Résoudre les problèmes liés aux espaces de stockage direct
Servez-vous des informations contenues dans cet article pour résoudre les problèmes de déploiement d’espaces de stockage direct.
En général, commencez par ces étapes :
- Vérifiez dans Windows Server Catalog que la marque et le modèle de SSD sont certifiés pour Windows Server 2016 et Windows Server 2019. Vérifiez auprès du fournisseur que les lecteurs sont pris en charge pour les espaces de stockage direct.
- Inspectez le stockage pour rechercher tous les lecteurs défectueux. Utilisez un logiciel de gestion du stockage pour vérifier le statut des lecteurs. Si l’un des lecteurs est défectueux, contactez votre fournisseur.
- Si nécessaire, mettez à jour les microprogrammes de stockage et de lecteur. Vérifiez que les dernières mises à jour Windows sont installées sur tous les nœuds. Vous pouvez obtenir les dernières mises à jour pour Windows Server 2016 depuis l’Historique des mises à jour Windows 10 et Windows Server 2016. Procurez-vous les dernières mises à jour pour Windows Server 2019 depuis l’Historique des mises à jour Windows 10 et Windows Server 2019.
- Mettez à jour les pilotes et les microprogrammes de carte réseau.
- Exécutez la validation de cluster et passez en revue la section Espace de stockage direct. Vérifiez que les lecteurs que vous utilisez pour le cache sont bien répertoriés et qu’ils ne présentent pas d’erreurs.
Si les problèmes persistent, passez en revue les informations de dépannage concernant chaque problème spécifique traité dans cet article.
Les ressources du disque virtuel sont dans l’état Aucune redondance
Les nœuds d’un système d’espaces de stockage direct redémarrent de manière inattendue en raison d’un incident ou d’une panne d’alimentation. Ensuite, un ou plusieurs disques virtuels ne sont peut-être pas en ligne, et vous obtenez la description Informations de redondance insuffisantes.
| FriendlyName | ResiliencySettingName | OperationalStatus | HealthStatus | IsManualAttach | Taille | PSComputerName |
|---|---|---|---|---|---|---|
| Disk4 | Miroir | Ok | Healthy | True | 10 To | Node-01.conto... |
| Disk3 | Miroir | Ok | Healthy | True | 10 To | Node-01.contoso. |
| Disk2 | Miroir | Aucune redondance | Unhealthy | True | 10 To | Node-01.contoso. |
| Disk1 | Miroir | {No Redundancy, InService} | Unhealthy | True | 10 To | Node-01.contoso. |
De même, après une tentative de mise en ligne du disque virtuel, les informations suivantes sont consignées dans le journal de cluster, DiskRecoveryAction.
[Verbose] 00002904.00001040::YYYY/MM/DD-12:03:44.891 INFO [RES] Physical Disk <DiskName>: OnlineThread: SuGetSpace returned 0.
[Verbose] 00002904.00001040:: YYYY/MM/DD -12:03:44.891 WARN [RES] Physical Disk < DiskName>: Underlying virtual disk is in 'no redundancy' state; its volume(s) may fail to mount.
[Verbose] 00002904.00001040:: YYYY/MM/DD -12:03:44.891 ERR [RES] Physical Disk <DiskName>: Failing online due to virtual disk in 'no redundancy' state. If you would like to attempt to online the disk anyway, first set this resource's private property 'DiskRecoveryAction' to 1. We will try to bring the disk online for recovery, but even if successful, its volume(s) or CSV may be unavailable.
L’état opérationnel Aucune redondance se manifeste en cas de défaillance d’un disque ou si le système ne peut pas accéder aux données sur le disque virtuel. Ce problème peut se produire si un redémarrage intervient sur un nœud lors d’une opération de maintenance sur les nœuds.
Pour résoudre ce problème, procédez comme suit :
Supprimez les disques virtuels affectés de CSV. Ils sont alors placés dans le groupe Stockage disponible du cluster et commencent à se présenter sous le ResourceType
Physical Disk.Remove-ClusterSharedVolume -Name "CSV Name"Sur le nœud qui possède le groupe Stockage disponible, exécutez la commande suivante sur chaque disque dont l’état est Aucune redondance. Pour identifier le nœud sur lequel se trouve le groupe Stockage disponible, vous pouvez exécuter cette commande :
Get-ClusterGroupDéfinissez l’action de récupération du disque, puis démarrez le ou les disques.
Get-ClusterResource "Physical Disk Resource Name" | Set-ClusterParameter -Name DiskRecoveryAction -Value 1 Start-ClusterResource -Name "Physical Disk Resource Name"Une réparation doit démarrer automatiquement. Attendez la fin de la réparation. Il se peut qu’elle passe à l’état interrompu et démarre de nouveau. Pour surveiller la progression :
- Exécutez
Get-StorageJobpour surveiller l’état de la réparation et savoir quand elle se termine. - Exécutez
Get-VirtualDisket vérifiez que l’espace retourne la valeur Healthy (Sain) pour HealthStatus.
