Analyse CPU
Ce guide fournit des techniques détaillées que vous pouvez utiliser pour examiner les problèmes liés aux unités de traitement centralisées (UC) qui affectent les métriques d’évaluation d’impact.
Les sections de métrique ou de problème individuelles des guides d’analyse spécifiques à l’évaluation identifient les problèmes courants à examiner. Ce guide fournit des techniques et des outils que vous pouvez utiliser pour examiner ces problèmes.
Les techniques de ce guide utilisent windows Analyseur de performances (WPA) à partir de Windows Performance Toolkit (WPT). Le WPT fait partie du Kit de déploiement et d’évaluation Windows (Windows ADK) et peut être téléchargé à partir du programme Windows Insider. Pour plus d’informations, consultez La référence technique de Windows Performance Toolkit.
Ce guide est organisé en trois sections suivantes :
Cette section décrit comment les ressources processeur sont gérées dans Windows 10. |
|
Cette section explique comment afficher et interpréter les informations du processeur dans le Kit de ressources Windows ADK. |
|
Cette section contient une collection de techniques que vous pouvez utiliser pour examiner et résoudre les problèmes courants liés aux performances du processeur. |
Arrière-plan
Cette section contient des descriptions simples et une discussion de base sur les performances du processeur. Pour une étude plus complète sur ce sujet, nous vous recommandons le livre Windows Internals, Fifth Edition.
Les ordinateurs modernes peuvent contenir plusieurs processeurs installés dans des sockets distincts. Chaque processeur peut héberger plusieurs cœurs de processeur physique, chacun capable de traiter simultanément un ou deux flux d’instructions distincts. Ces processeurs de flux d’instructions individuels sont gérés par le système d’exploitation Windows en tant que processeurs logiques.
Dans ce guide, le processeur et le processeur font référence à un processeur logique, c’est-à-dire un périphérique matériel que le système d’exploitation peut utiliser pour exécuter des instructions de programme.
Windows 10 gère activement le matériel processeur de deux manières principales : la gestion de l’alimentation, l’équilibre entre la consommation d’énergie et les performances et l’utilisation, afin d’équilibrer les exigences de traitement des programmes et des pilotes.
Réglage de la gestion de la puissance du processeur
Les processeurs n’existent pas toujours dans un état d’exploitation. Quand aucune instruction n’est prête à s’exécuter, Windows place un processeur dans un état d’inactivité cible (ou C-State), tel que déterminé par Windows Power Manager. En fonction des modèles d’utilisation du processeur, l’état C cible d’un processeur sera ajusté au fil du temps.
Les états inactifs sont des états numérotés de C0 (actif ; non inactif) par des états de puissance progressivement inférieurs. Ces états incluent C1 (arrêté, mais l’horloge est toujours activée), C2 (arrêté et l’horloge est désactivée), etc. L’implémentation d’états inactifs est spécifique au processeur. Toutefois, un nombre d’état plus élevé dans tous les processeurs reflète une consommation d’alimentation inférieure, mais également un temps d’attente plus long avant que le processeur puisse revenir au traitement des instructions. Le temps passé dans les états inactifs affecte considérablement l’utilisation de l’énergie et la durée de vie de la batterie.
Certains processeurs peuvent fonctionner dans des états de performances (P-) et de limitation (T-), même lorsqu’ils traitent activement des instructions. Les états P définissent les fréquences d’horloge et les niveaux de tension pris en charge par le processeur. Les états T ne modifient pas directement la fréquence de l’horloge, mais peuvent réduire la vitesse d’horloge effective en ignorant l’activité de traitement sur une fraction de cycles d’horloge. Ensemble, les états P et T actuels déterminent la fréquence d’exploitation effective du processeur. Les fréquences inférieures correspondent à des performances inférieures et à une consommation d’énergie inférieure.
Windows Power Manager détermine un état P et T approprié pour chaque processeur, en fonction des modèles d’utilisation du processeur et de la stratégie d’alimentation du système. Le temps passé dans des états hautes performances par rapport à des états à faible performance affecte considérablement l’utilisation de l’énergie et la durée de vie de la batterie.
Gestion de l’utilisation du processeur
Windows utilise trois abstractions majeures pour gérer l’utilisation du processeur.
Processus
Threads
Appels de procédure différés (DPC) et routines de service d’interruption (ISR)
Processus et threads
Tous les programmes en mode utilisateur dans Windows s’exécutent dans le contexte d’un processus. Un processus inclut les attributs et composants suivants :
Espace d’adressage virtuel
Classe Priority
Modules de programme chargés
Informations sur l’environnement et la configuration
Au moins un thread
Bien que les processus contiennent les modules de programme, le contexte et l’environnement, ils ne sont pas directement planifiés pour s’exécuter sur un processeur. Au lieu de cela, les threads appartenant à un processus sont planifiés pour s’exécuter sur un processeur.
Un thread gère les informations de contexte d’exécution. Presque tous les calculs sont gérés dans le cadre d’un thread. L’activité de thread affecte fondamentalement les mesures et les performances du système.
Étant donné que le nombre de processeurs d’un système est limité, tous les threads ne peuvent pas être exécutés en même temps. Windows implémente le partage de temps processeur, ce qui permet à un thread de s’exécuter pendant un certain temps avant que le processeur bascule vers un autre thread. L’acte de basculement entre les threads est appelé commutateur de contexte et il est effectué par un composant Windows appelé répartiteur. Le répartiteur prend des décisions de planification des threads en fonction de la priorité, du processeur idéal et de l’affinité, du quantum et de l’état.
Priorité
La priorité est un facteur clé dans la façon dont le répartiteur sélectionne le thread à exécuter. La priorité du thread est un entier compris entre 0 et 31. Si un thread est exécutable et a une priorité plus élevée qu’un thread en cours d’exécution, le thread de priorité inférieure est immédiatement préempté et le thread de priorité supérieure est basculé dans le contexte.
Lorsqu’un thread est en cours d’exécution ou est prêt à s’exécuter, aucun thread de priorité inférieure ne peut s’exécuter, sauf s’il existe suffisamment de processeurs pour exécuter les deux threads en même temps, ou à moins que le thread de priorité supérieure ne soit limité à s’exécuter sur qu’un sous-ensemble de processeurs disponibles. Les threads ont une priorité de base qui peut être temporairement élevée vers des priorités plus élevées à certains moments : par exemple, lorsque le processus possède la fenêtre de premier plan ou lorsqu’une E/S est terminée.
Processeur idéal et affinité
Le processeur et l’affinité idéaux d’un thread déterminent les processeurs sur lesquels un thread donné est planifié pour s’exécuter. Chaque thread a un processeur idéal défini par le programme ou automatiquement par Windows. Windows utilise une méthodologie de tourniquet pour qu’un nombre de threads d’environ égal dans chaque processus soit affecté à chaque processeur. Si possible, Windows planifie l’exécution d’un thread sur son processeur idéal ; toutefois, le thread peut parfois s’exécuter sur d’autres processeurs.
L’affinité du processeur d’un thread limite les processeurs sur lesquels un thread s’exécutera. Il s’agit d’une restriction plus forte que l’attribut de processeur idéal du thread. Le programme définit l’affinité à l’aide de SetThreadAffinityMask. L’affinité peut empêcher l’exécution des threads sur des processeurs particuliers.
Quantum
Les commutateurs de contexte sont des opérations coûteuses. Windows permet généralement à chaque thread de s’exécuter pendant une période appelée quantum avant de basculer vers un autre thread. La durée quantique est conçue pour préserver la réactivité apparente du système. Il optimise le débit en minimisant la surcharge de basculement de contexte. Les durées quantiques peuvent varier entre les clients et les serveurs. Les durées quantiques sont généralement plus longues sur un serveur pour optimiser le débit au détriment de la réactivité apparente. Sur les ordinateurs clients, Windows affecte des quantums plus courts dans l’ensemble, mais fournit un quantum plus long au thread associé à la fenêtre de premier plan actuelle.
État
Chaque thread existe dans un état d’exécution particulier à tout moment. Windows utilise trois états pertinents pour les performances ; voici : En cours d’exécution, Prêt et En attente.
Les threads en cours d’exécution sont dans l’état en cours d’exécution . Les threads qui peuvent s’exécuter, mais qui ne sont pas en cours d’exécution, sont dans l’état Prêt . Les threads qui ne peuvent pas s’exécuter, car ils attendent un événement particulier sont dans l’état d’attente .
