Trasformazione con Azure Databricks
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
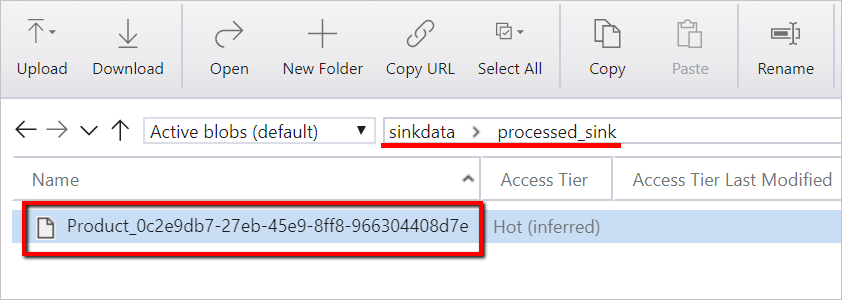
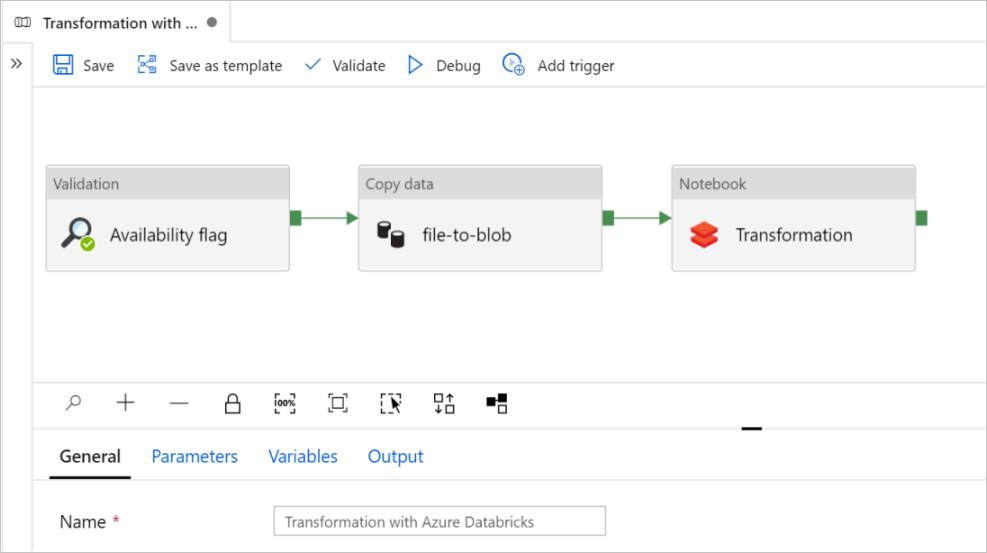
In questa esercitazione viene creata una pipeline end-to-end che contiene le attività Convalida, Copia dati e Notebook in Azure Data Factory.
La convalida garantisce che il set di dati di origine sia pronto per l'utilizzo downstream prima di attivare il processo di copia e analisi.
Copiare i dati duplica il set di dati di origine nell'archiviazione sink, montato come DBFS nel notebook di Azure Databricks. In questo modo, il set di dati può essere usato direttamente da Spark.
Il notebook attiva il notebook di Databricks che trasforma il set di dati. Aggiunge anche il set di dati a una cartella elaborata o ad Azure Synapse Analytics.
Per semplicità, il modello in questa esercitazione non crea un trigger pianificato. Se necessario, è possibile aggiungerne uno.
Prerequisiti
Un account di archiviazione BLOB di Azure con un contenitore chiamato
sinkdataper l'uso come sink.Prendere nota del nome dell'account di archiviazione, del nome del contenitore e della chiave di accesso. Questi valori saranno necessari più avanti nel modello.
Un'area di lavoro di Azure Databricks.
Importare un notebook per la trasformazione
Per importare un notebook di trasformazione nell'area di lavoro di Databricks:
Accedere all'area di lavoro di Azure Databricks.
Fare clic con il pulsante destro del mouse su una cartella nell'area di lavoro e scegliere Importa.
Selezionare Importa da: URL. Nella casella di testo immettere
https://adflabstaging1.blob.core.windows.net/share/Transformations.html.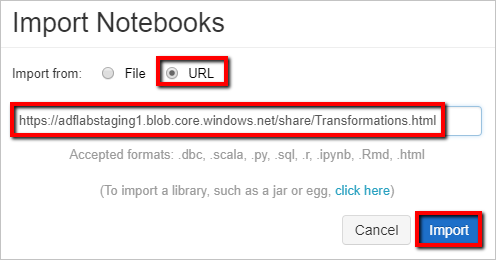
A questo punto, aggiornare il notebook di trasformazione con le informazioni di connessione all'archiviazione.
