La machine virtuelle Linux Azure ne parvient pas à démarrer après l’application des modifications du noyau
S’applique à : ✔️ Machines virtuelles Linux
Note
CentOS référencé dans cet article est une distribution Linux et atteint la fin de vie (EOL). Faites le point sur votre utilisation et organisez-vous en conséquence. Pour plus d’informations, consultez les conseils sur la fin de vie centOS.
Cet article fournit des solutions à un problème dans lequel une machine virtuelle Linux ne peut pas démarrer après l’application des modifications du noyau.
Prerequisites
Vérifiez que la console série est activée et fonctionnelle dans la machine virtuelle Linux.
Comment identifier le problème de démarrage lié au noyau
Pour identifier un problème de démarrage lié au noyau, vérifiez la chaîne de panique du noyau spécifique. Pour ce faire, utilisez Azure CLI ou le Portail Azure pour afficher la sortie du journal de la console série de la machine virtuelle dans le volet diagnostics de démarrage ou le volet console série.
Une panique du noyau ressemble à la sortie suivante et s’affiche à la fin du journal de la console série :
Probing EDD (edd=off to disable)... ok
Memory KASLR using RDRAND RDTSC...
[ 300.206297] Kernel panic - xxxxxxxx
[ 300.207216] CPU: 1 PID: 1 Comm: swapper/0 Tainted: G ------------ T 3.xxx.x86_64 #1
Résolution des problèmes en ligne
Conseil
Si vous avez une sauvegarde récente de la machine virtuelle, restaurez la machine virtuelle à partir de la sauvegarde pour résoudre le problème de démarrage.
La console série est la méthode la plus rapide pour résoudre le problème de démarrage. Il vous permet de résoudre directement le problème sans avoir à présenter le disque système à une machine virtuelle de récupération. Veillez à respecter les conditions préalables nécessaires pour votre distribution. Pour plus d’informations, consultez la console série de machines virtuelles pour Linux.
Identifiez le problème de démarrage spécifique lié au noyau.
Utilisez la console série Azure pour interrompre votre machine virtuelle dans le menu GRUB et sélectionnez n’importe quel noyau précédent pour le démarrer. Pour plus d’informations, consultez Le système de démarrage sur une version antérieure du noyau.
Accédez à la section correspondante pour résoudre le problème de démarrage spécifique lié au noyau :
Une fois le problème de démarrage lié au noyau résolu, redémarrez la machine virtuelle pour pouvoir démarrer sur la dernière version du noyau.
Résolution des problèmes hors connexion
Conseil
Si vous avez une sauvegarde récente de la machine virtuelle, restaurez la machine virtuelle à partir de la sauvegarde pour résoudre le problème de démarrage.
Si la console série Azure ne fonctionne pas dans la machine virtuelle spécifique ou n’est pas une option dans votre abonnement, résolvez le problème de démarrage à l’aide d’une machine virtuelle de secours/réparation. Pour ce faire, procédez comme suit :
À l’aide des commandes de réparation de machine virtuelle, créez une machine virtuelle de réparation à laquelle est connectée une copie du disque de système d’exploitation de la machine virtuelle affectée. Montez la copie des systèmes de fichiers du système d’exploitation dans la machine virtuelle de réparation à l’aide de chroot.
Note
Vous pouvez également créer une machine virtuelle de secours manuellement à l’aide du portail Azure. Pour plus d’informations, consultez l’article Résoudre les problèmes d’une machine virtuelle Linux en attachant le disque du système d’exploitation à une machine virtuelle de récupération à l’aide du portail Azure.
Identifiez le problème de démarrage spécifique lié au noyau.
Accédez à la section correspondante pour résoudre le problème de démarrage spécifique lié au noyau :
Une fois le problème de démarrage lié au noyau résolu, effectuez les actions suivantes :
- Quittez chroot.
- Démonter la copie des systèmes de fichiers de la machine virtuelle de secours/réparation.
- Exécutez la commande
az vm repair restorepour remplacer le disque de système d’exploitation réparé par le disque de système d’exploitation d’origine de la machine virtuelle. Pour plus d’informations, consultez l’étape 5 Réparer une machine virtuelle Linux à l’aide des commandes de réparation de machine virtuelle Azure. - Vérifiez si la machine virtuelle peut démarrer. Pour ce faire, examinez la Serial console Azure ou essayez de vous connecter à la machine virtuelle.
S’il existe un contenu important lié au noyau, la partition entière
/bootou d’autres contenus importants sont manquants et ne peuvent pas être récupérés, nous vous recommandons de restaurer la machine virtuelle à partir d’une sauvegarde. Pour plus d’informations, consultez l’article Comment restaurer les données de la machine virtuelle Azure dans le portail Azure.
Système de démarrage sur une version antérieure du noyau
Utiliser la console série Azure
Redémarrez la machine virtuelle à l’aide de la console série Azure.
- Sélectionnez le bouton d’arrêt en haut de la fenêtre de la console série.
- Sélectionnez l’option Redémarrer la machine virtuelle (dur).
Une fois la connexion de la console série reprise, vous verrez un compteur de compte à rebours situé dans le coin supérieur gauche de la fenêtre de la console série. Appuyez sur la touche ESCAPE pour interrompre votre machine virtuelle dans le menu GRUB.
