Résoudre les problèmes de basculement des groupes de disponibilité Always On
Note
Pour automatiser l’analyse manuelle décrite dans cet article, consultez Utiliser AGDiag pour diagnostiquer les événements d’intégrité du groupe de disponibilité.
Cet article fournit des étapes de dépannage pour vous aider à déterminer pourquoi votre groupe de disponibilité a basculé.
Effets des problèmes d’intégrité Always On ou du basculement
Always On implémente une surveillance d’intégrité robuste par le biais de différents mécanismes pour garantir l’intégrité de l’instance Microsoft SQL Server qui héberge le réplica principal, le cluster sous-jacent et l’intégrité du système. La charge de travail de production est interrompue momentanément lorsqu’un cluster Windows ou un problème d’intégrité Always On est identifié.
Lorsqu’une condition d’intégrité est détectée, la séquence d’événements suivante se produit généralement. Tout au long de cet utilitaire de résolution des problèmes, les événements d’intégrité sont mentionnés en référence aux événements suivants :
Les réplicas de groupe de disponibilité et les bases de données passent du rôle principal à la résolution du rôle.
Les bases de données de groupe de disponibilité passent en mode hors connexion et ne sont plus accessibles.
Le cluster Windows marque l’échec de la ressource cluster du groupe de disponibilité.
Le cluster Windows tente de rétablir le rôle de groupe de disponibilité en ligne (sur le réplica partenaire de basculement d’origine ou automatique).
Le rôle de groupe de disponibilité est en ligne correctement s’il est détecté comme sain par la surveillance de l’intégrité du cluster Always On et Windows.
Si elle réussit, les réplicas et les bases de données du groupe de disponibilité passent au rôle principal et les bases de données du groupe de disponibilité sont en ligne et sont accessibles par votre application.
Les applications ne peuvent pas accéder aux bases de données du groupe de disponibilité
Lorsqu’une condition d’intégrité est détectée, le réplica de groupe de disponibilité et les bases de données passent au rôle Résolution et les bases de données du groupe de disponibilité sont mises hors connexion. Une fois que le réplica est en ligne dans le rôle principal (sur le serveur de réplica d’origine ou le serveur de réplica du partenaire de basculement), le réplica et les bases de données passent à nouveau en ligne. Pendant que le réplica et les bases de données sont résolus et hors connexion, toutes les applications qui tentent d’accéder à ces bases de données de groupe de disponibilité échouent et génèrent un message « Erreur 983 » : Unable to access availability database.... Cette erreur est également enregistrée dans le journal des erreurs Microsoft SQL Server si SQL Server est configuré pour enregistrer les tentatives de connexion ayant échoué :
Logon Error: 983, Severity: 14, State: 1.
Logon Unable to access availability database '<databasename>' because the database replica is not in the PRIMARY or SECONDARY role. Connections to an availability database is permitted only when the database replica is in the PRIMARY or SECONDARY role. Try the operation again later.
La période pendant laquelle le groupe de disponibilité est dans le rôle résolution avant de revenir en ligne dans le rôle principal ne dure généralement que quelques secondes ou même moins d’une seconde.
Identifier et diagnostiquer les événements d’intégrité de groupe de disponibilité Always On ou le basculement
1. Identifier les tendances d’intégrité Always On
Vous pouvez examiner un événement d’intégrité Always On unique, ou il peut y avoir une tendance récente ou continue des problèmes de santé qui interrompent la production de façon intermittente. Les questions suivantes peuvent vous aider à affiner et à mettre en corrélation les changements récents dans votre environnement de production susceptibles d’être liés à ces problèmes d’intégrité :
- Quand la tendance des événements d’intégrité de cluster ou Always On a-t-il commencé ?
- Les événements d’intégrité se produisent-ils un jour donné ?
- Les événements d’intégrité se produisent-ils à un certain moment de la journée ?
- Les événements d’intégrité se produisent-ils le jour ou la semaine du mois ?
Si vous détectez une tendance, vérifiez la maintenance planifiée sur le système (le système hôte dans un environnement virtuel), les lots ETL et d’autres travaux susceptibles de mettre en corrélation ces événements d’intégrité. Si le système est une machine virtuelle, examinez le système hôte pour connaître les modifications éventuellement introduites au moment des pannes.
Considérez les charges de travail de production ad hoc occupées qui peuvent être corrélées au moment des problèmes d’intégrité (par exemple, lorsque les utilisateurs se connectent pour la première fois au système ou après le retour des utilisateurs à partir du déjeuner).
Note
Il est judicieux de prendre en compte un plan de collecte des données de performances tout au long de la semaine et du mois. Pour mieux comprendre quand le système est le plus busé, vous pouvez mesurer les compteurs du moniteur de performances Windows tels que Processor Information::% Processor Time, Memory::Available MByteset MSSQLServer:SQL Statistics::Batch Requests/sec.
