étape Stream-Output
L’objectif de l’étape de sortie de flux est de générer en continu (ou de diffuser) des données de vertex à partir de l’étape geometry-shader (ou de l’étape vertex-nuanceur si l’étape geometry-shader est inactive) vers une ou plusieurs mémoires tampons en mémoire tampon (voir Prise en main avec l’étape Stream-Output).
L’étape de sortie de flux (SO) se trouve dans le pipeline juste après l’étape geometry-shader et juste avant l’étape de rastérisation, comme illustré dans le diagramme suivant.
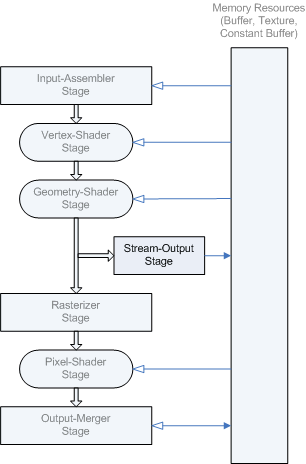
Les données diffusées en mémoire peuvent être lues dans le pipeline dans un passage de rendu ultérieur, ou peuvent être copiées dans une ressource de préproduction (de sorte qu’elles peuvent être lues par le processeur). La quantité de données diffusées en continu peut varier ; L’API ID3D11DeviceContext::D rawAuto est conçue pour gérer les données sans avoir à interroger (le GPU) sur la quantité de données écrites.
Lorsqu’un triangle ou une bande de ligne est lié à l’étape d’assembleur d’entrée, chaque bande est convertie en liste avant d’être diffusée en continu. Les sommets sont toujours écrits sous forme de primitives complètes (par exemple, 3 sommets à la fois pour les triangles) ; les primitives incomplètes ne sont jamais diffusées en continu. Les types primitifs avec adjacence ignorent les données d’adjacence avant de diffuser les données en continu.
Il existe deux façons d’alimenter des données de flux de sortie dans le pipeline :
- Les données de flux de sortie peuvent être transmises à l’étape d’assembleur d’entrée.
- Les données de sortie de flux peuvent être lues par des nuanceurs programmables à l’aide de fonctions de charge (telles que Charger).
Pour utiliser une mémoire tampon comme ressource de sortie de flux, créez la mémoire tampon avec l’indicateur D3D11_BIND_STREAM_OUTPUT . La phase flux-sortie prend en charge jusqu’à 4 mémoires tampons simultanément.
- Si vous diffusez des données dans plusieurs mémoires tampons, chaque mémoire tampon ne peut capturer qu’un seul élément (jusqu’à 4 composants) de données par vertex, avec une foulée de données implicite égale à la largeur d’élément dans chaque mémoire tampon (compatible avec la façon dont les mémoires tampons d’élément unique peuvent être liées pour l’entrée dans les phases de nuanceur). En outre, si les mémoires tampons ont des tailles différentes, l’écriture s’arrête dès que l’une des mémoires tampons est saturée.
- Si vous diffusez des données dans une seule mémoire tampon, la mémoire tampon peut capturer jusqu’à 64 composants scalaires de données par vertex (256 octets ou moins) ou la foulée de vertex peut atteindre 2 048 octets.
Contenu de cette section
| Rubrique | Description |
|---|---|
|
Prise en main avec la phase Stream-Output |
Cette section explique comment utiliser un nuanceur de géométrie avec l’étape de sortie de flux. |