Comment le système de gestion des ressources met en correspondance les balises de langue
La rubrique précédente (Comment le système de gestion des ressources met en correspondance et sélectionne les ressources) aborde la correspondance entre les qualificateurs de manière générale. Cette rubrique se concentre plus particulièrement sur la correspondance entre les balises de langue.
Introduction
Les ressources avec des qualificateurs de balise de langue sont comparées et notées en fonction de la liste de langues du runtime d’application. Pour connaître les définitions des différentes listes de langues, consultez Comprendre les langues de profil utilisateur et les langues de manifeste de l’application. La correspondance pour la première langue d’une liste se produit avant la correspondance de la deuxième langue dans une liste, même pour d’autres variantes régionales. Par exemple, une ressource pour en-Go est choisie sur une ressource fr-CA si le langage d’exécution de l’application est en-US. Uniquement s’il n’existe aucune ressource pour une forme d’en est une ressource pour l’autorité de certification fr-CA choisie (notez que la langue par défaut de l’application n’a pas pu être définie sur une forme d’en dans ce cas).
Le mécanisme de scoring utilise des données incluses dans le registre de sous-balise BCP-47 et d’autres sources de données. Il permet un dégradé de score avec différents gradients de correspondance et, lorsque plusieurs candidats sont disponibles, il sélectionne le candidat avec le score de correspondance le mieux adapté.
Par conséquent, vous pouvez baliser le contenu de langue en termes génériques, mais vous pouvez toujours spécifier du contenu spécifique si nécessaire. Par exemple, votre application peut avoir de nombreuses chaînes anglaises communes à la fois aux États-Unis, à la Grande-Bretagne et à d’autres régions. L’étiquetage de ces chaînes en tant que « en » (anglais) permet d’économiser de l’espace et de la surcharge de localisation. Lorsque des distinctions doivent être effectuées, comme dans une chaîne contenant le mot « couleur », les versions États-Unis et britanniques peuvent être étiquetées séparément à l’aide des sous-balises de langue et de région, en tant que « en-US » et « en-GB », respectivement.
Balises de langue
Les langues sont identifiées à l’aide de balises de langue BCP-47 normalisées et bien formées. Les composants de sous–balise sont définis dans le registre de sous-balise BCP-47. La structure normale d’une balise de langage BCP-47 se compose d’un ou plusieurs des éléments de sous-balise suivants.
- Sous-balise de langue (obligatoire).
- Sous-balise de script (qui peut être déduite à l’aide de la valeur par défaut spécifiée dans le registre de sous-balise).
- Sous-balise région (facultatif).
- Sous-balise variante (facultatif).
Des éléments de sous-balise supplémentaires peuvent être présents, mais ils auront un effet négligeable sur la correspondance linguistique. Il n’existe aucune plage de langage définie à l’aide de la carte générique (« »), par exemple, « en- ».
Correspondance de deux langues
Chaque fois que Windows compare deux langues, elle est généralement effectuée dans le contexte d’un processus plus volumineux. Il peut être dans le contexte de l’évaluation de plusieurs langues, par exemple lorsque Windows génère la liste des langues d’application (consultez Comprendre les langues de profil utilisateur et les langues du manifeste de l’application). Windows effectue cette opération en faisant correspondre plusieurs langues des préférences utilisateur aux langues spécifiées dans le manifeste de l’application. La comparaison peut également se trouver dans le contexte de l’évaluation de la langue, ainsi que d’autres qualificateurs pour une ressource particulière. Par exemple, Windows résout une ressource de fichier particulière en contexte de ressource spécifique ; avec l’emplacement d’accueil de l’utilisateur ou l’échelle ou le PPP actuel de l’appareil comme d’autres facteurs (en plus de la langue) qui sont pris en compte dans la sélection de ressources.
Lorsque deux balises de langue sont comparées, la comparaison est attribuée à un score en fonction de la proximité de la correspondance.
| Correspondance | Score | Exemple |
|---|---|---|
| Correspondance exacte | Le plus élevé | en-AU : en-AU |
| Correspondance de variante (langage, script, région, variant) | en-AU-variant1 : en-AU-variant1-t-ja | |
| Correspondance de région (langue, script, région) | en-AU : en-AU-variant1 | |
| Correspondance partielle (langage, script) | ||
| - Correspondance de la région de macro | en-AU : en-053 | |
| - Correspondance neutre dans la région | en-AU : en | |
| - Correspondance d’affinité orthographique (prise en charge limitée) | en-AU : en-GB | |
| - Correspondance de région préférée | en-AU : en-US | |
| - N’importe quelle correspondance de région | en-AU : en-CA | |
| Langue indéterminée (n’importe quelle correspondance de langue) | en-AU : und | |
| Aucune correspondance (incompatibilité de script ou incompatibilité de balise de langue principale) | Minimale | en-AU : fr-FR |
Correspondance exacte
Les balises sont exactement égales (tous les éléments de sous-balise correspondent). Une comparaison peut être promue vers ce type de correspondance à partir d’une correspondance de variante ou de région. Par exemple, en-US correspond en-US.
Correspondance de variante
Les balises correspondent à la langue, au script, à la région et aux sous-balises variant, mais elles diffèrent d’un autre point de vue.
Correspondance de région
Les balises correspondent à la langue, au script et aux sous-balises de région, mais elles diffèrent d’un autre point de vue. Par exemple, de-DE-1996 correspond à de-DE, et en-US-x-Pirate correspond en-US.
Correspondances partielles
Les balises correspondent aux sous-balises de langue et de script, mais elles diffèrent dans la région ou dans une autre sous-balise. Par exemple, en-US correspond en ou en-US correspond en-*.
Correspondance de la région de macro
Les balises correspondent aux sous-balises de langage et de script ; les deux balises ont des sous-balises de région, dont l’une désigne une région de macro qui englobe l’autre région. Les sous-balises de région macro sont toujours numériques et sont dérivées des codes de pays et de zone de la Division des statistiques des Nations Unies M.49. Pour plus d’informations sur les relations englobantes, consultez Composition des régions géographiques (continentales), des sous-régions géographiques et des regroupements économiques et autres sélectionnés.
Notez que les codes ONU pour les « regroupements économiques » ou « autres regroupements » ne sont pas pris en charge dans BCP-47.
Notez qu’une balise avec la sous-balise macro-région « 001 » est considérée comme équivalente à une balise neutre dans la région. Par exemple, « es-001 » et « es » sont traités comme synonymes.
Correspondance neutre dans la région
Les balises correspondent aux sous-balises de langue et de script, et une seule balise a une balise de région. Une correspondance parente est préférée à d’autres correspondances partielles.
Correspondance d’affinité orthographique
Les balises correspondent aux sous-balises de langue et de script, et les sous-balises de région ont une affinité orthographique. L’affinité s’appuie sur les données conservées dans Windows qui définissent des régions affinées spécifiques à une langue, par exemple « en-IE » et « en-Go ».
Correspondance de région préférée
Les balises correspondent aux sous-balises de langue et de script, et l’une des sous-balises de région est la sous-balise de région par défaut pour la langue. Par exemple, « fr-FR » est la région par défaut de la sous-balise « fr ». Donc, fr-FR est une meilleure correspondance pour fr-BE que fr-CA. Cela s’appuie sur les données conservées dans Windows définissant une région par défaut pour chaque langue dans laquelle Windows est localisé.
Correspondance frère
Les balises correspondent à des sous-balises de langage et de script, et les deux ont des sous-balises de région, mais aucune autre relation n’est définie entre elles. En cas de correspondances frères multiples, le dernier frère énuméré sera le gagnant, en l’absence d’une correspondance plus élevée.
Langue indéterminée
Une ressource peut être marquée comme « und » pour indiquer qu’elle correspond à n’importe quelle langue. Cette balise peut également être utilisée avec une balise de script pour filtrer les correspondances en fonction du script. Par exemple, « und-Latn » correspond à n’importe quelle balise de langue qui utilise le script latin. Voir ci-dessous pour plus de détails.
Incompatibilité de script
Lorsque les balises correspondent uniquement à la balise de langue principale, mais pas au script, la paire est considérée comme ne pas correspondre et est notée au-dessous du niveau d’une correspondance valide.
Pas de correspondance
Les sous-balises de langue primaire ne correspondent pas au niveau d’une correspondance valide. Par exemple, zh-Hant ne correspond pas à zh-Hans.
Exemples
Une langue utilisateur « zh-Hans-CN » (Chinois simplifié (Chine)) correspond aux ressources suivantes dans l’ordre de priorité indiqué. Un X indique qu’aucune correspondance n’est établie.
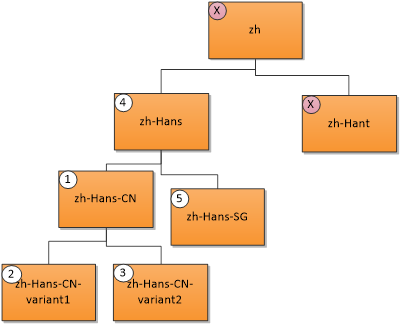
- Correspondance exacte ; 2. et 3. Correspondance de région ; 4. Correspondance parente ; 5. Correspondance frère.
Lorsqu’une sous-balise de langage a une valeur Suppress-Script définie dans le registre de sous-balise BCP-47, la correspondance correspondante se produit, prenant la valeur du code de script supprimé. Par exemple, en-Latn-US correspond à en-US. Dans cet exemple suivant, la langue de l’utilisateur est « en-AU » (anglais (Australie)).
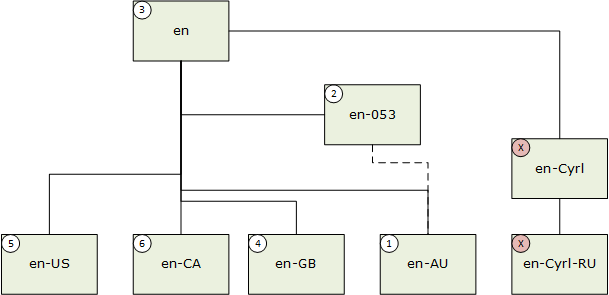
- Correspondance exacte ; 2. Correspondance de la région de macro ; 3. Correspondance neutre dans la région ; 4. Correspondance d’affinité orthographique ; 5. Correspondance de région préférée ; 6. Correspondance frère.
Correspondance d’une langue à une liste de langues
Parfois, la correspondance se produit dans le cadre d’un processus plus important de mise en correspondance d’une langue unique à une liste de langues. Par exemple, il peut y avoir une correspondance d’une ressource basée sur une langue unique à la liste de langues d’une application. Le score de la correspondance est pondéré par la position de la première langue correspondante dans la liste. Plus la langue est en bas de la liste, plus le score est bas.
Lorsque la liste de langues contient deux variantes régionales ou plus ayant les mêmes sous-balises de langue et de script, les comparaisons pour la première balise de langue ne sont notées que pour les correspondances exactes, variant et région. Le scoring de correspondances partielles est reporté à la dernière variante régionale. Cela permet aux utilisateurs de contrôler correctement le comportement de correspondance de leur liste de langues. Le comportement de correspondance peut inclure l’autorisation d’une correspondance exacte pour un élément secondaire dans la liste à préférer à une correspondance partielle pour le premier élément de la liste, s’il existe un troisième élément qui correspond à la langue et au script du premier. Voici un exemple.
- Liste de langues (dans l’ordre) : « pt-PT » (Portugais (Portugal)), « en-US » (anglais (États-Unis)), « pt-BR » (portugais (Brésil)).
- Ressources : « en-US », « pt-BR ».
- Ressource avec le score supérieur : « en-US ».
- Description : la comparaison commence par « pt-PT », mais ne trouve pas de correspondance exacte. En raison de la présence de « pt-BR » dans la liste de langues de l’utilisateur, la correspondance partielle est reportée à la comparaison avec « pt-BR ». La comparaison de langue suivante est « en-US », qui a une correspondance exacte. Par conséquent, la ressource gagnante est « en-US ».
OR
- Liste de langues (dans l’ordre) : « es-MX » (espagnol (Mexique)), « es-HO » (espagnol (Honduras)).
- Ressources : « en-ES », « es-HO ».
- Ressource avec le score supérieur : « es-HO ».
Langue indéterminée (« und »)
La balise de langue « und » peut être utilisée pour spécifier une ressource qui correspondra à n’importe quelle langue en l’absence d’une meilleure correspondance. Elle peut être considérée comme similaire à la plage de langues BCP-47 « » ou « -<script> ». Voici un exemple.
- Liste de langues : « en-US », « zh-Hans-CN ».
- Ressources : « zh-Hans-CN », « und ».
- Ressource avec le score supérieur : « und ».
- Description : la comparaison commence par « en-US », mais ne trouve pas de correspondance basée sur « en » (partielle ou meilleure). Étant donné qu’il existe une ressource étiquetée avec « und », l’algorithme correspondant utilise cela.
La balise « und » permet à plusieurs langues de partager une seule ressource et d’autoriser les langues individuelles à être traitées comme des exceptions. Par exemple,
- Liste de langues : « zh-Hans-CN », « en-US ».
- Ressources : « zh-Hans-CN », « und ».
- Ressource avec le score supérieur : « zh-Hans-CN ».
- Description : la comparaison trouve une correspondance exacte pour le premier élément et ne case activée donc pas pour la ressource intitulée « und ».
Vous pouvez utiliser « und » avec une balise de script pour filtrer les ressources par script. Par exemple,
- Liste de langues : « ru ».
- Ressources : « und-Latn », « und-Cyrl », « und-Arab ».
- Ressource avec le score supérieur : « und-Cyrl ».
- Description : la comparaison ne trouve pas de correspondance pour « ru » (partielle ou meilleure), et correspond donc à la balise de langue « und ». La valeur de suppress-script « Cyrl » associée à la balise de langue « ru » correspond à la ressource « und-Cyrl ».
Affinité régionale orthographique
Lorsque deux balises de langue avec des différences de sous-balise de région sont mises en correspondance, des paires particulières de régions peuvent avoir une affinité plus élevée entre elles qu’avec d’autres. Les seuls groupes d'affinités pris en charge sont pour l’anglais (« en »). Les sous-balises de région « PH » (Philippines) et « LR » (Libéria) ont une affinité orthographique avec la sous-balise de la région « US ». Toutes les autres sous-balises de région sont affinées avec la sous-balise de région « GB » (Royaume-Uni). Par conséquent, lorsque les ressources « en-US » et « en-Go » sont disponibles, une liste de langues « en-HK » (anglais (Hong Kong (R.A.S.))) obtient un score plus élevé avec des ressources « en-Go » que avec des ressources « en-US ».
Gestion des langues avec de nombreuses variantes régionales
Certaines langues ont de grandes communautés d’orateur dans différentes régions qui utilisent différentes variétés de cette langue—langues telles que l’anglais, le Français et l’espagnol, qui sont parmi celles les plus souvent prises en charge dans les applications multilingues. Les différences régionales peuvent inclure des différences dans l’orthographie (par exemple, « couleur » ou « couleur ») ou des différences de dialecte telles que le glossaire (par exemple, « camion » et « camion » et « camion »).
Ces langues présentant des variantes régionales significatives présentent certains défis lors de la création d’une application prête pour le monde : « Combien de variantes régionales différentes doivent être prises en charge ? » « Quelles sont celles qui ? » « Quel est le moyen le plus économique de gérer ces ressources variantes régionales pour mon application ? ». Il est au-delà de l’étendue de cette rubrique pour répondre à toutes ces questions. Toutefois, les mécanismes de correspondance de langue dans Windows fournissent des fonctionnalités qui peuvent vous aider à gérer les variantes régionales.
Les applications ne prennent souvent en charge qu’une seule variété de langue donnée. Supposons qu’une application dispose de ressources pour une seule variété d’anglais qui sont censées être utilisées par les anglophones, quelle que soit la région à partir de laquelle ils sont. Dans ce cas, la balise « en » sans sous-balise de région reflète cette attente. Toutefois, les applications ont peut-être utilisé historiquement une balise telle que « en-US » qui inclut une sous-balise de région. Dans ce cas, cela fonctionnera également : l’application utilise une seule variété d’anglais, et Windows gère la mise en correspondance d’une ressource marquée pour une variante régionale avec une langue choisie pour l’utilisateur pour une variante régionale différente de manière appropriée.
Si deux variétés régionales ou plus seront prises en charge, toutefois, une différence telle que « en » ou « en-US » peut avoir un impact significatif sur l’expérience utilisateur et il devient important de prendre en compte les sous-balises de région à utiliser.
Supposons que vous souhaitiez fournir des localisations Français distinctes pour les Français utilisées au Canada et aux Français européens. Pour le Français canadien, « fr-CA » peut être utilisé. Pour les orateurs de l’Europe, la localisation utilisera Français (France), et ainsi « fr-FR » peut être utilisé pour cela. Mais que se passe-t-il si un utilisateur donné est de Belgique, avec une langue choisie de « fr-BE » ; qu’est-ce qu’ils obtiendront ? La région « BE » est différente de « FR » et « CA », ce qui suggère une correspondance « n’importe quelle région » pour les deux. Cependant, la France est la région préférée pour Français, et donc le « fr-FR » sera considéré comme le meilleur match dans ce cas.
Supposons que vous aviez d’abord localisé votre application pour une seule variété de Français, à l’aide de chaînes Français (France), mais que vous les mettez génériquement en tant que « fr », puis que vous souhaitez ajouter la prise en charge des Français canadiennes. Probablement que certaines ressources doivent être réacrites pour les Français canadiennes. Vous pouvez continuer à utiliser toutes les ressources d’origine les conservant qualifiées de « fr », et simplement ajouter le petit ensemble de nouvelles ressources à l’aide de « fr-CA ». Si la langue choisie de l’utilisateur est « fr-CA », la ressource « fr-CA » aura un score correspondant supérieur à celui de la ressource « fr ». Toutefois, si la langue choisie de l’utilisateur concerne toute autre variété de Français, la ressource neutre en région « fr » sera une meilleure correspondance que la ressource « fr-CA ».
Comme autre exemple, supposons que vous souhaitez fournir des localisations espagnoles distinctes pour les orateurs de l’Espagne et des haut-parleurs de l’Amérique latine. Supposons que les traductions pour l’Amérique latine aient été fournies par un fournisseur au Mexique. Devez-vous utiliser « es-ES » (Espagne) et « es-MX » (Mexique) pour deux ensembles de ressources ? Si vous l’avez fait, cela pourrait créer des problèmes pour les orateurs d’autres régions d’Amérique latine comme l’Argentine ou la Colombie, car ils obtiendraient les ressources « es-ES ». Dans ce cas, il existe une meilleure alternative : vous pouvez utiliser une sous-balise de région macro, « es-419 » pour refléter que vous envisagez que les ressources soient utilisées pour les orateurs de n’importe quelle partie de l’Amérique latine ou des Caraïbes.
Les balises linguistiques neutres en région et les sous-balises de région de macro peuvent être très efficaces si vous souhaitez prendre en charge plusieurs variétés régionales. Pour réduire le nombre d’actifs distincts dont vous avez besoin, vous pouvez qualifier un actif donné d’une manière qui reflète la couverture la plus large pour laquelle elle s’applique. Ensuite, compléter une ressource largement applicable avec une variante plus spécifique en fonction des besoins. Une ressource avec un qualificateur de langue neutre en région sera utilisée pour les utilisateurs de toute variété régionale, sauf s’il existe une autre ressource avec un qualificateur plus spécifique à la région qui s’applique à cet utilisateur. Par exemple, une ressource « en » correspondra à un utilisateur anglais australien, mais une ressource avec « en-053 » (anglais tel qu’utilisé en Australie ou nouvelle-Zélande) sera une meilleure correspondance pour cet utilisateur, tandis qu’une ressource avec « en-AU » sera la meilleure correspondance possible.
L’anglais a besoin d’une considération particulière. Si une application ajoute la localisation pour deux variétés anglaises, celles-ci seront probablement pour l’anglais américain et pour le Royaume-Uni, ou « international », anglais. Comme indiqué ci-dessus, certaines régions en dehors des États-Unis suivent États-Unis conventions orthographiques, et la correspondance de langue Windows prend cela en compte. Dans ce scénario, il n’est pas recommandé d’utiliser la balise « en » neutre dans la région pour l’une des variantes ; utilisez plutôt « en-GB » et « en-US ». (Si une ressource donnée ne nécessite pas de variantes distinctes, toutefois, « en » peut être utilisé.) Si « en-GB » ou « en-US » est remplacé par « en », cela interférera avec l’affinité régionale orthographique fournie par Windows. Si une troisième localisation anglaise est ajoutée, utilisez une sous-balise de région spécifique ou macro pour les variantes supplémentaires si nécessaire (par exemple, « en-CA », « en-AU » ou « en-053 »), mais continuez à utiliser « en-GB » et « en-US ».
Rubriques connexes
- Comment le système de gestion des ressources met en correspondance et sélectionne les ressources
- BCP-47
- Comprendre les langues de profil utilisateur et les langues du manifeste de l’application
- Composition des régions macro géographiques (continentales), des sous-régions géographiques et des regroupements économiques et autres sélectionnés