2. Passez en revue le journal du cluster
Le journal du cluster Windows est le journal le plus complet à utiliser pour identifier le type d’événement d’intégrité Always On ou cluster, ainsi que la condition d’intégrité détectée qui a provoqué l’événement. Pour générer et ouvrir le journal du cluster, procédez comme suit :
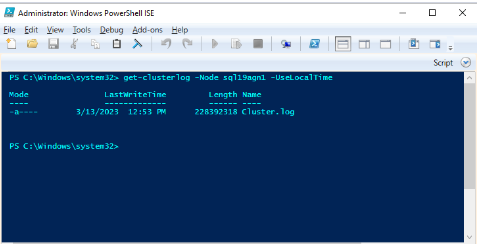
Utilisez Windows PowerShell pour générer le journal du cluster Windows sur le nœud de cluster qui héberge le réplica principal au moment de l’événement d’intégrité. Par exemple, exécutez l’applet de commande suivante dans une fenêtre PowerShell avec élévation de privilèges à l’aide de « sql19agn1 » comme nom de serveur SQL Server :
get-clusterlog -Node sql19agn1 -UseLocalTime
Note
Par défaut, le fichier journal est créé dans %WINDIR%\cluster\reports.
3. Rechercher l’événement d’intégrité dans le journal du cluster
Always On utilise plusieurs mécanismes de surveillance de l’intégrité pour surveiller l’intégrité du groupe de disponibilité. En plus d’un événement d’intégrité de cluster Windows (dans lequel le cluster Windows détecte un problème d’intégrité parmi les nœuds de cluster), Always On a quatre types différents de vérifications d’intégrité :
- Le service SQL Server n’est pas en cours d’exécution
- Délai d’expiration du bail SQL Server
- Délai d’expiration du contrôle d’intégrité SQL Server
- Problème d’intégrité interne SQL Server
Vous pouvez localiser l’un de ces événements d’intégrité spécifiques Always On en recherchant le journal du cluster pour la chaîne [hadrag] Resource Alive result 0. Cette chaîne est enregistrée dans le journal du cluster lorsque l’un de ces événements est détecté. Par exemple :
00001334.00002ef4::2019/06/24-18:24:36.153 ERR [RES] SQL Server Availability Group : [hadrag] Resource Alive result 0.
Vous pouvez utiliser un outil pour rechercher tous les événements d’intégrité dans le journal du cluster afin de générer un rapport récapitulatif des problèmes d’intégrité Always On. Cela peut être utile pour identifier les tendances chronologiques et déterminer si une condition d’intégrité Always On particulière est récurrente. La capture d’écran suivante montre comment utiliser un éditeur de texte (NotePad++, dans ce cas) pour rechercher toutes les lignes du journal du cluster qui contiennent la [hadrag] Resource Alive result 0 chaîne :

Identifier et résoudre le problème d’intégrité qui a déclenché le basculement
Pour identifier les problèmes d’intégrité dans le journal du cluster du réplica principal, comparez-les aux problèmes décrits dans les sections suivantes. Les raisons courantes du basculement du groupe de disponibilité sont les suivantes :
- Événement d’intégrité du cluster
- Le service SQL Server est arrêté (événement d’intégrité Always On)
- Délai d’expiration du bail (événement d’intégrité Always On)
- Délai d’expiration du contrôle d’intégrité (événement d’intégrité Always On)
- Intégrité de SQL Server (événement d’intégrité Always On)
Événements d’intégrité du cluster
Le cluster Microsoft Windows surveille l’intégrité des serveurs membres du cluster. Si un problème d’intégrité est détecté, un serveur membre de cluster peut être supprimé du cluster. En outre, les ressources de cluster (y compris le rôle de groupe de disponibilité hébergé sur le serveur membre de cluster supprimé) sont déplacées vers le réplica partenaire de basculement du groupe de disponibilité s’il est configuré pour le basculement automatique.
Symptômes
Voici un exemple d’événement d’intégrité de cluster dans le journal du cluster. Pour le trouver, vous pouvez rechercher Lost quorum ou Cluster service has terminated parce que l’un ou l’autre peut être présent pendant la modification du rôle de groupe de disponibilité ou le basculement.
00000fe4.00001628::2022/12/15-14:26:02.654 WARN [QUORUM] Node 1: Lost quorum (1)
00000fe4.00001628::2022/12/15-14:26:02.654 WARN [QUORUM] Node 1: goingAway: 0, core.IsServiceShutdown: 0
00000fe4.00001628::2022/12/15-14:26:02.654 WARN lost quorum (status = 5925)
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [NETFT] Cluster Service preterminate succeeded.
00000fe4.00001628::2022/12/15-14:26:02.654 WARN lost quorum (status = 5925), executing OnStop
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [DM]: Shutting down, so unloading the cluster database.