Une transition d’état en état est illustrée dans la figure 1 Transitions d’état de thread :
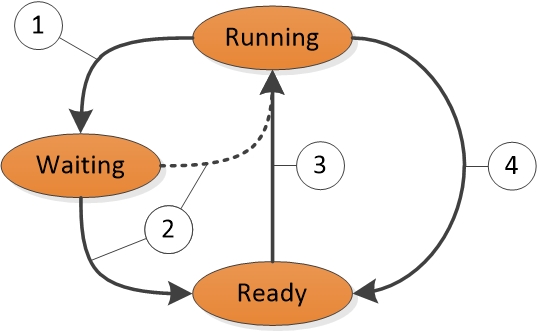
Figure 1 Transitions d’état de thread
La figure 1 Transitions d’état de thread est expliquée comme suit :
Un thread dans l’état en cours d’exécution lance une transition vers l’état d’attente en appelant une fonction d’attente telle que WaitForSingleObject ou Sleep(> 0).
Une opération de thread ou de noyau en cours d’exécution lit un thread dans l’état d’attente (par exemple, l’expiration de SetEvent ou de minuteur). Si un processeur est inactif ou si le thread prêt a une priorité plus élevée qu’un thread en cours d’exécution, le thread prêt peut basculer directement vers l’état en cours d’exécution. Sinon, il est placé dans l’état Prêt.
Un thread dans l’état Prêt est planifié pour le traitement par le répartiteur lorsqu’un thread en cours d’exécution attend, génère (Sleep(0)) ou atteint la fin de son quantum.
Un thread dans l’état en cours d’exécution est désactivé et placé dans l’état Prêt par le répartiteur lorsqu’il est préempté par un thread de priorité supérieure, génère (Sleep(0)) ou lorsque son quantum se termine.
Un thread qui existe dans l’état d’attente n’indique pas nécessairement un problème de performances. La plupart des threads passent beaucoup de temps dans l’état d’attente, ce qui permet aux processeurs d’entrer dans des états inactifs et d’économiser de l’énergie. L’état du thread devient un facteur important dans les performances uniquement lorsqu’un utilisateur attend qu’un thread termine une opération.
DPCs et ISR
Outre le traitement des threads, les processeurs répondent aux notifications provenant d’appareils matériels tels que des cartes réseau ou des minuteurs. Lorsqu’un périphérique matériel nécessite une attention du processeur, il génère une interruption. Windows répond à une interruption matérielle en suspendant un thread en cours d’exécution et en exécutant l’ISR associé à l’interruption.
Pendant le temps qu’il exécute un ISR, un processeur peut être empêché de gérer toute autre activité, y compris d’autres interruptions. Pour cette raison, les ISR doivent se terminer rapidement ou les performances du système peuvent se dégrader. Pour réduire le temps d’exécution, les ISR planifient généralement des DPC pour effectuer des tâches qui doivent être effectuées en réponse à une interruption. Pour chaque processeur logique, Windows gère une file d’attente de contrôleurs de domaine planifiés. Les dpcs prennent la priorité sur les threads à n’importe quel niveau de priorité. Avant qu’un processeur ne retourne aux threads de traitement, il exécute toutes les dpcs dans sa file d’attente.
Pendant le temps qu’un processeur exécute des contrôleurs de domaine et des ISR, aucun thread ne peut s’exécuter sur ce processeur. Cette propriété peut entraîner des problèmes pour les threads qui doivent effectuer un travail à un débit donné ou avec un minutage précis, tel qu’un thread qui lit du contenu audio ou vidéo. Si le temps processeur utilisé pour exécuter des contrôleurs de domaine et des ISR empêche ces threads de recevoir suffisamment de temps de traitement, le thread peut ne pas atteindre son débit requis ou terminer ses éléments de travail à temps.
Outils Windows ADK
Windows ADK écrit des informations matérielles et des évaluations dans les fichiers de résultats d’évaluation. WPA fournit des informations détaillées sur l’utilisation du processeur dans différents graphiques. Cette section explique comment utiliser Windows ADK et WPA pour collecter, afficher et analyser les données de performances du processeur.
Fichiers de résultats de l’évaluation Windows ADK
Étant donné que Windows prend uniquement en charge les systèmes multiprocesseurs symétriques, toutes les informations de cette section s’appliquent à tous les processeurs et cœurs installés.
Des informations détaillées sur le matériel processeur sont disponibles dans la EcoSysInfo section d’un fichier de résultats d’évaluation sous le <Processor><Instance id=”0”> nœud.
Par exemple :
<Processor>
<Instance id="0">
<ProcessorName>The name of the first CPU</ProcessorName>
<TSCFrequency>The maximum frequency of the first CPU</TSCFrequency>
<NumProcs>The total number of processors</NumProcs>
<NumCores>The total number of cores</NumCores>
<NumCPUs>The total number of logical processors</NumCPUs>
...and so on...
Graphes WPA
Une fois que vous avez chargé une trace dans WPA, vous trouverez des informations matérielles sur le processeur sous les sections Trace/Configuration du système/Configuration du système/PnP de l’interface utilisateur WPA.
Notez que toutes les procédures de ce guide se produisent dans WPA.
Graphique des états inactifs du processeur
Si les informations d’état d’inactivité sont collectées dans une trace, le graphique États inactifs power/PROCESSEUR s’affiche dans l’interface utilisateur WPA. Ce graphique contient toujours des données sur l’état d’inactivité cible pour chaque processeur. Le graphique contient également des informations sur l’état d’inactivité réel de chaque processeur si cet état est pris en charge par le processeur.
Chaque ligne du tableau suivant décrit une modification d’état inactif pour l’état cible ou réel d’un processeur. Les colonnes suivantes sont disponibles pour chaque ligne du graphique :
| Colonne | Détails |
|---|---|
UC |
Processeur affecté par le changement d’état. |
Heure d’entrée |
Heure à laquelle le processeur a entré l’état inactif. |
Heure de sortie |
Heure à laquelle le processeur a quitté l’état inactif. |
Max :Duration(ms) |
Temps passé dans l’état inactif (agrégation par défaut :maximum). |
Min :Duration(ms) |
Temps passé dans l’état inactif (agrégation par défaut :minimum). |
État suivant |
État vers lequel le processeur a été transféré après l’état actuel. |
État de préversion |
État à partir duquel le processeur a été transféré avant l’état actuel. |
État |
État d’inactivité actuel. |
État (numérique) |
État inactif actuel sous la forme d’un nombre (par exemple, 0 pour C0). |
Sum :Duration(ms) |
Temps passé dans l’état inactif (agrégation :sum par défaut). |
Table |
Inutilisé |
Type |
Cible (pour l’état cible sélectionné de Power Manager pour le processeur) ou Réel (pour l’état d’inactivité réel du processeur). |
Le profil WPA par défaut fournit deux présélections pour ce graphique : État par type, processeur et diagramme d’état par type, processeur.
État par type, processeur
Les états cibles et réels de chaque uc sont graphiques avec le numéro d’état sur l’axe Y dans l’état par type, graphique processeur . Figure 2 État d’inactivité du processeur par type, l’UC indique l’état réel de l’UC à mesure qu’il varie entre les états inactifs actifs et cibles.
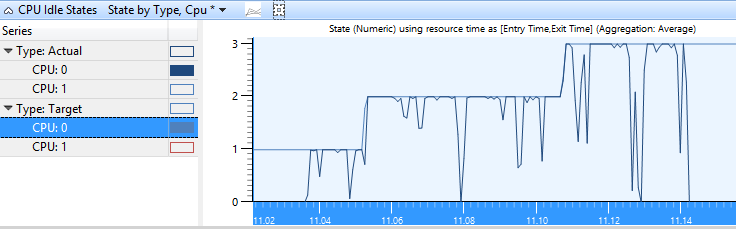
Figure 2 État d’inactivité du processeur par type, PROCESSEUR
Diagramme d’état par type, PROCESSEUR
Dans ce graphique, les états cibles et réels de chaque UC sont présentés au format chronologie. Chaque état a une ligne distincte dans la chronologie. Figure 3 Diagramme d’état d’inactivité de l’UC par type, l’UC affiche les mêmes données que l’état d’inactivité de l’UC par type, processeur, dans une vue de chronologie.
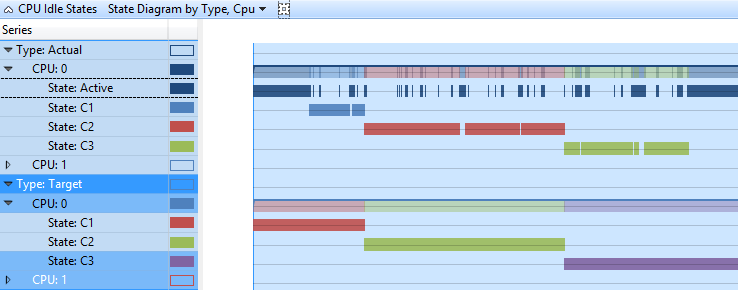
Figure 3 Diagramme d’état inactif du processeur par type, PROCESSEUR
Graphique de fréquence du processeur
Si les données de fréquence du processeur ont été collectées sur un système qui prend en charge plusieurs états P ou T, le graphique fréquence du processeur est disponible dans l’interface utilisateur WPA. Chaque ligne du tableau suivant représente le temps à un niveau de fréquence particulier pour un processeur. La colonne Fréquence (MHz) contient un nombre limité de fréquences qui correspondent aux états P et aux états T pris en charge par le processeur. Les colonnes suivantes sont disponibles pour chaque ligne du graphique :
| Colonne | Détails |
|---|---|
% durée |
La durée est exprimée sous la forme d’un pourcentage de temps processeur total sur la période actuellement visible. |
Count |
Nombre de modifications de fréquence (toujours 1 pour les lignes individuelles). |
UC |
Processeur affecté par la modification de fréquence. |
Heure d’entrée |
Heure à laquelle l’UC est entrée dans l’état P. |
Heure de sortie |
Heure à laquelle le processeur a quitté l’état P. |
Fréquence (MHz) |
Fréquence de l’UC pendant la durée pendant laquelle elle est dans l’état P. |
Max :Duration(ms) |
Temps passé dans l’état P (agrégation par défaut :maximum). |
Min :Duration(ms) |
Temps passé dans l’état P (agrégation par défaut :minimum). |
Sum :Duration(ms) |
Temps passé dans l’état P (agrégation par défaut :sum). |
Table |
Inutilisé |
Type |
Informations supplémentaires sur l’état P. |
Le profil par défaut définit la fréquence par préréglage du processeur pour ce graphique. La figure 4 Fréquence de l’UC par processeur montre un processeur lors de la transition entre trois états P :