- Exécutez
Une fois la réparation terminée et les disques virtuels à l’état sain, modifiez de nouveau les paramètres de disque virtuel.
Get-ClusterResource "Physical Disk Resource Name" | Set-ClusterParameter -Name DiskRecoveryAction -Value 0Mettez le ou les disques hors connexion, puis remettez-les en ligne pour que
DiskRecoveryActionprenne effet :Stop-ClusterResource "Physical Disk Resource Name" Start-ClusterResource "Physical Disk Resource Name"Ajoutez de nouveau les disques virtuels affectés à CSV.
Add-ClusterSharedVolume -Name "Physical Disk Resource Name"
DiskRecoveryAction est un commutateur de remplacement qui permet d’attacher le volume d’espace en mode lecture-écriture sans aucune vérification. La propriété permet de déterminer pourquoi un volume n’est pas en ligne. Elle s’apparente au mode maintenance, mais vous pouvez l’appeler sur une ressource à l’état en échec. Elle vous permet également d’accéder aux données en vue de les copier. Cet accès est utile en cas d’absence de redondance. La propriété DiskRecoveryAction a été ajoutée à la mise à jour du 22 février 2018, KB 4077525.
État détaché dans un cluster
Lorsque vous exécutez la cmdlet Get-VirtualDisk, l’état OperationalStatus présente la valeur Detached (Détaché) pour un ou plusieurs disques virtuels d’espaces de stockage direct. Cependant, l’état HealthStatus signalé par la cmdlet Get-PhysicalDisk indique que tous les disques physiques sont à l’état Healthy (Sain).
Cet exemple montre la sortie de la cmdlet Get-VirtualDisk.
| FriendlyName | ResiliencySettingName | OperationalStatus | HealthStatus | IsManualAttach | Taille | PSComputerName |
|---|---|---|---|---|---|---|
| Disk4 | Miroir | Ok | Healthy | True | 10 To | Node-01.contoso. |
| Disk3 | Miroir | Ok | Healthy | True | 10 To | Node-01.contoso. |
| Disk2 | Miroir | Détachée | Unknown | True | 10 To | Node-01.contoso. |
| Disk1 | Miroir | Détachée | Unknown | True | 10 To | Node-01.contoso. |
De même, les événements suivants peuvent être journalisés sur les nœuds :
Log Name: Microsoft-Windows-StorageSpaces-Driver/Operational
Source: Microsoft-Windows-StorageSpaces-Driver
Event ID: 311
Level: Error
User: SYSTEM
Computer: Node#.contoso.local
Description: Virtual disk {GUID} requires a data integrity scan.
Data on the disk is out-of-sync and a data integrity scan is required.
To start the scan, run this command:
Get-ScheduledTask -TaskName "Data Integrity Scan for Crash Recovery" | Start-ScheduledTask
Once you have resolved that condition, you can online the disk by using these commands in PowerShell:
Get-VirtualDisk | ?{ $_.ObjectId -Match "{GUID}" } | Get-Disk | Set-Disk -IsReadOnly $false
Get-VirtualDisk | ?{ $_.ObjectId -Match "{GUID}" } | Get-Disk | Set-Disk -IsOffline $false
------------------------------------------------------------
Log Name: System
Source: Microsoft-Windows-ReFS
Event ID: 134
Level: Error
User: SYSTEM
Computer: Node#.contoso.local
Description: The file system was unable to write metadata to the media backing volume <VolumeId>. A write failed with status "A device which does not exist was specified." ReFS will take the volume offline. It might be mounted again automatically.
------------------------------------------------------------
Log Name: Microsoft-Windows-ReFS/Operational
Source: Microsoft-Windows-ReFS
Event ID: 5
Level: Error
User: SYSTEM
Computer: Node#.contoso.local
Description: ReFS failed to mount the volume.
Context: 0xffffbb89f53f4180
Error: A device which does not exist was specified.
Volume GUID:{00000000-0000-0000-0000-000000000000}
DeviceName:
Volume Name:
L’état Detached Operational Status se manifeste si le journal de suivi des zones obsolescentes (DRT) est plein. Les espaces de stockage utilisent le DRT pour les espaces mis en miroir de sorte que les mises à jour en cours d’exécution au niveau des métadonnées soient journalisées en cas de panne d’alimentation. Les mises à jour journalisées garantissent que l’espace de stockage peut rétablir ou annuler des opérations. Elles ramènent l’espace de stockage dans un état flexible et cohérent après le rétablissement de l’alimentation et la sauvegarde du système. Si le journal DRT est plein, le disque virtuel ne peut pas être mis en ligne tant que les métadonnées DRT n’ont pas été synchronisées et vidées. Ce processus nécessite l’exécution d’une analyse complète qui peut prendre plusieurs heures.