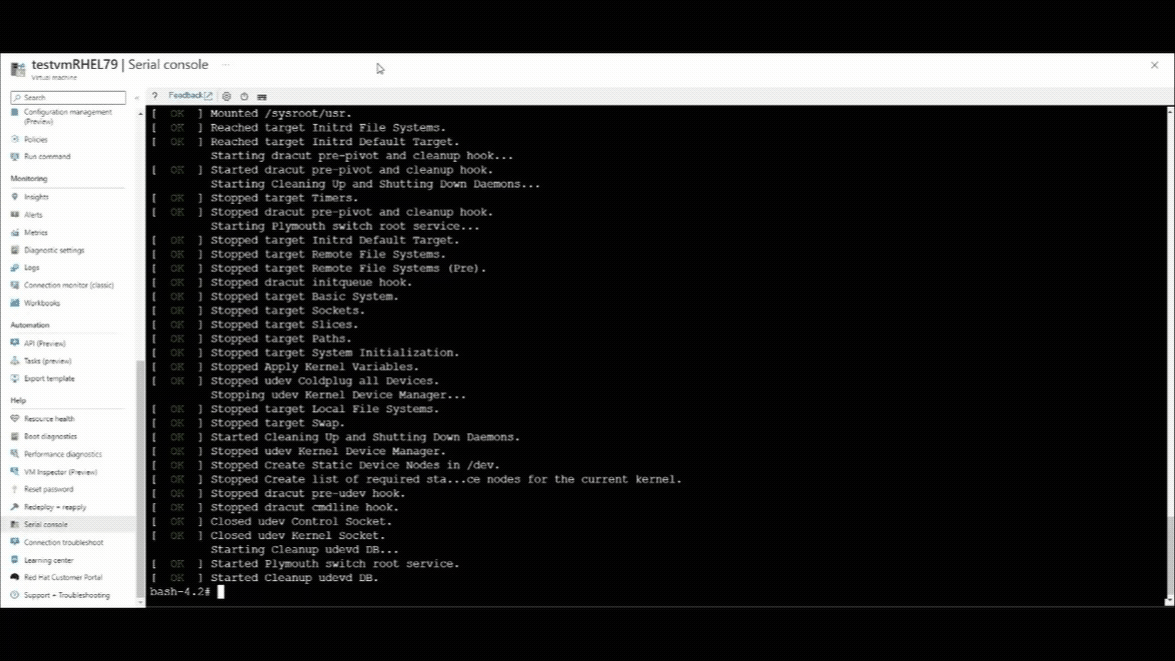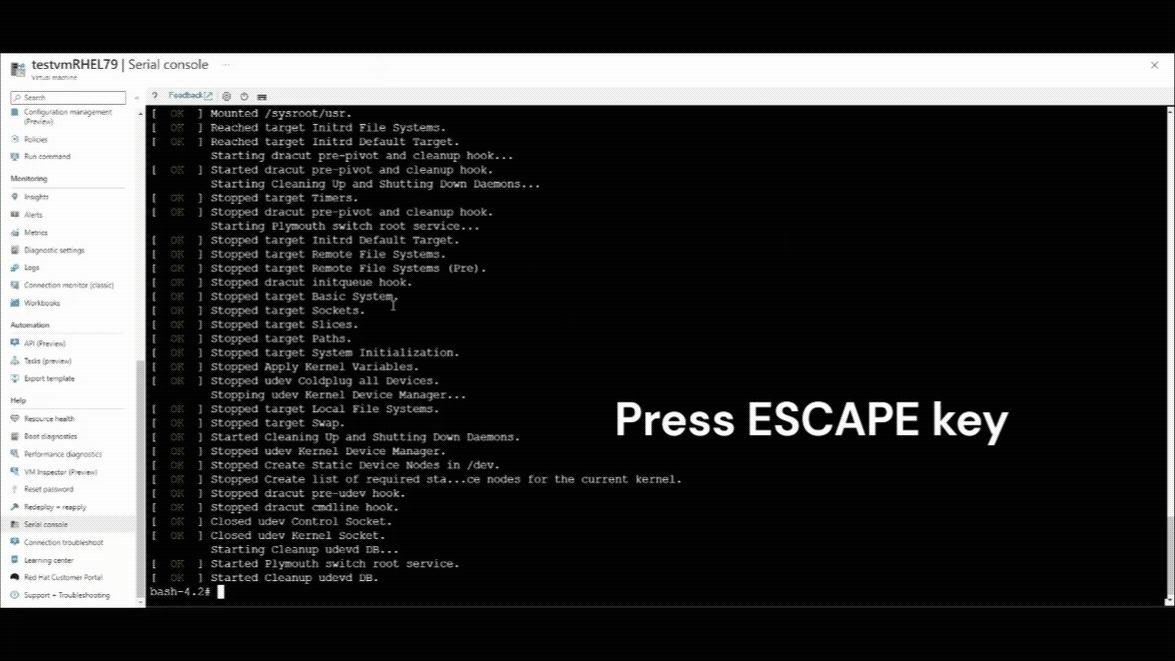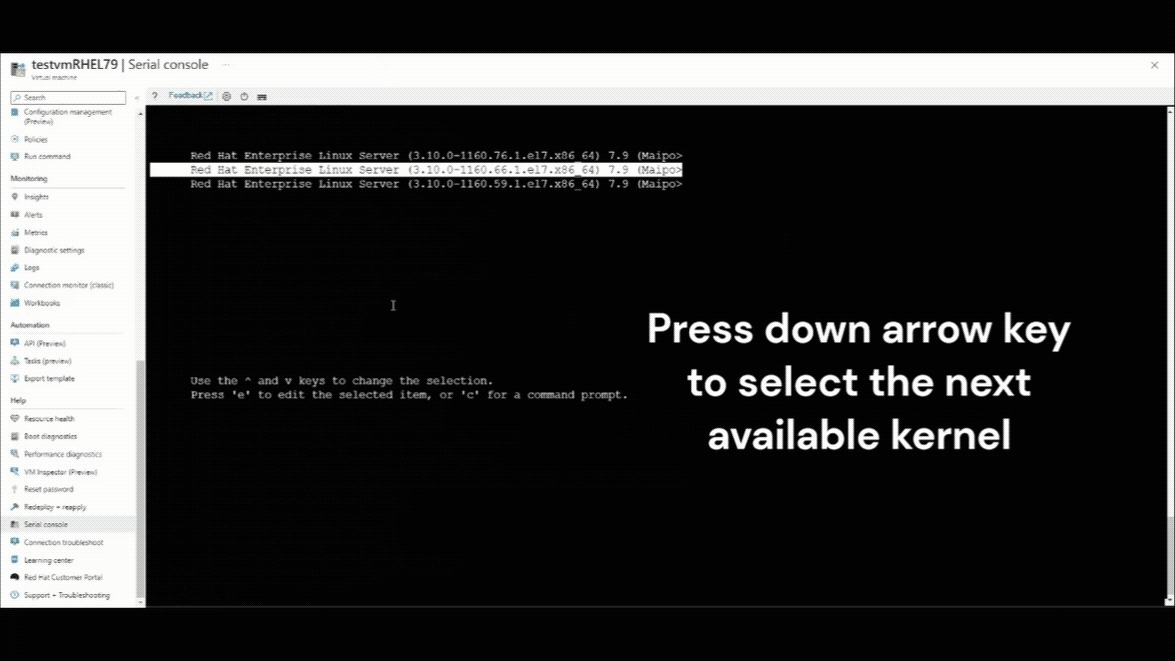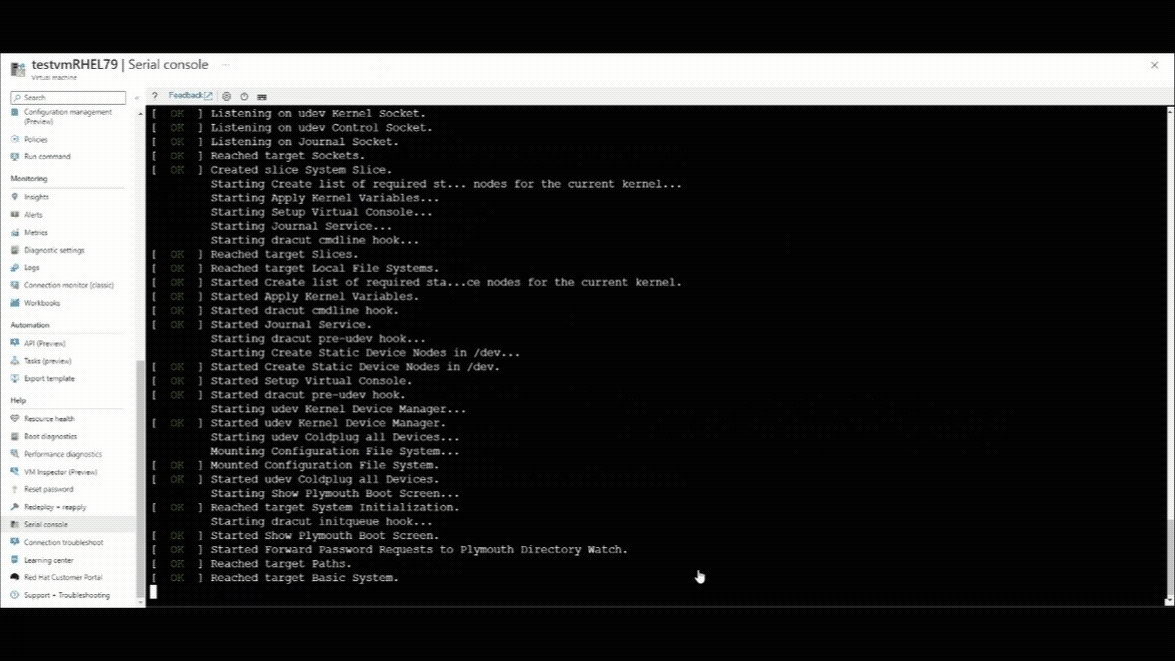
Appuyez sur la flèche vers le bas pour sélectionner n’importe quelle version du noyau précédente.
Modifiez la
GRUB_DEFAULTvariable dans le fichier /etc/default/grub, comme indiqué dans Modifier manuellement la version du noyau par défaut. Il s’agit d’un changement persistant.

Note
S’il n’existe qu’une seule version du noyau répertoriée dans le menu GRUB, suivez l’approche de résolution des problèmes hors connexion pour résoudre ce problème à partir d’une machine virtuelle de réparation.
Utiliser la machine virtuelle de réparation (scripts ALAR)
Exécutez la commande bash suivante dans Azure Cloud Shell pour créer une machine virtuelle de réparation. Pour plus d’informations, consultez Utiliser azure Linux Auto Repair (ALAR) pour corriger une machine virtuelle Linux - option de noyau.
az vm repair create --verbose -g $RGNAME -n $VMNAME --repair-username rescue --repair-password 'password!234' --copy-disk-name repairdiskcopyExécutez la commande suivante pour remplacer le noyau rompu par la version précédemment installée :
az vm repair run --verbose -g $RGNAME -n $VMNAME --run-id linux-alar2 --parameters kernel --run-on-repair az vm repair restore --verbose -g $RGNAME -n $VMNAME
Note
S’il n’existe qu’une seule version du noyau installée dans le système, suivez l’approche de résolution des problèmes hors connexion pour résoudre ce problème à partir d’une machine virtuelle de réparation.
Modifier manuellement la version du noyau par défaut
Pour modifier la version du noyau par défaut à partir d’une machine virtuelle de réparation (à l’intérieur de chroot) ou sur une machine virtuelle en cours d’exécution, procédez comme suit :
Note
Si une restauration de rétrogradation du noyau est effectuée, sélectionnez la version du noyau la plus récente au lieu de l’ancienne.