Nel notebook importato passare al comando 5 , come illustrato nel frammento di codice seguente.
- Sostituire
<storage name>e<access key>con le proprie informazioni di connessione di archiviazione. - Usare l'account di archiviazione con il
sinkdatacontenitore.
# Supply storageName and accessKey values storageName = "<storage name>" accessKey = "<access key>" try: dbutils.fs.mount( source = "wasbs://sinkdata\@"+storageName+".blob.core.windows.net/", mount_point = "/mnt/Data Factorydata", extra_configs = {"fs.azure.account.key."+storageName+".blob.core.windows.net": accessKey}) except Exception as e: # The error message has a long stack track. This code tries to print just the relevant line indicating what failed. import re result = re.findall(r"\^\s\*Caused by:\s*\S+:\s\*(.*)\$", e.message, flags=re.MULTILINE) if result: print result[-1] \# Print only the relevant error message else: print e \# Otherwise print the whole stack trace.- Sostituire
Generare un token di accesso di Databricks per consentire a Data Factory di accedere a Databricks.
- Nell'area di lavoro di Azure Databricks selezionare il nome utente di Azure Databricks nella barra superiore e quindi selezionare Impostazioni nell'elenco a discesa.
- Selezionare Sviluppatore.
- Accanto a Token di accesso selezionare Gestisci.
- Selezionare Genera nuovo token.
- (Facoltativo) Immettere un commento che consente di identificare questo token in futuro e modificare la durata predefinita del token di 90 giorni. Per creare un token senza durata (scelta non consigliata), lasciare vuota la casella Durata (giorni) (vuota).
- Selezionare Genera.
- Copiare il token visualizzato in un percorso sicuro e quindi selezionare Fine.
Salvare il token di accesso per usarlo in un secondo momento nella creazione di un servizio collegato Databricks. Il token di accesso ha un aspetto simile a dapi32db32cbb4w6eee18b7d87e45exxxxxx.
Come usare questo modello
Passare al modello Trasformazione con Azure Databricks e creare nuovi servizi collegati per le connessioni seguenti.
Connessione BLOB di origine: per accedere ai dati di origine.
Per questo esercizio, è possibile usare l'archivio BLOB pubblico che contiene i file di origine. Fare riferimento allo screenshot seguente per la configurazione. Usare l'URL di firma di accesso condiviso seguente per connettersi all'archiviazione di origine (accesso in sola lettura):
https://storagewithdata.blob.core.windows.net/data?sv=2018-03-28&si=read%20and%20list&sr=c&sig=PuyyS6%2FKdB2JxcZN0kPlmHSBlD8uIKyzhBWmWzznkBw%3D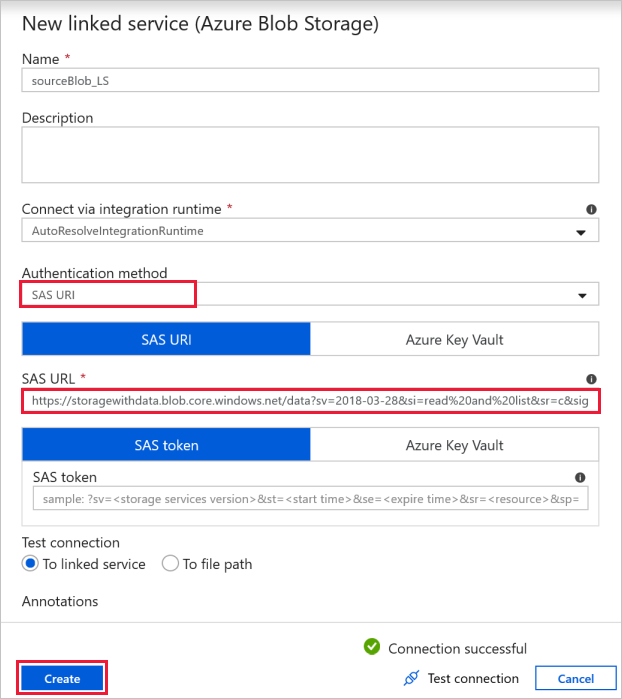
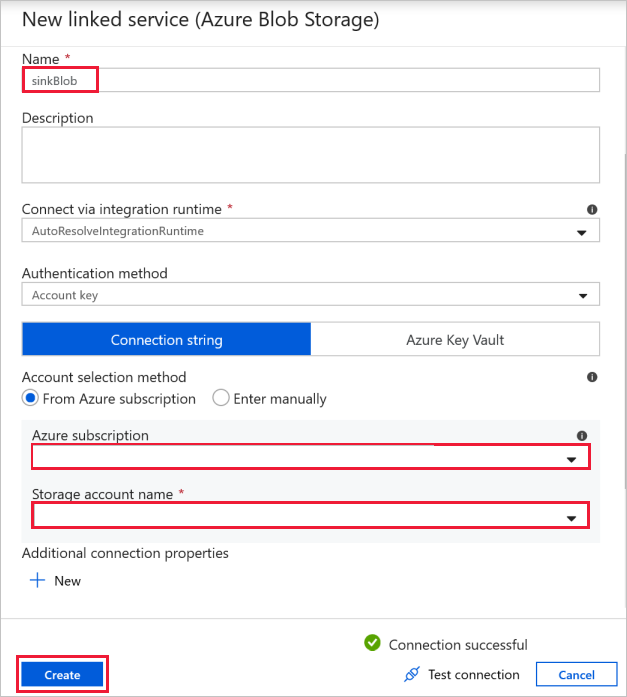
Connessione BLOB di destinazione: per archiviare i dati copiati.