Pour résoudre ce problème, procédez comme suit :
Supprimez les disques virtuels affectés de CSV.
Remove-ClusterSharedVolume -Name "CSV Name"Exécutez ces commandes sur chaque disque qui ne se met pas en ligne.
Get-ClusterResource -Name "Physical Disk Resource Name" | Set-ClusterParameter DiskRunChkDsk 7 Start-ClusterResource -Name "Physical Disk Resource Name"Exécutez la commande suivante sur chaque nœud dans lequel le volume détaché est en ligne.
Get-ScheduledTask -TaskName "Data Integrity Scan for Crash Recovery" | Start-ScheduledTaskLancez cette tâche sur tous les nœuds pour lesquels le volume détaché est en ligne. Une réparation doit démarrer automatiquement. Attendez la fin de la réparation. Il se peut qu’elle passe à l’état interrompu et démarre de nouveau. Pour surveiller la progression :
- Exécutez
Get-StorageJobpour surveiller l’état de la réparation et savoir quand elle se termine. - Exécutez
Get-VirtualDisket vérifiez que l’espace retourne la valeur Healthy (Sain) pour HealthStatus.L’analyse de l’intégrité des données pour la récupération sur incident est une tâche qui ne s’affiche pas en tant que travail de stockage, et il n’existe aucun indicateur de progression. Si la tâche s’affiche comme étant en cours d’exécution, cela signifie qu’elle s’exécute. Une fois achevée, elle s’affiche comme étant terminée.
De même, vous pouvez consulter l’état d’une tâche de planification en cours d’exécution en utilisant cette cmdlet :
Get-ScheduledTask | ? State -eq running
- Exécutez
Une fois l’analyse de l’intégrité des données terminée pour la récupération sur incident, la réparation est terminée et les disques virtuels sont sains. Rétablissez les paramètres de disque virtuel.
Get-ClusterResource -Name "Physical Disk Resource Name" | Set-ClusterParameter DiskRunChkDsk 0Mettez le ou les disques hors connexion, puis remettez-les en ligne pour que
DiskRecoveryActionprenne effet :Stop-ClusterResource "Physical Disk Resource Name" Start-ClusterResource "Physical Disk Resource Name"Ajoutez de nouveau les disques virtuels affectés à CSV.
Add-ClusterSharedVolume -Name "Physical Disk Resource Name"Utilisez
DiskRunChkdsk value 7pour attacher le volume d’espace et définir la partition en mode lecture seule. Cette action permet aux espaces de se découvrir et d’auto-guérir en déclenchant une réparation. La réparation s’exécute automatiquement une fois montée. Elle vous permet également d’accéder aux données pour les copier. Pour certaines conditions d’erreur, telles qu’un journal DRT complet, vous devez exécuter la tâche planifiée Analyse de l’intégrité des données pour la récupération sur incident.
La tâche d’analyse de l’intégrité des données pour la récupération sur incident permet de synchroniser et d’effacer un journal DRT plein. Cette tâche peut prendre plusieurs heures. L’analyse de l’intégrité des données pour la récupération sur incident est une tâche qui ne s’affiche pas en tant que travail de stockage, et il n’existe aucun indicateur de progression. Si la tâche s’affiche comme étant en cours d’exécution, cela signifie qu’elle s’exécute. Une fois la tâche achevée, elle s’affiche comme étant terminée. Si vous annulez la tâche ou redémarrez un nœud pendant l’exécution de cette tâche, elle doit recommencer à partir du début.
Pour plus d’informations, consultez Résoudre les problèmes d’état d’intégrité et d’exploitation des espaces de stockage direct.
Événement 5120 avec STATUS_IO_TIMEOUT c00000b5
Important
Pour Windows Server 2016 : Pour limiter le risque de rencontrer ces symptômes pendant l’application de la mise à jour avec le correctif, nous vous recommandons d’utiliser la procédure du mode maintenance du stockage pour installer la mise à jour cumulative du 18 octobre 2018 pour Windows Server 2016 ou une version ultérieure lorsque la mise à jour cumulative Windows Server 2016 actuellement installée sur les nœuds a été publiée entre le 8 mai 2018 et le 9 octobre 2018.
Vous pouvez obtenir l’événement 5120 avec STATUS_IO_TIMEOUT c00000b5 après avoir redémarré un nœud sur Windows Server 2016 disposant de la mise à jour cumulative qui a été publiée entre le 8 mai 2018 KB 4103723 et le 9 octobre 2018 KB 4462917.
Lorsque vous redémarrez le nœud, l’événement 5120 est consigné dans le journal des événements système et comporte l’un de ces codes d’erreur :
Event Source: Microsoft-Windows-FailoverClustering
Event ID: 5120
Description: Cluster Shared Volume 'CSVName' ('Cluster Virtual Disk (CSVName)') has entered a paused state because of 'STATUS_IO_TIMEOUT(c00000b5)'. All I/O will temporarily be queued until a path to the volume is reestablished.
Cluster Shared Volume 'CSVName' ('Cluster Virtual Disk (CSVName)') has entered a paused state because of 'STATUS_CONNECTION_DISCONNECTED(c000020c)'. All I/O will temporarily be queued until a path to the volume is reestablished.
Lorsqu’un événement 5120 est journalisé, un vidage dynamique est généré pour collecter des informations de débogage qui peuvent causer d’autres symptômes ou nuire aux performances. Pendant la génération du vidage dynamique, une brève interruption se produit. Cette interruption permet à un instantané de mémoire d’écrire le fichier d’image mémoire. Les systèmes dotés d’une grande quantité de mémoire et fortement sollicités peuvent faire perdre aux nœuds leur appartenance au cluster et entraîner la journalisation de l’événement 1135 suivant.
Event source: Microsoft-Windows-FailoverClustering
Event ID: 1135
Description: Cluster node 'NODENAME'was removed from the active failover cluster membership. The Cluster service on this node might have stopped. This could also be due to the node having lost communication with other active nodes in the failover cluster. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapters on this node. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Une modification apportée le 8 mai 2018 à Windows Server 2016 était une mise à jour cumulative destinée à ajouter des handles résilients SMB pour les sessions réseau SMB intra-cluster des espaces de stockage direct. Cette mise à jour avait pour objectif d’améliorer la résilience face aux défaillances de réseau temporaires et la façon dont RoCE gérait la congestion du réseau. Ces améliorations ont également augmenté par inadvertance les délais d’attente lorsque des connexions SMB tentent de se reconnecter et attendent d’expirer lorsqu’un nœud est redémarré. Ces problèmes peuvent nuire à un système fortement sollicité. Pendant les temps d’arrêt non planifiés, des pauses d’E/S pouvant durer 60 secondes ont également été observées tandis que le système attendait l’expiration des connexions. Pour résoudre ce problème, installez la mise à jour cumulative du 18 octobre 2018 pour Windows Server 2016 ou une version ultérieure.
Remarque
Cette mise à jour aligne les délais d’attente CSV sur les délais d’attente de connexion SMB pour résoudre ce problème. Elle n’implémente pas les modifications pour désactiver la génération de vidage dynamique mentionnée dans la section Solution de contournement.
Flux du processus d’arrêt
Exécutez l’applet de commande Get-VirtualDisk et assurez-vous que la valeur HealthStatus est Sain.
Drainez le nœud en exécutant cette cmdlet :
Suspend-ClusterNode -DrainPlacez les disques de ce nœud en mode maintenance du stockage en exécutant cette cmdlet :
Get-StorageFaultDomain -Type StorageScaleUnit | Where-Object {$_.FriendlyName -eq "<NodeName>"} | Enable-StorageMaintenanceModeExécutez la cmdlet
Get-PhysicalDisket vérifiez que la valeur deOperationalStatusest le modeIn Maintenance.Exécutez la cmdlet
Restart-Computerpour redémarrer le nœud.Une fois le nœud redémarré, retirez les disques de ce nœud du mode maintenance du stockage en exécutant cette cmdlet :
Get-StorageFaultDomain -Type StorageScaleUnit | Where-Object {$_.FriendlyName -eq "<NodeName>"} | Disable-StorageMaintenanceModeReprenez le nœud en exécutant cette cmdlet :
Resume-ClusterNodeVérifiez l’état des travaux de resynchronisation en exécutant cette cmdlet :
Get-StorageJob
Désactivation des vidages dynamiques
Pour atténuer les effets de la génération du vidage dynamique sur les systèmes disposant d’une grande quantité de mémoire et qui sont fortement sollicités, vous pouvez désactiver la génération du vidage dynamique. Ces trois options vous sont fournies :
Attention
Cette procédure peut empêcher la collecte d’informations de diagnostic dont le Support Microsoft pourrait avoir besoin pour examiner le problème. Il est possible qu’un agent du support vous demande de réactiver la génération du vidage dynamique selon le scénario de dépannage.