RHEL 7, Oracle Linux 7 et CentOS 7
Validez la liste des noyaux disponibles dans le fichier de configuration GRUB en exécutant l’une des commandes suivantes :
Machines virtuelles Gen1 :
cat /boot/grub2/grub.cfg | grep menuentryMachines virtuelles Gen2 :
cat /boot/efi/EFI/*/grub.cfg | grep menuentry
Définissez le nouveau noyau par défaut et spécifiez le titre du noyau correspondant en exécutant la commande suivante :
# grub2-set-default 'Red Hat Enterprise Linux Server, with Linux 3.10.0-123.el7.x86_64'Note
Remplacez
Red Hat Enterprise Linux Server, with Linux 3.10.0-123.el7.x86_64par le titre de l’entrée de menu correspondante.Vérifiez que le nouveau noyau par défaut est le noyau souhaité en exécutant la commande suivante :
grub2-editenv listVérifiez que la valeur de la
GRUB_DEFAULTvariable dans le fichier /etc/default/grub est définiesavedsur . Pour le modifier, veillez à régénérer le fichier de configuration GRUB pour appliquer les modifications.
RHEL 8/9 et CentOS 8
Répertoriez les noyaux disponibles en exécutant la commande suivante :
ls -l /boot/vmlinuz-*Définissez le nouveau noyau par défaut en exécutant la commande suivante :
grubby --set-default /boot/vmlinuz-4.18.0-372.19.1.el8_6.x86_64Note
Remplacez
4.18.0-372.19.1.el8_6.x86_64par la version du noyau correspondante.Vérifiez que le nouveau noyau par défaut est le noyau souhaité en exécutant la commande suivante :
grubby --default-kernel
SLES 12/15, Ubuntu 18.04/20.04
Répertoriez les noyaux disponibles dans le fichier de configuration GRUB en exécutant la commande suivante :
Machines virtuelles Gen1 :
SLES 12/15 :
cat /boot/grub2/grub.cfg | grep menuentryUbuntu 18.04/20.04 :
cat /boot/grub/grub.cfg | grep menuentry
Machines virtuelles Gen2 :
cat /boot/efi/EFI/*/grub.cfg | grep menuentry
Définissez le nouveau noyau par défaut en modifiant la valeur de la
GRUB_DEFAULTvariable dans le fichier /etc/default/grub . Pour la version du noyau la plus récente installée dans le système, la valeur par défaut est 0. Le noyau disponible suivant est défini sur « 1>2 ».vi /etc/default/grub GRUB_DEFAULT="1>2"Note
Pour plus d’informations sur la configuration de la
GRUB_DEFAULTvariable, consultez SUSE Boot Loader GRUB2 et Ubuntu Grub2/Setup. En guise de référence : la valeur menuentry de niveau supérieur est 0, la première valeur de sous-menu de niveau supérieur est 1, et chaque valeur de menuentry imbriquée commence par 0. Par exemple, « 1>2 » est la troisième menuentry du premier sous-menu.Régénérez le fichier de configuration GRUB pour appliquer les modifications. Suivez les instructions de Réinstaller GRUB et régénérer le fichier de configuration GRUB pour la distribution Linux et la génération de machine virtuelle correspondantes.
Panique du noyau - pas de synchronisation : VFS : Impossible de monter la racine fs sur unknown-block(0,0)
Cette erreur se produit en raison d’une mise à jour système récente (noyau). Il est le plus souvent vu dans les distributions basées sur RHEL. Vous pouvez identifier ce problème à partir de la console série Azure. Vous verrez l’un des messages d’erreur suivants :
« Panique du noyau - pas de synchronisation : VFS : Impossible de monter les fs racines sur unknown-block(0,0) »
[ 301.026129] Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0) [ 301.027122] CPU: 0 PID: 1 Comm: swapper/0 Tainted: G ------------ T 3.10.0-1160.36.2.el7.x86_64 #1 [ 301.027122] Hardware name: Microsoft Corporation Virtual Machine/Virtual Machine, BIOS 090008 12/07/2018 [ 301.027122] Call Trace: [ 301.027122] [<ffffffff82383559>] dump_stack+0x19/0x1b [ 301.027122] [<ffffffff8237d261>] panic+0xe8/0x21f [ 301.027122] [<ffffffff8298b794>] mount_block_root+0x291/0x2a0 [ 301.027122] [<ffffffff8298b7f6>] mount_root+0x53/0x56 [ 301.027122] [<ffffffff8298b935>] prepare_namespace+0x13c/0x174 [ 301.027122] [<ffffffff8298b412>] kernel_init_freeable+0x222/0x249 [ 301.027122] [<ffffffff8298ab28>] ? initcall_blcklist+0xb0/0xb0 [ 301.027122] [<ffffffff82372350>] ? rest_init+0x80/0x80 [ 301.027122] [<ffffffff8237235e>] kernel_init+0xe/0x100 [ 301.027122] [<ffffffff82395df7>] ret_from_fork_nospec_begin+0x21/0x21 [ 301.027122] [<ffffffff82372350>] ? rest_init+0x80/0x80 [ 301.027122] Kernel Offset: 0xc00000 from 0xffffffff81000000 (relocation range: 0xffffffff80000000-0xffffffffbfffffff)« error : file '/initramfs-*.img' introuvable »
erreur : fichier '/initramfs-3.10.0-1160.36.2.el7.x86_64.img' introuvable.
Ce type d’erreur indique que le fichier initramfs n’est pas généré, le fichier de configuration GRUB contient l’entrée d’initrd manquante après un processus de mise à jour corrective ou une configuration incorrecte manuelle GRUB.
Avant de redémarrer un serveur, nous vous recommandons de valider la configuration et /boot le contenu GRUB s’il existe une mise à jour du noyau en exécutant l’une des commandes suivantes. Il est important de s’assurer que la mise à jour est effectuée et qu’il n’y a pas de fichiers initramfs manquants.