Nella finestra Nuovo servizio collegato selezionare il BLOB di archiviazione sink.
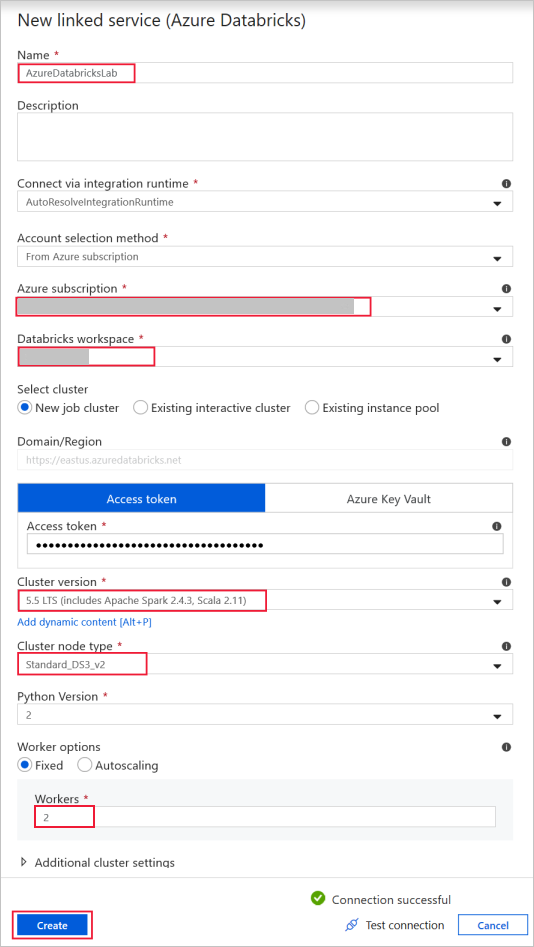
Azure Databricks : per connettersi al cluster Databricks.
Creare un servizio collegato a Databricks usando la chiave di accesso generata in precedenza. Se disponibile, è possibile scegliere di selezionare un cluster interattivo. In questo esempio viene usata l'opzione Nuovo cluster di processi .
Selezionare Usa questo modello. Verrà visualizzata una pipeline creata.
Introduzione e configurazione della pipeline
Nella nuova pipeline la maggior parte delle impostazioni viene configurata automaticamente con i valori predefiniti. Esaminare le configurazioni della pipeline e apportare le modifiche necessarie.
Nel flag Di disponibilità dell'attività di convalida verificare che il valore del set di dati di origine sia impostato su
SourceAvailabilityDatasetquello creato in precedenza.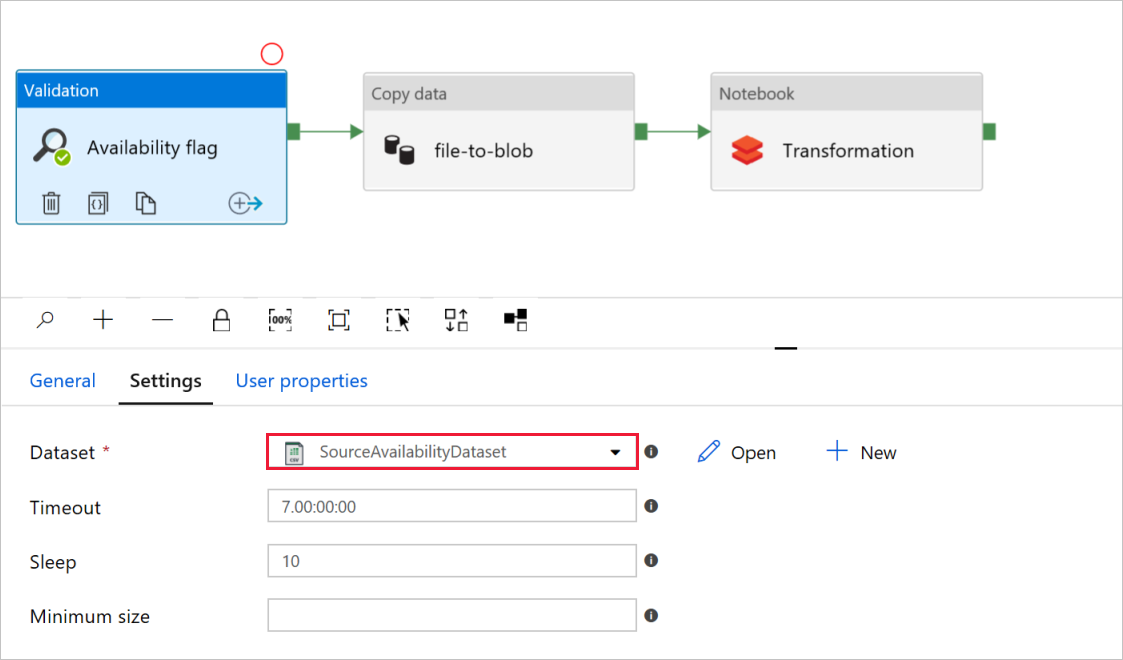
Nella scheda Copia file attività datiin BLOB selezionare le schede Origine e Sink. Modificare le impostazioni, se necessario.
Scheda Origine
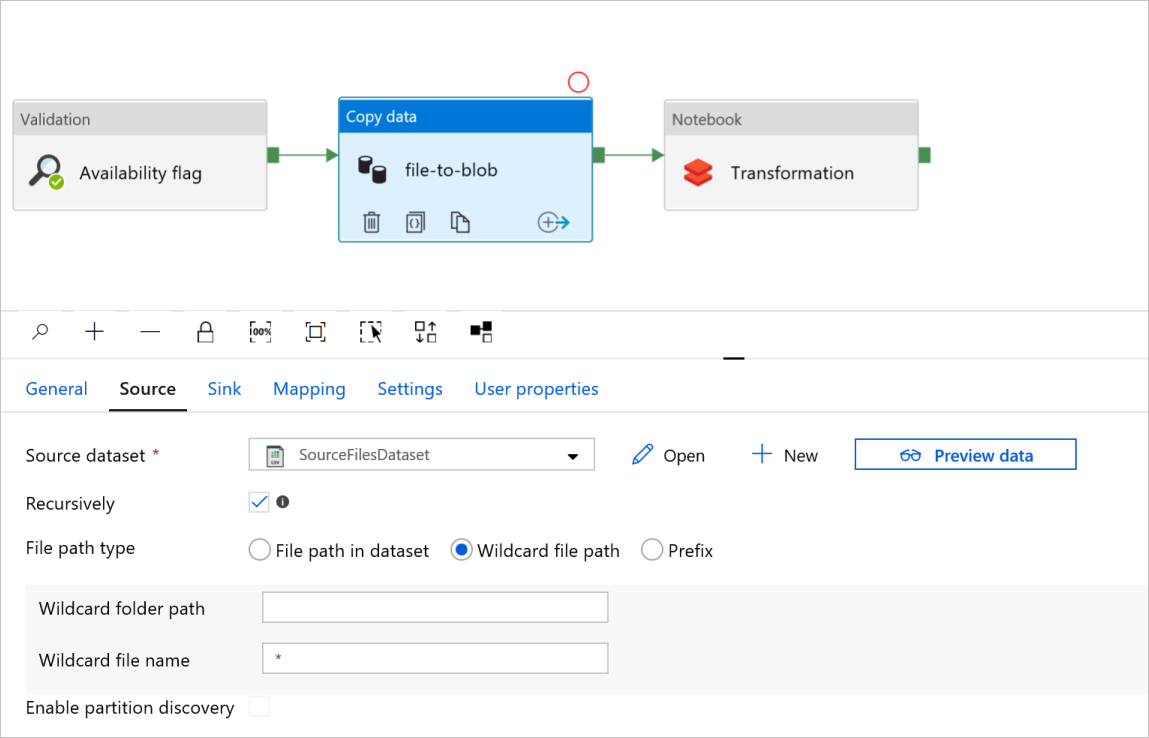
Scheda Sink
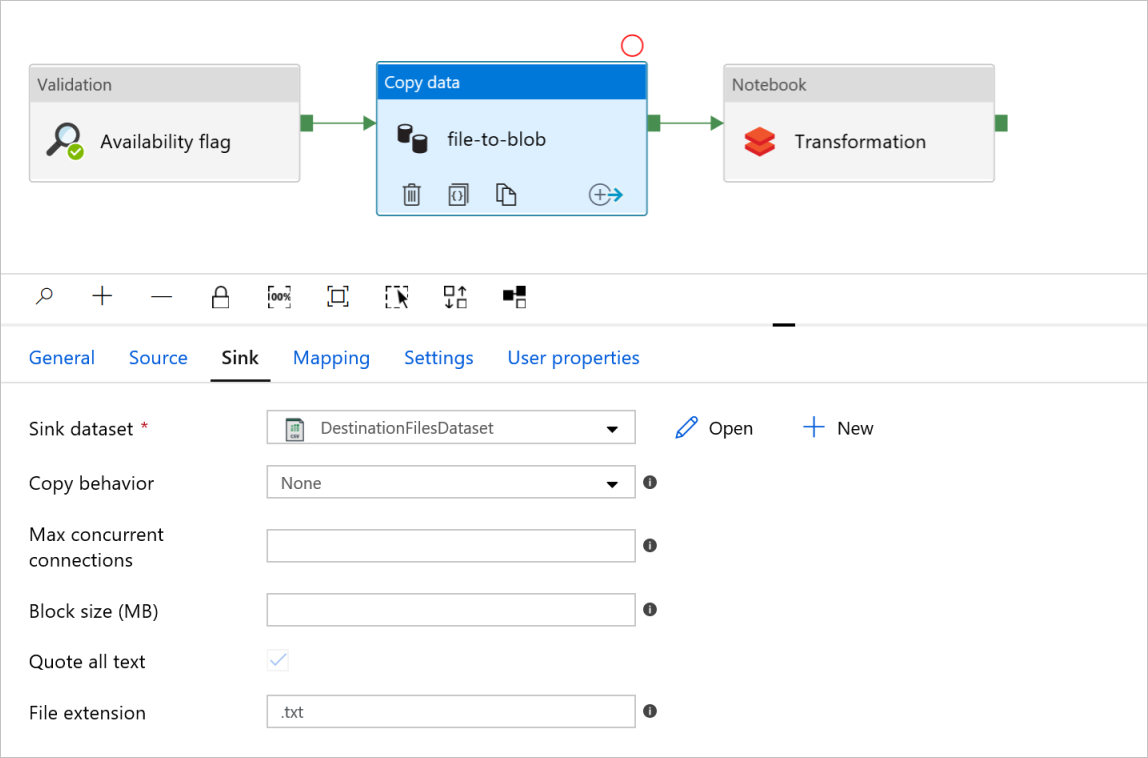