Désactiver tous les vidages
Pour désactiver complètement tous les vidages, y compris les vidages dynamiques à l’échelle du système, suivez ces étapes. Utilisez cette procédure pour ce scénario :
- Créez la clé de registre suivante : HKLM\System\CurrentControlSet\Control\CrashControl\ForceDumpsDisabled
- Sous la nouvelle clé ForceDumpsDisabled, créez une propriété REG_DWORD comme GuardedHost, puis définissez sa valeur sur 0x10000000.
- Appliquez la nouvelle clé de registre à chaque nœud de cluster.
Remarque
Vous devez redémarrer l’ordinateur pour que la modification du registre prenne effet.
Une fois cette clé de registre définie, la création de vidage dynamique échoue et génère une erreur STATUS_NOT_SUPPORTED.
Autoriser un seul LiveDump
Par défaut, le Rapport d’erreurs Windows n’autorise qu’un seul LiveDump par type de rapport tous les sept jours, et seulement un LiveDump par machine tous les cinq jours. Vous pouvez modifier cela en définissant les clés de registre suivantes pour qu’elles n’autorisent qu’un seul LiveDump sur l’ordinateur pour toujours.
reg add "HKLM\Software\Microsoft\Windows\Windows Error Reporting\FullLiveKernelReports" /v SystemThrottleThreshold /t REG_DWORD /d 0xFFFFFFFF /f
reg add "HKLM\Software\Microsoft\Windows\Windows Error Reporting\FullLiveKernelReports" /v ComponentThrottleThreshold /t REG_DWORD /d 0xFFFFFFFF /f
Remarque
Vous devez redémarrer l’ordinateur pour que la modification prenne effet.
Désactiver la génération cluster
Pour désactiver la génération cluster de vidages dynamiques (par exemple, lorsqu’un événement 5120 est journalisé), exécutez cette cmdlet :
(Get-Cluster).DumpPolicy = ((Get-Cluster).DumpPolicy -Band 0xFFFFFFFFFFFFFFFE)
Cette applet de commande a un effet immédiat sur tous les nœuds de cluster sans redémarrage de l’ordinateur.
Performances d'E/S lentes
Si vous constatez des performances d’E/S lentes, vérifiez si le cache est activé dans votre configuration d’espaces de stockage direct.
Il existe deux façons de vérifier :
Utilisation du journal du cluster. Ouvrez le journal de cluster avec l’éditeur de texte de votre choix et recherchez « [=== SBL Disks ===] ». Vous voyez le disque sur le nœud où le journal a été généré.
Exemple de disques avec cache : notez que l’état est
CacheDiskStateInitializedAndBoundet qu’un GUID est présent ici.[=== SBL Disks ===] {26e2e40f-a243-1196-49e3-8522f987df76},3,false,true,1,48,{1ff348f1-d10d-7a1a-d781-4734f4440481},CacheDiskStateInitializedAndBound,1,8087,54,false,false,HGST,HUH721010AL4200,7PG3N2ER,A21D,{d5e27a3b-42fb-410a-81c6-9d8cc12da20c},[R/M 0 R/U 0 R/T 0 W/M 0 W/U 0 W/T 0],Cache non activé : vous pouvez voir ici qu’aucun GUID n’est présent et que l’état est
CacheDiskStateNonHybrid.[=== SBL Disks ===] {426f7f04-e975-fc9d-28fd-72a32f811b7d},12,false,true,1,24,{00000000-0000-0000-0000-000000000000},CacheDiskStateNonHybrid,0,0,0,false,false,HGST,HUH721010AL4200,7PGXXG6C,A21D,{d5e27a3b-42fb-410a-81c6-9d8cc12da20c},[R/M 0 R/U 0 R/T 0 W/M 0 W/U 0 W/T 0],Cache non activé : lorsque tous les disques sont du même type, le cas n’est pas activé par défaut. Vous pouvez voir ici qu’aucun GUID n’est présent et que l’état est
CacheDiskStateIneligibleDataPartition.{d543f90c-798b-d2fe-7f0a-cb226c77eeed},10,false,false,1,20,{00000000-0000-0000-0000-000000000000},CacheDiskStateIneligibleDataPartition,0,0,0,false,false,NVMe,INTEL SSDPE7KX02,PHLF7330004V2P0LGN,0170,{79b4d631-976f-4c94-a783-df950389fd38},[R/M 0 R/U 0 R/T 0 W/M 0 W/U 0 W/T 0],Utilisez Get-PhysicalDisk.xml à partir de SDDCDiagnosticInfo.
- Ouvrez le fichier XML en utilisant « $d = Import-Clixml GetPhysicalDisk.XML ».
- Exécutez
ipmo storage. - Exécutez
$d. Remarquez que Usage (Utilisation) a la valeur Auto-Select (Sélection automatique) et non Journal.