Figure 4 Fréquence du processeur par processeur
Graphique de l’utilisation du processeur (échantillonné)
Les données affichées dans le graphique Utilisation de l’UC (Échantillonné) représentent des exemples d’activité processeur prises à intervalle d’échantillonnage régulier. Dans la plupart des traces, il s’agit d’une milliseconde (1 ms). Chaque ligne du tableau représente un exemple unique.
Le poids de l’échantillon représente l’importance de cet échantillon, par rapport à d’autres échantillons. Le poids est égal à l’horodatage de l’échantillon actuel moins l’horodatage de l’échantillon précédent. Le poids n’est pas toujours exactement égal à l’intervalle d’échantillonnage en raison de fluctuations de l’état et de l’activité du système.
La figure 5 Échantillonnage du processeur représente la façon dont les données sont collectées :
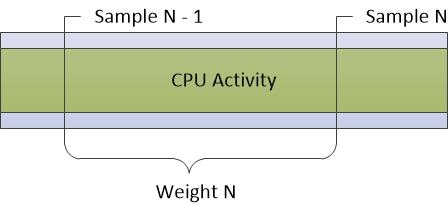
Figure 5 Échantillonnage du processeur
Toute activité processeur qui se produit entre des échantillons n’est pas enregistrée par cette méthode d’échantillonnage. Par conséquent, les activités de très courte durée telles que les DPCS et les ISR ne sont pas bien représentées dans le graphique d’échantillonnage du processeur.
Les colonnes suivantes sont disponibles pour chaque ligne du graphique :
| Colonne | Détails |
|---|---|
% de poids |
Le poids est exprimé sous la forme d’un pourcentage du temps processeur total passé sur l’intervalle de temps actuellement visible. |
Adresse |
Adresse mémoire de la fonction située en haut de la pile. |
Tous les nombres |
Nombre d’échantillons représentés par une ligne. Ce nombre inclut des exemples pris lorsqu’un processeur est inactif. Pour les lignes individuelles, cette colonne est toujours 1. |
Count |
Nombre d’échantillons représentés par une ligne, à l’exclusion des échantillons pris lorsqu’un processeur est inactif. Pour les lignes individuelles, cette colonne est toujours 1 (ou 0, pour les cas où le processeur était dans un état de faible puissance). |
UC |
Index de base 0 de l’UC sur lequel cet exemple a été effectué. |
Nom d’affichage |
Nom complet du processus actif. |
DPC/ISR |
Que l’exemple mesure l’utilisation régulière du processeur, un DPC/ISR ou un état d’alimentation faible. |
Fonction |
Fonction située en haut de la pile. |
Module |
Module qui contient la fonction en haut de la pile. |
Priorité |
Priorité du thread en cours d’exécution. |
Process |
Nom de l’image du processus propriétaire du code en cours d’exécution. |
Nom du processus |
Nom complet (y compris l’ID de processus) du processus propriétaire du code en cours d’exécution. |
Pile |
Pile du thread en cours d’exécution. |
ID du thread |
ID du thread en cours d’exécution. |
Fonction de démarrage du thread |
Fonction avec laquelle le thread en cours d’exécution a démarré. |
Module de démarrage du thread |
Module qui contient la fonction de démarrage du thread. |
TimeStamp |
Heure à laquelle l’échantillon a été prélevé. |
Poids |
Heure (en millisecondes) représentée par l’exemple (c’est-à-dire l’heure depuis le dernier échantillon). |
Le profil par défaut fournit les présélections suivantes pour ce graphique :
Utilisation par processeur
Utilisation par priorité
Utilisation par processus
Utilisation par processus et thread
Utilisation par processeur
Le graphique Utilisation de l’utilisation du processeur par processeur montre comment le travail est distribué entre les processeurs. La figure 6 Utilisation de l’utilisation du processeur par uc montre cette distribution pour deux processeurs :
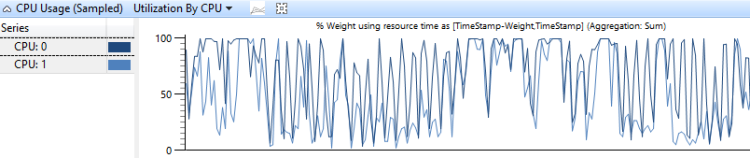
Figure 6 Utilisation de l’utilisation du processeur par processeur
Utilisation par priorité
L’utilisation du processeur regroupée par priorité de thread montre comment les threads à priorité élevée affectent les threads de priorité inférieure. La figure 7 Utilisation de l’UC (échantillonné) utilisation par priorité affiche ce graphique :
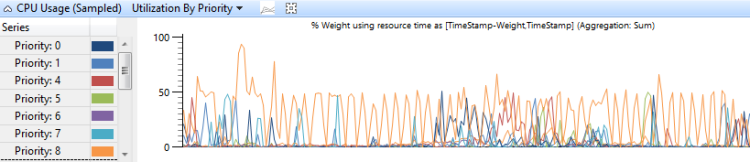
Figure 7 Utilisation du processeur (échantillonné) par priorité
Utilisation par processus
L’utilisation du processeur regroupée par processus indique l’utilisation relative des processus. La figure 8 Utilisation de l’UC (échantillonné) par processus montre cette présélection. Dans cet exemple de graphique, un processus s’affiche pour prendre plus de temps processeur que les autres processus.
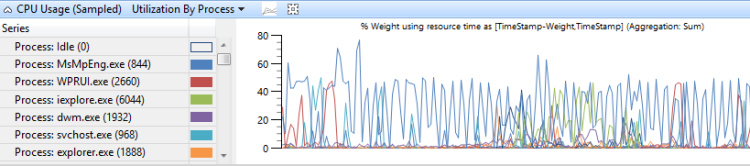
Figure 8 Utilisation de l’UC (échantillonné) Utilisation par processus
Utilisation par processus et thread
L’utilisation du processeur regroupée par processus, puis regroupée par thread montre l’utilisation relative des processus et des threads dans chaque processus. La figure 9 Utilisation de l’UC (échantillonné) par processus et thread montre cette présélection. Les threads d’un seul processus sont sélectionnés dans ce graphique.
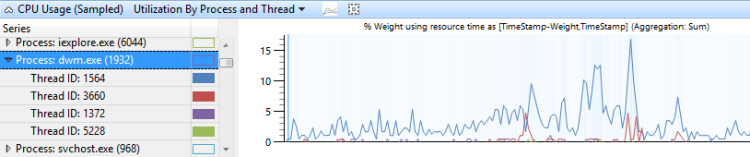
Figure 9 Utilisation du processeur (échantillonné) par processus et thread
Graphique d’utilisation du processeur (précis)
Le graphique Utilisation du processeur (Précision) enregistre les informations associées aux événements de basculement de contexte. Chaque ligne représente un ensemble de données associées à un commutateur de contexte unique ; autrement dit, quand un thread a commencé à s’exécuter. Les données sont collectées pour la séquence d’événements suivante :
Le nouveau thread est déconnecté.
Le nouveau thread est prêt à s’exécuter par le thread de préparation.
Le nouveau thread est basculé, ce qui entraîne le basculement d’un ancien thread.
Le nouveau thread est à nouveau mis hors file d’attente.
Dans la figure 10 Diagramme précis de l’utilisation du processeur, le temps passe de gauche à droite. Les étiquettes de diagramme correspondent aux noms de colonnes dans le graphique Utilisation de l’UC (Précision). Les étiquettes des colonnes Timestamp s’affichent en haut du diagramme et les étiquettes des colonnes Durée d’intervalle s’affichent en bas du diagramme.
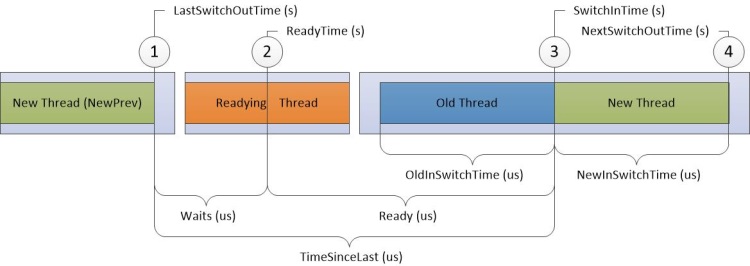
Figure 10 Diagramme précis de l’utilisation du processeur
Les sauts dans la chronologie de la figure 10 Diagramme précis de l’utilisation du processeur divisent la chronologie en régions qui peuvent se produire simultanément sur différents processeurs. Ces chronologies peuvent se chevaucher tant que l’ordre des événements numérotés n’est pas modifié. Par exemple, le thread de préparation peut s’exécuter sur processeur-2 en même temps qu’un nouveau thread est basculé, puis de nouveau sur processeur-1.
Les informations sont enregistrées pour les quatre cibles suivantes sur la chronologie :
Nouveau thread, qui est le thread qui a été basculé. Il s’agit du focus principal de cette ligne dans le graphique.
Thread NewPrev, qui fait référence à l’heure précédente dans laquelle le nouveau thread a été basculé.
Thread prêt, qui est le thread qui a préparé le nouveau thread à traiter.
Ancien thread, qui est le thread qui a été basculé lorsque le nouveau thread a été basculé.
Les données du tableau suivant sont liées à chaque thread cible :
| Colonne | Détails |
|---|---|
% d’utilisation du processeur |
Utilisation du processeur du nouveau thread après son basculement. Cette valeur est exprimée sous la forme d’un pourcentage de temps processeur total sur la période actuellement visible. |
Count |
Nombre de commutateurs de contexte représentés par la ligne. Il s’agit toujours de 1 pour les lignes individuelles. |
Count :Waits |
Nombre d’attentes représentées par la ligne. Il s’agit toujours de 1 pour les lignes individuelles, sauf lorsqu’un thread est basculé vers un état inactif ; dans ce cas, il est défini sur 0. |
UC |
Processeur sur lequel le commutateur de contexte s’est produit. |
Utilisation du processeur (ms) |
Utilisation du processeur du nouveau thread après le changement de contexte. Cela est égal à NewInSwitchTime, mais s’affiche en millisecondes. |
IdealCpu |
Uc idéale sélectionnée par le planificateur pour le nouveau thread. |
LastSwitchOutTime (s) |
Heure précédente où le nouveau thread a été mis hors service. |
NewInPri |
Priorité du nouveau thread qui est basculé. |
NewInSwitchTime(s) |
NextSwitchOutTime(s) moins SwitchInTime(s) |
NewOutPri |
Priorité du nouveau thread lorsqu’il bascule. |
NewPrevOutPri |
Priorité du nouveau thread lorsqu’il a été précédemment basculé. |
NewPrevState |
État du nouveau thread une fois qu’il a été précédemment désactivé. |
NewPrevWaitMode |
Mode d’attente du nouveau thread lorsqu’il a été précédemment basculé. |
NewPrevWaitReason |
Raison pour laquelle le nouveau thread a été mis hors service. |
NewPriDecr |
Boost de priorité qui affecte le thread. |
NewProcess |
Processus du nouveau thread. |
NewProcess Name |
Nom du processus du nouveau thread, y compris PID. |
NewQnt |
Inutilisé. |
NewState |
État du nouveau thread après son basculement. |
NewThreadId |
ID de thread du nouveau thread. |
NewThreadStack |
Pile du nouveau thread lorsqu’il est basculé. |
NewThreadStartFunction |
Fonction de début du nouveau thread. |
NewThreadStartModule |
Module de démarrage du nouveau thread. |
NewWaitMode |
Mode d’attente du nouveau thread. |
NewWaitReason |
Raison pour laquelle le nouveau thread a été mis hors service. |
NextSwitchOutTime(s) |
Heure à laquelle le nouveau thread a été mis hors service. |
