Come usare la replica Apache Hive nei cluster Azure HDInsight
Nel contesto di database e warehouse, la replica è il processo di duplicazione delle entità da un warehouse a un altro. La duplicazione può essere applicata a un intero database o a un livello inferiore, ad esempio una tabella o una partizione. L'obiettivo è disporre di una replica che cambia ogni volta che l'entità di base cambia. La replica in Apache Hive è incentrata sul ripristino di emergenza e offre una replica di copia primaria unidirezionale. Nei cluster HDInsight la replica Hive può essere usata per replicare in modo unidirezionale il metastore Hive e il data lake sottostante associato in Azure Data Lake Storage Gen2.
La replica Hive si è evoluta nel corso degli anni con versioni più recenti che offrono funzionalità migliori e un uso più rapido e meno intensivo delle risorse. In questo articolo viene descritta la replica (Replv2) Hive supportata nei tipi di cluster HDInsight 3.6 e HDInsight 4.0.
Vantaggi di replv2
La replica HiveV2 (chiamata Replv2anche ) presenta i vantaggi seguenti rispetto alla prima versione della replica Hive che usa Hive IMPORT-EXPORT:
- Replica incrementale basata su eventi
- Replica temporizzato
- Requisiti di larghezza di banda ridotti
- Riduzione del numero di copie intermedie
- Lo stato della replica viene mantenuto
- Replica vincolata
- Supporto per un modello Hub e Spoke
- Supporto per le tabelle ACID (in HDInsight 4.0)
Fasi di replica
La replica basata su eventi Hive è configurata tra i cluster primari e secondari. Questa replica è costituita da due fasi distinte: bootstrap e esecuzioni incrementali.
Bootstrap
Il bootstrap deve essere eseguito una sola volta per replicare lo stato di base dei database da primario a secondario. È possibile configurare il bootstrapping, se necessario, per includere un subset delle tabelle nel database di destinazione in cui è necessario abilitare la replica.
Esecuzioni incrementali
Dopo il bootstrap, le esecuzioni incrementali vengono automatizzate nel cluster primario e gli eventi generati durante queste esecuzioni incrementali vengono riprodotti nel cluster secondario. Quando il cluster secondario viene aggiornato con il cluster primario, il database secondario diventa coerente con gli eventi del database primario.
Comandi di replica
Hive offre un set di comandi REPL, DUMP, LOADe STATUS , per orchestrare il flusso di eventi. Il DUMP comando genera un log locale di tutti gli eventi DDL/DML nel cluster primario. Il LOAD comando è un approccio per copiare in modo differita i metadati e i dati registrati nell'output del dump della replica estratto e viene eseguito nel cluster di destinazione. Il STATUS comando viene eseguito dal cluster di destinazione per fornire l'ID evento più recente che il caricamento della replica più recente è stato replicato correttamente.
Impostare l'origine di replica
Prima di iniziare con la replica, verificare che il database da replicare sia impostato come origine di replica. È possibile usare il DESC DATABASE EXTENDED <db_name> comando per determinare se il parametro repl.source.for è impostato con il nome del criterio.
Se i criteri sono pianificati e il repl.source.for parametro non è impostato, è prima necessario impostare questo parametro usando ALTER DATABASE <db_name> SET DBPROPERTIES ('repl.source.for'='<policy_name>').
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source.for'='replpolicy1')
Eseguire il dump dei metadati nel data lake
Il REPL DUMP [database name]. => location / event_id comando viene usato nella fase bootstrap per eseguire il dump dei metadati pertinenti in Azure Data Lake Storage Gen2. event_id Specifica l'evento minimo a cui sono stati inseriti i metadati pertinenti in Azure Data Lake Storage Gen2.