Vous obtenez une sortie de ce type :
FriendlyName SerialNumber MediaType CanPool OperationalStatus HealthStatus Utilisation Taille NVMe INTEL SSDPE7KX02 PHLF733000372P0LGN SSD False Ok Healthy Sélection automatique 1.82 To NVMe INTEL SSDPE7KX02 PHLF7504008J2P0LGN SSD False Ok Healthy Sélection automatique 1.82 To NVMe INTEL SSDPE7KX02 PHLF7504005F2P0LGN SSD False Ok Healthy Sélection automatique 1.82 To NVMe INTEL SSDPE7KX02 PHLF7504002A2P0LGN SSD False Ok Healthy Sélection automatique 1.82 To NVMe INTEL SSDPE7KX02 PHLF7504004T2P0LGN SSD False Ok Healthy Sélection automatique 1.82 To NVMe INTEL SSDPE7KX02 PHLF7504002E2P0LGN SSD False Ok Healthy Sélection automatique 1.82 To NVMe INTEL SSDPE7KX02 PHLF7330002Z2P0LGN SSD False Ok Healthy Sélection automatique 1.82 To NVMe INTEL SSDPE7KX02 PHLF733000272P0LGN SSD False Ok Healthy Sélection automatique 1.82 To NVMe INTEL SSDPE7KX02 PHLF7330001J2P0LGN SSD False Ok Healthy Sélection automatique 1.82 To NVMe INTEL SSDPE7KX02 PHLF733000302P0LGN SSD False Ok Healthy Sélection automatique 1.82 To NVMe INTEL SSDPE7KX02 PHLF7330004D2P0LGN SSD False Ok Healthy Sélection automatique 1.82 To
Comment détruire un cluster existant pour pouvoir utiliser les mêmes disques à nouveau
Dans un cluster Espaces de stockage direct, désactivez Espaces de stockage direct et utilisez le processus de nettoyage décrit dans Nettoyer les lecteurs. Le pool de stockage en cluster reste toujours à l’un état Offline (Hors connexion), et le service de contrôle d’intégrité est supprimé du cluster.
L’étape suivante consiste à supprimer le pool de stockage fantôme :
Get-ClusterResource -Name "Cluster Pool 1" | Remove-ClusterResource
Maintenant, si vous exécutez Get-PhysicalDisk sur n’importe lequel de ces nœuds, vous voyez tous les disques qui se trouvaient dans le pool. Par exemple, dans un lab comportant un cluster à 4 nœuds avec 4 disques SAS, de 100 Go chacun présentés sur chaque nœud. Dans ce cas, une fois l’espace de stockage direct désactivé, ce qui supprime le SBL (Storage Bus Layer) mais laisse le filtre, si vous exécutez Get-PhysicalDisk, il doit signaler 4 disques à l’exclusion du disque du système d’exploitation local. Au lieu de cela, il a en a signalé 16. Ce comportement est identique pour tous les nœuds du cluster. Lorsque vous exécutez une commande Get-Disk, vous voyez les disques attachés localement, qui sont numérotés 0, 1, 2, et ainsi de suite, comme indiqué dans cet exemple de sortie :
| Number | Nom convivial | Numéro de série | HealthStatus | OperationalStatus | Total Size | Type de partition |
|---|---|---|---|---|---|---|
| 0 | Msft Virtual | Healthy | En ligne | 127 Go | GPT | |
| Msft Virtual | Healthy | Hors connexion | 100 Go | RAW | ||
| Msft Virtual | Healthy | Hors connexion | 100 Go | RAW | ||
| Msft Virtual | Healthy | Hors connexion | 100 Go | RAW | ||
| Msft Virtual | Healthy | Hors connexion | 100 Go | RAW | ||
| 1 | Msft Virtual | Healthy | Hors connexion | 100 Go | RAW | |
| Msft Virtual | Healthy | Hors connexion | 100 Go | RAW | ||
| 2 | Msft Virtual | Healthy | Hors connexion | 100 Go | RAW | |