Nella trasformazione Attività notebook esaminare e aggiornare i percorsi e le impostazioni in base alle esigenze.
Il servizio collegato Databricks deve essere precompilato con il valore di un passaggio precedente, come illustrato di seguito:
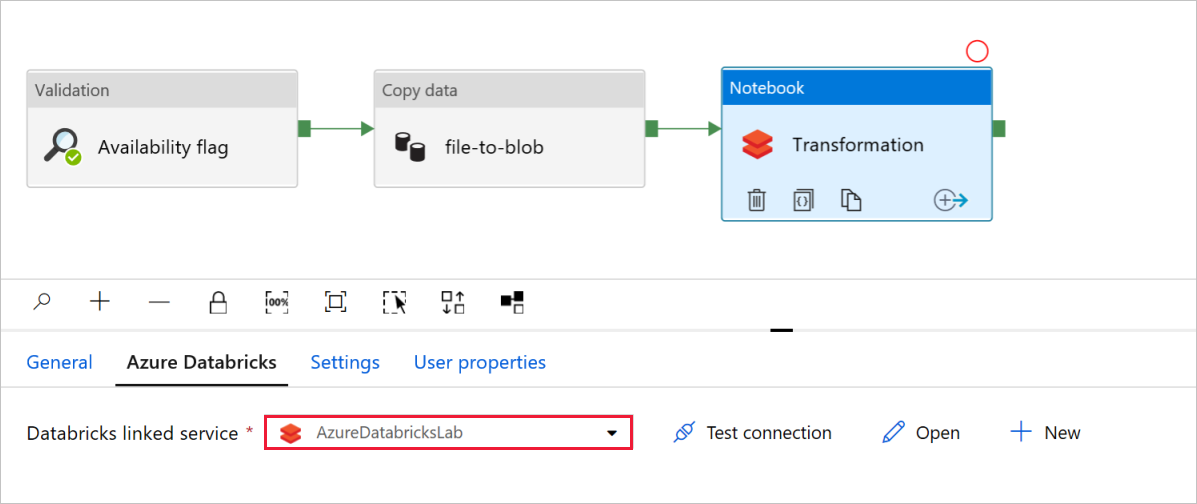
Per controllare le impostazioni del notebook :
Selezionare la scheda Impostazioni . Per Percorso notebook verificare che il percorso predefinito sia corretto. Potrebbe essere necessario esplorare e scegliere il percorso corretto del notebook.
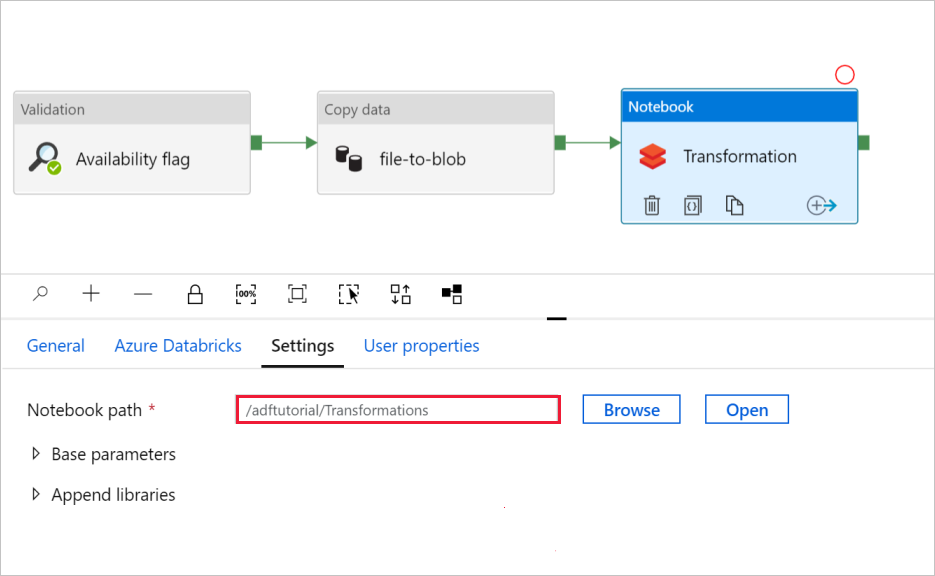
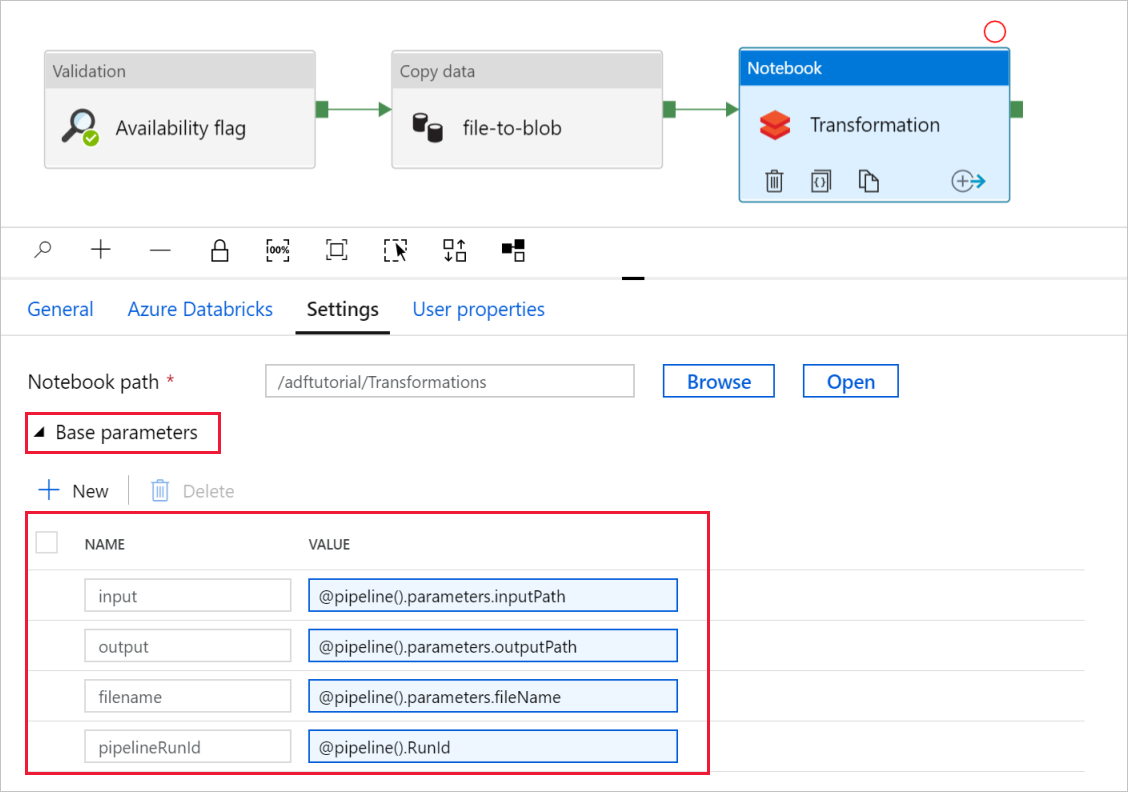
Espandere il selettore Parametri di base e verificare che i parametri corrispondano a quanto illustrato nello screenshot seguente. Questi parametri vengono passati al notebook di Databricks da Data Factory.
