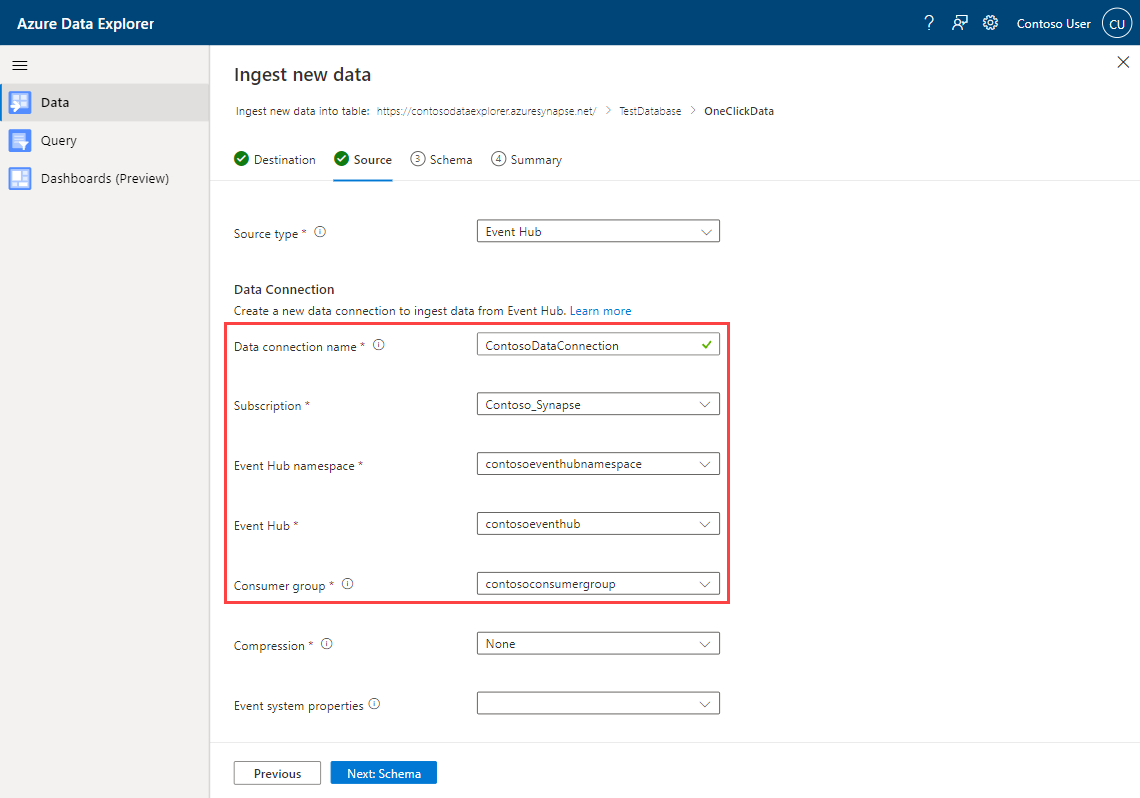
Selezionare Avanti.
Mapping dello schema
Il servizio genera automaticamente le proprietà di schema e inserimento, che è possibile cambiare. È possibile usare una struttura di mapping esistente o crearne una nuova, a seconda che i dati vengano inseriti in una tabella nuova o esistente.
Nella scheda Schema eseguire le azioni seguenti:
- Verificare il tipo di compressione generato automaticamente.
- Scegliere il formato dei dati. Formati diversi consentiranno di apportare ulteriori modifiche.
- Modificare il mapping nella finestra Editor.
Formati di file
L'inserimento con un clic può essere eseguito da origini dati in tutti i formati di dati supportati da Esplora dati per l'inserimento.
Finestra Editor
Nella finestra Editor della scheda Schema è possibile modificare le colonne della tabella dati in base alle esigenze.
Le modifiche che è possibile apportare in una tabella dipendono dai parametri seguenti:
- Il tipo di tabella è nuovo o esistente
- Il tipo di mapping è nuovo o esistente
| Tipo di tabella | Tipo di mapping | Modifiche disponibili |
|---|---|---|
| Nuova tabella | Nuovo mapping | Cambia tipo di dati, Rinomina colonna, Nuova colonna, Elimina colonna, Aggiorna colonna, Ordinamento crescente, Ordinamento decrescente |
| Tabella esistente | Nuovo mapping | Nuova colonna (per cui è poi possibile cambiare il tipo di dati, rinominare e aggiornare) Aggiorna colonna, Ordinamento crescente, Ordinamento decrescente |
| Mapping esistente | Ordinamento crescente, Ordinamento decrescente |
Nota
Quando si aggiunge una nuova colonna o se ne aggiorna una esistente, è possibile cambiare le trasformazioni di mapping. Per altre informazioni, vedere Trasformazioni di mapping
Trasformazioni del mapping
Alcuni mapping del formato dati (Parquet, JSON e Avro) supportano semplici trasformazioni in fase di inserimento. Per applicare le trasformazioni del mapping, creare o aggiornare una colonna nella finestra Editor.
Le trasformazioni del mapping possono essere eseguite su una colonna di tipo stringa o data/ora, con l'origine con un tipo di dati int o long. Le trasformazioni del mapping supportate sono:
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Inserimento dati
Dopo aver completato il mapping dello schema e le modifiche delle colonne, la procedura guidata avvierà il processo di inserimento dati.
Quando si inseriscono dati da origini non di contenitore, l'inserimento avrà effetto immediato.
Se l'origine dati è un contenitore:
- I dati vengono aggregati in base ai criteri di invio in batch di Esplora dati.
- Dopo l'inserimento, è possibile scaricare il relativo report ed esaminare le prestazioni di ogni BLOB coinvolto.
Esplorazione iniziale dei dati
Dopo l'inserimento, la procedura guidata offre le opzioni per usare comandi rapidi per l'esplorazione iniziale dei dati.