Analizzare la trasformazione nel flusso di dati di mapping
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
I flussi di dati sono disponibili nelle pipeline sia di Azure Data Factory che di Azure Synapse. Questo articolo si applica ai flussi di dati per mapping. Se non si ha esperienza con le trasformazioni, vedere l'articolo introduttivo Trasformare i dati con un flusso di dati per mapping.
Usare la trasformazione Analizza per analizzare le colonne di testo nei dati che sono stringhe in formato documento. I tipi correnti supportati di documenti incorporati che possono essere analizzati sono JSON, XML e testo delimitato.
Impostazione
Nel pannello di configurazione della trasformazione analisi selezionare prima di tutto il tipo di dati contenuti nelle colonne da analizzare inline. La trasformazione analisi contiene anche le impostazioni di configurazione seguenti.

Colonna
Analogamente alle colonne derivate e alle aggregazioni, la proprietà Column consente di modificare una colonna esistente selezionandola dalla selezione a discesa. In alternativa, è possibile digitare qui il nome di una nuova colonna. Azure Data Factory archivia i dati di origine analizzati in questa colonna. Nella maggior parte dei casi, si vuole definire una nuova colonna che analizza il campo stringa di documento incorporato in ingresso.
Espressione
Usare il generatore di espressioni per impostare l'origine per l'analisi. L'impostazione dell'origine può essere semplice come la selezione della colonna di origine con i dati autonomi da analizzare oppure è possibile creare espressioni complesse da analizzare.
Espressioni di esempio
Dati stringa di origine:
chrome|steel|plastic- Espressione:
(desc1 as string, desc2 as string, desc3 as string)
- Espressione:
Dati JSON di origine:
{"ts":1409318650332,"userId":"309","sessionId":1879,"page":"NextSong","auth":"Logged In","method":"PUT","status":200,"level":"free","itemInSession":2,"registration":1384448}- Espressione:
(level as string, registration as long)
- Espressione:
Dati JSON annidati di origine:
{"car" : {"model" : "camaro", "year" : 1989}, "color" : "white", "transmission" : "v8"}- Espressione:
(car as (model as string, year as integer), color as string, transmission as string)
- Espressione:
Dati XML di origine:
<Customers><Customer>122</Customer><CompanyName>Great Lakes Food Market</CompanyName></Customers>- Espressione:
(Customers as (Customer as integer, CompanyName as string))
- Espressione:
Codice XML di origine con dati di attributo:
<cars><car model="camaro"><year>1989</year></car></cars>- Espressione:
(cars as (car as ({@model} as string, year as integer)))
- Espressione:
Espressioni con caratteri riservati:
{ "best-score": { "section 1": 1234 } }- L'espressione precedente non funziona perché il carattere '-' in
best-scoreviene interpretato come operazione di sottrazione. Usare una variabile con notazione tra parentesi quadre in questi casi per indicare al motore JSON di interpretare il testo letteralmente:var bestScore = data["best-score"]; { bestScore : { "section 1": 1234 } }
- L'espressione precedente non funziona perché il carattere '-' in
Nota: se si verificano errori durante l'estrazione degli attributi (in particolare da @model) un tipo complesso, una soluzione alternativa consiste nel convertire il tipo complesso in una stringa, rimuovere il simbolo @ (in particolare, replace(toString(your_xml_string_parsed_column_name.cars.car),'@',') e quindi usare l'attività di trasformazione PARSE JSON.
Tipo di colonna di output
Ecco dove si configura lo schema di output di destinazione dall'analisi scritta in una singola colonna. Il modo più semplice per impostare uno schema per l'output dall'analisi consiste nel selezionare il pulsante "Rileva tipo" in alto a destra del generatore di espressioni. ADF tenta di eseguire automaticamente la correzione automatica dello schema dal campo stringa, che si sta analizzando e impostarlo automaticamente nell'espressione di output.
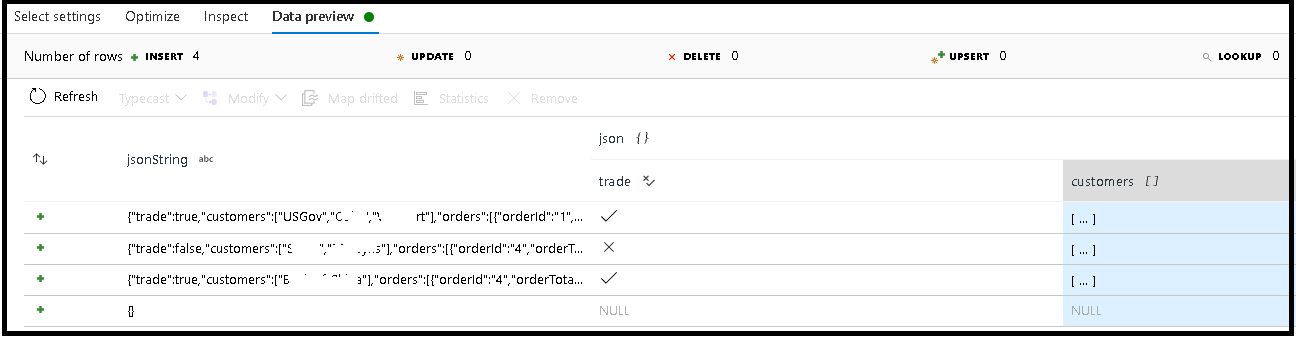
In questo esempio è stata definita l'analisi del campo in ingresso "jsonString", ovvero testo normale, ma formattato come struttura JSON. I risultati analizzati verranno archiviati come JSON in una nuova colonna denominata "json" con questo schema:
(trade as boolean, customers as string[])
Fare riferimento alla scheda Inspect e all'anteprima dei dati per verificare che l'output sia mappato correttamente.
Usare l'attività Colonna derivata per estrarre dati gerarchici, ovvero your_complex_column_name.car.model nel campo dell'espressione.
Esempi
source(output(
name as string,
location as string,
satellites as string[],
goods as (trade as boolean, customers as string[], orders as (orderId as string, orderTotal as double, shipped as (orderItems as (itemName as string, itemQty as string)[]))[])
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
documentForm: 'documentPerLine') ~> JsonSource
source(output(
movieId as string,
title as string,
genres as string
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false) ~> CsvSource
JsonSource derive(jsonString = toString(goods)) ~> StringifyJson
StringifyJson parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json',
documentForm: 'arrayOfDocuments') ~> ParseJson
CsvSource derive(csvString = 'Id|name|year\n\'1\'|\'test1\'|\'1999\'') ~> CsvString
CsvString parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv
ParseJson select(mapColumn(
jsonString,
json
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedJson
ParseCsv select(mapColumn(
csvString,
csv
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedCsv
Script del flusso di dati
Sintassi
Esempi
parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json|XML|delimited',
documentForm: 'singleDocument') ~> ParseJson
parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv
Contenuto correlato
- Utilizzare la trasformazione Flatten per pivot di righe in colonne.
- Utilizzare la trasformazione Colonna derivata per trasformare le righe.