Data Science Toolkit - Logistic regression custom model service
The Logistic Regression Custom Model Service allows you to create logistic regression models (sometimes called "logit models") to predict the likelihood of clicks or conversions based on a combination of multiple signals. The logistic regression models can then be associated with a line item using the Line Item Service - ALI (Archived).
Note
This offering is currently in Closed Beta and available to a limited set of clients. For more information about the Advanced Ads Toolset and potential use cases that may apply to your business, reach out to your account representative.
The formula for logistic regression is:
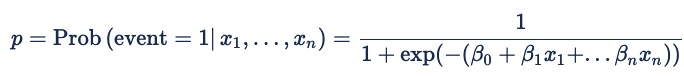
For online advertising, the event is a click, a pixel fire, or another online action. The probability is conditional on both the predictors x 1 through xn and on an implicit set of variables that represent the features in a bid request. The beta coefficients are the weights that the model assigns to different predictors.
We convert this probability of an event happening to an expected value by multiplying the probability by the event's value (the eCPC goal for a click prediction), adding an additive offset to the estimate, and then applying min/max expected value limits to reduce the impact of mispredictions.
The formula for deriving an expected value for an impression from the probability of an event happening is:
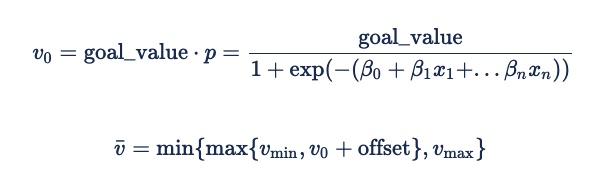
The offset will usually be 0. However, a negative value may be useful as a security factor to ensure performance at the expense of delivery on low-performing inventory. That will ensure that the advertiser does not bid, instead of bidding very little and potentially incurring fixed fees.
For more information about how logistic regression custom models work, see Logistic Regression Models.
REST API
Add a new logistic regression model
POST https://api.appnexus.com/custom-model-logit
(template JSON)
Modify a logistic regression model
PUT https://api.appnexus.com/custom-model-logit?id=CUSTOM_MODEL_LOGIT_ID
(template JSON)
Delete a logistic regression model
DELETE https://api.appnexus.com/custom-model-logit?id=CUSTOM_MODEL_LOGIT_ID
View all logistic regression models
GET https://api.appnexus.com/custom-model-logit
View a specific logistic regression model
GET https://api.appnexus.com/custom-model-logit?id=CUSTOM_MODEL_LOGIT_ID
JSON fields
General
| Field | Type | Description |
|---|---|---|
id |
int | The ID of the logistic regression custom model. Default: Auto-generated number Required on: PUT/ DELETE in query string |
name |
string | The name of the model. |
beta0 |
float | β 0 coefficient in the logistic regression equation. |
max |
float | Max in the expected value equation. |
min |
float | Min in the expected value equation. |
offset |
float | Offset in the expected value equation. |
scale |
float | Scale in the expected value equation. |
predictors |
array | Array of predictors. See Predictors below for more details. |
Predictors
| Field | Type | Description |
|---|---|---|
predictor_type |
scalar_descriptor, custom_model_descriptor, freq_rec_descriptor, segment_descriptor, categorical_descriptor |
|
keys |
||
hash_seed |
||
default_value |
||
hash_table_size_log |
||
coefficients |
Hashed descriptor
This endpoint is to submit a pre-hashed table. bucket_index0 and bucket_index1, each 64 bits long, are there to support hashing algorithms that produce long values as keys. Currently, we only support one hashing algorithm: MurmurHash3_x64_128, which will create two 64 bit integers but we only use the lower 64 bits of the hash.
Values in bucket_index0 must always be smaller than (2 ^ hash_table_size_log) or they will get rejected.
Currently, the values in bucket_index1 are ignored as this is to be used for future expansion. If a value is sent for bucket_index1, it must be 0. The parameter is optional.
Hash Table keys
For each of your Hash Table keys, you will need a uint32 value. These values should be the ID of respective object that you are referencing from our system - domain_id, for instance, rather than the domain string value. These uint32 keys are then transformed into a byte array (little-endian), and hashed.