repl dump tpcds_orc;
Output di esempio:
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0 | 2925 |
Caricare i dati nel cluster di destinazione
Il REPL LOAD [database name] FROM [ location ] { WITH ( ‘key1’=‘value1’{, ‘key2’=‘value2’} ) } comando viene usato per caricare i dati nel cluster di destinazione sia per il bootstrap che per le fasi incrementali della replica. [database name] può essere uguale all'origine o a un nome diverso nel cluster di destinazione. Rappresenta [location] la posizione dell'output del comando precedente REPL DUMP . Ciò significa che il cluster di destinazione deve essere in grado di comunicare con il cluster di origine. La WITH clausola è stata aggiunta principalmente per impedire il riavvio del cluster di destinazione, consentendo la replica.
repl load tpcds_orc from '/tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0';
Output dell'ultimo ID evento replicato
Il REPL STATUS [database name] comando viene eseguito nei cluster di destinazione e restituisce l'ultimo oggetto replicato event_id. Il comando consente inoltre agli utenti di conoscere lo stato in cui è stato replicato il cluster di destinazione. È possibile usare l'output di questo comando per costruire il comando successivo REPL DUMP per la replica incrementale.
repl status tpcds_orc;
Output di esempio:
| last_repl_id |
|---|
| 2925 |
Eseguire il dump dei dati e dei metadati pertinenti nel data lake
Il REPL DUMP [database name] FROM [event-id] { TO [event-id] } { LIMIT [number of events] } comando viene usato per eseguire il dump dei metadati e dei dati pertinenti in Azure Data Lake Storage. Questo comando viene usato nella fase incrementale e viene eseguito nel warehouse di origine. FROM [event-id] È necessario per la fase incrementale e il valore di event-id può essere derivato eseguendo il REPL STATUS [database name] comando nel magazzino di destinazione.
repl dump tpcds_orc from 2925;
Output di esempio:
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-466466agadd0 | 2960 |
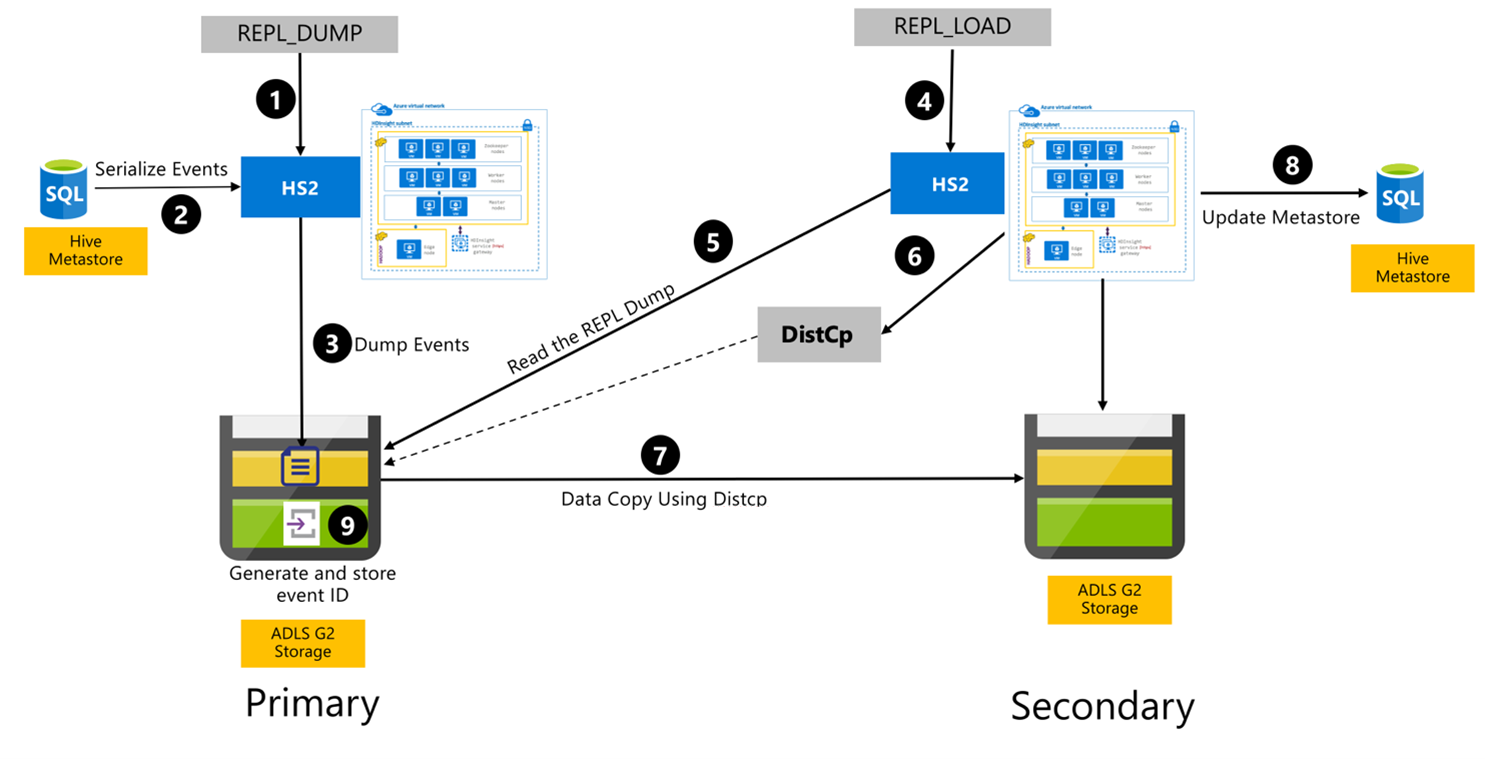
Processo di replica Hive
I passaggi seguenti sono gli eventi sequenziali che si verificano durante il processo di replica Hive.
Assicurarsi che le tabelle da replicare siano impostate come origine di replica per un determinato criterio.
