Esercitazione: Copiare dati in Azure Data Box Heavy tramite NFS
Questa esercitazione descrive come connettersi al computer host e copiarne i dati usando l'Interfaccia utente Web locale di Azure Data Box Heavy.
In questa esercitazione apprenderai a:
- Prerequisiti
- Connettersi a Data Box Heavy
- Copiare i dati in Data Box Heavy
Prerequisiti
Prima di iniziare, verificare che:
- È stata completata l'esercitazione : Configurare Azure Data Box Heavy.
- Aver ricevuto Data Box Heavy e che lo stato dell'ordine nel portale sia Recapitato.
- Avere un computer host con i dati da copiare in Data Box Heavy. Il computer host deve
- Eseguire un sistema operativo supportato.
- Essere connesso a una rete ad alta velocità. Per una velocità di copia più veloce, è possibile utilizzare in parallelo due connessioni da 40 GbE (una per nodo). Se non si dispone di una connessione da 40 GbE, si consiglia di avere almeno due connessioni da 10 GbE (una per nodo).
Connettersi a Data Box Heavy
In base all'account di archiviazione selezionato, Data Box Heavy crea fino a:
- Tre condivisioni per ogni account di archiviazione associato per GPv1 e GPv2.
- Una condivisione per l'archiviazione Premium.
- Una condivisione per l'account di archiviazione BLOB.
Queste condivisioni vengono create in entrambi i nodi del dispositivo.
Nelle condivisioni di BLOB in blocchi e BLOB di pagine:
- Le entità di primo livello sono contenitori.
- Le entità di secondo livello sono BLOB.
Nelle condivisioni per File di Azure:
- Le entità di primo livello sono condivisioni.
- Le entità di secondo livello sono file.
La tabella seguente mostra il percorso UNC delle condivisioni in Data Box Heavy e l'URL del percorso di Archiviazione di Azure in cui vengono caricati i dati. L'URL del percorso finale di Archiviazione di Azure può essere derivato dal percorso UNC della condivisione.
| Storage | Percorso UNC |
|---|---|
| BLOB in blocchi di Azure | //<DeviceIPAddress>/<StorageAccountName_BlockBlob>/<ContainerName>/files/a.txthttps://<StorageAccountName>.blob.core.windows.net/<ContainerName>/files/a.txt |
| BLOB di pagine di Azure | //<DeviceIPAddress>/<StorageAccountName_PageBlob>/<ContainerName>/files/a.txthttps://<StorageAccountName>.blob.core.windows.net/<ContainerName>/files/a.txt |
| File di Azure | //<DeviceIPAddress>/<StorageAccountName_AzFile>/<ShareName>/files/a.txthttps://<StorageAccountName>.file.core.windows.net/<ShareName>/files/a.txt |
Se si usa un computer host Linux, eseguire la procedura seguente per configurare il dispositivo in modo da consentire l'accesso ai client NFS.
Specificare l'indirizzo IP dei client autorizzati ad accedere alla condivisione. Nell'interfaccia utente Web locale passare alla pagina Connetti e copia. In Impostazioni NFS fare clic su Accesso client NFS.
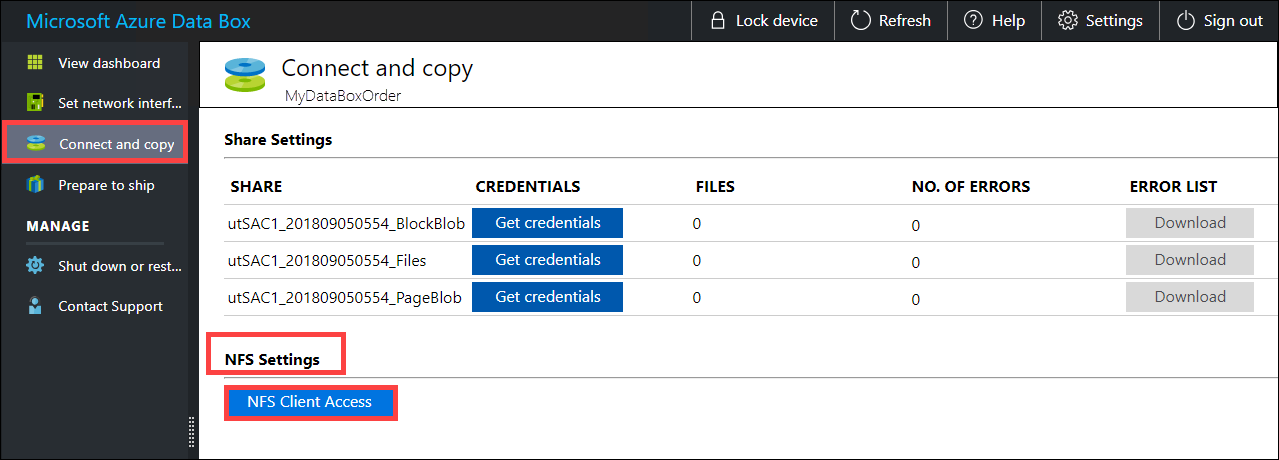
Specificare l'indirizzo IP del client NFS e fare clic su Aggiungi. Per configurare l'accesso per più client NFS, ripetere questa procedura. Fare clic su OK.