OldInSwitchTime(s) |
Heure à laquelle l’ancien thread a été basculé avant son basculement. |
OldOutPri |
Priorité de l’ancien thread lorsqu’il a été mis hors service. |
OldProcess |
Processus propriétaire de l’ancien thread. |
OldProcess Name |
Nom du processus propriétaire de l’ancien thread, y compris piD. |
OldQnt |
Inutilisé. |
OldState |
État de l’ancien thread après son basculement. |
OldThreadId |
ID de thread de l’ancien thread. |
OldThreadStartFunction |
Fonction de début de l’ancien thread. |
OldThreadStartModule |
Module de démarrage de l’ancien thread. |
OldWaitMode |
Mode d’attente de l’ancien thread. |
OldWaitReason |
La raison pour laquelle l’ancien thread a été mis hors service. |
PrevCState |
État CState précédent du processeur. Si ce n’est pas 0 (Actif), le processeur était dans un état inactif avant que le nouveau thread ne soit basculé dans le contexte. |
Prêt(s) |
SwitchInTime(s) moinsReadyTime (s) |
Readying ThreadId |
ID de thread du thread de préparation. |
Préparation de ThreadStartFunction |
Fonction de début du thread de préparation. |
Readying ThreadStartModule |
Module de démarrage du thread de préparation. |
ReadyingProcess |
Processus propriétaire du thread de préparation. |
ReadyingProcess Name |
Nom du processus propriétaire du thread de préparation, y compris piD. |
ReadyThreadStack |
Pile du thread de préparation. |
ReadyTime (s) |
Heure de préparation du nouveau thread. |
SwitchInTime(s) |
Heure à laquelle le nouveau thread a été basculé. |
TimeSinceLast (s) |
SwitchInTime(s) moins LastSwitchOutTime (s) |
Attentes (s) |
ReadyTime (s) moins LastSwitchOutTime (s) |
Le profil par défaut utilise les présélections suivantes pour ce graphique :
Chronologie par processeur
Chronologie par processus, thread
Utilisation par priorité au début du commutateur de contexte
Utilisation par processeur
Utilisation par processus, thread
Chronologie par processeur
L’utilisation du processeur sur une chronologie par UC montre comment le travail est distribué entre les processeurs. La figure 11 Chronologie de l’utilisation du processeur (précise) par processeur affiche la chronologie sur un système de huit processeurs :
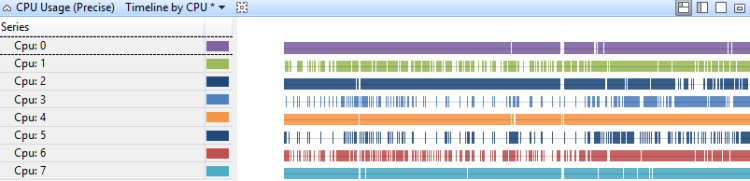
Figure 11 Chronologie de l’utilisation du processeur (précise) par processeur
Chronologie par processus, thread
L’utilisation du processeur sur une chronologie par processus, par thread, indique les processus qui ont des threads en cours d’exécution à certains moments. Figure 12 Utilisation (précision) Chronologie par processus, thread montre cette chronologie dans plusieurs processus :
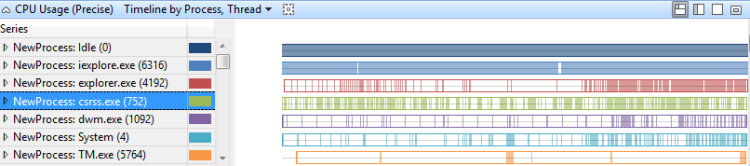
Figure 12 Chronologie d’utilisation (précise) par processus, thread
Utilisation par priorité au début du commutateur de contexte
Ce graphique identifie les rafales d’activité de thread de haute priorité à chaque niveau de priorité. La figure 13 Utilisation du processeur (précise) par priorité au début du commutateur de contexte montre la distribution des priorités :
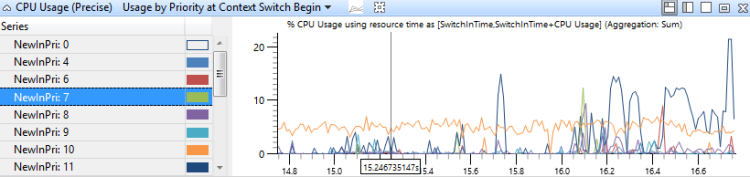
Figure 13 Utilisation du processeur (précise) utilisation par priorité au début du commutateur de contexte
Utilisation par processeur
Dans ce graphique, l’utilisation du processeur est regroupée et représentée par le processeur pour montrer comment le travail est distribué entre les processeurs. La figure 14 Utilisation de l’UC (précision) par processeur montre ce graphique pour un système qui a huit processeurs.
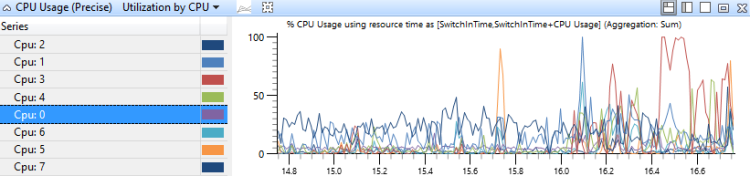
Figure 14 Utilisation de l’UC (précise) Utilisation par processeur
Utilisation par processus, thread
Dans ce graphique, l’utilisation du processeur est regroupée en premier par processus, puis par thread. Il montre l’utilisation relative des processus et des threads dans chaque processus Figure 15 Utilisation de l’UC (précision) utilisation par processus, thread montre cette distribution entre plusieurs processus :
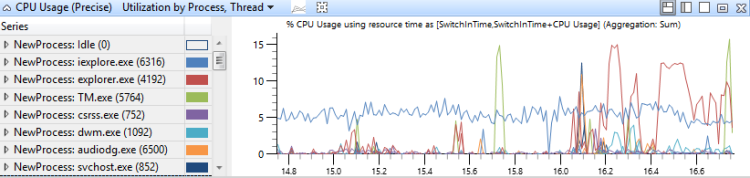
Figure 15 Utilisation de l’UC (précise) utilisation par processus, thread
Graphique DPC/ISR
Le graphique DPC/ISR est la source principale des informations DPC/ISR dans WPA. Chaque ligne du graphique représente un fragment, qui est une période pendant laquelle un DPC ou un ISR s’est exécuté sans interruption. Les données sont collectées au début et à la fin des fragments. Des données supplémentaires sont collectées lorsqu’un DPC/ISR est terminé. La figure 16 Diagramme DPC/ISR montre comment cela fonctionne :
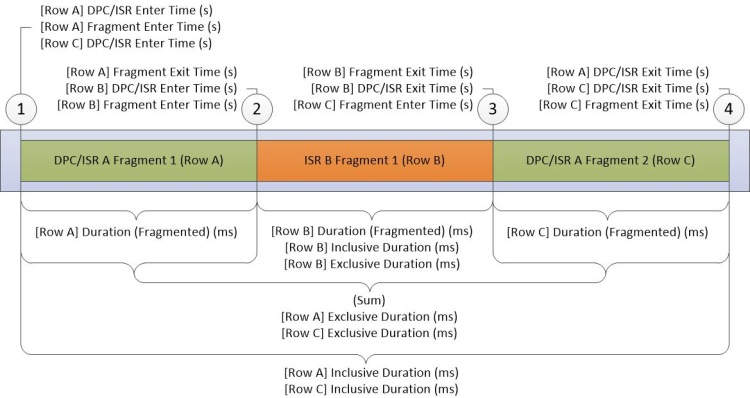
Figure 16 Diagramme DPC/ISR
La figure 16 Diagramme DPC/ISR décrit les données collectées pendant les activités suivantes :
DPC/ISR-A commence à s’exécuter.
Une interruption d’appareil ayant un niveau d’interruption supérieur à DPC/ISR-A entraîne l’interruption DPC/ISR A, ce qui met fin au premier fragment de DPC/ISR-A.
ISR-B se termine et termine ainsi le fragment d’ISR-B. DPC/ISR-A reprend l’exécution dans un deuxième fragment.
DPC/ISR-A se termine, terminant ainsi le deuxième fragment de DPC/ISR-A.
Une ligne pour chaque fragment s’affiche dans la table de données. Les fragments pour DPC/ISR-A partagent des informations identiques avec des colonnes non fragmentées.
Les colonnes du graphe DPC/ISR décrivent les informations au niveau fragment, ou les colonnes de niveau DPC/ISR. Chaque fragment dissimiule les données dans les colonnes au niveau des fragments et les données identiques dans les colonnes DPC/ISR.
| Colonne | Détails |
|---|---|
% durée (fragmentée) |
Durée (fragmentée) exprimée sous la forme d’un pourcentage de temps processeur total sur la période actuellement visible. |
% durée exclusive |
Durée exclusive exprimée sous la forme d’un pourcentage de temps processeur total sur la période actuellement visible. |
% durée inclusive |
Durée inclusive exprimée sous la forme d’un pourcentage de temps processeur total sur la période actuellement visible. |
Adresse |
Adresse mémoire de la fonction DPC ou ISR. |
Nombre (DPCs/ISR) |
Nombre de DPCs/ISR représentés par cette ligne. Il s’agit toujours de 1 pour les lignes qui représentent le fragment final d’un DPC/ISR ; sinon, ce nombre est égal à 0. |
Nombre (fragments) |
Nombre de fragments représentés par la ligne. Il s’agit toujours de 1 pour les lignes individuelles. |
UC |
Index du processeur logique sur lequel la DPC ou l’ISR s’est exécutée. |
DPC Type |
Pour DPC, le type de DPC, soit standard, soit minuteur. Cette valeur est vide pour un ISR. |
Durée d’entrée DPC/ISR |
Heure de début de la trace du DPC/ISR. |
Temps de sortie DPC/ISR (s) |
Heure du début de la trace à la fin de l’exécution du DPC/ISR. |
Durée (fragmentée) (ms) |
Heure de sortie du fragment (s) moins Heure d’entrée du fragment (s) en millisecondes. |
Durée exclusive (ms) |
Somme des durées fragmentées en ms. pour tous les fragments de ce DPC/ISR. |
Fragment |
Si le DPC/ISR de cette ligne a plusieurs fragments, cette valeur a la valeur True ; sinon, elle a la valeur False. |
Fragment |
Si ce n’était pas le seul fragment de ce DPC/ISR, cette valeur est True ; sinon, elle a la valeur False. |
Heure d’entrée de fragment (s) |
Heure à laquelle le fragment a commencé à s’exécuter. |
Heure de sortie du fragment (s) |
Heure à laquelle le fragment s’est arrêté. |
Fonction |
Fonction DPC ou ISR exécutée. |
Durée inclusive (ms) |
Heure de sortie DPC/ISR (s) moins DPC/ISR Enter Time (s) en millisecondes. |
MessageIndex |
Index d’interruption pour les interruptions signalées par les messages. |
Module |
Module qui contient la fonction DPC ou ISR. |
Valeur de retour |
Valeur de retour du DPC/ISR |
Type |
Type d’événement ; il s’agit de DPC ou d’interruption (ISR). |
Vector |
Valeur du vecteur d’interruption sur l’appareil. |
Le profil par défaut utilise les présélections suivantes pour ce graphique :
[DPC,ISR,DPC/ISR] Durée par processeur
[DPC,ISR,DPC/ISR] Durée par module, fonction
[DPC,ISR,DPC/ISR] Chronologie par module, fonction
[DPC,ISR,DPC/ISR] Durée par processeur
Les événements DPC/ISR sont agrégés par le processeur sur lequel ils ont été exécutés et triés par durée. Ce graphique montre l’allocation de l’activité DPC entre les processeurs. La figure 17 Durée DPC/ISR par processeur montre ce graphique pour un système qui a huit processeurs.
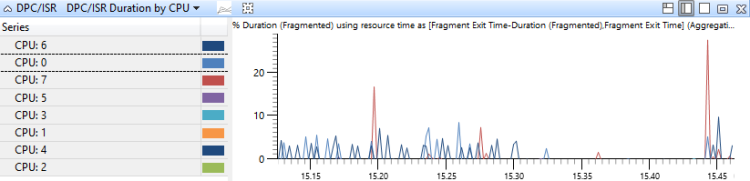
Figure 17 Durée DPC/ISR par processeur
[DPC,ISR,DPC/ISR] Durée par module, fonction
Les événements DPC/ISR sont agrégés dans ce graphique par le module et la fonction des routines DPC/ISR, et sont triés par durée. Cela montre quelles routines DPC/ISR ont consommé la plupart du temps la figure 18 DPC/ISR Duration by Module, Function montre une période de temps qui entraîne une activité DPC/ISR dans deux modules :
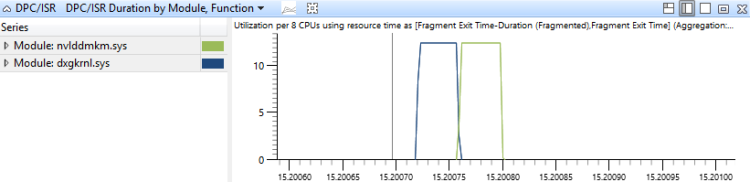
Figure 18 Durée DPC/ISR par module, Fonction
[DPC,ISR,DPC/ISR] Chronologie par module, fonction
Les événements DPC/ISR sont agrégés dans ce graphique par le module et la fonction des routines DPC/ISR. Elles sont représentées sous forme de chronologie. Ce graphique fournit une vue détaillée de la période pendant laquelle les DPCs/ISR s’exécutent. Ce graphique peut également montrer comment un seul DPC/ISR peut être fragmenté. Figure 19 Chronologie DPC/ISR par module, la fonction montre une chronologie de l’activité dans trois modules :