Il
REPL_DUMPcomando viene eseguito nel cluster primario con vincoli associati, ad esempio nome del database, intervallo di ID evento e URL di archiviazione di Azure Data Lake Storage Gen2.Il sistema serializza un dump di tutti gli eventi rilevati dal metastore alla versione più recente. Questo dump viene archiviato nell'account di archiviazione di Azure Data Lake Storage Gen2 nel cluster primario nell'URL specificato da
REPL_DUMP.Il cluster primario rende persistenti i metadati di replica nell'archiviazione di Azure Data Lake Storage Gen2 del cluster primario. Il percorso è configurabile nell'interfaccia utente di configurazione Hive in Ambari. Il processo fornisce il percorso in cui vengono archiviati i metadati e l'ID dell'evento DML/DDL rilevato più recente.
Il
REPL_LOADcomando viene eseguito dal cluster secondario. Il comando punta al percorso configurato nel passaggio 3.Il cluster secondario legge il file di metadati con gli eventi rilevati creati nel passaggio 3. Assicurarsi che il cluster secondario disponga della connettività di rete all'archiviazione di Azure Data Lake Storage Gen2 del cluster primario da
REPL_DUMPcui sono archiviati gli eventi rilevati.Il cluster secondario genera un calcolo di copia distribuita (
DistCP).Il cluster secondario copia i dati dall'archiviazione del cluster primario.
Il metastore nel cluster secondario viene aggiornato.
L'ultimo ID evento rilevato viene archiviato nel metastore primario.
La replica incrementale segue lo stesso processo e richiede l'ultimo ID evento replicato come input. Ciò porta a una copia incrementale dall'ultimo evento di replica. Le repliche incrementali vengono in genere automatizzate con una frequenza pre-determinata per raggiungere gli obiettivi del punto di ripristino (RPO) necessari.
Modelli di replica
La replica viene in genere configurata in modo unidirezionale tra il database primario e quello secondario, in cui il database primario è adatto alle richieste di lettura e scrittura. Il cluster secondario è adatto solo alle richieste di lettura. Le scritture sono consentite nel database secondario in caso di emergenza, ma la replica inversa deve essere configurata nuovamente nel database primario.