Verificare che nel computer host Linux sia installata una versione supportata del client NFS. Usare la versione specifica della distribuzione Linux in uso.
Dopo l'installazione del client NFS, usare il comando seguente per montare la condivisione NFS nel dispositivo Data Box:
sudo mount <Data Box Heavy device IP>:/<NFS share on Data Box Heavy device> <Path to the folder on local Linux computer>L'esempio seguente mostra come connettersi tramite NFS a una condivisione del Data Box Heavy. L'indirizzo IP del Data Box Heavy è
10.161.23.130e la condivisioneMystoracct_Blobviene montata sulla macchina virtuale Ubuntu, dato che il punto di montaggio è/home/databoxheavyubuntuhost/databoxheavy.sudo mount -t nfs 10.161.23.130:/Mystoracct_Blob /home/databoxheavyubuntuhost/databoxheavyPer i client Mac, è necessario aggiungere un'altra opzione in questo modo:
sudo mount -t nfs -o sec=sys,resvport 10.161.23.130:/Mystoracct_Blob /home/databoxheavyubuntuhost/databoxheavyCreare sempre una cartella per i file che si intendono copiare nella condivisione e quindi copiare i file in tale cartella. La cartella creata nelle condivisioni di BLOB in blocchi e BLOB di pagine rappresenta un contenitore in cui i dati vengono caricati come BLOB. Non è possibile copiare direttamente i file nella cartella root dell'account di archiviazione.
Copiare i dati in Data Box Heavy
Dopo aver stabilito la connessione alle condivisioni Data Box Heavy, il passaggio successivo consiste nel copiare i dati. Prima di procedere alla copia dei dati, tenere conto delle considerazioni seguenti:
Assicurarsi di copiare i dati nelle condivisioni corrispondenti al formato dati appropriato. Ad esempio, copiare i dati del BLOB in blocchi nella condivisione per i BLOB in blocchi. Copiare i dischi rigidi virtuali nei BLOB di pagine. Se il formato dei dati non corrisponde al tipo di condivisione appropriato, il caricamento dei dati in Azure non riuscirà.
Durante la copia dei dati, assicurarsi che le dimensioni dei dati siano conformi ai valori descritti nei limiti per il servizio di archiviazione di Azure e per Data Box Heavy.
Se i dati caricati da Data Box Heavy vengono caricati contemporaneamente da altre applicazioni all'esterno di Data Box Heavy, è possibile che si verifichino errori del processo di caricamento e il danneggiamento dei dati.
È consigliabile non usare SMB e NFS contemporaneamente né copiare gli stessi dati nella stessa destinazione finale in Azure. In questi casi il risultato finale non può essere determinato.
Creare sempre una cartella per i file che si intendono copiare nella condivisione e quindi copiare i file in tale cartella. La cartella creata nelle condivisioni di BLOB in blocchi e BLOB di pagine rappresenta un contenitore in cui i dati vengono caricati come BLOB. Non è possibile copiare direttamente i file nella cartella root dell'account di archiviazione.
In caso di inserimento di nomi di file e directory che fanno distinzione tra maiuscole e minuscole da una condivisione NFS a NFS in Data Box Heavy:
- Nel nome verrà mantenuta la distinzione tra maiuscole e minuscole.
- Per i file non verrà applicata la distinzione tra maiuscole e minuscole.
Se ad esempio vengono copiati
SampleFile.txteSamplefile.Txt, le maiuscole e le minuscole verranno mantenute nel nome copiato nel dispositivo, ma il secondo file sovrascriverà il primo perché i due file verranno considerati uguali.
Se si usa un computer host Linux, usare un'utilità di copia simile a Robocopy. Alcune soluzioni alternative disponibili in Linux sono rsync, FreeFileSync, Unison e Ultracopier.
Il comando cp è una delle opzioni migliori per copiare una directory. Per altre informazioni sulla sintassi, vedere cp man-pages.
Se si usa l'opzione rsync per una copia multithread, seguire queste indicazioni:
Installare il pacchetto CIFS Utils o NFS Utils in base al file system usato dal client Linux.
sudo apt-get install cifs-utilssudo apt-get install nfs-utilsInstallare Rsync e Parallel (varia in base alla versione distribuita di Linux).
sudo apt-get install rsyncsudo apt-get install parallelCreare un punto di montaggio.
sudo mkdir /mnt/databoxheavyMontare il volume.
sudo mount -t NFS4 //Databox-heavy-IP-Address/share_name /mnt/databoxheavyEseguire il mirroring della struttura di directory delle cartelle.
rsync -za --include='*/' --exclude='*' /local_path/ /mnt/databoxheavyCopiare i file.
cd /local_path/; find -L . -type f | parallel -j X rsync -za {} /mnt/databoxheavy/{}dove j specifica il numero di parallelizzazione, X = numero di copie parallele
È consigliabile iniziare con 16 copie parallele e aumentare il numero di thread in base alle risorse disponibili.