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [DM] Shutting down, so unloading the cluster database (waitForLock: false).
000019cc.000019d0::2022/12/15-14:26:02.654 WARN [RHS] Cluster service has terminated. Cluster.Service.Running.Event got signaled.
Une autre façon d’identifier cet événement consiste à rechercher dans le journal des événements système Windows :
Critical SQL19AGN1.CSSSQL 1135 Microsoft-Windows-FailoverClusterin Node Mgr NT AUTHORITY\SYSTEM Cluster node 'SQL19AGN2' was removed from the active failover cluster membership. The Cluster service on this node may have stopped. This could also be due to the node having lost communication with other active nodes in the failover cluster. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapters on this node. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Critical SQL19AGN1.CSSSQL 1177 Microsoft-Windows-FailoverClusterin Quorum Manager NT AUTHORITY\SYSTEM The Cluster service is shutting down because quorum was lost. This could be due to the loss of network connectivity between some or all nodes in the cluster, or a failover of the witness disk. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapter. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Diagnostiquer un événement d’intégrité de cluster
Les erreurs dans le journal des événements Windows (événements 1135 et 1177) suggèrent que la connectivité réseau est une cause de l’événement. Il s’agit de la raison la plus courante pour laquelle un problème d’intégrité de cluster est détecté. L’exemple suivant montre que d’autres serveurs membres du cluster n’ont pas pu communiquer avec ce serveur qui héberge le réplica principal du groupe de disponibilité et que ce problème a déclenché la suppression du nœud de cluster du cluster :
00000fe4.00001edc::2022/12/14-22:44:36.870 INFO [NODE] Node 1: New join with n3: stage: 'Attempt Initial Connection' status (10060) reason: 'Failed to connect to remote endpoint <endpoint address>'
00000fe4.00001620::2022/12/15-14:26:02.050 INFO [IM] got event: Remote endpoint <endpoint address> unreachable from <endpoint address>
00000fe4.00001620::2022/12/15-14:26:02.050 WARN [NDP] All routes for route (virtual) local <local address> to remote <remote address> are down
00000fe4.0000179c::2022/12/15-14:26:02.053 WARN [NODE] Node 1: Connection to Node 2 is broken. Reason GracefulClose(1226)' because of 'channel to remote endpoint <endpoint address> is closed'
Vous pouvez rechercher dans le journal du cluster la preuve d’un échec de connexion au nœud. À partir de l’emplacement dans le journal du cluster où vous avez trouvé Lost quorum, recherchez en arrière les chaînes telles que Failed to connect to remote endpoint, unreachableet is broken.
Résolution
Assurez-vous que la surveillance de l’intégrité du cluster est appropriée pour l’environnement hôte. Pour plus d’informations sur les groupes de disponibilité Always On SQL Server hébergés dans Microsoft Azure, consultez la vue d’ensemble du cluster de basculement Windows Server - SQL Server sur des machines virtuelles Azure.
Si nécessaire, envisagez de contacter le support de haute disponibilité Microsoft Windows pour ouvrir un incident de support.
Le service SQL Server est arrêté : événement d’intégrité Always On
La surveillance de l’intégrité Always On peut détecter si le service SQL Server qui héberge le réplica principal du groupe de disponibilité n’est plus en cours d’exécution.
Symptômes
Voici un exemple de rapport du journal du cluster pour le rôle de groupe de disponibilité « ag » qui indique un échec, car QueryServiceStatusEx il a retourné un ID 0de processus :
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] QueryServiceStatusEx returned a process id 0
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] SQL server service is not alive
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] Resource Alive result 0.
00001898.0000185c::2023/02/27-13:27:41.121 WARN [RHS] Resource ag IsAlive has indicated failure.
Diagnostiquer les événements d’arrêt du service SQL
Vérifiez le journal des événements système Windows et le journal des erreurs SQL Server pour obtenir un arrêt inattendu de SQL Server.
Si SQL Server a été arrêté par un arrêt système ou un arrêt administratif, vous verrez l’entrée suivante dans le journal des erreurs SQL Server :
2023-03-10 09:38:46.73 spid9s SQL Server is terminating in response to a 'stop' request from Service Control Manager. This is an informational message only. No user action is required.
Le journal des événements système Windows affiche l’entrée d’erreur suivante :
Information 3/10/2023 9:41:06 AM Service Control Manager 7036 None The SQL Server (MSSQLSERVER) service entered the stopped state.
Le journal des événements système Windows affiche l’entrée d’erreur suivante si SQL Server s’arrête de façon inattendue :
Error 3/10/2023 8:37:46 AM Service Control Manager 7034 None The SQL Server (MSSQLSERVER) service terminated unexpectedly. It has done this 1 time(s).
