Clonage de bloc sur ReFS
Le clonage de bloc demande au système de fichiers de copier une plage d’octets de ficher pour le compte d’une application. Les fichiers source et de destination utilisés peuvent être identiques ou différents. Malheureusement, les opérations de copie traditionnelles sont coûteuses, car elles déclenchent des lectures et des écritures coûteuses sur les données physiques sous-jacentes.
Dans ReFS, le clonage de bloc effectue les copies dans le cadre d’une opération de métadonnées moins coûteuse que la lecture et l’écriture des données de fichier. ReFS permet à un ensemble de fichiers de partager les mêmes clusters logiques (emplacements physiques sur un volume). Les opérations de copie ont donc uniquement à remapper une région d’un fichier vers un emplacement physique distinct, ce qui est plus rapide et logique que d’effectuer des opérations physiques coûteuses. Ce processus accélère les opérations de copie et réduit le nombre d’E/S générées dans le stockage sous-jacent. Cette amélioration bénéficie également aux charges de travail de virtualisation, car les opérations de fusion de point de contrôle .vhdx sont considérablement accélérées lors de l’utilisation des opérations de clonage de bloc. De plus, comme plusieurs fichiers peuvent partager les mêmes clusters logiques, les données identiques ne sont pas stockées à plusieurs emplacements physiques, ce qui augmente la capacité de stockage.
Fonctionnement
Le clonage de bloc sur ReFS transforme les opérations de données de fichier en opérations de métadonnées. Pour rendre possible cette optimisation, ReFS introduit des nombres de références dans ses métadonnées pour les régions copiées. Ce nombre de références indique le nombre de régions du fichier distinctes qui font référence aux mêmes régions physiques. Cela permet à plusieurs fichiers de partager les mêmes données physiques :
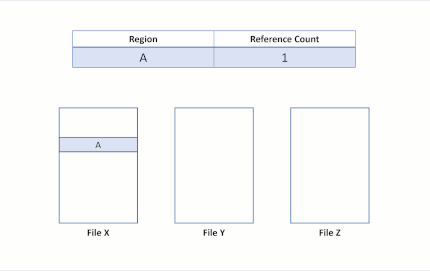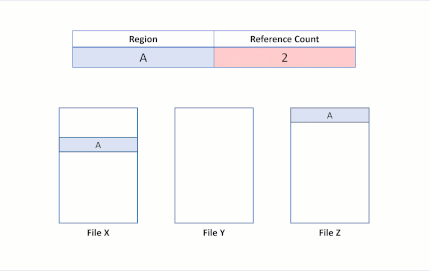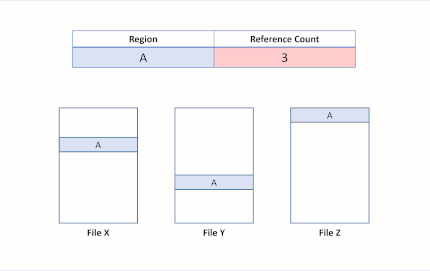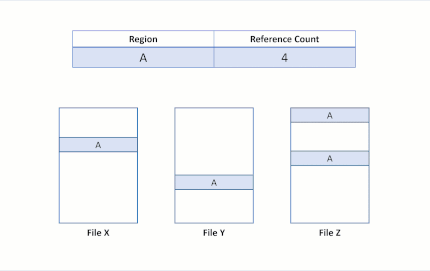
ReFS enregistre le nombre de références pour chaque cluster logique, ce qui maintient l’isolation entre les fichiers : les opérations d’écriture dans les régions partagées déclenchent un mécanisme d’allocation sur écriture, où ReFS alloue une nouvelle région pour l’opération d’écriture entrante. Ce mécanisme préserve l’intégrité des clusters logiques partagés.
Exemple
Prenons l’exemple de deux fichiers, appelés X et Y, qui contiennent chacun trois régions mappées à des clusters logiques distincts.
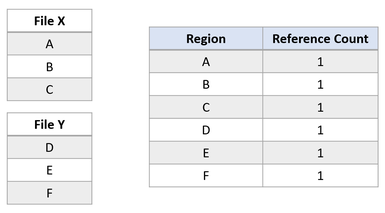
Supposons maintenant qu’une application émette une opération de clonage de bloc du fichier X vers le fichier Y pour que les régions A et B soient copiées au niveau de la région E. Nous obtenons alors l’état du système de fichiers suivant :
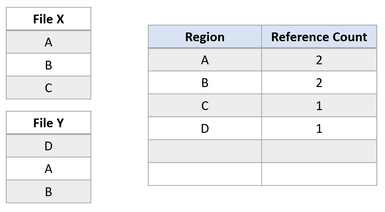
Cet état du système de fichiers indique que la région de clonage de bloc a été dupliquée. ReFS effectue cette opération de copie uniquement en mettant à jour les mappages VCN en LCN, sans que cela nécessite de lecture de données physiques, ni de remplacement de données physiques dans le fichier Y. Les fichiers X et Y partagent maintenant des clusters logiques, comme le montre les nombres de références dans le tableau. Du fait qu’il n’y a pas de données physiques à copier, ReFS permet d’utiliser moins de capacité de stockage sur le volume.
Supposons maintenant que l’application tente d’écraser la région A dans le fichier X. ReFS duplique la région partagée, met à jour les comptes de référence en conséquence, et effectue l’écriture entrante sur la région nouvellement dupliquée. Cela permet de préserver l’isolation entre les fichiers.
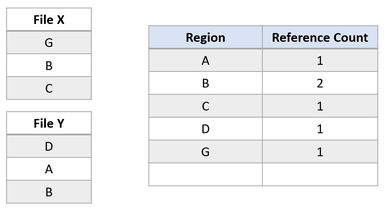
Après cette modification, la région B est toujours partagée par les deux fichiers. Si la région A était plus grande qu’un cluster, seul le cluster modifié aurait été dupliqué, et la portion restante serait restée partagée.
Remarques et restrictions relatives à la fonctionnalité
- Les régions source et de destination doivent commencer et finir à la limite d’un cluster.
- La région clonée doit mesurer moins de 4 Go.
- Le nombre maximal de régions d’un fichier pouvant être mappées à la même région physique est 8175.
- La région de destination ne doit pas dépasser la fin du fichier. Pour que l’application puisse étendre la destination des données clonées, elle doit d’abord appeler SetEndOfFile.
- Si les régions source et de destination se trouvent dans le même fichier, elles ne doivent pas se chevaucher. (L’application doit pouvoir continuer l’opération de clonage de bloc en la fractionnant en plusieurs clones de bloc qui ne se chevauchent plus.)
- Les fichiers source et de destination doivent se trouver sur le même volume ReFS.
- Les fichiers source et de destination doivent être définis avec le même paramètre Flux d’intégrité.
- Si le fichier source est partiellement alloué, le fichier de destination doit l’être également.
- L’opération de clonage de bloc casse les verrous opportunistes partagés (également appelés verrous opportunistes de niveau 2).
- Le volume ReFS doit avoir été formaté avec Windows Server 2016, et si le clustering de basculement est utilisé, le niveau fonctionnel de clustering doit être Windows Server 2016 ou plus récent au moment du formatage.
- À partir des builds de Windows 11 24H2 et Windows Server 2025, le clonage de bloc s’effectue nativement dans les opérations de copie Windows prises en charge.