Trasformazione Ordinamento nel flusso di dati di mapping
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
I flussi di dati sono disponibili nelle pipeline sia di Azure Data Factory che di Azure Synapse. Questo articolo si applica ai flussi di dati per mapping. Se non si ha esperienza con le trasformazioni, vedere l'articolo introduttivo Trasformare i dati con un flusso di dati per mapping.
La trasformazione ordinamento consente di ordinare le righe in ingresso nel flusso di dati corrente. È possibile scegliere singole colonne e ordinarle in ordine crescente o decrescente.
Nota
I flussi di dati di mapping vengono eseguiti in cluster Spark che distribuiscono i dati tra più nodi e partizioni. Se si sceglie di ripartizionare i dati in una trasformazione successiva, l'ordinamento potrebbe andare perso a causa del rimshuffing dei dati. Il modo migliore per mantenere l'ordinamento nel flusso di dati consiste nell'impostare una singola partizione nella scheda Ottimizza della trasformazione e mantenere la trasformazione Ordinamento il più vicino possibile al sink.
Impostazione
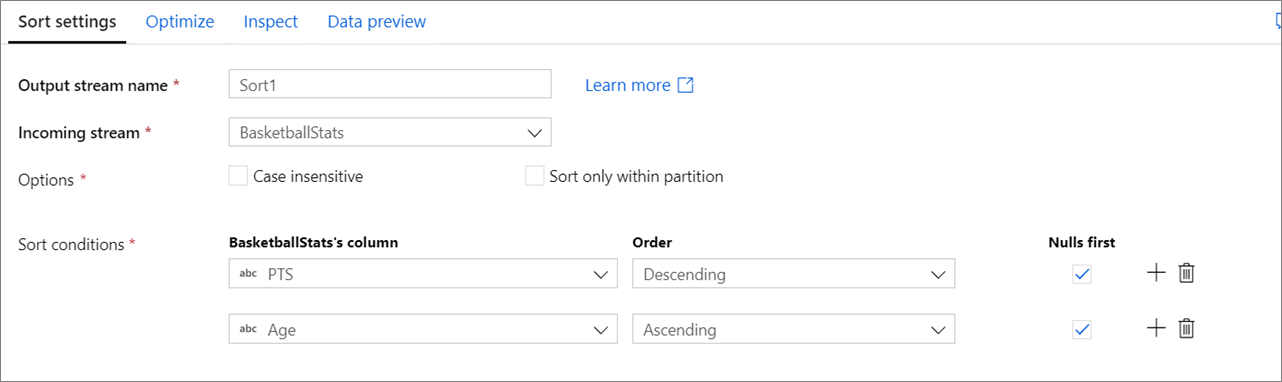
Senza distinzione tra maiuscole e minuscole: indica se si desidera ignorare la distinzione tra maiuscole e minuscole durante l'ordinamento di campi stringa o di testo
Ordina solo all'interno delle partizioni: quando i flussi di dati vengono eseguiti in Spark, ogni flusso di dati è suddiviso in partizioni. Questa impostazione ordina i dati solo all'interno delle partizioni in ingresso anziché ordinare l'intero flusso di dati.
Condizioni di ordinamento: scegliere le colonne in base a cui si esegue l'ordinamento e in quale ordine si verifica l'ordinamento. L'ordine determina la priorità di ordinamento. Scegliere se i valori Null verranno visualizzati all'inizio o alla fine del flusso di dati.
Colonne calcolate
Per modificare o estrarre un valore di colonna prima di applicare l'ordinamento, passare il puntatore del mouse sulla colonna e selezionare "colonna calcolata". Verrà aperto il generatore di espressioni per creare un'espressione per l'operazione di ordinamento anziché usare un valore di colonna.
Script del flusso di dati
Sintassi
<incomingStream>
sort(
desc(<sortColumn1>, { true | false }),
asc(<sortColumn2>, { true | false }),
...
) ~> <sortTransformationName<>
Esempio
Lo script del flusso di dati per la configurazione di ordinamento precedente si trova nel frammento di codice seguente.
BasketballStats sort(desc(PTS, true),
asc(Age, true)) ~> Sort1
Contenuto correlato
Dopo l'ordinamento, è possibile usare la trasformazione Aggregazione