Vérifiez la fin du journal des erreurs SQL Server pour obtenir des indices. Si le journal des erreurs se termine brusquement, cela signifie qu’il a été arrêté par force. Par exemple, si SQL Server a été arrêté à l’aide du Gestionnaire de tâches, le rapport d’erreurs SQL Server ne révélerait aucune information sur les problèmes internes susceptibles d’avoir provoqué l’arrêt du processus.
Résolution
Assurez-vous que les administrateurs de base de données et système autorisés ont accès au système pour réduire les interruptions inattendues du service SQL Server. Après avoir examiné les journaux des événements, examinez pourquoi un service doit être arrêté de façon inattendue.
Si un problème d’intégrité interne SQL Server a provoqué l’arrêt inattendu de SQL Server, il peut y avoir des indices d’une exception irrécupérable possible (y compris un fichier de diagnostic de vidage mémoire généré) à la fin du journal des erreurs SQL. Passez en revue les indices et prenez les mesures nécessaires. Si vous trouvez un fichier de vidage, contactez le support microsoft SQL Server et fournissez le journal des erreurs sql Server et le contenu du fichier de vidage pour une investigation plus approfondie.
Délai d’expiration du bail : événement d’intégrité Always On
Always On utilise un mécanisme de « bail » pour surveiller l’intégrité de l’ordinateur sur lequel SQL Server est installé. Le délai d’expiration du bail par défaut est de 20 secondes.
Symptômes
Voici un exemple de sortie d’un délai d’expiration du bail Always On à partir du journal du cluster. Vous pouvez rechercher ces chaînes pour localiser un délai d’attente de bail dans le journal du cluster.
00001a0c.00001c5c::2023/01/04-15:36:54.762 ERR [RES] SQL Server Availability Group : [hadrag] Availability Group lease is no longer valid
00001a0c.00001c5c::2023/01/04-15:36:54.762 ERR [RES] SQL Server Availability Group : [hadrag] Resource Alive result 0.
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] Lease timeout detected, logging perf counter data collected so far
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:35:57.0, 98.068572, 509227008.000000, 0.000395, 0.000350 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:7.0, 12.314941, 451817472.000000, 0.000278, 0.000266 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:17.0, 17.270742, 416096256.000000, 0.000376, 0.000292 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:27.0, 38.399895, 416301056.000000, 0.000446, 0.000304 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:37.0, 100.000000, 417517568.000000, 0.001292, 0.000666
Pour plus d’informations sur le délai d’expiration du bail, consultez la section Mécanisme de bail dans Mécanismes et instructions relatives au bail, au cluster et aux délais d’expiration du contrôle d’intégrité pour les groupes de disponibilité Always On.
Diagnostiquer et résoudre les événements de délai d’expiration du bail Always On
Il existe deux problèmes principaux qui peuvent déclencher un délai d’expiration du bail :
Vidage de mémoire SQL Server : quand SQL Server détecte certains événements d’intégrité internes, tels qu’une violation d’accès, une assertion ou un blocage du planificateur, il génère un fichier de vidage de diagnostic (.mdmp) dans le dossier SQL Server \LOG . Le processus de génération d’un vidage de mémoire interrompt l’exécution de SQL Server pendant une courte période. Au cours de cette période, le mécanisme de bail peut détecter l’absence de réponse de service et déclencher une action. Pour plus d’informations, consultez Impact de la génération de vidage.
Problème de performances à l’échelle du système : un délai d’expiration du bail n’indique pas nécessairement un problème d’intégrité SQL Server. Au lieu de cela, il peut indiquer un problème d’intégrité à l’échelle du système qui affecte également l’intégrité du serveur SQL Server.
- Utilisation élevée du processeur sur le système (près de 100 %).
- Conditions de mémoire insuffisante : mémoire virtuelle insuffisante et/ou l’un des processus est mis en page.
- WSFC en mode hors connexion en raison d’une perte de quorum
- Limitation des machines virtuelles affectant les performances et provoquant l’expiration du bail.
Résolution
Pour obtenir des instructions détaillées sur la résolution des problèmes, consultez MSSQLSERVER_19407. Voici les deux problèmes les plus courants :
diagnostic du fichier de vidage du serveur 1. SQL
SQL Server peut détecter un problème d’intégrité interne tel qu’une violation d’accès, une assertion ou des planificateurs bloqués. Dans ce cas, le programme génère un mini-fichier de vidage (.mdmp) dans le dossier SQL Server \LOG du processus SQL Server pour le diagnostic. Le processus SQL Server est figé pendant plusieurs secondes pendant que le fichier mini dump est écrit sur le disque. Pendant ce temps, tous les threads du processus SQL Server sont dans un état figé, ce qui inclut le thread de bail surveillé par la surveillance de l’intégrité Always On. Par conséquent, Always On peut détecter un délai d’attente de bail.