Figure 19 Chronologie DPC/ISR par module, fonction
Arborescences de pile
Les arborescences de pile sont affichées dans l’utilisation du processeur (échantillonné), l’utilisation du processeur (précise) et les tables DPC/ISR dans WPA, ainsi que dans les problèmes signalés dans les rapports d’évaluation. Les arborescences de pile décrivent les piles d’appels associées à plusieurs événements sur une période donnée. Chaque nœud de l’arborescence représente un segment de pile partagé par un sous-ensemble des événements. L’arborescence est construite à partir des piles individuelles et est illustrée dans la figure 20 Piles à partir de trois événements :

Figure 20 Piles de trois événements
La figure 21 Segments communs identifiés montre comment les séquences courantes sont identifiées pour ce graphique :

Figure 21 Segments communs identifiés
La figure 22 Arborescence générée à partir de piles montre comment les segments courants sont combinés pour former les nœuds d’une arborescence :
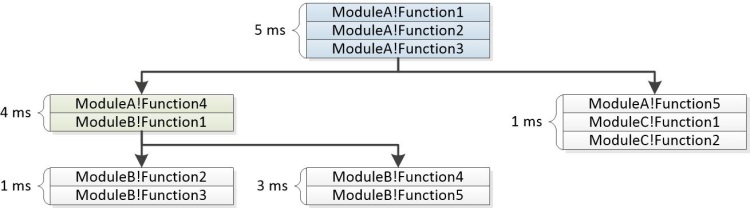
Figure 22 Arborescence générée à partir de piles
La colonne Stacks de l’interface utilisateur WPA contient un expandeur pour chaque nœud non feuille. Dans les problèmes signalés par l’évaluation, l’arborescence s’affiche avec les pondérations d’agrégation. Certaines branches peuvent être supprimées du graphique si leurs poids ne répondent pas à un seuil spécifié. L’exemple de pile ci-dessous montre comment les événements représentés ci-dessus sont affichés dans le cadre d’un problème signalé par l’évaluation.
5ms ModuleA!Function1
5ms ModuleA!Function2
5ms ModuleA!Function3
|
4ms |-ModuleA!Function4
4ms | ModuleB!Function1
| |
1ms | |-ModuleB-Function2
1ms | | ModuleB-Function3
| |
3ms | |-ModuleB!Function3
3ms | ModuleB!Function4
|
1ms |-ModuleA!Function5
1ms ModuleC!Function1
1ms ModuleC!Function2
Le <itself> nœud d’une pile représente l’heure à laquelle une fonction elle-même se trouve en haut de la pile. Le <itself> nœud n’inclut pas le temps passé dans les fonctions appelées par la fonction parente. Cette durée est appelée temps exclusif passé dans la fonction.
Par exemple, Function1 appelle Function2. Function2 a passé 2 ms dans une boucle nécessitant beaucoup d’UC et a appelé une autre fonction qui s’est exécutée pour 4 ms. Cela peut être représenté par la pile suivante :
6ms ModuleA!Function1
|
2ms |-<itself>
4ms |-ModuleA!Function2
4ms ModuleB!Function3
4ms ModuleB-Function4
Techniques
Cette section décrit une approche standard de l’analyse des performances. Il fournit des techniques que vous pouvez utiliser pour examiner les problèmes courants de performances liés au processeur.
L’analyse des performances est un processus en quatre étapes :
Définissez le scénario et le problème.
Identifiez les composants impliqués et l’intervalle de temps approprié.
Créez un modèle de ce qui aurait dû se produire.
Utilisez le modèle pour identifier les problèmes et examiner les causes racines.
Définir le scénario et le problème
La première étape de l’analyse des performances consiste à définir clairement le scénario et le problème. De nombreux problèmes de performances affectent les scénarios mesurés par les métriques d’évaluation. Par exemple :
Scénario 1 : une ressource physique n’est pas entièrement utilisée. Par exemple, un serveur ne peut pas utiliser entièrement une connexion réseau, car il ne peut pas chiffrer les paquets suffisamment rapidement.
Scénario 2 : Une ressource physique est utilisée plus qu’elle ne le doit. Par exemple, un système utilise des ressources processeur importantes pendant une période d’inactivité qui utilise l’alimentation de la batterie.
Scénario 3 : Les activités ne sont pas terminées à un taux requis. Par exemple, les images sont supprimées pendant la lecture vidéo, car les images ne sont pas décodées assez rapidement.
Scénario 4 : Une activité a été retardée. Par exemple, l’utilisateur a lancé Internet Explorer, mais il a fallu plus de temps que prévu pour ouvrir un onglet.
Les scénarios 3 et 4 liés aux ressources processeur sont abordés dans ce guide. Les scénarios 1 et 2 ne sont pas couverts. Pour analyser ces problèmes, vous pouvez commencer par une observation ambiguë telle que « il est trop lent » et poser des questions supplémentaires pour identifier le scénario et le problème exact.
Identifier les composants et la période
Une fois le scénario et le problème identifiés, vous pouvez identifier les composants impliqués et la période d’intérêt. Les composants incluent des ressources matérielles, des processus et des threads.
Vous pouvez souvent trouver l’intervalle de temps d’intérêt en identifiant l’activité associée dans le guide d’analyse. Une activité est un intervalle entre un événement de démarrage et un événement d’arrêt que vous pouvez sélectionner et effectuer un zoom avant, dans WPA. Si une activité n’est pas définie, vous pouvez trouver l’intervalle de temps en recherchant des événements génériques spécifiques associés au scénario, ou en recherchant des modifications dans l’utilisation des ressources qui peuvent marquer le début et la fin d’un scénario. Par exemple, si le processeur était inactif pendant deux secondes, puis entièrement utilisé pendant quatre secondes, puis inactif pendant deux secondes, les quatre secondes d’utilisation complète peuvent être la zone d’intérêt d’une trace qui capture la lecture vidéo.
Créer un modèle
Pour comprendre les causes racines d’un problème, vous devez avoir un modèle de ce qui doit se produire. Le modèle commence par le problème ou tout objectif associé pour la métrique ; par exemple, « Cette opération doit être terminée en moins de 5 secondes ».
Un modèle plus complet contient des informations sur la façon dont les composants doivent effectuer. Par exemple, quelle communication est attendue entre les composants ? Quelle est l’utilisation des ressources classique ? Combien de temps les opérations prennent-elles généralement ?
Vous trouverez souvent des informations sur le modèle dans le guide d’analyse de l’évaluation. Si cette ressource n’est pas disponible, vous pouvez produire une trace à partir d’un matériel et d’un logiciel similaires qui ne présentent pas le problème de performances, pour créer un modèle.
Utiliser le modèle pour identifier les problèmes, puis examiner les causes racines
Une fois que vous avez un modèle, vous pouvez comparer une trace au modèle pour identifier les problèmes. Par exemple, un modèle pour une activité particulière appelée Suspend Devices peut suggérer que l’activité entière doit se terminer en trois secondes, tandis que chaque instance d’une sous-activité appelée Suspend <Device Name> ne doit pas prendre plus de 100 ms. Si deux instances de la sous-activité suspendent <le nom> de l’appareil prennent chacune 800 ms, vous devez examiner ces instances.
Chaque écart du modèle peut être analysé pour trouver une cause racine. Vous devez examiner l’état des threads impliqués et rechercher les causes racines courantes. Quelques principales causes racines liées au processeur, pour les activités qui ne se terminent pas à un débit requis ou sont retardées, sont décrites ici :
Utilisation directe du processeur : les threads appropriés ont reçu des ressources processeur complètes, mais le programme requis n’a pas été exécuté assez rapidement. Cela peut être dû à un dysfonctionnement d’un programme ou à un matériel lent.
Interférence de thread : un thread n’a pas obtenu suffisamment de temps d’exécution, car d’autres threads s’exécutaient à la place. Dans ce cas, le thread est considéré comme affamé ou préempté.
Interférence DPC/ISR : les threads n’ont pas obtenu suffisamment de temps d’exécution, car les processeurs étaient occupés à traiter les PROCESSEURs ou les ISR.
Dans de nombreux cas, l’une de ces causes racines n’affecte pas notablement le thread et le thread passe la plupart du temps dans un état d’attente. Dans ce cas, vous devez identifier et examiner l’événement pour lequel le thread attend. Ce type d’investigation récursif est appelé analyse d’attente, et commence par identifier le chemin critique.
Technique avancée : Analyse d’attente et chemin critique
Une activité est un réseau d’opérations, certains séquentiels et certains parallèles, qui circulent d’un événement de début à un événement de fin. Toute paire d’événements de début/fin dans une trace peut être vue comme une activité. Le chemin le plus long via ce réseau d’opérations est appelé chemin critique. La réduction de la durée de toute opération sur le chemin critique réduit directement la durée de l’activité globale, bien qu’elle puisse également changer le chemin critique.
La figure 23 Opérations d’activité montre l’activité de trois threads. Thread-1 envoie l’événement de démarrage de l’activité, puis attend que Thread-2 et Thread-3 terminent leurs tâches. Thread-2 termine sa tâche en premier, suivie de Thread-3. Lorsque les deux threads ont terminé leurs tâches, thread-1 est prêt et termine l’événement d’activité.
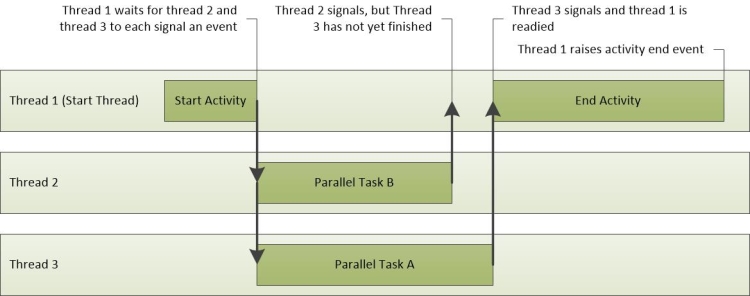
Figure 23 Opérations d’activité
Dans ce scénario, le chemin critique inclut des parties de Thread-3 et Thread-1. Celles-ci sont tracées dans la figure 24 Chemin critique. Étant donné que thread-2 n’est pas sur le chemin critique, le temps nécessaire pour terminer sa tâche n’affecte pas le temps d’activité global.
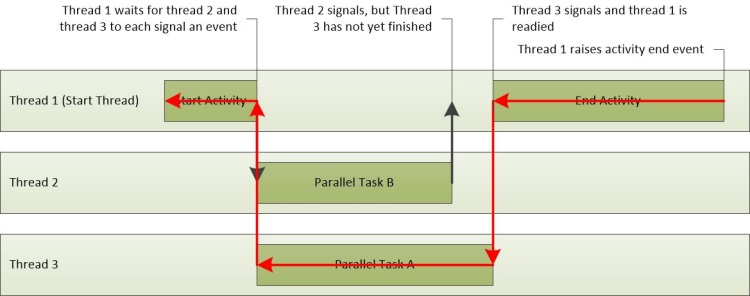
Figure 24 Chemin critique
Le chemin critique est une réponse littérale de bas niveau à la question de la raison pour laquelle une activité a pris autant de temps que cela. Une fois que les segments clés du chemin critique sont connus, ils peuvent être analysés pour trouver les problèmes qui contribuent au retard global.
Approche générale de la recherche du chemin critique
La première étape de recherche du chemin critique consiste à passer en revue le modèle de scénario pour comprendre l’objectif et l’implémentation de l’activité.
Comprendre une activité peut aider à identifier des opérations, des processus et des threads spécifiques qui peuvent se trouver sur le chemin critique. Par exemple, un retard dans l’activité Init de l’Explorateur De reprise de démarrage rapide peut être dû aux applications RunOnce et au processus d’initialisation de l’Explorateur, qui nécessitent une quantité importante d’E/S.
Après avoir examiné le modèle de scénario, vérifiez si l’évaluation a signalé des problèmes pour l’activité affectée. Plusieurs fois, une approximation du chemin critique est incluse dans les problèmes de retard signalés par l’évaluation. Le chemin critique s’affiche sous la forme d’une séquence d’attentes et d’actions prêtes. Il peut être lu à partir du début à la fin sous la forme d’une séquence d’événements, avec le segment principal retardé du chemin critique au milieu de la liste. La dernière entrée de la liste est l’action qui a préparé le thread qui a terminé l’activité.
Si vous devez rechercher manuellement le chemin critique, nous vous recommandons d’identifier le processus et le thread qui a terminé l’activité et de travailler en arrière à partir de l’instant où l’activité s’est terminée. Vous pouvez identifier le processus et le thread qui a démarré une activité, ainsi que le processus et le thread qui ont terminé une activité, via le graphique Activités dans WPA.
Le graphique Activités s’affiche lorsque la trace est chargée via un fichier XML de résultats d’évaluation. Pour identifier le processus et le thread associé à une activité particulière, développez le graphique sur l’activité d’intérêt, puis basculez l’affichage vers Graph+Table. Définissez le mode graphique sur Table. Les colonnes Start Process, Start Thread Id, End Process et End Thread Id s’affichent pour chaque activité du tableau.
Une fois que vous connaissez le processus de début et de fin, le thread et l’implémentation de l’activité, le chemin critique peut être suivi vers l’arrière. Commencez par analyser le thread qui a terminé l’activité pour déterminer comment ce thread a passé la plupart du temps : en cours d’exécution, prêt ou en attente.
Le temps d’exécution significatif indique que l’utilisation directe du processeur peut avoir contribué à la durée du chemin critique. Le temps passé en mode prêt indique que d’autres threads contribuent à la durée du chemin critique en empêchant l’exécution d’un thread sur le chemin critique. Le temps passé à attendre des points d’E/S, des minuteurs ou d’autres threads et processus sur le chemin critique pour lequel le thread actuel attendait.
Chaque thread qui a préparé le thread actuel est probablement un autre lien dans le chemin critique et peut également être analysé jusqu’à ce que la durée du chemin critique soit prise en compte.
Procédure : recherche du chemin critique dans WPA
La procédure suivante suppose que vous avez identifié une activité dans le graphique Activités pour laquelle vous souhaitez trouver le chemin critique.
Vous pouvez identifier le processus qui a terminé l’activité en pointant sur l’activité dans le graphique Activités .
Ajoutez le graphique Utilisation de l’UC (Précis). Effectuez un zoom sur l’activité affectée et appliquez l’utilisation par processus, la présélection de thread .
Cliquez avec le bouton droit sur les en-têtes de colonne et rendez les colonnes ReadyThreadStack et Utilisation du processeur (ms) visibles. Supprimez les colonnes Ready (us) [Max] et Waits (us) [Max].
Développez le processus cible et triez-le respectivement par utilisation de l’UC (ms), Ready (us) [Sum] et Waits (us) [Sum].
Recherchez les NewThreadIds dans le processus dont le temps est le plus élevé dans l’état En cours d’exécution, Prêt ou En attente.
Les threads qui passent beaucoup de temps dans les états En cours d’exécution ou Prêt peuvent représenter l’utilisation directe du processeur sur le chemin critique. Notez que leurs ID de thread.Threads qui passent beaucoup de temps dans l’état d’attente peuvent être en attente sur les E/S, un minuteur ou sur un autre thread dans le chemin critique.
Pour découvrir ce que les threads attendaient, développez le groupe NewThreadId pour afficher ReadyThreadStack.
Développez [Racine].
Les piles commençant par KiDispatchInterrupt ne sont pas liées à un autre thread. Pour déterminer ce que le thread attendait dans ces piles, développez KiDispatchInterrupt et affichez les fonctions sur la pile enfant. IopfCompleteRequest indique que le thread prêt attendait les E/S. KiTimerExpiration indique que le thread prêt attendait un minuteur.
Développez les piles qui ne commencent pas par KiDispatchInterrupt jusqu’à ce que vous voyiez un ReadyingProcess et un ReadyingThread. Si le processus est déjà développé, développez NewThreadId qui correspond à ReadyingThread. Répétez cette étape jusqu’à ce que vous trouviez un thread en cours d’exécution, prêt, en attente d’une autre raison ou en attendant un autre processus. Si le thread attend un autre processus, répétez cette procédure à l’aide de ce processus.
Exemple
Cet exemple présente un délai dans l’activité Init de l’Explorateur De reprise de démarrage rapide. Une recherche dans le volet Problèmes indique que sept problèmes de type retard sont signalés pour cette activité. Chacun de ces problèmes peut être examiné en tant que segment du chemin critique. Les segments clés suivants sont identifiés :
Le thread 3872 du processus TestBootStrapper.exe (3024) est préempté pendant 2,1 secondes.
Le thread 3872 du processus TestBootStrapper.exe (3024) utilise 1 seconde de temps processeur.
Le thread 3872 du processus TestBootStrapper.exe (3024) vide une ruche de Registre pendant 544 millisecondes.
Le thread 3872 du processus TestBootStrapper.exe (3024) veille pendant 513 millisecondes.
Threads 4052 et 4036 de Explorer.exe lecture à partir du disque, ce qui entraîne un délai de 461 millisecondes.
Le thread 3872 du processus TestBootStrapper.exe (3024) est affamé pendant 187 millisecondes.
Le thread 3872 du processus TestBootStrapper.exe écrit 3,5 Mo sur disque, ce qui entraîne un délai de 178 millisecondes.
Les problèmes montrent que cette activité a été retardée de 5,2 secondes. Ces retards contribuent à une grande proportion des activités dans l’ensemble de 6,3 secondes. L’application TestBootStrapper.exe est principalement responsable du délai, principalement parce qu’elle a préempté d’autres tâches de traitement.
Examiner les problèmes dans le chemin critique
Effectuez un zoom sur la région affectée et ajoutez les colonnes ReadyThreadStack et Utilisation du processeur (ms).
Dans ce cas, Explorer.exe est le processus qui termine l’activité. Développez le processus explorer.exe et triez-le respectivement par utilisation de l’UC (ms), Ready (us) [Sum] et Waits (us) [Sum], comme illustré dans les illustrations suivantes :

Figure 25 Activité par utilisation du processeur (ms)

Figure 26 Activité par prêt (nous)

Figure 27 Activité par attentes (nous)
Le tri par la colonne Utilisation du processeur (ms) affiche une ligne enfant supérieure de 299 millisecondes. Le tri par la colonne Ready (us) [Somme] affiche une ligne enfant supérieure de 46 ms. Le tri par la colonne Waits (us) [Somme] affiche une ligne enfant supérieure de 5749 millisecondes et une deuxième ligne de 4902 millisecondes. Étant donné que ces lignes contribuent considérablement au retard, vous devez les examiner plus en détail.
Développez les piles pour afficher les threads de préparation, comme illustré dans les illustrations suivantes :
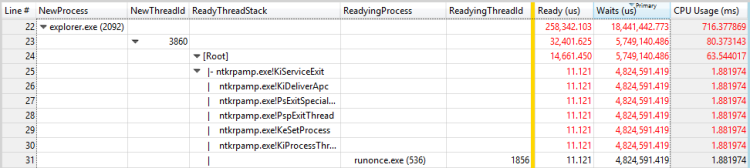
Figure 28 Processus de préparation et thread de préparation pour un thread
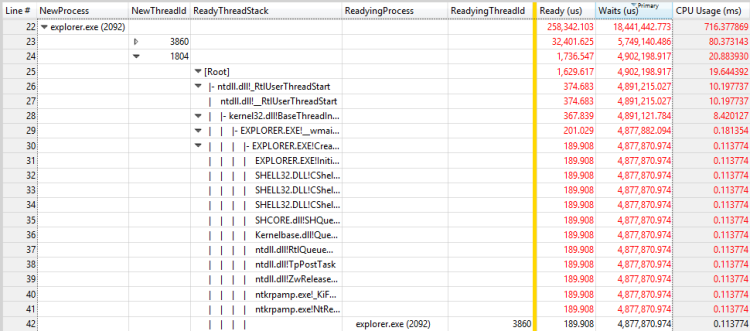
Figure 29 Processus de préparation et thread de préparation pour un autre thread
Dans cet exemple, le premier thread passe la plupart du temps en attente de la sortie du processus de RunOnce.exe. Vous devez examiner pourquoi le processus de RunOnce.exe prend tellement de temps. Le deuxième thread attend le premier thread et est probablement un lien insignifiant dans la même chaîne d’attente.
Répétez les étapes de cette procédure pour RunOnce.exe. La colonne principale de contribution est Waits (nous) et elle a quatre contributeurs possibles.
Développez chaque contributeur pour voir que les trois premiers contributeurs attendent chacun le quatrième contributeur. Cette situation rend les trois premiers contributeurs insignifiants à la chaîne d’attente. Le quatrième contributeur attend un autre processus, TestBootStrapper.exe.
Ce scénario est illustré dans la figure 30 Processus de préparation et thread de préparation d’un thread dans RunOnce.exe :
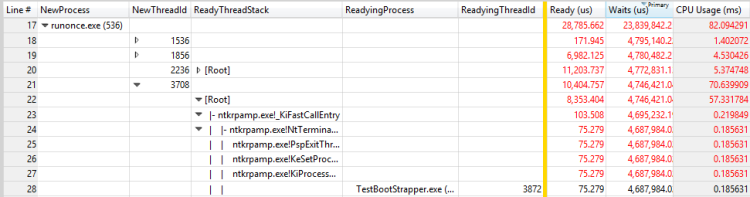
Figure 30 Processus de préparation et thread de préparation pour un thread dans RunOnce.exe
Répétez les étapes de cette procédure pour TestBootStrapper.exe. Les résultats sont présentés dans les trois figures suivantes :

Figure 31 Threads par utilisation du processeur (ms)

Figure 32 Threads by Ready (us)

Figure 33 Threads by Waits (us)
Le thread 3872 a passé environ 1 seconde en cours d’exécution, 2 secondes prêtes et 1,3 secondes en attente. Étant donné que ce thread est également le thread de préparation pour le thread 3872, les temps en cours d’exécution et prêts contribuent probablement au délai. L’évaluation signale les problèmes suivants dont les heures correspondent aux retards :
Le thread 3872 du processus TestBootStrapper.exe (3024) est préempté pour 2,1 secondes.
Le thread 3872 du processus TestBootStrapper.exe (3024) est affamé pendant 187 millisecondes.
Le thread 3872 du processus TestBootStrapper.exe (3024) utilise 1 seconde de temps processeur.
Pour rechercher d’autres problèmes de contribution, affichez l’événement pour lequel le thread 3872 attendait. Développez ReadyThreadStack pour afficher les contributeurs aux 1,3 secondes d’attente, comme illustré dans la figure 34 Contributeurs au temps d’attente :

Figure 34 Contributeurs au temps d’attente
KiRetireDpcList est généralement lié aux E/S et KiTimerExpiration est un minuteur. Vous pouvez voir comment l’E/S et le minuteur ont été lancés en supprimant ReadyThreadStack, puis en affichant NewThreadStack. Cette vue affiche trois fonctions connexes, comme illustré dans la figure 35 E/S et le minuteur sur NewThreadStack :

Figure 35 E/S et minuteur sur NewThreadStack
Cette vue révèle les détails suivants :
Le thread 3872 du processus TestBootStrapper.exe (3024) vide une ruche de Registre pendant 544 millisecondes.
Le thread 3872 du processus TestBootStrapper.exe (3024) veille pendant 513 millisecondes.
Le thread 3872 du processus TestBootStrapper.exe écrit 3,5 Mo sur disque, ce qui entraîne un délai de 178 millisecondes.
Lorsque vous avez commencé à examiner le chemin critique, vous avez analysé la cause d’attente la plus importante dans Explorer.exe et ignoré toutes les parties du chemin critique qui se sont produites après cette cause d’attente. Pour capturer cette section précédemment ignorée du chemin critique, vous devez examiner la chronologie. Ajoutez l’utilisation du processeur (précise) et appliquez la chronologie par processus, préréglage de thread .
Filtrez pour inclure uniquement les processus identifiés dans le cadre du chemin critique. Le graphique obtenu est illustré dans la figure 36 Chronologie du chemin critique :

Figure 36 Chronologie du chemin critique
La figure 36 Chronologie du chemin critique montre que Explorer.exe effectué plus de travail après qu’il a cessé d’attendre RunOnce.exe. Effectuez un zoom avant la période après la chaîne d’attente précédemment analysée et effectuez une autre analyse. Dans ce cas, l’analyse révèle un grand nombre de threads internes à Explorer.exe et aucune trace claire par le biais du chemin critique. Dans ce cas, une analyse supplémentaire n’est pas susceptible de produire des insights exploitables.
Utilisation directe du processeur
Les activités sont souvent retardées, car un thread sur le chemin critique utilise un temps processeur significatif. En utilisant le modèle d’état de thread, vous pouvez voir que ce problème est caractérisé par un thread sur le chemin critique qui passe une durée exceptionnelle dans l’état en cours d’exécution. Sur certains matériels, cette utilisation intensive du processeur peut contribuer aux retards.
Identification du problème
De nombreuses évaluations utilisent des heuristiques pour identifier les problèmes directs liés à l’utilisation du processeur. Une utilisation significative du processeur sur le chemin critique est signalée comme un problème sous la forme suivante :
L’utilisation du processeur par le processus P retarde l’activité affectée A pendant x secondes
Où P est le processus en cours d’exécution, A est l’activité, et x est la durée en secondes.
Si ces problèmes sont signalés pour une activité qui entraîne des retards, l’utilisation directe du processeur peut être la cause.
Examiner l’utilisation directe du processeur
Vous pouvez identifier manuellement le problème en recherchant des processeurs individuels qui entraînent une utilisation de 100 % du processeur dans le graphique Utilisation de l’UC (échantillonné).
Effectuez un zoom avant sur une zone d’intérêt dans le graphique, puis sélectionnez la présélection Utilisation par processus et thread .
Par défaut, le tableau affiche les lignes situées en haut qui ont l’utilisation agrégée la plus élevée du processeur. Ces threads s’affichent également en haut du graphique Utilisation du processeur (échantillonné).
Remarque Sur un système qui a plusieurs processeurs, un thread qui utilise 100 % d’un processeur unique semble consommer 100/(nombre de processeurs logiques). Sur ce type de système, seul le thread inactif virtuel (PID 0, TID 0) peut afficher une utilisation supérieure au processeur de 100/(nombre de processeurs logiques). Si les processus et les threads qui consomment le plus d’UC correspondent à tous les threads du chemin critique, l’utilisation directe de l’UC est probablement un facteur.
Exemple de problème d’utilisation directe de l’UC signalée par l’évaluation
L’utilisation du processeur par le processus de TestUM.exe (4024) retarde l’activité affectée, le processus d’arrêt de démarrage rapide TestIM.exe, pendant 2,1 secondes. Cet exemple est illustré dans la figure 37 Thread 3208 :
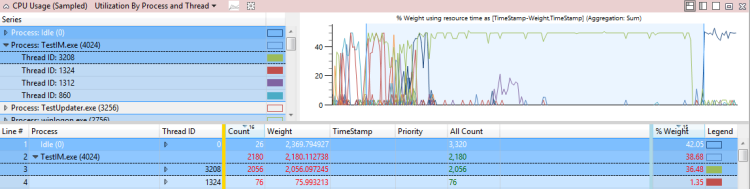
Figure 37 Thread 3208
Examen
Après avoir découvert que l’utilisation directe du processeur contribue à un délai sur le chemin critique, vous devez identifier les modules et fonctions spécifiques qui contribuent au délai.
Technique : passer en revue un problème d’utilisation directe de l’UC signalé par l’évaluation
Vous pouvez développer un problème d’utilisation directe de l’UC signalée par l’évaluation pour afficher le chemin critique affecté par l’utilisation directe du processeur. Si vous développez le nœud associé à l’utilisation du processeur, les piles associées à l’utilisation du processeur et les modules associés s’affichent. Cette vue est illustrée dans la figure 38 Segment d’utilisation du processeur développé :
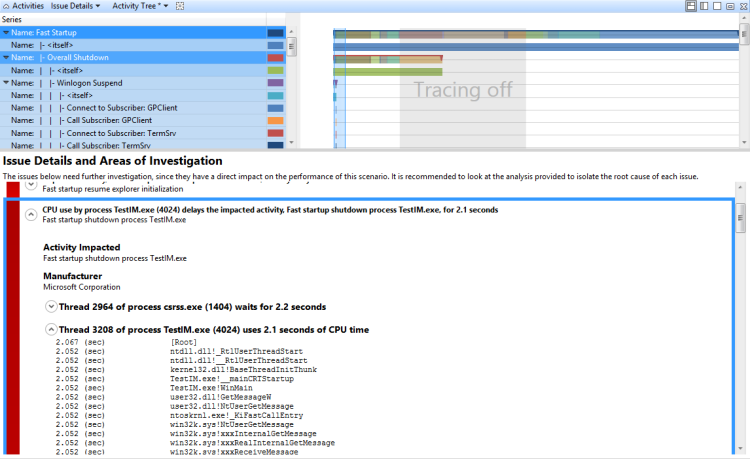
Figure 38 Segment d’utilisation du processeur développé
Technique : Explorer manuellement les piles d’un problème d’utilisation directe du processeur
Si l’évaluation n’a pas signaler de problème ou si vous avez besoin d’une vérification supplémentaire, vous pouvez utiliser le graphique Utilisation du processeur (échantillonné) pour collecter manuellement des informations sur les modules et les fonctions impliqués dans un problème d’utilisation du processeur. Pour ce faire, vous devez effectuer un zoom avant sur la zone d’intérêt et afficher les piles triées par utilisation du processeur.
Explorer manuellement les piles d’un problème d’utilisation directe du processeur
Dans le menu Trace, cliquez sur Charger des symboles.
Zoomez sur la chronologie pour afficher uniquement la partie du chemin critique affecté par le problème de processeur.
Appliquez l’utilisation par processus et la présélection de thread .
Ajoutez la colonne Stack à l’affichage, puis faites glisser cette colonne à droite de l’ID de thread (à gauche de la barre).
Développez le processus et le thread pour afficher les arborescences de pile.
Les lignes de la pile sont triées dans l’ordre décroissant par % poids de l’utilisation du processeur. Cela met les piles les plus intéressantes en haut. Lorsque vous développez les piles, regardez la colonne % Poids pour vous assurer que votre focus reste sur les lignes qui ont la plus grande utilisation.
Pour extraire une copie de la pile, sélectionnez toutes les lignes, cliquez avec le bouton droit, puis cliquez sur Copier la sélection.
Résolution
Vous pouvez appliquer des solutions aux niveaux de configuration et de composant pour résoudre une utilisation élevée du processeur.
L’utilisation directe du processeur a un impact plus élevé sur les ordinateurs qui ont des processeurs inférieurs. Dans ces cas, vous pouvez ajouter davantage de puissance de traitement à l’ordinateur. Vous pouvez également supprimer les modules problématiques du chemin critique ou du système. Si vous pouvez modifier les composants, envisagez d’effectuer un effort de refonte pour obtenir l’un des résultats suivants :
Supprimer le code nécessitant beaucoup d’UC du chemin critique
Utiliser des algorithmes plus efficaces sur le processeur
Différer ou mettre en cache le travail
Interférence de thread
L’utilisation du processeur par les threads qui ne se trouvent pas sur le chemin critique (et qui peuvent ne pas être liés à l’activité) peut entraîner le retard des threads qui se trouvent sur le chemin critique. Le modèle d’état de thread montre que ce problème est caractérisé par des threads sur le chemin critique qui passent un temps inhabituel dans l’état Prêt.
Identification du problème
De nombreuses évaluations utilisent des heuristiques pour identifier les problèmes liés aux interférences. Celles-ci sont signalées sous l’une des deux formes suivantes :
Le processus P est affamé. La famine provoque un retard à l’activité affectée A de x ms.
Le processus P est préempté. La préemption entraîne un délai pour l’activité affectée A de x ms.
Où P est le processus, A est l’activité, et x est le temps en ms.
Le premier formulaire reflète les interférences des threads au même niveau de priorité que le thread sur le chemin critique. Le deuxième formulaire reflète les interférences des threads qui se trouvent à un niveau de priorité supérieur à celui du thread sur le chemin critique.
Si ces types de problèmes sont signalés pour une activité retardée, l’interférence de thread peut être la cause. Vous pouvez utiliser le graphique Utilisation du processeur (Précision) pour identifier manuellement le problème.
Identifier les problèmes d’interférence de thread
Effectuez un zoom sur l’intervalle et appliquez l’utilisation par préréglage du processeur . Une utilisation de 100 % sur toutes les UC indique un problème d’interférence.
Appliquez l’utilisation par processus, la présélection de threads et le tri par la première colonne Ready (us). (Il s’agit de la colonne qui inclut le Agrégation de somme .)
Développez le processus de l’activité affectée et examinez le temps prêt pour les threads sur le chemin critique. Cette valeur est la durée maximale pendant laquelle le délai peut être réduit en résolvant tout problème d’interférence de thread. Une valeur avec une magnitude significative par rapport au délai examiné indique qu’un problème d’interférence de thread existe.
La figure 39 Utilisation du processeur est proche de 100 % et la figure 40 Problème d’interférence de thread représente ce scénario :

La figure 39 Utilisation du processeur est proche de 100 %
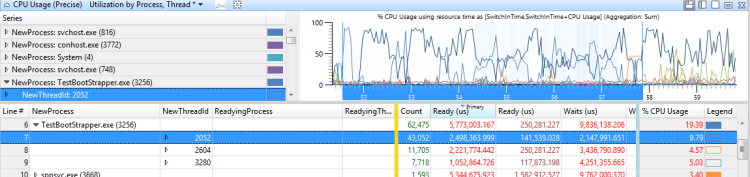
Figure 40 Problème d’interférence de thread
Examen
Une fois le problème identifié, vous devez déterminer pourquoi le thread affecté a passé tant de temps dans l’état Prêt.
Technique : déterminer pourquoi un thread a passé du temps dans l’état prêt
Vous pouvez utiliser le graphique Utilisation de l’UC (Précision) pour déterminer pourquoi un thread a passé du temps dans l’état Prêt. Vous devez d’abord déterminer si le thread est limité à certains processeurs. Bien que vous ne puissiez pas obtenir directement ces informations, vous pouvez examiner l’historique d’utilisation du processeur d’un thread pendant des périodes d’utilisation élevée du processeur. Il s’agit de la période où les threads ont tendance à basculer fréquemment entre les processeurs.
Déterminer les restrictions du processeur d’un thread
Effectuez un zoom sur la région affectée.
Ajoutez le graphique Utilisation de l’UC (Précis) et appliquez l’utilisation par processus, préréglage de thread .
Utilisez la boîte de dialogue Avancé pour ajouter une colonne uc qui a un mode d’agrégation De nombre unique à droite de NewThreadId.
Filtrez le graphique pour afficher uniquement les threads qui vous intéressent.
La valeur de la colonne Processeur reflète le nombre de processeurs sur lesquels le thread s’est exécuté pendant l’intervalle de temps actuel. Pendant les périodes d’utilisation du processeur de 100 %, ce nombre correspond approximativement au nombre de processeurs sur lesquels ce thread est autorisé à s’exécuter. Si la valeur est inférieure au nombre de processeurs disponibles, le thread est probablement limité à certains processeurs.
La figure 41 Threads restreints fournit un exemple de ce graphique :
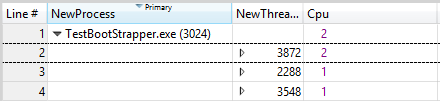
Figure 41 Threads restreints
Une fois que vous connaissez les restrictions de processeur d’un thread, vous pouvez déterminer ce qui a été préempté ou affamé. Pour ce faire, vous devez identifier les intervalles que le thread a passé dans l’état Prêt, puis examiner les autres threads ou processus en cours d’exécution pendant ces intervalles.
Déterminer les éléments préemptés ou affamés du thread
Construisez un graphique qui indique quand le thread était dans l’état Prêt et appliquez l’utilisation par processus, préréglage de thread .
Ouvrez l’Éditeur de vue, cliquez sur Avancé, puis sélectionnez l’onglet Configuration du graphique.
Définissez l’heure de début sur ReadyTime (s) et définissez la durée sur Prêt (nous) comme indiqué dans la figure 42 Colonnes de temps prêt. Cliquez sur OK.

Figure 42 Colonnes de temps prêt
Dans l’Éditeur de vue, remplacez la colonne Utilisation du processeur (%) par la colonne Ready (us) [Somme].
Sélectionnez le thread d’intérêt pour produire un graphique similaire à la figure 43 Ready Time Graph :

Figure 43 Graphique de temps prêt
Dans ce cas, le thread a passé beaucoup de temps dans l’état Prêt. Pour déterminer sa priorité classique, ajoutez une agrégation moyenne à la colonne NewInPri .
Dans ce cas, la priorité moyenne du thread est exactement 8. Ce nombre indique qu’il s’agit probablement d’un thread d’arrière-plan qui ne reçoit jamais d’élévations de priorité.
Une fois que la priorité moyenne est connue, examinez l’activité uc pour les processeurs sur lesquels le thread est autorisé à s’exécuter.
Dans ce cas, le thread a été déterminé à avoir une affinité pour le processeur 1 uniquement.
Ajoutez un autre graphique Utilisation de l’UC (Précision) et appliquez l’utilisation par préréglage du processeur . Sélectionnez les PROCESSEURs appropriés.
Ouvrez l’affichage Avancé et ajoutez un filtre pour la priorité que vous avez trouvée précédemment pour filtrer ce thread. Ce scénario est illustré dans la figure 44 Filtre de thread :
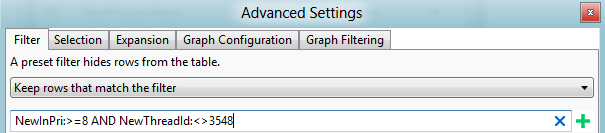
Figure 44 Filtre de thread
Dans la figure 45 Utilisation du processeur, temps prêt et autre activité de thread, le graphique supérieur montre l’utilisation du processeur du thread 3548. Le graphique intermédiaire indique l’heure à laquelle le thread était prêt et le graphique inférieur affiche l’activité sur les processeurs sur lesquels le thread a été autorisé à s’exécuter (dans ce cas, Cpu1).
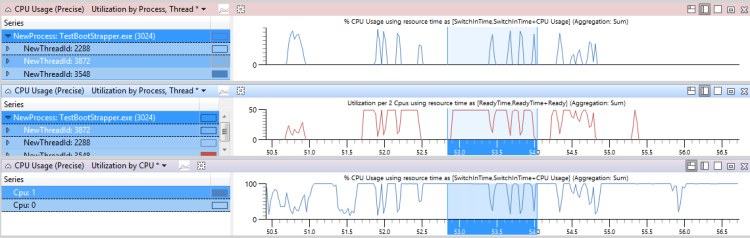
Figure 45 Utilisation du processeur, temps prêt et autres activités de thread
Effectuez un zoom sur une région où le thread était prêt, mais n’a pas exécuté, pendant la plupart du temps pendant cet intervalle.
Dans le graphique Utilisation du processeur, ajoutez NewInPri à gauche de la barre et examinez les résultats.
Les threads ou les processus qui ont des priorités qui sont égales à la priorité du thread cible indiquent l’heure pendant laquelle le thread a été affamé. Les threads ou processus ayant une priorité supérieure à la priorité du thread cible indiquent l’heure à laquelle le thread a été préempté. Vous pouvez calculer le temps total pendant lequel le thread a été préempté en ajoutant les heures de tous les threads et actions préemptifs.
La figure 46 Utilisation par priorité lorsque le thread cible était prêt montre que 730 ms de l’heure du thread ont été préemptées et que 300 ms de l’heure du thread étaient affamées. (Cette figure est zoomée sur un intervalle de 1192 ms.)
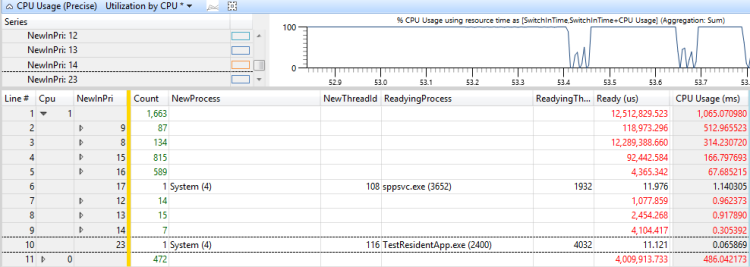
Figure 46 Utilisation par priorité lorsque le thread cible était prêt
Pour déterminer quels threads sont responsables de la préemption et de la faim de ce thread, ajoutez la colonne NewProcess à droite de la colonne NewInPri et passez en revue les niveaux de priorité auxquels les processus étaient en cours d’exécution. Dans ce cas, la préemption et la faim ont été principalement causées par un autre thread dans le même processus et par TestResidentApp.exe. Vous pouvez supposer que ces processus reçoivent des élévations de priorité périodiques au-dessus de leur priorité de base.
Résolution
Vous pouvez résoudre les problèmes de préemption ou de faim en modifiant la configuration ou les composants. Les recours suivants peuvent également vous être utile :
Supprimez les processus problématiques du système.
Ajustez la priorité de base des processus problématiques...
Modifiez l’heure à laquelle les processus problématiques s’exécutent ; par exemple, retardez leur heure de début lorsque l’ordinateur redémarre.
Si les composants problématiques peuvent être modifiés, remaniez-les pour qu’ils soient moins gourmands en ressources processeur ou pour s’exécuter à une priorité inférieure.
Interférence DPC/ISR
Lorsque le temps processeur excessif est consommé par l’exécution de contrôleurs de domaine et d’ISR, il se peut qu’il n’y ait pas suffisamment de temps processeur disponible pour exécuter des threads. Cette situation peut entraîner des retards similaires aux interférences de thread. Lorsque les threads doivent effectuer des opérations à un taux régulier de fréquence élevée, comme dans la lecture vidéo ou l’animation, l’interférence par les CONTRÔLEURs de domaine et les ISR peut entraîner des problèmes opérationnels.
Identification du problème
De nombreuses évaluations utilisent des heuristiques pour identifier les problèmes liés à DPC/ISR. L’activité DPC/ISR est identifiée comme suspecte lorsqu’elle est signalée comme un problème sous la forme suivante :
DPC D dépasse le seuil de m millisecondes x fois pendant P. Les n instances de cette DPC s’exécutent pour un total combiné de t millisecondes.
Où D est la DPC , m est le nombre de millisecondes qui définit le seuil, x correspond au nombre de fois où le DPC a dépassé le seuil, P est le processus actuel, n est le nombre d’instances exécutées par la DPC, et t’est le temps total en millisecondes que la DPC a exécutées sur le seuil.
Par exemple, le problème suivant est signalé par une évaluation :
DPC sdbus.sys ! SdbusWorkerDpc dépasse l’objectif de 3,0 millisecondes 153 fois pendant la durée de vie du moteur multimédia. Les 153 instances de cette exécution DPC pour un total combiné de 864 millisecondes
Si ce problème est signalé pour une activité qui présente des événements ou des retards problématiques, l’activité DPC/ISR peut être la cause.
Identifier manuellement les interférences DPC/ISR
Pour identifier manuellement les interférences DPC/ISR, ouvrez une trace dans WPA et identifiez les événements problématiques d’intérêt. Il s’agit d’événements génériques spécifiques à l’évaluation tels que Microsoft-Windows-Dwm-Core :SCHEDULE_GLITCH ou Microsoft-Windows-MediaEngine :DroppedFrame.
En regard du graphique des événements, ajoutez la durée DPC/ISR par graphique processeur . Si les pics dans la durée DPC/ISR par graphique processeur s’alignent sur les événements de problème, les DPC/ISR peuvent être un facteur à l’origine des problèmes.
Pour des données supplémentaires, effectuez un zoom sur la période qui se produit 100 ms avant l’affichage de plusieurs événements de problème. Si une activité DPC/ISR significative s’affiche sur un ou plusieurs processeurs de la région 100 ms avant que les événements de problème ne se produisent, vous pouvez conclure que les événements de problème ont été causés par l’activité DPC/IRS.
Pour déterminer si les interférences DPC/ISR provoquent des retards, effectuez un zoom sur une région qui affiche un thread en cours d’exécution. Notez le processeur ou les processeurs sur lesquels ce thread est en cours d’exécution.
Dans le graphique DPC/ISR, appliquez la durée DPC/ISR par préréglage du processeur et affichez l’activité DPC/ISR sur les processeurs pertinents dans cet intervalle de temps.
La figure 47 Événements de problème et activité DPC/ISR montre que le thread 864 de iexplore.exe est pertinent pour l’activité affectée. Le thread 864 est dans l’état d’exécution du processeur2 pour 10,65 % de l’intervalle de temps affiché. Toutefois, le graphique DPC/ISR montre que cpu2 a été occupé à exécuter DPC/ISR pendant 10 % de cette période.
Notez que la plupart des DPC/ISR n’ont pas un impact aussi élevé que celui indiqué dans cet exemple.
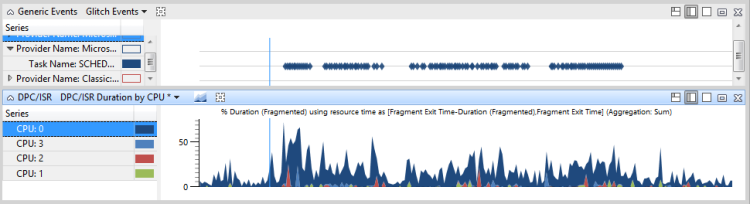
Figure 47 Événements de problème et activité DPC/ISR
Dans la figure 48 DPC/ISR non liée aux événements de problème, les DPC/ISR ne sont pas liés aux problèmes de performances :
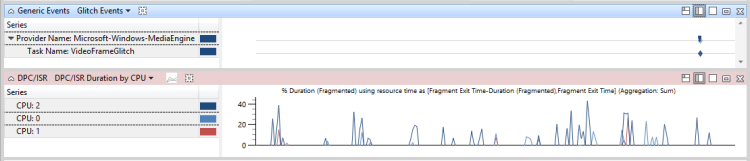
Figure 48 DPC/ISR non liée aux événements de problème
Dans la figure 49 Retard provoqué par l’interférence DPC/ISR, les DPC/ISR sont montrés pour provoquer des problèmes de performances :
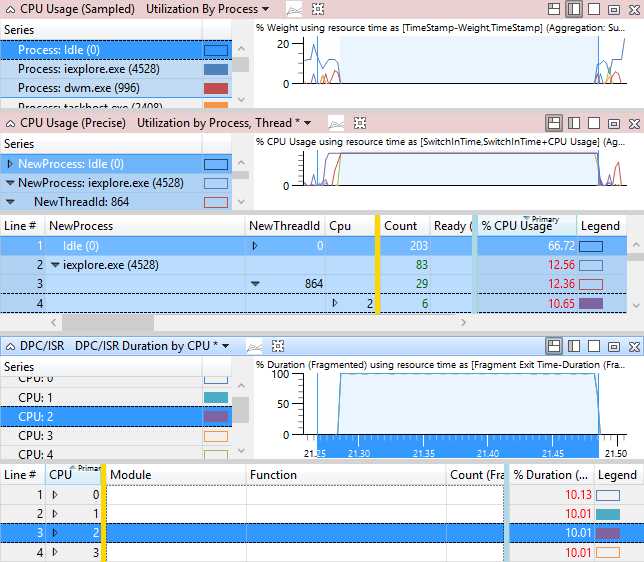
Figure 49 Retard causé par l’interférence DPC/ISR
Examen
Une fois que vous avez déterminé que les DPCs/ISR sont liés à des problèmes ou des retards, vous devez déterminer les FOURNISSEURS/ISR spécifiques qui sont impliqués et pourquoi ils se produisent fréquemment ou s’exécutent pendant une durée excessive.
Technique : examiner un problème DPC/ISR signalé par l’évaluation
Dans les problèmes DPC/ISR signalés par l’évaluation, vous pouvez développer le problème qui affiche les principaux processus préemptés par le DPC ou l’ISR. Développez la pile pour afficher l’activité DPC pour le processus qui est le plus lié à l’activité affectée, comme indiqué ci-dessous, développez la pile pour comprendre ce que faisait la DPC. La figure 50 Pile DPC développée montre la pile développée :
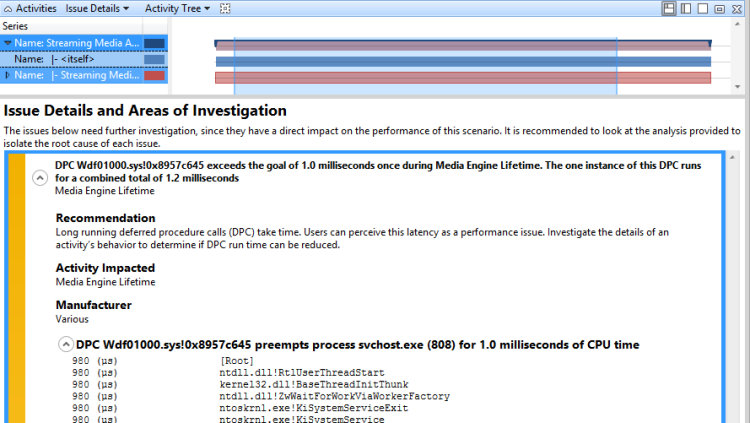
Figure 50 Pile DPC développée
Technique : Rechercher les DPCS/ISR de durée la plus élevée et passer en revue les piles
Si une évaluation ne signale pas le DPC/ISR comme un problème, vous pouvez utiliser les graphiques DPC/ISR et Utilisation de l’UC (échantillonné) pour obtenir des informations sur la pile pour les contrôleurs de domaine les plus pertinents. Nous vous recommandons de trouver un DPC/ISR intéressant, de noter son module et sa fonction, puis de trouver les exemples dans le graphique Utilisation du processeur (Échantillonné) pour obtenir des informations complètes sur la pile.
Rechercher les dpcs/ISR de durée la plus élevée et passer en revue les piles
Effectuez un zoom sur l’intervalle d’intérêt.
Dans le graphique DPC/ISR, sélectionnez la durée DPC/ISR prédéfinie par module, fonction.
Si des symboles sont chargés, les événements DPC/ISR sont triés par durée totale, puis divisés par module et fonction. Les lignes supérieures de la liste contiennent les événements DPC/ISR qui ont probablement provoqué les problèmes d’événement. Prenez note des noms de module et de fonction.
Dans le graphique Utilisation du processeur (échantillonné), sélectionnez la présélection Utilisation par processus . Par défaut, cette présélection masque l’activité DPC/ISR.
Ouvrez l’Éditeur d’affichage, puis cliquez sur Avancé.
Sous l’onglet Filtre, modifiez les lignes Masquer qui correspondent au paramètre de filtre pour conserver les lignes qui correspondent au filtre. Cela permet aux activités DPC/ISR d’être affichées.
Supprimez la colonne Processus et ajoutez la colonne Pile pour afficher les dpcs/ISR triés par pile.
Effacez la sélection de ligne actuelle.
Cliquez avec le bouton droit sur une cellule de la colonne Pile , puis cliquez sur Rechercher dans cette colonne.
Entrez un module et une fonction que vous avez notés à l’étape 2 de cette procédure.
Cochez Ajouter à la sélection actuelle, puis cliquez sur Rechercher tout pour sélectionner toutes les instances de la fonction.
Une fois que toutes les lignes sont sélectionnées, cliquez avec le bouton droit et cliquez sur Papillon/Affichage appelé.
Cette vue affiche les activités de cette fonction particulière, triées par durée totale. La vue est similaire à une pile affichée dans l’affichage détaillé d’un problème signalé par l’évaluation. La colonne Poids correspond approximativement au temps inclusif passé par chaque fonction sur la pile, en millisecondes.
Cette vue est illustrée dans la figure 51 Appelé d’un DPC trié par durée approximative :

Figure 51 Appelé d’un DPC trié par durée approximative
Technique : passer en revue les DPCS/ISR à long terme
La durée totale des DPCS/ISR est importante, mais les DPCS/ISR individuels à long terme sont plus susceptibles d’entraîner des retards. Dans le graphique DPC/ISR, la colonne Durée inclusive (ms), triée dans l’ordre décroissant, affiche les durées maximales de DPC/ISR individuels. Les DPC/ISR long prédéfinis disponibles dans certains profils d’évaluation vous permettent de filtrer cette vue pour afficher uniquement les DPCs/ISR qui ont une durée inclusive supérieure à 1 ms.
Remarque Si cette présélection n’est pas disponible, vous pouvez ouvrir l’Éditeur d’affichage, section Avancé, pour ajouter un filtre.
Résolution
L’activité DPC/ISR reflète souvent un problème matériel ou logiciel qui doit être corrigé au niveau du matériel ou du composant. Au niveau de la configuration, vous pouvez remplacer le matériel ou mettre à niveau le pilote associé vers une version fixe. Au niveau d’un composant, le matériel et les pilotes doivent suivre les meilleures pratiques pour les DPCs/ISR de MSDN, et doivent utiliser des CONTRÔLEURs de domaine thread quand c’est possible. Les contrôleurs de domaine thread ne s’exécutent pas au niveau de distribution sur les éditions clientes de Windows. Pour plus d’informations sur les meilleures pratiques pour les DPCs/ISR, consultez Recommandations sur le comportement de l’ISR et le DPC et l’introduction aux DPCs threaded.
Rubriques connexes
Présentation des DPCS threadés
Gestion de l’alimentation et ACPI - Prise en charge de l’architecture et du pilote
PPM dans Windows Vista et Windows Server 2008
Planification, contexte de thread et IRQL