Python example
hash_bucket = (mmh3.hash64(bytes, seed)[ 0 ]) % table_size
| Field | Type | Description |
|---|---|---|
type |
||
keys |
Array of one to 5 descriptors in this list: | |
hashed_seeds |
Seeds used when passed to Murmurhash3_x64_128 function, only first one is used for now, array is for planned future hash functions that need more than one seed |
|
hash_id |
Existing hash table ID | |
default_value |
Value returned by the descriptor if no match is found in your hash table | |
hash_table_size_log |
Log of maximum value for a key of your table. Values larger than 2^hash_table_size_log will be rejected. Max for hash_table_size_log is 64 (no bucketing) |
Hashed descriptor example
{
"type": "hashed",
"keys": [
],
"hash_seeds": [42, 42, 42, 42, 42, 42],
"hash_id": ,
"default_value": 0,
"hash_table_size_log": 20
}
Lookup Table (LUT) descriptor
| Field | Type | Description |
|---|---|---|
type |
||
feature_keyword |
||
default_value |
||
initial_range_log |
||
bucket_count_log_per_range |
LUT descriptor example
{
"type": "lookup",
"default_value": 0.1,
"features": [
{
"type": "categorical_descriptor",
"feature_keyword": "advertiser_id"
},
{
"type": "scalar_descriptor",
"feature_keyword": "user_age",
"default_value": 0
}
],
"coefficients": [
{'weight': 1.1, 'key': [1, 1]},
{'weight': 1.3, 'key': [2, 2]},
{'weight': 1.2, 'key': [3, 3]},
]
}
Categorical descriptor
Since this is finding an exact match, the default_value, initial_range_log and bucket_count_log_per_range params are not needed.
Missing values
The key value of -1 can be used as a placeholder for a missing feature; For instance, when a domain is not reported by the seller. Otherwise, the default value of the LUT or Hash Model will be used, since no match will be found for that feature value.
| Field | Type | Description |
|---|---|---|
type |
||
feature_keyword |
- country- region- city- dma- postal_code- user_day- user_hour- os_family- os_extended- browser- language- user_gender- domain- ip_address- position- placement- placement_group- publisher- seller_member_id- supply_type- device_type- device_model- carrier- mobile_app- mobile_app_instance- mobile_app_bundle- appnexus_intended_audience- seller_intended_audience- spend_protection- user_group_id- advertiser_id- brand_category- creative- inventory_url_id- media_type |
|
default_value |
||
object_type |
Advertiser, li - ne_item, campaign (not split?) |
|
object_id |
ID of the referenced advertiser, |
Categorical descriptor example
{
"type": "categorical_descriptor",
"feature_keyword": "city"
}
Frequency and recency descriptor
| Field | Type | Description |
|---|---|---|
type |
||
feature_keyword |
frequency_lifefrequency_dailyrecency |
|
default_value |
||
object_type |
Advertiser, line_item, campaign (not split?) |
|
object_id |
ID of the referenced advertiser, | |
default_value |
Value returned by the descriptor if no match is found | |
initial_range_log |
Used for log bucketing, initial range | |
bucket_count_log_per_range |
used for log bucketing, # of buckets per range |
Frequency and recency descriptor example
{
"type": "frequency_recency_descriptor",
"feature_keyword": 'frequency_life',
"object_type": 'advertiser',
"object_id": 1,
"default_value": 0,
"initial_range_log": 4,
"bucket_count_log_per_range": 2
}
Scalar descriptor
| Field | Type | Description |
|---|---|---|
type |
||
feature_keyword |
- appnexus_audited- cookie_age- estimated_average_price- estimated_clearing_price- predicted_iab_view_rate- predicted_video_completion_rate- self_audited- size- creative_size- spend_protection- uniform- user_ageNote: The size descriptor is represented as a string in your models ("300x250", for instance), though converted to a scalar in our bidder. Any size is technically valid in our system, hence this feature being treated as a scalar rather than a categorical feature. |
|
default_value |
Value returned by the descriptor if no match is found | |
initial_range_log |
Used for log bucketing, initial range | |
bucket_count_log_per_range |
Used for log bucketing, # of buckets per range |
Scalar descriptor example
{
"type": "scalar_descriptor",
"feature_keyword": "cookie_age",
"default_value": 0,
"initial_range_log": 4,
"bucket_count_log_per_range": 2
}
Segment descriptor
| Field | Type | Description |
|---|---|---|
type |
||
feature_keyword |
segment_valuesegment_agesegment_presence |
|
segment_id |
ID of referenced segment | |
default_value |
Value returned by the descriptor if no match is found | |
initial_range_log |
Used for log bucketing, initial range | |
bucket_count_log_per_range |
Used for log bucketing, # of buckets per range |
Segment descriptor example
{
"type": "segment_descriptor",
"feature_keyword": "segment_age",
"segment_id": 2,
"default_value": 0,
"initial_range_log": 4,
"bucket_count_log_per_range": 2
}