**Dump thread - spid = 0, EC = 0x0000000000000000
***Stack Dump being sent to C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\LOG\SQLDump0001.txt
* *******************************************************************************
*
* BEGIN STACK DUMP:
* 11/02/14 21:21:10 spid 1920
*
* Deadlocked Schedulers
*
* *******************************************************************************
* -------------------------------------------------------------------------------
* Short Stack Dump
Stack Signature for the dump is 0x00000000000002BA
Error: 19407, Severity: 16, State: 1.
The lease between availability group 'ag' and the Windows Server Failover Cluster has expired. A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster. To determine whether the availability group is failing over correctly, check the corresponding availability group resource in the Windows Server Failover Cluster.
Pour résoudre ce problème, le diagnostic du fichier de vidage mémoire doit être examiné pour la cause racine. Envisagez de contacter le support microsoft SQL Server pour fournir le journal des erreurs SQL Server et le contenu du fichier de vidage pour une investigation plus approfondie.
2. Utilisation élevée du processeur ou autre problème de performances système
Un délai d’expiration du bail indique un problème de performances qui affecte l’ensemble du système, y compris SQL Server. Pour diagnostiquer le problème système, les diagnostics d’intégrité Always On signale les données du moniteur de performances dans le journal du cluster et incluent l’événement de délai d’expiration du bail. Les données de performances s’étendent sur environ 50 secondes avant l’événement de délai d’expiration du bail, en signalant l’utilisation du processeur, la mémoire libre et la latence du disque.
Voici un exemple des données de performances signalées qui affichent un délai d’attente de bail dans le journal du cluster. Dans cet exemple de sortie, utilisation globale élevée du processeur qui peut être liée au délai d’expiration du bail.
00000f90.000015c0::2020/08/07-14:16:41.378 WARN [RES] SQL Server Availability Group: [hadrag] Lease timeout detected, logging perf counter data collected so far
00000f90.000015c0::2020/08/07-14:16:41.382 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:20.0, 83.266073, 31700828160.000000, 0.018094, 0.015752
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:30.0, 93.653224, 31697063936.000000, 0.038590, 0.026897
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:40.0, 94.270691, 31696265216.000000, 0.166000, 0.038962
00000f90.000015c0::2020/08/07-14:16:41.434 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:50.0, 90.272016, 31695409152.000000, 0.215141, 0.106084
00000f90.000015c0::2020/08/07-14:16:41.434 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:16:1.0, 99.991336, 31695892480.000000, 0.046983, 0.035440
Si les données de performances affichent une utilisation élevée du processeur, une condition de mémoire faible ou une latence de disque élevée au moment d’un délai d’attente de bail, commencez à collecter des données Analyseur de performances pour la journée complète sur le réplica principal afin d’examiner ces symptômes. En capturant les données du moniteur de performances sur une période plus longue, vous pouvez mieux identifier les valeurs de référence et de pointe pour ces ressources et surveiller les modifications apportées à ces ressources lorsqu’un délai d’attente de bail se produit. Lorsque vous collectez ces données, déterminez s’il existe certaines charges de travail planifiées ou ad hoc dans SQL Server qui correspondent au moment de ces problèmes de ressources et événements d’intégrité.
Vous devez également capturer des compteurs qui signalent la même utilisation des ressources système, y compris les éléments suivants :
Processor Information::% Processor TimeMemory::Available MBytesLogical Disk::Avg. Disk sec/ReadLogical Disk::Avg. Disk sec/WriteLogical Disk::Avg. Disk Read Queue LengthLogical Disk::Avg. Disk Write Queue LengthMSSQLServer:SQL Statistics::Batch Requests/sec
Délai d’expiration du contrôle d’intégrité : événement d’intégrité Always On
Always On utilise un mécanisme de contrôle d’intégrité pour surveiller l’intégrité de SQL Server et la possibilité pour les applications clientes de se connecter.
Symptômes
Lorsqu’un réplica de groupe de disponibilité passe au rôle principal, la surveillance de l’intégrité Always On établit une connexion ODBC locale à l’instance SQL Server. Pendant la connexion et la surveillance d’Always On, si SQL Server ne répond pas sur la connexion ODBC au cours de la période définie pour le délai d’expiration du contrôle d’intégrité du groupe de disponibilité (la valeur par défaut est de 30 secondes), un événement de délai d’expiration du contrôle d’intégrité est déclenché. Dans ce cas, le groupe de disponibilité passe du rôle principal au rôle de résolution et lance le basculement, s’il est configuré pour ce faire.
Pour plus d’informations sur les délais d’expiration du contrôle d’intégrité, consultez la section « Fonctionnement du délai d’expiration du contrôle d’intégrité » dans La mécanique et les instructions relatives au bail, au cluster et aux délais d’expiration du contrôle d’intégrité pour les groupes de disponibilité Always On.