BIOS - Systèmes Gen1
# ls -l /boot # cat /boot/grub2/grub.cfgBasé sur UEFI - Systèmes Gen2
# ls -l /boot # cat /boot/efi/EFI/*/grub.cfg
Régénérer les initramfs manquants à l’aide de scripts ALAR de machine virtuelle de réparation Azure
Créez une machine virtuelle de réparation en exécutant la ligne de commande Bash suivante avec Azure Cloud Shell. Pour plus d’informations, consultez Utiliser azure Linux Auto Repair (ALAR) pour corriger une machine virtuelle Linux - option initrd.
az vm repair create --verbose -g $RGNAME -n $VMNAME --repair-username rescue --repair-password 'password!234' --copy-disk-name repairdiskcopyRégénérez l’image initrd/initramfs et régénérez le fichier de configuration GRUB s’il contient l’entrée initrd manquante. Pour ce faire, exécutez la commande suivante :
az vm repair run --verbose -g $RGNAME -n $VMNAME --run-id linux-alar2 --parameters initrd --run-on-repair az vm repair restore --verbose -g $RGNAME -n $VMNAMEUne fois la commande de restauration exécutée, redémarrez la machine virtuelle d’origine et vérifiez qu’elle est en mesure de démarrer.
Régénérer manuellement les initramfs manquants
Important
- Si vous êtes en mesure de démarrer la machine virtuelle à l’aide d’une version précédente du noyau ou à l’intérieur de chroot à partir de la machine virtuelle de réparation/sauvetage, régénérez manuellement les initramfs manquants.
- Pour régénérer manuellement les initramfs manquants à partir d’une machine virtuelle de réparation, assurez-vous que l’étape 1 de la résolution des problèmes hors connexion a déjà été suivie et que ces commandes sont exécutées à l’intérieur de chroot.
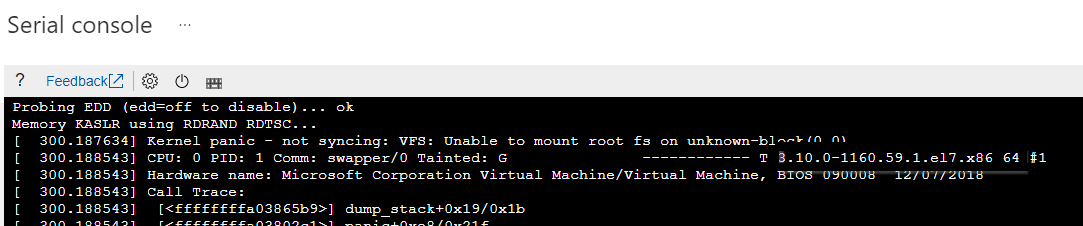
Identifiez la version spécifique du noyau qui rencontre des problèmes de démarrage. Vous pouvez extraire les informations de version de l’erreur de panique du noyau correspondante.
Reportez-vous à la capture d’écran suivante comme exemple. L’erreur de panique du noyau indique que la version du noyau est « 3.10.0-1160.59.1.el7.x86_64 » :
Régénérez le fichier initramfs manquant en exécutant l’une des commandes suivantes :
RHEL/CentOS/Oracle Linux 7/8
sudo depmod -a 3.10.0-1160.59.1.el7.x86_64 sudo dracut -f /boot/initramfs-3.10.0-1160.59.1.el7.x86_64.img 3.10.0-1160.59.1.el7.x86_64Important
Remplacez
3.10.0-1160.59.1.el7.x86_64par la version du noyau correspondante.SLES 12/15
sudo depmod -a 5.3.18-150300.38.53-azure sudo dracut -f /boot/initrd-5.3.18-150300.38.53-azure 5.3.18-150300.38.53-azureImportant
Remplacez
5.3.18-150300.38.53-azurepar la version du noyau correspondante.Ubuntu 18.04
sudo depmod -a 5.4.0-1077-azure sudo mkinitramfs -k -o /boot/initrd.img-5.4.0-1077-azureImportant
Remplacez
5.4.0-1077-azurepar la version du noyau correspondante.
Régénérer le fichier de configuration GRUB. Suivez les instructions fournies dans Réinstaller GRUB et régénérer le fichier de configuration GRUB pour la distribution Linux et la génération de machine virtuelle correspondantes
Si les étapes ci-dessus sont effectuées à partir d’une machine virtuelle de réparation, suivez l’étape 3 dans la résolution des problèmes hors connexion. Si les étapes ci-dessus sont effectuées à partir de la console série Azure, suivez la méthode de résolution des problèmes en ligne.
Redémarrez votre machine virtuelle sur la version du noyau la plus récente.
Panique du noyau - pas de synchronisation : tentative de tuer l’init
Identifiez ce problème à partir de la console série Azure. Vous verrez la sortie comme suit :
dracut Warning: Boot has failed. To debug this issue add "rdshell" to the kernel command line.
Kernel panic - not syncing: Attempted to kill init!
Pid: 1, comm: init Not tainted 2.6.32-754.17.1.el6.x86_64 #1
Call Trace:
[<ffffffff81558bfa>] ? panic+0xa7/0x18b
[<ffffffff81130370>] ? perf_event_exit_task+0xc0/0x340
[<ffffffff81086433>] ? do_exit+0x853/0x860
[<ffffffff811a33b5>] ? fput+0x25/0x30
[<ffffffff81564272>] ? system_call_after_swapgs+0xa2/0x152
[<ffffffff81086498>] ? do_group_exit+0x58/0xd0
[<ffffffff81086527>] ? sys_exit_group+0x17/0x20
[<ffffffff81564357>] ? system_call_fastpath+0x35/0x3a
[<ffffffff8156427e>] ? system_call_after_swapgs+0xae/0x152
Ce type de panique du noyau se produit en raison des causes possibles suivantes :
Consultez les sections suivantes pour connaître les détails de la cause et les solutions. Vérifiez que les commandes sont exécutées à partir d’une machine virtuelle de réparation/sauvetage dans un environnement chroot, comme indiqué dans la résolution des problèmes hors connexion.
Fichiers et répertoires importants manquants
Les fichiers et répertoires Linux importants sont manquants en raison d’une erreur humaine. Par exemple, les fichiers sont supprimés accidentellement ou la corruption du système de fichiers.
Validez le contenu du disque du système d’exploitation après avoir attaché la copie du disque du système d’exploitation à une machine virtuelle de réparation et monté les systèmes de fichiers correspondants à l’aide de chroot. Vous pouvez comparer les sorties avec celles d’une machine virtuelle opérationnelle exécutant la même version du système d’exploitation.
ls -l / ls -l /usr/lib ls -l /usr/lib64 ls -lR / | moreRestaurez les fichiers manquants à partir d’une sauvegarde. Pour plus d’informations, consultez Récupérer des fichiers à partir de la sauvegarde de machine virtuelle Azure. Selon le nombre de fichiers manquants, il peut être préférable d’effectuer une restauration complète de machine virtuelle. Pour plus d’informations, consultez l’article Comment restaurer les données de la machine virtuelle Azure dans le portail Azure.
Bibliothèques et packages principaux système manquants
Les bibliothèques, fichiers ou packages système importants sont supprimés du système ou endommagés. Pour résoudre ce problème, réinstallez les bibliothèques, fichiers ou packages concernés. Cette solution fonctionne sur des distributions basées sur RPM comme les machines virtuelles Red Hat/CentOS/SUSE. Pour les autres distributions Linux, nous vous recommandons de restaurer la machine virtuelle à partir de la sauvegarde.
Pour effectuer la réinstallation, procédez comme suit :
Créez une machine virtuelle de secours à l’aide d’une image brute avec la même version et la même génération de système d’exploitation que la machine virtuelle affectée.
Accédez à l’environnement chroot dans la machine virtuelle de secours pour résoudre le problème.
sudo chroot /rescueLa sortie de commande indique la bibliothèque manquante ou endommagée, comme indiqué ci-dessous :
/bin/bash: error while loading shared libraries: libc.so.6: cannot open shared object file: No such file or directoryVérifiez tous les packages système et leur état correspondant dans la machine virtuelle de secours. Comparez la sortie à une machine virtuelle saine exécutant la même version du système d’exploitation.
sudo rpm --verify --all --root=/rescueVoici un exemple de sortie de la commande :
error: Failed to dlopen /usr/lib64/rpm-plugins/systemd_inhibit.so /lib64/librt.so.1: undefined symbol: __pthread_attr_copy, version GLIBC_PRIVATE S.5....T. c /etc/dnf/dnf.conf S.5....T. c /etc/ssh/sshd_config .M....... /boot/efi/EFI/BOOT/BOOTX64.EFI .M....... /boot/efi/EFI/BOOT/fbx64.efi .M....... /boot/efi/EFI/redhat/BOOTX64.CSV .M....... /boot/efi/EFI/redhat/mmx64.efi .M....... /boot/efi/EFI/redhat/shimx64-redhat.efi .M....... /boot/efi/EFI/redhat/shimx64.efi missing /run/motd.d .M....... g /var/spool/anacron/cron.daily .M....... g /var/spool/anacron/cron.monthly .M....... g /var/spool/anacron/cron.weekly missing /lib64/libc-2.28.so <------- .M....... /boot/efi/EFI/redhat S.5....T. c /etc/security/pwquality.confLa ligne
missing /lib64/libc-2.28.sode sortie est liée à l’erreur précédente à l’étape 2, et indique que le package libc-2.28.so est manquant. Toutefois, le package libc-2.28.so peut être modifié. Dans ce cas, la sortie s’affiche.M.....au lieu demissing. Le package libc-2.28.so est référencé comme exemple dans les étapes suivantes.Dans la machine virtuelle de secours, vérifiez quel package contient la bibliothèque /lib64/libc-2.28.so.
sudo rpm -qf /lib64/libc-2.28.soglibc-2.28-127.0.1.el8.x86_64Note
La sortie affiche le package qui doit être réinstallé, y compris le nom et la version du package. La version du package peut être différente de celle installée sur la machine virtuelle affectée.
Dans la machine virtuelle affectée, vérifiez la version du package glibc installée.
sudo rpm -qa --all --root=/rescue | grep -i glibcglibc-common-2.28-211.0.1.el8.x86_64 glibc-gconv-extra-2.28-211.0.1.el8.x86_64 glibc-2.28-211.0.1.el8.x86_64 <---- glibc-langpack-en-2.28-211.0.1.el8.x86_64Téléchargez le package glibc-2.28-211.0.1.el8.x86_64. Vous pouvez le télécharger à partir du site web officiel du fournisseur du système d’exploitation ou à partir de la machine virtuelle de secours à l’aide d’un outil de gestion de package comme
yumdownloaderouzypper install --download-only <packagename>selon le système d’exploitation que vous exécutez.Voici un exemple d’utilisation de l’outil
yumdownloader:cd /tmp sudo yumdownloader glibc-2.28-211.0.1.el8.x86_64Last metadata expiration check: 0:03:24 ago on Thu 25 May 2023 02:36:25 PM UTC. glibc-2.28-211.0.1.el8.x86_64.rpm 8.7 MB/s | 2.2 MB 00:00Réinstallez le package affecté dans la machine virtuelle de secours.
sudo rpm -ivh --root=/rescue /tmp/glibc-*.rpm --replacepkgs --replacefileswarning: /tmp/glibc-2.28-211.0.1.el8.x86_64.rpm: Header V3 RSA/SHA256 Signature, key ID ad986da3: NOKEY Verifying... ################################# [100%] Preparing... ################################# [100%] Updating / installing... 1:glibc-2.28-211.0.1.el8 ################################# [100%]Accédez à l’environnement chroot dans la machine virtuelle de secours pour valider la réinstallation.
sudo chroot /rescueDésactivez la machine virtuelle de secours et échangez le disque du système d’exploitation vers la machine virtuelle affectée.
Autorisations de fichier incorrectes
Les autorisations de fichiers à l’échelle du système incorrectes sont modifiées en raison d’une erreur humaine (par exemple, une personne s’exécute chmod 777 sur / ou d’autres systèmes de fichiers de système d’exploitation importants). Pour résoudre ce problème, restaurez les autorisations de fichier. Cette solution fonctionne sur des distributions basées sur RPM comme les machines virtuelles Red Hat/CentOS/SUSE. Pour les autres distributions Linux, nous vous recommandons de restaurer la machine virtuelle à partir de la sauvegarde.
Pour restaurer les autorisations de fichier, exécutez la commande suivante après avoir attaché la copie du disque du système d’exploitation à une machine virtuelle de réparation et monté les systèmes de fichiers correspondants à l’aide de chroot :
rpm -a --setperms
rpm --setugids --all
chmod u+s /bin/sudo
chmod 660 /etc/sudoers.d/*
chmod 644 /etc/ssh/*.pub
chmod 640 /etc/ssh/*.key
Note
N’exécutez pas cette commande sur les systèmes de production en cours d’exécution.
Si le problème existe toujours après avoir récupéré manuellement les autorisations de fichier correspondantes, effectuez une restauration à partir de la sauvegarde.
Partitions manquantes
Dans les cas où /usr, , /opt, /var/home, /tmpet / les systèmes de fichiers sont répartis entre différentes partitions, les données peuvent être inaccessibles en raison de problèmes au niveau des partitions, ce qui peut être dû à des erreurs lors des opérations de redimensionnement de partition ou d’autres personnes.
Dans ce scénario, si vous documentez la disposition de la table de partition d’origine, avec les secteurs de début et de fin exacts pour chacune des partitions d’origine, et aucune autre modification n’est effectuée sur le système, comme la création de nouveaux systèmes de fichiers, recréez les partitions à l’aide de la même disposition d’origine avec des outils tels que fdisk (pour les tables de partitions MBR) ou gdisk (pour les tables de partition GPT) pour accéder au système de fichiers manquant.
Si cette approche ne fonctionne pas, effectuez une restauration à partir de la sauvegarde.
Problèmes SELinux
Les autorisations SELinux incorrectes peuvent empêcher le système d’accéder à des fichiers importants. Pour résoudre ce problème, effectuez les étapes suivantes :
Pour vérifier si le système rencontre des problèmes en raison d’autorisations SELinux incorrectes, démarrez le système avec SELinux désactivé en ajoutant l’option de noyau selinux=0 à la ligne GRUB linux16.
Si le système est en mesure de démarrer, exécutez la commande suivante pour déclencher un relabel SELinux au moment du démarrage et redémarrer le système :
touch /.autorelabelSi la machine virtuelle ne peut toujours pas démarrer, effectuez une restauration complète de la machine virtuelle à partir de la sauvegarde. Pour plus d’informations, consultez l’article Comment restaurer les données de la machine virtuelle Azure dans le portail Azure.
Autres problèmes de démarrage liés au noyau
Cet article décrit les paniques de noyau Linux les plus courantes identifiées dans Azure. Pour plus d’informations sur les scénarios courants de panique du noyau, consultez La panique du noyau dans les machines virtuelles Linux Azure - Événements de panique de noyau courants.
Il existe d’autres paniques importantes possibles du noyau qui peuvent entraîner aucun démarrage ni aucun scénario SSH (Secure Shell).
Veillez à exécuter toutes les commandes d’une machine virtuelle de réparation à l’intérieur d’un environnement chroot, comme indiqué dans la résolution des problèmes hors connexion. Si le système est déjà démarré sur une version précédente du noyau, ces commandes peuvent également être exécutées à partir de la machine virtuelle d’origine à l’aide de privilèges racines ousudo, comme indiqué dans la résolution des problèmes en ligne.
Mise à niveau récente du noyau
Si le noyau panique après une mise à niveau récente du noyau, démarrez la machine virtuelle sur la version précédente du noyau. Pour plus d’informations, consultez Le système de démarrage sur une version antérieure du noyau.
Vous pouvez également vérifier s’il existe déjà une version de noyau plus récente publiée par le fournisseur de distribution Linux et l’installer. Pour plus d’informations sur l’installation de la dernière version du noyau, consultez le processus de mise à jour du noyau.
Rétrogradation récente du noyau
Si le noyau panique après une rétrogradation récente du noyau, revenez au noyau installé le plus récent. Vous pouvez également vérifier s’il existe déjà une version de noyau plus récente publiée par le fournisseur de distribution Linux et l’installer. Pour plus d’informations sur l’installation de la dernière version du noyau, consultez le processus de mise à jour du noyau.
Pour démarrer le système sur la version du noyau la plus récente, suivez les instructions de Modification manuelle de la version du noyau par défaut, mais sélectionnez le premier noyau répertorié dans le menu GRUB. Dans une modification manuelle, vous pouvez définir la GRUB_DEFAULT valeur sur 0 et régénérer le fichier de configuration GRUB correspondant.
Modifications apportées au module noyau
Vous pouvez rencontrer une panique de noyau liée à un nouveau module de noyau ou à un module de noyau manquant. Pour obtenir des détails sur le module de noyau spécifique qui provoque des problèmes (le cas échéant), vérifiez la trace de panique du noyau correspondante.
Pour valider les modules de noyau chargés et les modules désactivés dans les fichiers /etc/modprobe.d/*.conf , exécutez l’une des commandes suivantes :
RHEL/CentOS/Oracle Linux 7/8
lsinitrd /boot/initramfs-3.10.0-1160.59.1.el7.x86_64.img lsmod cat /etc/modprobe.d/*.confImportant
Remplacez
3.10.0-1160.59.1.el7.x86_64par la version du noyau correspondante.SLES 12/15
lsinitrd /boot/initrd-5.3.18-150300.38.53-azure lsmod cat /etc/modprobe.d/*.confImportant
Remplacez
5.3.18-150300.38.53-azurepar la version du noyau correspondante.Ubuntu 18.04
lsinitramfs /boot/initrd.img-5.4.0-1077-azure lsmod cat /etc/modprobe.d/*.confImportant
Remplacez
5.4.0-1077-azurepar la version du noyau correspondante.
Pour supprimer un module de noyau spécifique, exécutez la commande suivante et régénérez les initramfs si nécessaire.
rmmod <kernel_module_name>
Si un service système utilise le module de noyau spécifique, désactivez-le en exécutant la ou systemctl stop <serviceName> la systemctl disable <serviceName> commande.
Modifications récentes de configuration du système d’exploitation
Identifiez les modifications récentes de configuration du noyau susceptibles de provoquer des problèmes. Pour résoudre les problèmes, ajustez ces paramètres ou restaurez les modifications de configuration.
Exécutez la commande suivante pour rechercher les paramètres de noyau persistant configurés dans l’un des fichiers suivants :
cat /etc/systctl.conf
cat /etc/sysctl.d/*
Exécutez la commande suivante pour analyser les paramètres de noyau actuels et leurs valeurs actuelles :
sysctl -a
Note
Exécutez cette commande sur un système en cours d’exécution et non à partir d’un environnement chroot.
Fichiers manquants possibles
Pour plus d’informations sur ce type de problème, consultez Fichiers et répertoires importants manquants.
Autorisations incorrectes sur les fichiers
Pour plus d’informations sur ce type de problème, consultez Autorisations de fichier incorrectes.
Partitions manquantes
Pour plus d’informations sur ce type de problème, consultez Partitions manquantes.
Bogues du noyau
Identifiez ce problème à partir de la console série Azure. Ce type de problème se présente comme la sortie suivante :
[5275698.017004] kernel BUG at XXX/YYY.c:72!
[5275698.017004] invalid opcode: 0000 [#1] SMP
Ce type de panique de noyau est associé à des bogues de noyau ou à des bogues de noyau tiers.
Pour résoudre les bogues du noyau, recherchez la base de connaissances du fournisseur à l’aide de la chaîne BUG du noyau et recherchez les problèmes connus dans la version correspondante du noyau que votre système exécute. Voici quelques ressources de fournisseur importantes :
Analyseur Oops du noyau Red Hat
Cet outil est conçu pour vous aider à diagnostiquer un incident du noyau. Lorsque vous entrez un texte, vmcore-dmesg.txt ou un fichier incluant un ou plusieurs messages d’oops de noyau, il vous guide tout au long du diagnostic du problème d’incident du noyau.
-
Pour accéder aux ressources Red Hat, liez vos comptes Microsoft Azure et Red Hat. Pour plus d’informations, consultez Comment les clients Microsoft Azure peuvent accéder au portail client Red Hat.
Nous vous recommandons de maintenir tous vos systèmes à jour pour éliminer les bogues éventuels déjà résolus dans les versions de noyau les plus récentes. Pour plus d’informations, consultez Processus de mise à jour du noyau.
Si une analyse plus approfondie est requise de la part du fournisseur, configurez et activez kdump pour générer un vidage du noyau :
- Configuration de kdump dans les machines virtuelles Red Hat.
- Configuration du vidage sur incident du noyau dans les machines virtuelles Ubuntu.
- Configuration du vidage du cœur du noyau dans les machines virtuelles SLES
Processus de mise à jour du noyau
Pour installer la dernière version du noyau disponible, exécutez l’une des commandes suivantes :
RHEL/CentOS/Oracle Linux
yum update kernelSLES 12/15
zypper refresh zypper update kernel*Ubuntu 18.04/20.04
apt update apt install linux-azure
Pour réinstaller une version spécifique du noyau, exécutez l’une des commandes suivantes. Assurez-vous que vous n’êtes pas démarré sur la même version du noyau que vous essayez de réinstaller. Pour plus d’informations, consultez Le système de démarrage sur une version antérieure du noyau.
RHEL/CentOS/Oracle Linux
yum reinstall kernel-3.10.0-1160.59.1.el7.x86_64Important
Remplacez
3.10.0-1160.59.1.el7.x86_64par la version du noyau correspondante.SLES 12/15
zypper refresh zypper install -f kernel-azure-5.3.18-150300.38.75.1.x86_64Important
Remplacez
kernel-azure-5.3.18-150300.38.75.1.x86_64par la version du noyau correspondante.Ubuntu 18.04/20.04
apt update apt install --reinstall linux-azure=5.4.0.1091.68Important
Remplacez
5.4.0.1091.68par la version du noyau correspondante.
Pour mettre à jour le système et appliquer les dernières modifications disponibles, exécutez l’une des commandes suivantes :
RHEL/CentOS/Oracle Linux
yum updateSLES 12/15
zypper refresh zypper updateUbuntu 18.04/20.04
apt update apt upgrade
Les paniques du noyau peuvent être liées à l’un des éléments suivants. Pour plus d’informations, consultez Paniques du noyau au moment de l’exécution.
- Modifications de charge de travail d’application.
- Bogues d’application ou de développement d’applications.
- Problèmes liés aux performances, et ainsi de suite.
Prochaines étapes
Si l’erreur de démarrage spécifique n’est pas un problème de démarrage lié au noyau, consultez Résoudre les erreurs de démarrage d’Azure Linux Machines Virtuelles pour obtenir d’autres options de résolution des problèmes.
Contactez-nous pour obtenir de l’aide
Pour toute demande ou assistance, créez une demande de support ou posez une question au support de la communauté Azure. Vous pouvez également soumettre des commentaires sur les produits à la communauté de commentaires Azure.