Résolution des problèmes de performances lentes de SQL Server dues à des problèmes d’E/S
S'applique à : SQL Server
Cet article fournit des conseils sur les problèmes d’E/S à l’origine de performances lentes de SQL Server et sur la façon de résoudre les problèmes.
Définir les performances des E/S lentes
Les compteurs d’analyseur de performances sont utilisés pour déterminer les performances des E/S lentes. Ces compteurs mesurent la vitesse à laquelle le sous-système d’E/S services chaque demande d’E/S en moyenne en termes de temps d’horloge. Les compteurs d’analyse de performances spécifiques qui mesurent la latence d’E/S dans Windows sont Avg Disk sec/ Read, Avg. Disk sec/Writeet Avg. Disk sec/Transfer (cumulative des lectures et des écritures).
Dans SQL Server, les choses fonctionnent de la même façon. En règle générale, vous examinez si SQL Server signale des goulots d’étranglement d’E/S mesurés au moment de l’horloge (millisecondes). SQL Server envoie des demandes d’E/S au système d’exploitation en appelant les fonctions Win32 telles que WriteFile(), , ReadFile()WriteFileGather()et ReadFileScatter(). Lorsqu’il publie une requête d’E/S, SQL Server times the request and reports the duration of the request using wait types. SQL Server utilise des types d’attente pour indiquer les attentes d’E/S à différents endroits du produit. Les attentes liées aux E/S sont les suivantes :
Si ces attentes dépassent 10 à 15 millisecondes de manière cohérente, les E/S sont considérées comme un goulot d’étranglement.
Note
Pour fournir un contexte et une perspective, dans le monde de la résolution des problèmes de SQL Server, Microsoft CSS a observé des cas où une demande d’E/S a pris plus d’une seconde et jusqu’à 15 secondes par transfert de tels systèmes d’E/S ont besoin d’optimisation. À l’inverse, Microsoft CSS a vu les systèmes où le débit est inférieur à une milliseconde/transfert. Avec la technologie SSD/NVMe d’aujourd’hui, les taux de débit annoncés varient en dizaines de microsecondes par transfert. Par conséquent, la figure de 10 à 15 millisecondes/transfert est un seuil très approximatif que nous avons sélectionné en fonction de l’expérience collective entre les ingénieurs Windows et SQL Server au cours des années. En règle générale, lorsque les nombres dépassent ce seuil approximatif, les utilisateurs SQL Server commencent à voir la latence dans leurs charges de travail et les signalent. En fin de compte, le débit attendu d’un sous-système d’E/S est défini par le fabricant, le modèle, la configuration, la charge de travail et potentiellement plusieurs autres facteurs.
Méthodologie
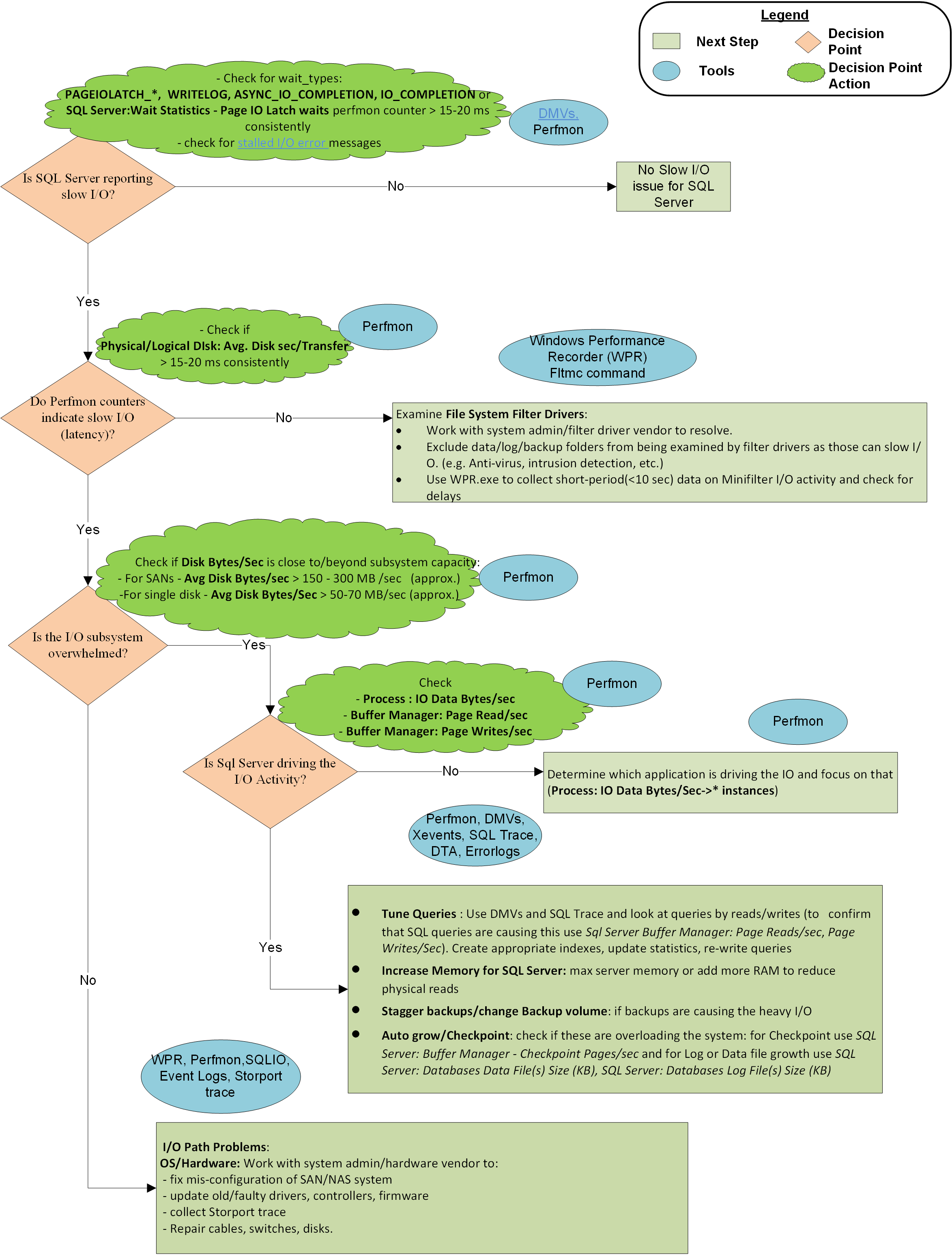
Un organigramme à la fin de cet article décrit la méthodologie utilisée par Microsoft CSS pour aborder les problèmes d’E/S lents avec SQL Server. Ce n’est pas une approche exhaustive ou exclusive, mais elle s’est avérée utile pour isoler le problème et le résoudre.
Vous pouvez choisir l’une des deux options suivantes pour résoudre le problème :
Option 1 : Exécuter les étapes directement dans un notebook via Azure Data Studio
Note
Avant d’essayer d’ouvrir ce notebook, vérifiez qu’Azure Data Studio est installé sur votre ordinateur local. Pour l’installer, accédez à Découvrir comment installer Azure Data Studio.
Option 2 : Suivez les étapes manuellement
La méthodologie est décrite dans les étapes suivantes :
Étape 1 : SQL Server signale-t-il des E/S lentes ?
SQL Server peut signaler la latence des E/S de plusieurs façons :
- Types d’attente d’E/S
- DMV
sys.dm_io_virtual_file_stats - Journal des erreurs ou journal des événements d’application
Types d’attente d’E/S
Déterminez s’il existe une latence d’E/S signalée par les types d’attente SQL Server. Les valeurs , WRITELOGet ASYNC_IO_COMPLETION les valeurs PAGEIOLATCH_*de plusieurs autres types d’attente moins courants doivent généralement rester inférieures à 10 à 15 millisecondes par requête d’E/S. Si ces valeurs sont plus cohérentes, un problème de performances d’E/S existe et nécessite un examen approfondi. La requête suivante peut vous aider à collecter ces informations de diagnostic sur votre système :
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
for ([int]$i = 0; $i -lt 100; $i++)
{
sqlcmd -E -S $sqlserver_instance -Q "SELECT r.session_id, r.wait_type, r.wait_time as wait_time_ms`
FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s `
ON r.session_id = s.session_id `
WHERE wait_type in ('PAGEIOLATCH_SH', 'PAGEIOLATCH_EX', 'WRITELOG', `
'IO_COMPLETION', 'ASYNC_IO_COMPLETION', 'BACKUPIO')`
AND is_user_process = 1"
Start-Sleep -s 2
}
Statistiques des fichiers dans sys.dm_io_virtual_file_stats
Pour afficher la latence au niveau du fichier de base de données comme indiqué dans SQL Server, exécutez la requête suivante :
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
sqlcmd -E -S $sqlserver_instance -Q "SELECT LEFT(mf.physical_name,100), `
ReadLatency = CASE WHEN num_of_reads = 0 THEN 0 ELSE (io_stall_read_ms / num_of_reads) END, `
WriteLatency = CASE WHEN num_of_writes = 0 THEN 0 ELSE (io_stall_write_ms / num_of_writes) END, `
AvgLatency = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0 `
ELSE (io_stall / (num_of_reads + num_of_writes)) END,`
LatencyAssessment = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 'No data' ELSE `
CASE WHEN (io_stall / (num_of_reads + num_of_writes)) < 2 THEN 'Excellent' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 2 AND 5 THEN 'Very good' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 6 AND 15 THEN 'Good' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 16 AND 100 THEN 'Poor' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 100 AND 500 THEN 'Bad' `
ELSE 'Deplorable' END END, `
[Avg KBs/Transfer] = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0 `
ELSE ((([num_of_bytes_read] + [num_of_bytes_written]) / (num_of_reads + num_of_writes)) / 1024) END, `
LEFT (mf.physical_name, 2) AS Volume, `
LEFT(DB_NAME (vfs.database_id),32) AS [Database Name]`
FROM sys.dm_io_virtual_file_stats (NULL,NULL) AS vfs `
JOIN sys.master_files AS mf ON vfs.database_id = mf.database_id `
AND vfs.file_id = mf.file_id `
ORDER BY AvgLatency DESC"
Examinez les colonnes et LatencyAssessment les AvgLatency détails de la latence.
Erreur 833 signalée dans le journal des événements d’erreur ou d’application
Dans certains cas, vous pouvez observer l’erreur 833 SQL Server has encountered %d occurrence(s) of I/O requests taking longer than %d seconds to complete on file [%ls] in database [%ls] (%d) dans le journal des erreurs. Vous pouvez vérifier les journaux d’erreurs SQL Server sur votre système en exécutant la commande PowerShell suivante :
Get-ChildItem -Path "c:\program files\microsoft sql server\mssql*" -Recurse -Include Errorlog |
Select-String "occurrence(s) of I/O requests taking longer than Longer than 15 secs"
Pour plus d’informations sur cette erreur, consultez la section MSSQLSERVER_833 .
Étape 2 : Les compteurs Perfmon indiquent-ils une latence d’E/S ?
Si SQL Server signale une latence d’E/S, reportez-vous aux compteurs du système d’exploitation. Vous pouvez déterminer s’il existe un problème d’E/S en examinant le compteur Avg Disk Sec/Transferde latence. L’extrait de code suivant indique une façon de collecter ces informations via PowerShell. Il collecte des compteurs sur tous les volumes de disque : « _total ». Passez à un volume de lecteur spécifique (par exemple, « D : »). Pour rechercher les volumes qui hébergent vos fichiers de base de données, exécutez la requête suivante dans votre serveur SQL Server :
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
sqlcmd -E -S $sqlserver_instance -Q "SELECT DISTINCT LEFT(volume_mount_point, 32) AS volume_mount_point `
FROM sys.master_files f `
CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id) vs"
Rassemblez Avg Disk Sec/Transfer les métriques sur votre volume de choix :
clear
$cntr = 0
# replace with your server name, unless local computer
$serverName = $env:COMPUTERNAME
# replace with your volume name - C: , D:, etc
$volumeName = "_total"
$Counters = @(("\\$serverName" +"\LogicalDisk($volumeName)\Avg. disk sec/transfer"))
$disksectransfer = Get-Counter -Counter $Counters -MaxSamples 1
$avg = $($disksectransfer.CounterSamples | Select-Object CookedValue).CookedValue
Get-Counter -Counter $Counters -SampleInterval 2 -MaxSamples 30 | ForEach-Object {
$_.CounterSamples | ForEach-Object {
[pscustomobject]@{
TimeStamp = $_.TimeStamp
Path = $_.Path
Value = ([Math]::Round($_.CookedValue, 5))
turn = $cntr = $cntr +1
running_avg = [Math]::Round(($avg = (($_.CookedValue + $avg) / 2)), 5)
} | Format-Table
}
}
write-host "Final_Running_Average: $([Math]::Round( $avg, 5)) sec/transfer`n"
if ($avg -gt 0.01)
{
Write-Host "There ARE indications of slow I/O performance on your system"
}
else
{
Write-Host "There is NO indication of slow I/O performance on your system"
}
Si les valeurs de ce compteur sont constamment supérieures à 10 à 15 millisecondes, vous devez examiner le problème plus loin. Les pics occasionnels ne comptent pas dans la plupart des cas, mais veillez à vérifier la durée d’un pic. Si le pic a duré une minute ou plus, c’est plus d’un plateau qu’un pic.
Si les compteurs de l’analyseur de performances ne signalent pas de latence, mais QUE SQL Server le fait, le problème se produit entre SQL Server et le Gestionnaire de partition, autrement dit, les pilotes de filtre. Le Gestionnaire de partitions est une couche d’E/S où le système d’exploitation collecte les compteurs Perfmon . Pour résoudre la latence, assurez-vous que les exclusions appropriées des pilotes de filtre et résolvez les problèmes de pilote de filtre. Les pilotes de filtre sont utilisés par des programmes tels que les logiciels antivirus, les solutions de sauvegarde, le chiffrement, la compression, etc. Vous pouvez utiliser cette commande pour répertorier les pilotes de filtre sur les systèmes et les volumes auxquels ils s’attachent. Vous pouvez ensuite rechercher les noms des pilotes et les fournisseurs de logiciels dans l’article Sur les altitudes de filtre allouées .
fltmc instances
Pour plus d’informations, consultez Comment choisir un logiciel antivirus à exécuter sur des ordinateurs exécutant SQL Server.
Évitez d’utiliser le chiffrement du système de fichiers (EFS) et la compression du système de fichiers, car elles entraînent la synchronisation des E/S asynchrones et, par conséquent, plus lentes. Pour plus d’informations, voir l’E /S de disque asynchrone s’affiche comme synchrone sur l’article Windows .
Étape 3 : Le sous-système d’E/S est-il dépassé la capacité ?
Si SQL Server et le système d’exploitation indiquent que le sous-système d’E/S est lent, vérifiez si la cause est dépassée par le système au-delà de la capacité. Vous pouvez vérifier la capacité en examinant les compteurs d’E Disk Bytes/Sec/S , Disk Read Bytes/Secou Disk Write Bytes/Sec. Veillez à vérifier auprès de votre administrateur système ou fournisseur de matériel les spécifications de débit attendues pour votre san (ou un autre sous-système d’E/S). Par exemple, vous pouvez envoyer (push) plus de 200 Mo/s d’E/S via une carte HBA de 2 Go/s ou un port dédié de 2 Go/s sur un commutateur SAN. La capacité de débit attendue définie par un fabricant de matériel définit la façon dont vous procédez ici.
clear
$serverName = $env:COMPUTERNAME
$Counters = @(
("\\$serverName" +"\PhysicalDisk(*)\Disk Bytes/sec"),
("\\$serverName" +"\PhysicalDisk(*)\Disk Read Bytes/sec"),
("\\$serverName" +"\PhysicalDisk(*)\Disk Write Bytes/sec")
)
Get-Counter -Counter $Counters -SampleInterval 2 -MaxSamples 20 | ForEach-Object {
$_.CounterSamples | ForEach-Object {
[pscustomobject]@{
TimeStamp = $_.TimeStamp
Path = $_.Path
Value = ([Math]::Round($_.CookedValue, 3)) }
}
}
Étape 4 : SQL Server pilote-t-il l’activité d’E/S intensive ?
Si le sous-système d’E/S est submergé au-delà de la capacité, déterminez si SQL Server est le coupable en examinant Buffer Manager: Page Reads/Sec (le plus courant) et Page Writes/Sec (beaucoup moins courant) pour l’instance spécifique. Si SQL Server est le pilote d’E/S principal et que le volume d’E/S dépasse ce que le système peut gérer, collaborez avec les équipes de développement d’applications ou le fournisseur d’applications pour :
- Paramétrez les requêtes, par exemple : de meilleurs index, mettez à jour les statistiques, réécrivez des requêtes et recréez la base de données.
- Augmentez la mémoire maximale du serveur ou ajoutez davantage de RAM sur le système. Plus de RAM met en cache plus de données ou de pages d’index sans relecture fréquente à partir du disque, ce qui réduit l’activité d’E/S. L’augmentation de la mémoire peut également réduire
Lazy Writes/sec, qui sont pilotées par les vidages différés de l’enregistreur lorsqu’il est fréquemment nécessaire de stocker davantage de pages de base de données dans la mémoire limitée disponible. - Si vous constatez que les écritures de page sont la source d’une activité d’E/S intensive, examinez
Buffer Manager: Checkpoint pages/secsi elle est due à des vidages de pages massifs requis pour répondre aux demandes de configuration de l’intervalle de récupération. Vous pouvez utiliser des points de contrôle indirects pour même sortir des E/S au fil du temps ou augmenter le débit d’E/S matériel.
Causes
En général, les problèmes suivants sont les raisons principales pour lesquelles les requêtes SQL Server souffrent d’une latence d’E/S :
Problèmes matériels :
Configuration incorrecte de SAN (commutateur, câbles, HBA, stockage)
Capacité d’E/S dépassée (déséquilibré dans l’ensemble du réseau SAN, pas seulement le stockage back-end)
Problèmes liés aux pilotes ou au microprogramme
Les fournisseurs de matériel et/ou les administrateurs système doivent être engagés à ce stade.
Problèmes de requête : SQL Server sature les volumes de disques avec des requêtes d’E/S et envoie (push) le sous-système d’E/S au-delà de la capacité, ce qui entraîne un taux de transfert d’E/S élevé. Dans ce cas, la solution consiste à rechercher les requêtes qui provoquent un nombre élevé de lectures logiques (ou d’écritures) et à régler ces requêtes pour réduire les E/S de disque à l’aide d’index appropriés est la première étape à effectuer. Conservez également les statistiques mises à jour, car elles fournissent à l’optimiseur de requête des informations suffisantes pour choisir le meilleur plan. En outre, la conception incorrecte de la base de données et la conception des requêtes peuvent entraîner une augmentation des problèmes d’E/S. Par conséquent, la refonte des requêtes et parfois des tables peut aider à améliorer les E/S.
Pilotes de filtre : la réponse d’E/S SQL Server peut être gravement affectée si les pilotes de filtre du système de fichiers traitent le trafic d’E/S lourd. Les exclusions de fichiers appropriées de l’analyse antivirus et de la conception correcte du pilote de filtre par les fournisseurs de logiciels sont recommandées pour empêcher l’impact sur les performances des E/S.
Autres applications : une autre application sur la même machine avec SQL Server peut saturer le chemin d’E/S avec des demandes de lecture ou d’écriture excessives. Cette situation peut pousser le sous-système d’E/S au-delà des limites de capacité et provoquer la lenteur des E/S pour SQL Server. Identifiez l’application et ajustez-la ou déplacez-la ailleurs pour éliminer son impact sur la pile d’E/S.
Représentation graphique de la méthodologie
Informations sur les types d’attente liés aux E/S
Voici des descriptions des types d’attente courants observés dans SQL Server lorsque des problèmes d’E/S de disque sont signalés.
PAGEIOLATCH_EX
Se produit lorsqu’une tâche attend un verrou pour une page de données ou d’index (mémoire tampon) dans une requête d’E/S. La demande de verrou est en mode Exclusif. Un mode exclusif est utilisé lorsque la mémoire tampon est écrite sur le disque. De longues attentes peuvent indiquer l'existence de problèmes au niveau du sous-système de disque.
PAGEIOLATCH_SH
Se produit lorsqu’une tâche attend un verrou pour une page de données ou d’index (mémoire tampon) dans une requête d’E/S. La demande de verrou est en mode partagé. Le mode partagé est utilisé lorsque la mémoire tampon est lue à partir du disque. De longues attentes peuvent indiquer l'existence de problèmes au niveau du sous-système de disque.
PAGEIOLATCH_UP
Se produit lorsqu’une tâche attend un verrou pour une mémoire tampon dans une requête d’E/S. La demande de verrou est en mode Mise à jour. De longues attentes peuvent indiquer l'existence de problèmes au niveau du sous-système de disque.
WRITELOG
Se produit lorsqu’une tâche attend la fin d’un vidage du journal des transactions. Une vidage se produit lorsque le Gestionnaire de journaux écrit son contenu temporaire sur le disque. Les opérations courantes qui provoquent des vidages de journal sont des validations de transaction et des points de contrôle.
Les raisons courantes WRITELOG des longues attentes sont les suivantes :
Latence du disque du journal des transactions : il s’agit de la cause la plus courante des
WRITELOGattentes. En règle générale, il est recommandé de conserver les données et les fichiers journaux sur des volumes distincts. Les écritures du journal des transactions sont des écritures séquentielles lors de la lecture ou de l’écriture de données à partir d’un fichier de données est aléatoire. Le mélange de données et de fichiers journaux sur un volume de lecteur (en particulier les lecteurs de disque de rotation classiques) entraîne un déplacement excessif de la tête du disque.Trop de fichiers journaux virtuels : trop de fichiers journaux virtuels (VLF) peuvent entraîner
WRITELOGdes attentes. Un trop grand nombre de fonctions VLF peuvent entraîner d’autres types de problèmes, tels que la récupération longue.Trop de petites transactions : bien que les transactions volumineuses puissent entraîner un blocage, trop de petites transactions peuvent entraîner un autre ensemble de problèmes. Si vous ne commencez pas explicitement une transaction, toute insertion, suppression ou mise à jour entraîne une transaction (nous appelons cette transaction automatique). Si vous effectuez 1 000 insertions dans une boucle, 1 000 transactions sont générées. Chaque transaction de cet exemple doit être validée, ce qui entraîne un vidage du journal des transactions et 1 000 vidages de transaction. Dans la mesure du possible, regroupez les mises à jour, supprimez ou insérez dans une transaction plus importante pour réduire les vidages du journal des transactions et augmenter les performances. Cette opération peut entraîner moins
WRITELOGd’attentes.Les problèmes de planification provoquent l’échec de la planification des threads de l’enregistreur de journaux : avant SQL Server 2016, un thread d’enregistreur de journaux unique a effectué toutes les écritures de journal. S’il y a eu des problèmes avec la planification des threads (par exemple, un processeur élevé), le thread de l’enregistreur de journaux et les vidages de journal peuvent être retardés. Dans SQL Server 2016, jusqu’à quatre threads d’enregistreur de journaux ont été ajoutés pour augmenter le débit d’écriture des journaux. Consultez SQL 2016 - Il s’exécute simplement plus rapidement : plusieurs workers de l’enregistreur de journaux. Dans SQL Server 2019, jusqu’à huit threads d’enregistreur de journaux ont été ajoutés, ce qui améliore encore davantage le débit. En outre, dans SQL Server 2019, chaque thread de travail standard peut effectuer des écritures de journal directement au lieu de publier dans le thread de l’enregistreur de journaux. Avec ces améliorations,
WRITELOGles attentes seraient rarement déclenchées par des problèmes de planification.
ASYNC_IO_COMPLETION
Se produit lorsque certaines des activités d’E/S suivantes se produisent :
- Le fournisseur d’insertion en bloc (« Insérer en bloc ») utilise ce type d’attente lors de l’exécution d’E/S.
- Lecture du fichier Annuler dans LogShipping et diriger les E/S asynchrones pour la copie des journaux de transaction.
- Lecture des données réelles à partir des fichiers de données pendant une sauvegarde de données.
IO_COMPLETION
Se produit durant l'attente de l'exécution des opérations d'E/S. Ce type d’attente implique généralement des E/S non liées aux pages de données (mémoires tampons). Voici quelques exemples :
- Lecture et écriture de résultats de tri/hachage de/vers le disque pendant un déversement (vérifiez les performances du stockage tempdb ).
- Lecture et écriture de spools impatients sur le disque (vérifiez le stockage tempdb ).
- Lecture des blocs de journal à partir du journal des transactions (pendant toute opération qui provoque la lecture du journal à partir du disque, par exemple, récupération).
- Lecture d’une page à partir d’un disque lorsque la base de données n’est pas encore configurée.
- Copie de pages dans un instantané de base de données (copie en écriture).
- Fermeture du fichier de base de données et de la décompression de fichier.
BACKUPIO
Se produit lorsqu’une tâche de sauvegarde attend des données ou attend qu’une mémoire tampon stocke des données. Ce type n’est pas classique, sauf lorsqu’une tâche attend un montage de bande.