Voici un délai d’expiration du contrôle d’intégrité Always On tel qu’indiqué dans le journal du cluster :
0000211c.00002d70::2021/02/24-02:50:01.890 WARN [RES] SQL Server Availability Group: [hadrag] Failed to retrieve data column. Return code -1
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <AG>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <AG>: [hadrag] Resource Alive result 0.
0000211c.00002594::2021/02/24-02:50:02.453 WARN [RHS] Resource AG IsAlive has indicated failure.
00001278.00002ed8::2021/02/24-02:50:02.453 INFO [RCM] HandleMonitorReply: FAILURENOTIFICATION for 'AG', gen(0) result 1/0.
Diagnostiquer et résoudre l’événement de délai d’expiration du contrôle d’intégrité Always On
La section suivante vous aide à passer en revue les journaux SQL Server pour les événements de « miettes de navigation » que vous pouvez trouver et qui sont corrélés aux délais d’attente de contrôle d’intégrité Always On détectés et signalés. Les journaux d’activité examinés ici incluent le journal du cluster (où le délai d’expiration du contrôle d’intégrité est confirmé), les system_health journaux d’événements étendus et les journaux d’erreurs SQL Server (tous deux trouvés dans le dossier SQL Server \LOG ) et le journal des événements système Windows. Utilisez ces journaux et d’autres journaux pour rechercher des événements corrélatants susceptibles de vous aider à limiter la cause du délai d’expiration du contrôle d’intégrité.
1. Rechercher les événements de planificateur non-rendement
Le délai d’expiration du contrôle d’intégrité Always On est fréquemment dû à des événements « sans rendement » dans SQL Server. Quand SQL Server détecte qu’un thread n’a pas été généré sur un planificateur, il signale qu’un événement de planificateur non-rendement s’est produit. Si vous voyez d’autres tâches sur le même planificateur qui ne reçoivent pas de temps processeur, il s’agit du signe principal d’un planificateur sans rendement. Ce comportement peut entraîner une exécution différée de ces tâches et des charges de travail « affamées » affectées à un certain planificateur de temps processeur.
Pour rechercher les événements de planificateur non-rendement, procédez comme suit :
Vérifiez les journaux d’événements étendus SQL Server
system_healthpour déterminer si un événement de planificateur sans rendement d’un type quelconque a été signalé à l’heure de l’événement de contrôle d’intégrité Always On. Les événements qui ne produisent pas sont les suivants :scheduler_monitor_non_yielding_ring_buffer_recordedscheduler_monitor_non_yielding_iocp_ring_buffer_recordedscheduler_monitor_stalled_dispatcher_ring_buffer_recordedscheduler_monitor_non_yielding_rm_ring_buffer_recorded
Ouvrez les journaux des événements étendus d’intégrité du système SQL Server sur le réplica principal au moment de l’expiration du délai d’attente de contrôle d’intégrité suspect.
Dans SQL Server Management Studio (SSMS), accédez à Fichier ouvert, puis sélectionnez Fusionner les fichiers d’événements étendus.>
Cliquez sur le bouton Ajouter.
Dans la boîte de dialogue Ouvrir le fichier, accédez aux fichiers du répertoire SQL Server \LOG.
Appuyez longuement sur Ctrl, puis sélectionnez les fichiers dont les noms commencent par
system_health_xxx.xel.Sélectionnez Ouvrir>OK.
Filtrez les résultats. Cliquez avec le bouton droit sur un événement sous la colonne nom , puis sélectionnez Filtrer par cette valeur.
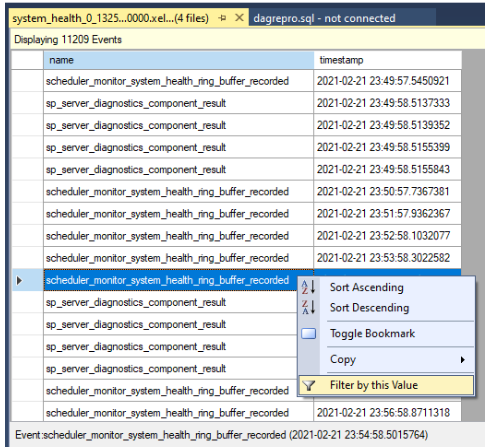
Définissez un filtre pour trier les lignes dans lesquelles les valeurs de la colonne de nom contiennent
yield, comme illustré dans la capture d’écran suivante. Cela retourne tous les types d’événements qui n’ont pas été générés dans lessystem_healthjournaux d’activité.
Comparez les horodatages pour voir s’il y avait des événements sans rendement au moment de l’expiration du contrôle d’intégrité. Voici le délai d’expiration du contrôle d’intégrité tel qu’indiqué dans le journal du cluster :
0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost 0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group < SQL19AGN1>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel 0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group < SQL19AGN1: [hadrag] Resource Alive result 0.Vous pouvez voir qu’il y avait des événements qui n’ont pas été générés au moment de l’expiration du contrôle d’intégrité.