Importante
Non sono supportati i tipi di file Linux seguenti: collegamenti simbolici, file di caratteri, file di blocco, socket e pipe. Questi tipi di file causeranno errori durante la fase Prepara per la spedizione.
Aprire la cartella di destinazione per visualizzare e verificare i file copiati. In caso di errori durante il processo di copia, scaricare i file di log degli errori per la risoluzione dei problemi. Per altre informazioni, vedere Visualizzare i log degli errori durante la copia dei dati in Data Box Heavy. Per un elenco dettagliato degli errori durante la copia dei dati, vedere Risolvere i problemi di Data Box Heavy.
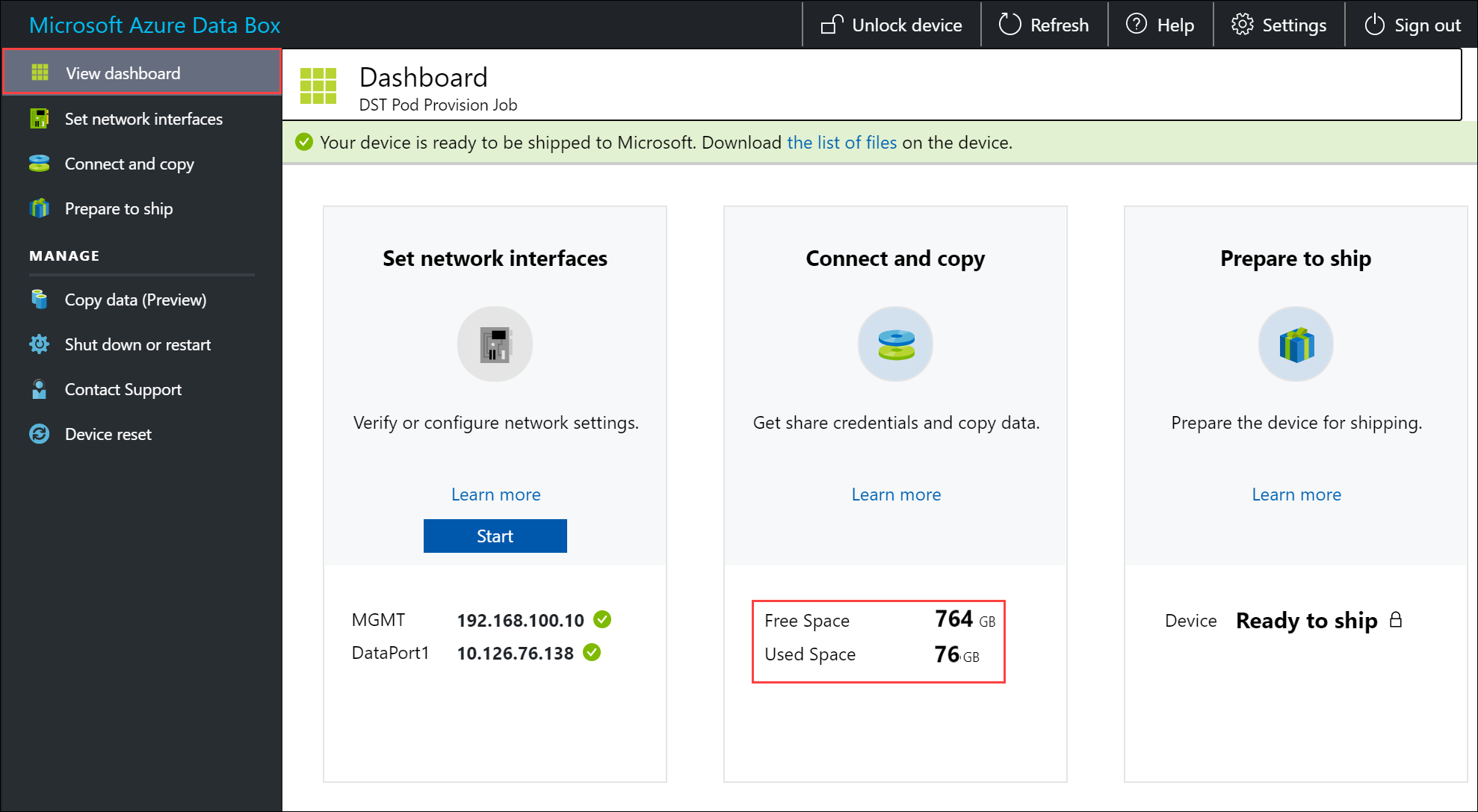
Per assicurare l'integrità dei dati, il checksum viene calcolato inline durante la copia dei dati. Al termine della copia, verificare lo spazio occupato e lo spazio disponibile nel dispositivo.
Passaggi successivi
In questa esercitazione sono stati presentati argomenti relativi ad Azure Data Box Heavy, ad esempio:
- Prerequisiti
- Connettersi a Data Box Heavy
- Copiare i dati in Data Box Heavy
Passare all'esercitazione successiva per informazioni su come riconsegnare Data Box a Microsoft.