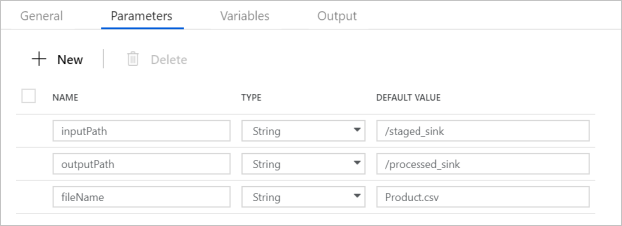
Verificare che i parametri della pipeline corrispondano a quanto illustrato nello screenshot seguente:
Connettersi ai set di dati.
Nota
Nei set di dati seguenti il percorso del file è stato specificato automaticamente nel modello. Se sono necessarie modifiche, assicurarsi di specificare il percorso sia per il contenitoreche per la directory in caso di errore di connessione.
SourceAvailabilityDataset : per verificare che i dati di origine siano disponibili.
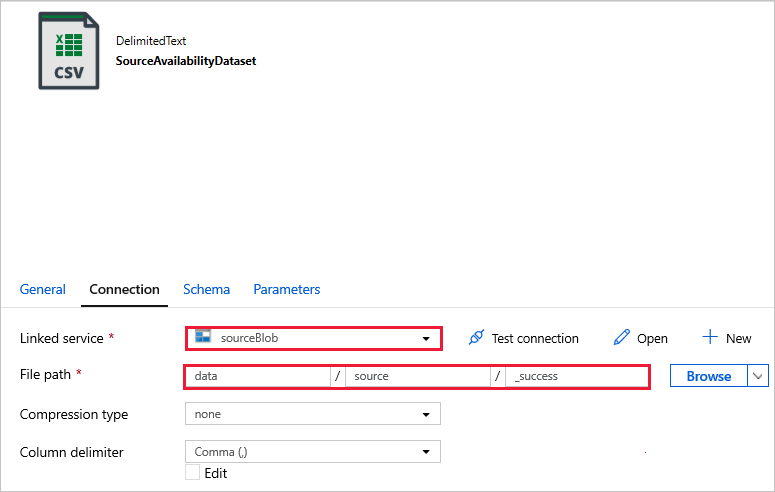
SourceFilesDataset : per accedere ai dati di origine.
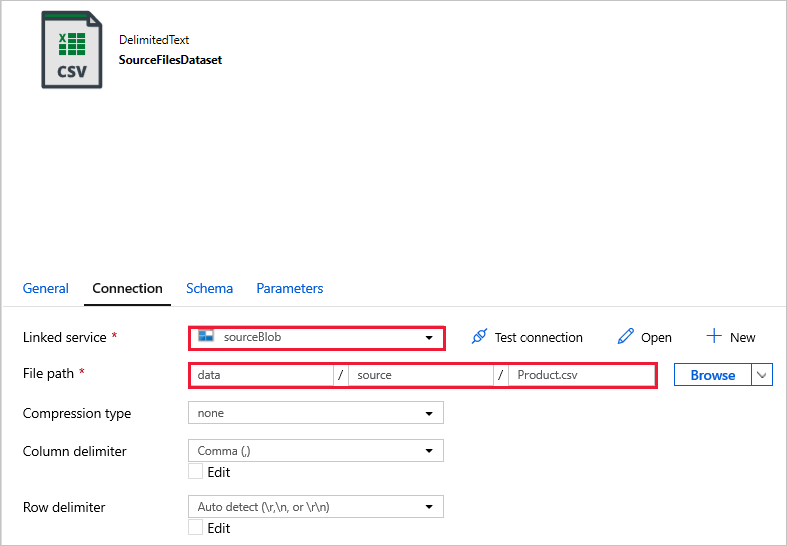
DestinationFilesDataset : per copiare i dati nella posizione di destinazione del sink. Usare i valori seguenti:
-
sinkBlob_LSServizio collegato, creato in un passaggio precedente.Percorso file -
sinkdata/staged_sink.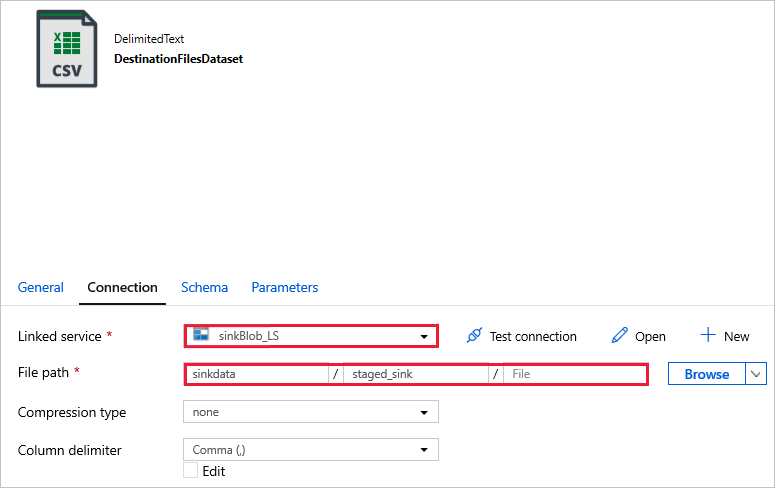
Selezionare Debug per eseguire la pipeline. È possibile trovare il collegamento ai log di Databricks per i log spark più dettagliati.
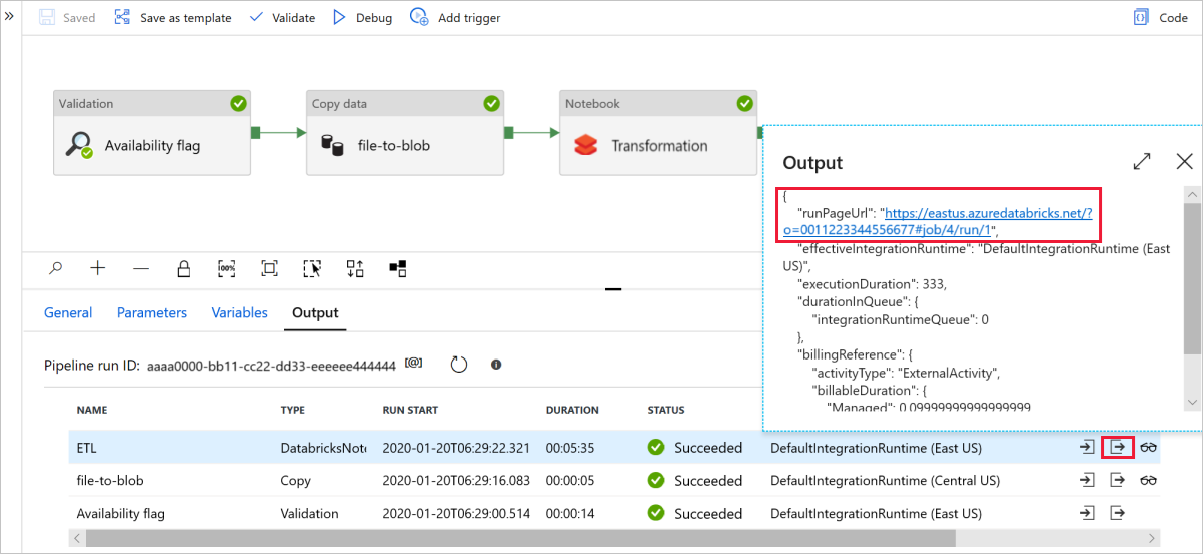
È anche possibile verificare il file di dati usando Archiviazione di Azure Explorer.
Nota
Per la correlazione con le esecuzioni della pipeline di Data Factory, questo esempio aggiunge l'ID di esecuzione della pipeline dalla data factory alla cartella di output. Ciò consente di tenere traccia dei file generati da ogni esecuzione.