| Msft Virtual | Healthy | Hors connexion | 100 Go | RAW | ||
| Msft Virtual | Healthy | Hors connexion | 100 Go | RAW | ||
| Msft Virtual | Healthy | Hors connexion | 100 Go | RAW | ||
| Msft Virtual | Healthy | Hors connexion | 100 Go | RAW | ||
| 4 | Msft Virtual | Healthy | Hors connexion | 100 Go | RAW | |
| 3 | Msft Virtual | Healthy | Hors connexion | 100 Go | RAW | |
| Msft Virtual | Healthy | Hors connexion | 100 Go | RAW | ||
| Msft Virtual | Healthy | Hors connexion | 100 Go | RAW | ||
| Msft Virtual | Healthy | Hors connexion | 100 Go | RAW |
Message d’erreur relatif au « type de média non pris en charge » lorsque vous créez un cluster Espaces de stockage direct à l’aide de Enable-ClusterS2D
Il se peut que vous obteniez des erreurs similaires lorsque vous exécutez la cmdlet Enable-ClusterS2D :
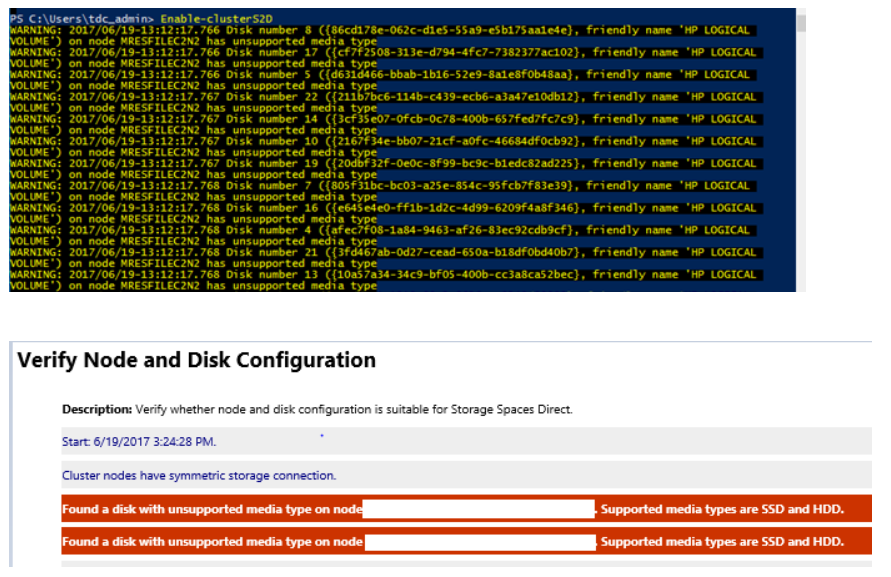
Pour résoudre ce problème, vérifiez que l’adaptateur HBA est configuré en mode HBA. Aucun HBA ne doit être configuré en mode RAID.
Enable-ClusterStorageSpacesDirect se bloque à « Attente jusqu’à ce que les disques SBL soient exposés » ou à 27 %
Vous voyez les informations suivantes dans le rapport de validation :
Le disque <identifier> connecté au nœud <nodename> a retourné une association de port SCSI et le périphérique à boîtier correspondant est introuvable. Le matériel n’est pas compatible avec les espaces de stockage direct (S2D). Contactez le fournisseur de matériel pour vérifier la prise en charge de SES (SCSI Enclosure Services).
Le problème concerne la carte expander HPE SAS qui se trouve entre les disques et la carte HBA. Expander SAS crée un ID dupliqué entre le premier lecteur connecté à expander et à l’expander lui-même. Ce problème a été résolu dans le microprogramme SAS Expander des contrôleurs HPE Smart Array : 4.02.
La série Intel SSD DC P4600 possède un NGUID non unique
Vous pouvez être confronté à un problème où un appareil de la série Intel SSD DC P4600 semble signaler un NGUID de 16 octets similaire pour plusieurs espaces de noms tels que 0100000001000000E4D25C000014E214 ou 0100000001000000E4D25C0000EEE214 dans cet exemple.
| UniqueId | DeviceId | MediaType | BusType | SerialNumber | Size | CanPool | FriendlyName | OperationalStatus |
|---|---|---|---|---|---|---|---|---|
| 5000CCA251D12E30 | 0 | HDD | SAS | 7PKR197G | 10000831348736 | False | HGST | HUH721010AL4200 |
| eui.0100000001000000E4D25C000014E214 | 4 | SSD | NVMe | 0100_0000_0100_0000_E4D2_5C00_0014_E214. | 1600321314816 | True | INTEL | SSDPE2KE016T7 |
| eui.0100000001000000E4D25C000014E214 | 5 | SSD | NVMe | 0100_0000_0100_0000_E4D2_5C00_0014_E214. | 1600321314816 | True | INTEL | SSDPE2KE016T7 |
| eui.0100000001000000E4D25C0000EEE214 | 6 | SSD | NVMe | 0100_0000_0100_0000_E4D2_5C00_00EE_E214. | 1600321314816 | True | INTEL | SSDPE2KE016T7 |
| eui.0100000001000000E4D25C0000EEE214 | 7 | SSD | NVMe | 0100_0000_0100_0000_E4D2_5C00_00EE_E214. | 1600321314816 | True | INTEL | SSDPE2KE016T7 |
Pour résoudre ce problème, mettez à jour le microprogramme sur les lecteurs Intel vers la dernière version. La version du microprogramme QDV101B1 de mai 2018 est connue pour résoudre ce problème.