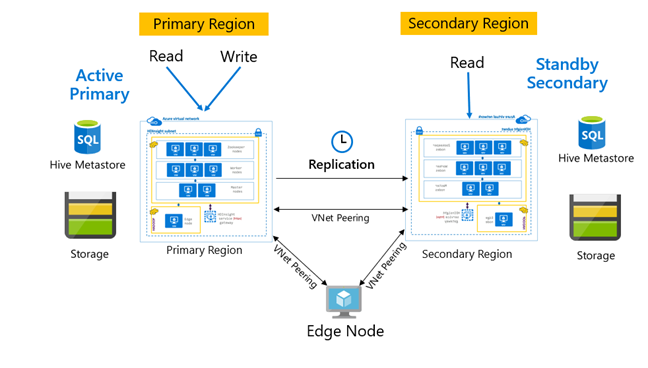
Esistono molti modelli adatti per la replica Hive, tra cui primario, secondario, hub e spoke e inoltro.
In HDInsight Active Primary – Standby Secondary è un modello di continuità aziendale e ripristino di emergenza (BCDR) comune e HiveReplicationV2 può usare questo modello con cluster Hadoop HDInsight separati a livello di area con peering reti virtuali. È possibile usare una macchina virtuale comune con peering a entrambi i cluster per ospitare gli script di automazione della replica. Per altre informazioni sui possibili modelli BCDR di HDInsight, vedere la documentazione sulla continuità aziendale di HDInsight.
Replica Hive con Enterprise Security Package
Nei casi in cui la replica Hive è pianificata nei cluster Hadoop HDInsight con Enterprise Security Package, è necessario tenere conto dei meccanismi di replica per il metastore Ranger e Microsoft Entra Domain Services.
Usare la funzionalità set di repliche di Microsoft Entra Domain Services per creare più repliche di Microsoft Entra Domain Services impostate per ogni tenant di Microsoft Entra in più aree. Ogni singolo set di repliche deve essere sottoposto a peering con reti virtuali HDInsight nelle rispettive aree. In questa configurazione, le modifiche apportate a Microsoft Entra Domain Services, tra cui configurazione, identità utente e credenziali, gruppi, oggetti criteri di gruppo, oggetti computer e altre modifiche vengono applicate a tutti i set di repliche nel dominio gestito tramite la replica di Microsoft Entra Domain Services.
È possibile eseguire periodicamente il backup e la replica dei criteri Ranger dal database primario al database secondario usando la funzionalità Import-Export di Ranger. È possibile scegliere di replicare tutti o un subset di criteri Ranger a seconda del livello di autorizzazione che si sta cercando di implementare nel cluster secondario.
Codice di esempio
La sequenza di codice seguente fornisce un esempio del modo in cui è possibile implementare il bootstrap e la replica incrementale in una tabella di esempio denominata tpcds_orc.
Impostare la tabella come origine per i criteri di replica.
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source. for'='replpolicy1');Dump bootstrap nel cluster primario.
repl dump tpcds_orc with ('hive.repl.rootdir'='/tmpag/hiveag/replag');Output di esempio:
dump_dir last_repl_id /tmpag/hiveag/replag/675d1bea-2361-4cad-bcbf-8680d305a27a 2925 Caricamento bootstrap nel cluster secondario.
repl load tpcds_orc from '/tmpag/hiveag/replag 675d1bea-2361-4cad-bcbf-8680d305a27a';Controllare lo
REPLstato nel cluster secondario.repl status tpcds_orc;last_repl_id 2925 Dump incrementale nel cluster primario.
repl dump tpcds_orc from 2925 with ('hive.repl.rootdir'='/tmpag/hiveag/ replag');Output di esempio:
dump_dir last_repl_id /tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31 2960 Caricamento incrementale nel cluster secondario.
repl load tpcds_orc from '/tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31';Controllare
REPLlo stato nel cluster secondario.repl status tpcds_orc;last_repl_id 2960
Passaggi successivi
Per altre informazioni sugli elementi descritti in questo articolo, vedere: