Trasformazione Unione nel flusso di dati di mapping
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
I flussi di dati sono disponibili nelle pipeline sia di Azure Data Factory che di Azure Synapse. Questo articolo si applica ai flussi di dati per mapping. Se non si ha esperienza con le trasformazioni, vedere l'articolo introduttivo Trasformare i dati con un flusso di dati per mapping.
La trasformazione Unione consente di unire più flussi di dati in uno solo, con un'operazione Union SQL di tali flussi come nuovo output dalla trasformazione Unione. Tutti gli schemi di ogni flusso di input verranno combinati all'interno del flusso di dati, senza dover disporre di una chiave di join.
È possibile combinare n numero di flussi nella tabella delle impostazioni selezionando l'icona "+" accanto a ogni riga configurata, inclusi i dati di origine e i flussi dalle trasformazioni esistenti nel flusso di dati.
Di seguito è riportato un breve video di trasformazione dell'unione nel flusso di dati di mapping:
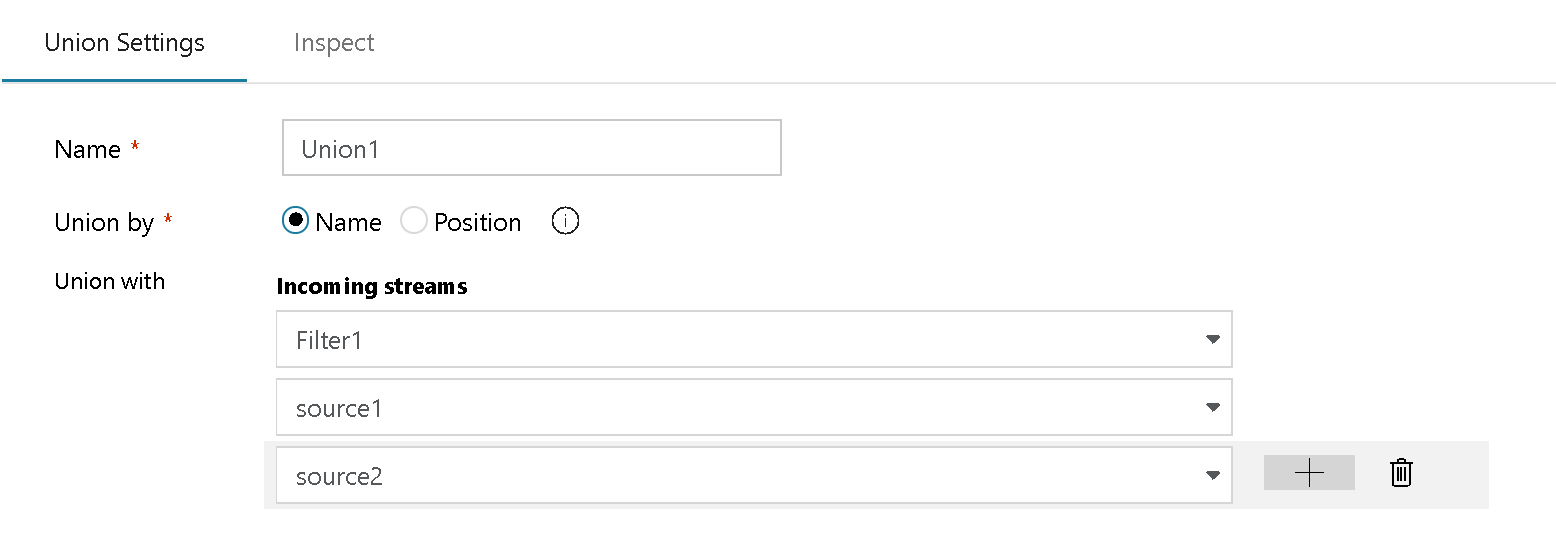
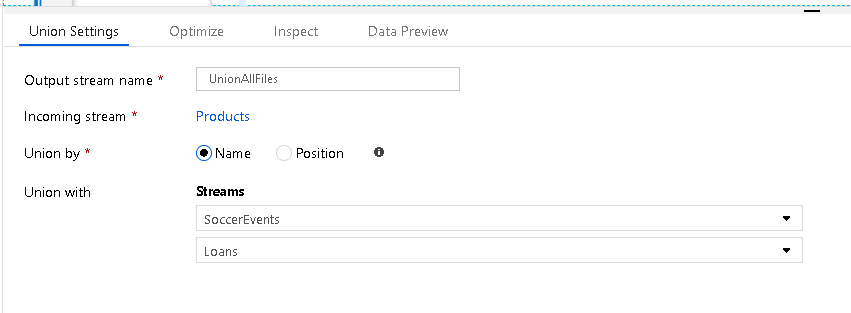