La version de mai 2018 de l’outil Centre de données SSD Intel inclut une mise à jour du microprogramme, QDV101B1, pour les séries Intel SSD DC P4600.
HealthStatus pour le disque physique et OperationalStatus
Dans un cluster Espaces de stockage direct Windows Server 2016, vous pouvez constater que l’état HealthStatus est Healthy (Sain) pour un ou plusieurs disques physiques, alors que l’état OperationalStatus est Removing from Pool, OK (Suppression du pool, OK).
L’état Removing from Pool (Suppression du pool) est une intention définie lorsque Remove-PhysicalDisk est appelé, mais est stocké dans Health pour maintenir l’état et permettre une récupération en cas d’échec de l’opération de suppression. Vous pouvez faire passer manuellement l’état OperationalStatus à Healthy (Sain) avec l’une de ces méthodes :
- Supprimez le disque physique du pool, puis rajoutez-le.
- Import-Module Clear-PhysicalDiskHealthData.ps1.
- Exécutez le script Clear-PhysicalDiskHealthData.ps1 pour effacer l’intention. Ce script est disponible en téléchargement sous forme de fichier .txt. Vous devez l’enregistrer sous forme de fichier ps1 avant de pouvoir l’exécuter.
Voici quelques exemples montrant comment exécuter le script :
Utilisez le paramètre
SerialNumberpour spécifier le disque que vous devez définir sur Healthy (Sain). Vous pouvez obtenir le numéro de série à partir deWMI MSFT_PhysicalDiskouGet-PhysicalDisk. Cet exemple utilise des zéros en guise de numéro de série.Clear-PhysicalDiskHealthData -Intent -Policy -SerialNumber 000000000000000 -Verbose -ForceUtilisez le paramètre
UniqueIdpour spécifier le disque, là encore depuisWMI MSFT_PhysicalDiskouGet-PhysicalDisk.Clear-PhysicalDiskHealthData -Intent -Policy -UniqueId 00000000000000000 -Verbose -Force
La copie de fichiers est lente
Vous remarquerez peut-être que la copie de fichier prend plus de temps que prévu lorsque vous utilisez l’Explorateur de fichiers pour copier un VHD volumineux sur le disque virtuel.
Nous vous déconseillons d’utiliser l’Explorateur de fichiers, Robocopy ou Xcopy pour copier un VHD volumineux sur le disque virtuel. Cela se traduit par des performances en retrait. Le processus de copie ne passe pas par la pile d’espaces de stockage direct, qui se trouve plus bas sur la pile de stockage, et agit plutôt comme un processus de copie local.
Si vous souhaitez tester les performances des espaces de stockage direct, nous vous recommandons d’utiliser VMFleet et Diskspd pour charger et tester les serveurs. Vous obtiendrez ainsi une base de référence et pourrez définir vos attentes par rapport aux performances des espaces de stockage direct.
Événements attendus visibles sur le reste des nœuds lors du redémarrage d’un nœud
Vous pouvez ignorer ces événements :
Event ID 205: Windows lost communication with physical disk {XXXXXXXXXXXXXXXXXXXX}. This can occur if a cable failed or was disconnected, or if the disk itself failed.
Event ID 203: Windows lost communication with physical disk {XXXXXXXXXXXXXXXXXXXX}. This can occur if a cable failed or was disconnected, or if the disk itself failed.
Si vous exécutez des machines virtuelles Azure, vous pouvez ignorer cet événement : ID d’événement 32 : Le pilote a détecté que le cache en écriture est activé sur l’appareil \Device\Harddisk5\DR5. Une altération des données pourrait se produire.
Performances faibles ou erreurs de type « Communication perdue », « Erreur d’E/S », « Détaché » ou « Aucune redondance » pour les déploiements qui utilisent des appareils Intel P3x00 NVMe
Nous avons identifié un problème critique qui affecte certains utilisateurs d’espaces de stockage direct qui utilisent du matériel basé sur la famille Intel P3x00 des appareils NVM Express (NVMe) avec des versions de microprogramme antérieures à la « version de maintenance 8 ».
Remarque
Il est possible que les appareils de certains OEM soient basés sur la famille Intel P3x00 des appareils NVMe avec des chaînes de version de microprogramme uniques. Contactez votre OEM pour plus d’informations sur la dernière version du microprogramme.
Si le matériel que vous utilisez dans votre déploiement est basé sur la famille Intel P3x00 des appareils NVMe, nous vous recommandons d’appliquer immédiatement le dernier microprogramme disponible (au moins la version de maintenance 8).