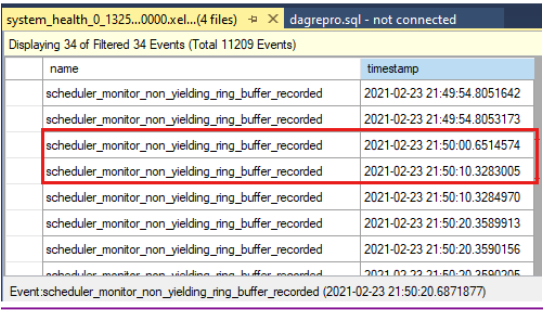
Si des événements qui ne produisent pas de rendement sont détectés, vérifiez la cause de l’événement sans rendement. Envisagez de contacter l’équipe du support technique SQL Server pour examiner les événements sans rendement.
2. Vérifiez le journal des erreurs SQL Server
Consultez le journal des erreurs SQL Server pour connaître la corrélation des événements au moment du délai d’expiration du contrôle d’intégrité. Ces événements peuvent fournir des « miettes de navigation » qui suggèrent des étapes supplémentaires pour étendre la cause racine des délais d’attente de contrôle d’intégrité.
Par exemple, l’entrée de journal suivante montre qu’un délai d’expiration du contrôle d’intégrité s’est produit dans le journal du cluster :
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <SQL19AGN1>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <SQL19AGN1>: [hadrag] Resource Alive result 0.
Dans le journal des erreurs SQL Server, dans les secondes du délai d’expiration du contrôle d’intégrité, SQL Server signale qu’il a détecté une latence d’E/S grave :
2021-02-23 20:49:54.64 spid12s SQL Server has encountered 1 occurrence(s) of I/O requests taking longer than 15 seconds to complete on file [C:\Program Files\Microsoft SQL Server\MSSQL15.MSSQLSERVER\MSSQL\DATA\agdb_log.ldf] in database id 12. The OS file handle is 0x0000000000001594. The offset of the latest long I/O is: 0x000030435b0000. The duration of the long I/O is: 26728 ms.
Passez en revue le journal des événements système pour connaître les indices système possibles susceptibles d’être liés à l’événement de délai d’expiration du contrôle d’intégrité. Lorsque vous passez en revue le journal des événements du système Windows, vous pouvez trouver un problème d’E/S signalé en même temps pour le même délai d’expiration du contrôle d’intégrité :
02/23/2021,08:50:16 PM,Warning,SQL19AGN1.CSSSQL.local.local,<...>,"Reset to device, \Device\<device ID>, was issued."
02/23/2021,08:50:16 PM,Warning,SQL19AGN1.CSSSQL.local.local,<...>,"The IO operation at logical block address <block address> for Disk 6 (PDO name: \Device\<device ID>) was retried."
Intégrité de SQL Server : événement d’intégrité Always On
Always On surveille différents types d’événements d’intégrité SQL Server. Bien qu’il héberge un réplica principal de groupe de disponibilité, SQL Server s’exécute en permanence sp_server_diagnostics qui signale l’intégrité de SQL Server à l’aide de différents composants. Quand des problèmes d’intégrité sont détectés, sp_server_diagnostics signale une erreur pour ce composant particulier, puis renvoie les résultats au processus de détection d’intégrité Always On. Lorsqu’une erreur est signalée, le rôle groupe de disponibilité affiche l’état d’échec et le basculement possible si le groupe de disponibilité est configuré pour ce faire.
Symptômes
Voici un exemple de problème d’intégrité SQL Server, comme indiqué sp_server_diagnostics dans le journal du cluster. SQL Server signale un état d’erreur dans le composant système à la surveillance de l’intégrité Always On, et le groupe de disponibilité « contoso-ag » est passé à un état d’échec.
Note
Un problème d’intégrité SQL Server génère un rapport similaire à celui du délai d’expiration du contrôle d’intégrité. Les deux événements d’intégrité rapportent Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel. La distinction pour un événement d’intégrité SQL Server est qu’il signale que le composant SQL Server est passé de « avertissement » à « erreur ».
INFO [RES] SQL Server Availability Group: [hadrag] SQL Server component 'system' health state has been changed from 'warning' to 'error' at 2019-06-20 15:05:52.330
ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, the state of system component is error
ERR [RES] SQL Server Availability Group <contoso-ag>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
ERR [RES] SQL Server Availability Group <contoso-ag>: [hadrag] Resource Alive result 0.
ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, the state of system component is error
WARN [RHS] Resource contoso-ag IsAlive has indicated failure.
INFO [RCM] HandleMonitorReply: FAILURENOTIFICATION for 'contoso-ag', gen(0) result 1/0.
Diagnostiquer les événements d’intégrité SQL Server
Le type de problème d’intégrité signalé par l’intégrité de SQL Server doit dicter la direction de l’analyse de la cause racine.