In questo caso, è possibile combinare metadati diversi da più origini (in questo esempio tre file di origine diversi) e combinarli in un singolo flusso:

A tale scopo, aggiungere altre righe in Impostazioni unione includendo tutte le origini da aggiungere. Non è necessario eseguire una ricerca o una chiave di join comune:
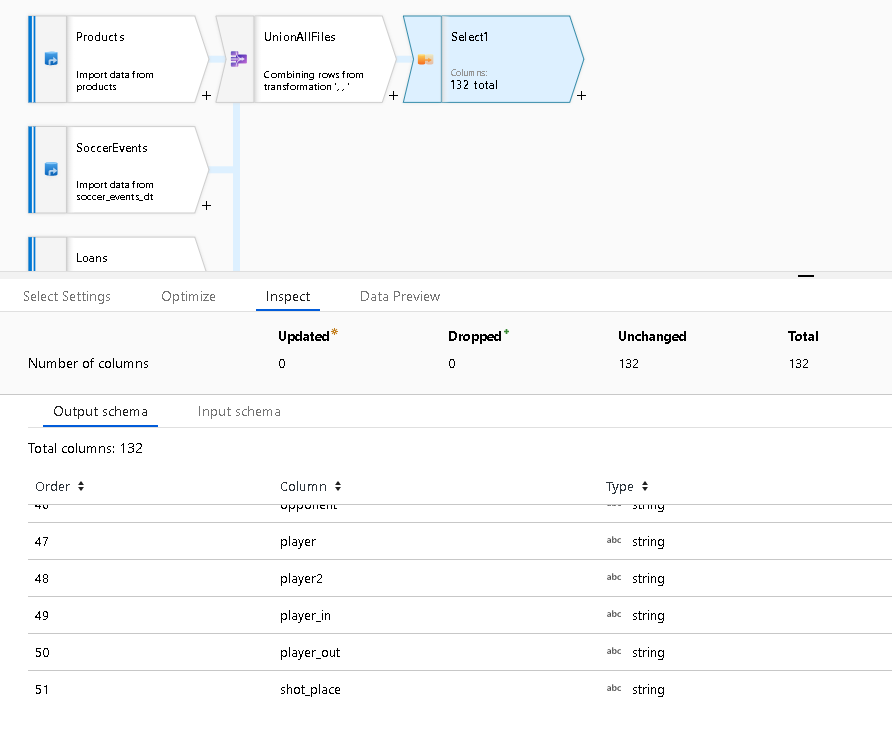
Se si imposta una trasformazione Select dopo l'unione, sarà possibile rinominare campi o campi sovrapposti non denominati da origini senza intestazione. Fare clic su "Inspect" per visualizzare i metadati combinati con 132 colonne totali in questo esempio da tre origini diverse:
Nome e posizione
Quando si sceglie "unione per nome", ogni valore di colonna verrà eliminato nella colonna corrispondente da ogni origine, con un nuovo schema di metadati concatenato.
Se si sceglie "unione per posizione", ogni valore di colonna verrà inserito nella posizione originale da ogni origine corrispondente, generando un nuovo flusso combinato di dati in cui i dati di ogni origine vengono aggiunti allo stesso flusso: