Copiare dati da Google BigQuery V1 usando Azure Data Factory o Synapse Analytics
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Questo articolo illustra come usare l'attività Copy nelle pipeline di Azure Data Factory e Synapse Analytics per copiare dati da Google BigQuery. Si basa sull'articolo di panoramica dell'attività di copia che presenta informazioni generali sull'attività di copia.
Importante
Il connettore Google BigQuery V2 offre un supporto di Google BigQuery nativo migliorato. Se si usa il connettore Google BigQuery V1 nella soluzione, aggiornare il connettore Google BigQuery perché V1 è alla fine del supporto. Per informazioni dettagliate sulla differenza tra V2 e V1, vedere questa sezione .
Funzionalità supportate
Questo connettore di Google BigQuery è supportato per le funzionalità seguenti:
| Funzionalità supportate | IR |
|---|---|
| Attività Copy (origine/-) | (1) (2) |
| Attività Lookup | (1) (2) |
① Azure Integration Runtime ② Runtime di integrazione self-hosted
Per un elenco degli archivi dati supportati come origini o sink dall'attività di copia, vedere la tabella relativa agli archivi dati supportati.
Il servizio fornisce un driver predefinito per abilitare la connettività. Non è pertanto necessario installare manualmente un driver per usare questo connettore.
Il connettore supporta le versioni di Windows in questo articolo.
Nota
Questo connettore Google BigQuery si basa sulle API BigQuery. Tenere presente che BigQuery limita la velocità massima delle richieste in arrivo e applica le quote appropriate in base al progetto: vedere la sezione Quotas & Limits - API requests (Limiti e quote - Richieste API). Assicurarsi di non attivare troppe richieste simultanee verso l'account.
Prerequisiti
Per usare questo connettore, sono necessarie le autorizzazioni minime seguenti di Google BigQuery:
- bigquery.connections.*
- bigquery.datasets.*
- bigquery.jobs.*
- bigquery.readsessions.*
- bigquery.routines.*
- bigquery.tables.*
Operazioni preliminari
Per eseguire l'attività di copia con una pipeline, è possibile usare uno degli strumenti o SDK seguenti:
- Strumento Copia dati
- Il portale di Azure
- .NET SDK
- SDK di Python
- Azure PowerShell
- API REST
- Modello di Azure Resource Manager
Creare un servizio collegato a Google BigQuery usando l'interfaccia utente
Seguire questa procedura per creare un servizio collegato a Google BigQuery nell'interfaccia utente del portale di Azure.
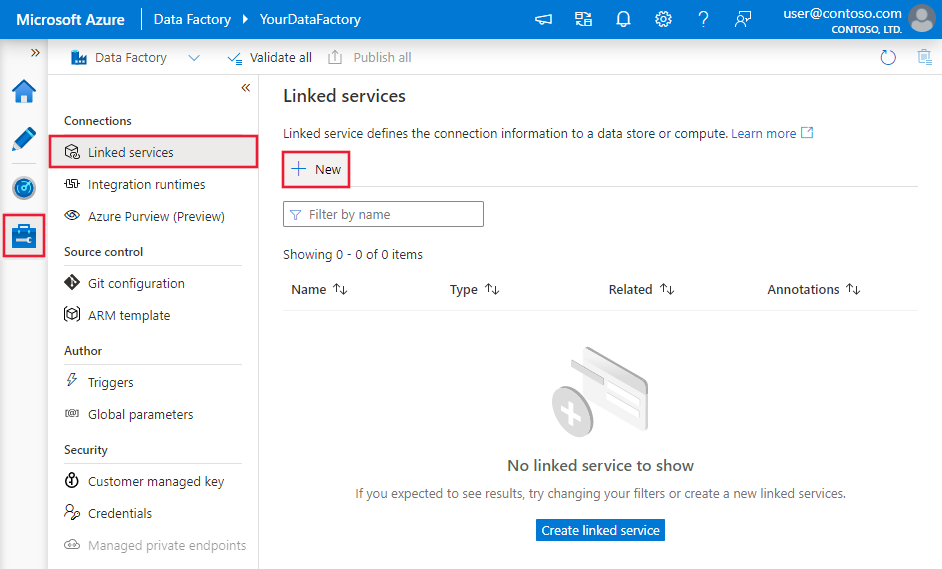
Passare alla scheda Gestisci nell'area di lavoro di Azure Data Factory o Synapse e selezionare Servizi collegati, quindi fare clic su Nuovo:
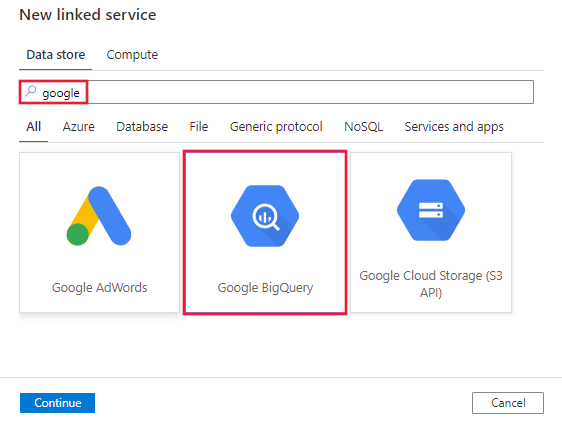
Cercare Google e selezionare il connettore Google BigQuery.
Configurare i dettagli del servizio, testare la connessione e creare il nuovo servizio collegato.
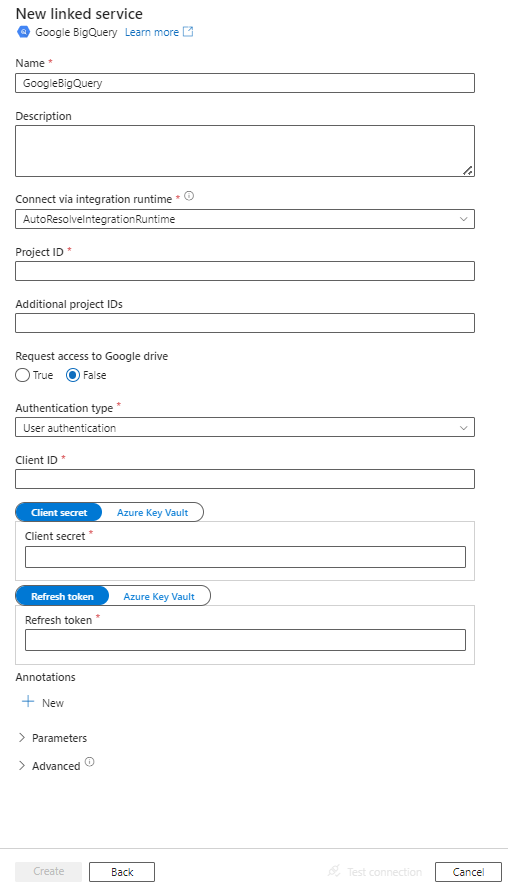
Dettagli di configurazione del connettore
Le sezioni seguenti riportano informazioni dettagliate sulle proprietà usate per definire entità specifiche per il connettore Google BigQuery.
Proprietà del servizio collegato
Per il servizio collegato Google BigQuery sono supportate le proprietà seguenti.
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type deve essere impostata su GoogleBigQuery. | Sì |
| progetto | ID di progetto del progetto BigQuery su cui eseguire query. | Sì |
| additionalProjects | A elenco delimitato da virgole di ID di progetto dei progetti BigQuery a cui accedere. | No |
| requestGoogleDriveScope | Indica se richiedere l'accesso a Google Drive. L'abilitazione dell'accesso a Google Drive consente di abilitare il supporto per le tabelle federate che combinano dati di BigQuery con dati da Google Drive. Il valore predefinito è false. | No |
| authenticationType | Meccanismo di autenticazione OAuth 2.0 usato per l'autenticazione. È possibile usare ServiceAuthentication solo sul runtime di integrazione self-hosted. I valori consentiti sono UserAuthentication e ServiceAuthentication. Fare riferimento alle sezioni sotto questa tabella per altre proprietà e altri esempi JSON per questi tipi di autenticazione. |
Sì |
Uso dell'autenticazione utente
Impostare la proprietà "authenticationType" su UserAuthentication e specificare le proprietà seguenti insieme alle proprietà generiche descritte nella precedente sezione:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| clientId | ID dell'applicazione usata per generare il token di aggiornamento. | Sì |
| clientSecret | Segreto dell'applicazione usata per generare il token di aggiornamento. Contrassegnare questo campo come SecureString per archiviarlo in modo sicuro oppure fare riferimento a un segreto archiviato in Azure Key Vault. | Sì |
| refreshToken | Token di aggiornamento ottenuto da Google e usato per autorizzare l'accesso a BigQuery. Per informazioni su come ottenerne uno, vedere Obtaining OAuth 2.0 access tokens (Ottenere token di accesso OAuth 2.0) e questo blog della community. Contrassegnare questo campo come SecureString per archiviarlo in modo sicuro oppure fare riferimento a un segreto archiviato in Azure Key Vault. | Sì |
L'ambito minimo richiesto per ottenere un token di aggiornamento OAuth 2.0 è https://www.googleapis.com/auth/bigquery.readonly. Se si prevede di eseguire una query che potrebbe restituire risultati di grandi dimensioni, potrebbe essere necessario un altro ambito. Per altre informazioni, fare riferimento a questo articolo.
Esempio:
{
"name": "GoogleBigQueryLinkedService",
"properties": {
"type": "GoogleBigQuery",
"typeProperties": {
"project" : "<project ID>",
"additionalProjects" : "<additional project IDs>",
"requestGoogleDriveScope" : true,
"authenticationType" : "UserAuthentication",
"clientId": "<id of the application used to generate the refresh token>",
"clientSecret": {
"type": "SecureString",
"value":"<secret of the application used to generate the refresh token>"
},
"refreshToken": {
"type": "SecureString",
"value": "<refresh token>"
}
}
}
}
Uso dell'autenticazione del servizio
Impostare la proprietà "authenticationType" su ServiceAuthentication e specificare le proprietà seguenti insieme alle proprietà generiche descritte nella precedente sezione. È possibile usare questo tipo di autenticazione solo sul runtime di integrazione self-hosted.
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| posta elettronica | ID di posta elettronica dell'account del servizio usato per ServiceAuthentication. Può essere usato solo sul runtime di integrazione self-hosted. | No |
| keyFilePath | Percorso completo del .json file di chiave usato per autenticare l'indirizzo di posta elettronica dell'account del servizio. |
Sì |
| trustedCertPath | Percorso completo del file PEM contenente i certificati CA attendibili usati per verificare il server in caso di connessione tramite TLS. Questa proprietà può essere impostata solo quando si usa TLS in runtime di integrazione self-hosted. Il valore predefinito è il file cacerts.pem installato con il runtime di integrazione. | No |
| useSystemTrustStore | Specifica se usare o meno un certificato CA dall'archivio di attendibilità di sistema o da un file PEM specificato. Il valore predefinito è false. | No |
Nota
Il connettore non supporta più i file di chiave P12. Se si fa affidamento sugli account del servizio, è consigliabile usare invece i file di chiave JSON. È stata deprecata anche la proprietà P12CustomPwd usata per supportare il file di chiave P12. Per altre informazioni, vedi questo articolo.
Esempio:
{
"name": "GoogleBigQueryLinkedService",
"properties": {
"type": "GoogleBigQuery",
"typeProperties": {
"project" : "<project id>",
"requestGoogleDriveScope" : true,
"authenticationType" : "ServiceAuthentication",
"email": "<email>",
"keyFilePath": "<.json key path on the IR machine>"
},
"connectVia": {
"referenceName": "<name of Self-hosted Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Proprietà del set di dati
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione dei set di dati, vedere l'articolo Set di dati. Questa sezione presenta un elenco delle proprietà supportate dal set di dati di Google BigQuery.
Per copiare dati da Google BigQuery, impostare la proprietà type del set di dati su GoogleBigQueryObject. Sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà tipo del set di dati deve essere impostata su: GoogleBigQueryObject | Sì |
| set di dati | Nome del set di dati di Google BigQuery. | No (se nell'origine dell'attività è specificato "query") |
| table | Nome della tabella. | No (se nell'origine dell'attività è specificato "query") |
| tableName | Nome della tabella. Questa proprietà è supportata per garantire la compatibilità con le versioni precedenti. Per i nuovi carichi di lavoro, usare dataset e table. |
No (se nell'origine dell'attività è specificato "query") |
Esempio
{
"name": "GoogleBigQueryDataset",
"properties": {
"type": "GoogleBigQueryObject",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<GoogleBigQuery linked service name>",
"type": "LinkedServiceReference"
}
}
}
Proprietà dell'attività di copia
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione delle attività, vedere l'articolo sulle pipeline. Questa sezione presenta un elenco delle proprietà supportate dal tipo di origine Google BigQuery.
GoogleBigQuerySource come tipo di origine
Per copiare dati da Google BigQuery, impostare il tipo di origine nell'attività di copia su GoogleBigQuerySource. Nella sezione source dell'attività di copia sono supportate le proprietà seguenti.
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type dell'origine dell'attività di copia deve essere impostata su GoogleBigQuerySource. | Sì |
| query | Usare la query SQL personalizzata per leggere i dati. Un esempio è "SELECT * FROM MyTable". |
No (se nel set di dati è specificato "tableName") |
Esempio:
"activities":[
{
"name": "CopyFromGoogleBigQuery",
"type": "Copy",
"inputs": [
{
"referenceName": "<GoogleBigQuery input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "GoogleBigQuerySource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Proprietà dell'attività Lookup
Per altre informazioni sulle proprietà, vedere Attività Lookup.
Contenuto correlato
Per un elenco degli archivi dati supportati come origini e sink dall'attività di copia, vedere Archivi dati supportati.