Par défaut, lorsque vous déployez un groupe de disponibilité, celui-ci FAILURE_CONDITION_LEVEL est défini sur trois. Cela active la surveillance de certains profils d’intégrité, mais pas tous les profils d’intégrité SQL Server. Au niveau par défaut, Always On déclenche un événement d’intégrité lorsque SQL Server produit trop de fichiers de vidage, une violation d’accès en écriture ou un verrou d’spinlock orphelin. La définition du groupe de disponibilité jusqu’à quatre ou cinq étend les types de problèmes d’intégrité SQL Server surveillés. Pour plus d’informations sur les moniteurs Always On d’intégrité SQL Server, consultez Configurer une stratégie de basculement automatique flexible pour un groupe de disponibilité - SQL Server Always On.
Pour identifier le problème d’intégrité spécifique à Always On, procédez comme suit :
Ouvrez les journaux d’événements étendus de diagnostic du cluster SQL Server sur le réplica principal au moment où l’événement d’intégrité SQL Server suspect s’est produit.
Dans SSMS, accédez à Fichier>Ouvert, puis sélectionnez Fusionner les fichiers d’événements étendus.
Sélectionnez Ajouter.
Dans la boîte de dialogue Ouvrir le fichier, accédez aux fichiers du répertoire SQL Server \LOG.
Appuyez sur Ctrl, sélectionnez les fichiers dont les noms correspondent
<servername>_<instance>_SQLDIAG_xxx.xel, puis sélectionnez Ouvrir>OK.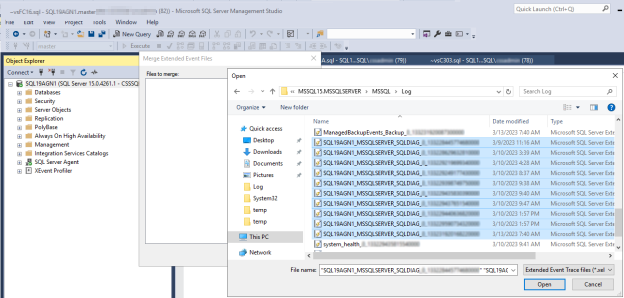
Vous verrez une nouvelle fenêtre à onglets dans SSMS qui inclut les événements étendus, comme illustré dans la capture d’écran suivante.
Pour examiner un problème d’intégrité SQL Server, recherchez la
component_health_resultvaleur dontstate_descla valeur esterror. Voici un exemple d’événement de composant système qui a signalé une erreur à la surveillance de l’intégrité Always On :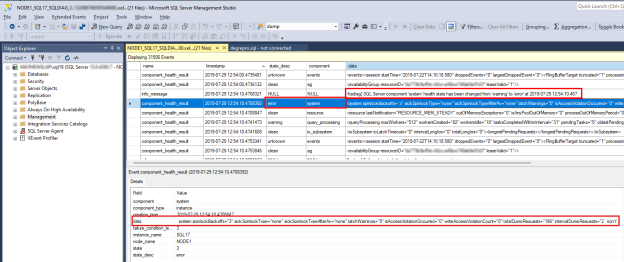
Double-cliquez sur la colonne de données dans le volet inférieur. Cela ouvre les données détaillées des composants dans un nouveau volet de fenêtre SSMS pour révision. Voici à quoi ressemblent les données des composants système :

Notez que les données « totalDumprequests=186 » indiquent qu’il y a eu trop d’événements de diagnostic de fichier de vidage générés sur ce serveur SQL Server. C’est la raison pour laquelle le composant système a signalé un état d’erreur. Lorsque la surveillance de l’intégrité Always On reçoit cet état d’erreur, elle déclenche un événement d’intégrité de groupe de disponibilité. Vous pouvez également vérifier qu’aucune violation d’accès en écriture ou blocages orphelins n’a été détectée à partir des données fournies dans les données du composant système.



Résolution
Selon le type de problème que vous découvrez, vous devez le résoudre en conséquence. Comme l’article Configurer une stratégie de basculement automatique flexible pour un groupe de disponibilité - l’article Sql Server Always On traite des problèmes qui peuvent aboutir à ce problème. Voici quelques exemples :
- Le service SQL Server est fermé.
- Délai d’expiration du bail.
- Le réplica de disponibilité est dans un état d'échec.
- Vidages de mémoire générés par des verrous de spinlocks orphelins, des violations d’accès ou trop de vidages de mémoire générés pendant une courte période.
- Condition de mémoire insuffisante persistante dans le pool de ressources interne SQL Server.
- Détection d’un interblocage de Scheduler.
- Détection d'un blocage insoluble.
S’il est nécessaire, contactez le support SQL Server pour ouvrir un incident de support pour obtenir de l’aide supplémentaire pour trouver la cause racine de ces problèmes d’intégrité SQL Server internes