Créer des tables delta
Spark est une infrastructure de traitement parallèle, avec des données stockées sur un ou plusieurs nœuds Worker. De plus, les fichiers Parquet sont immuables, avec de nouveaux fichiers écrits pour chaque mise à jour ou suppression. Avec ce processus, Spark peut stocker les données dans un grand nombre de petits fichiers, ce qu’on appelle le problème de petits fichiers. Cela signifie que les requêtes sur de grandes quantités de données peuvent s’exécuter lentement, voire échouer.
Fonction OptimizeWrite
OptimizeWrite est une fonctionnalité de Delta Lake qui réduit le nombre de fichiers au fur et à mesure qu’ils sont écrits. Au lieu d’écrire un grand nombre de petits fichiers, il écrit un petit nombre de fichiers plus volumineux. Cela permet d’éviter le problème de petits fichiers et de s’assurer que les performances ne sont pas détériorées.
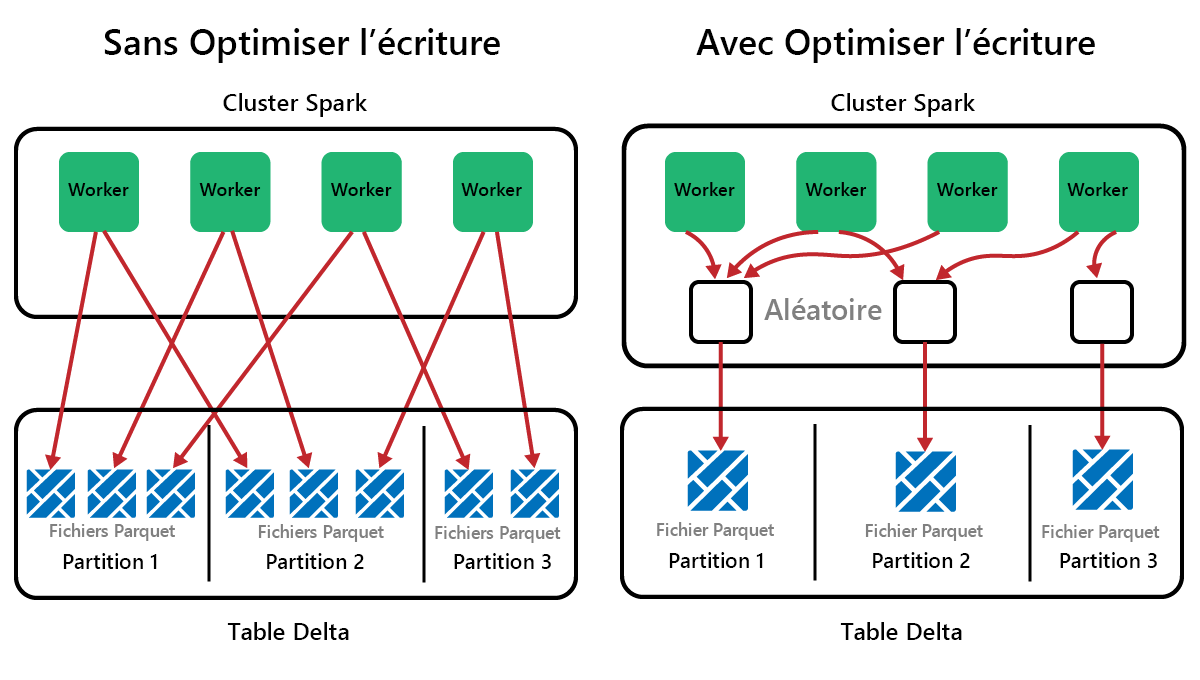
Dans Microsoft Fabric, OptimizeWrite est activé par défaut. Vous pouvez l’activer ou le désactiver au niveau de la session Spark :
# Disable Optimize Write at the Spark session level
spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", False)
# Enable Optimize Write at the Spark session level
spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", True)
print(spark.conf.get("spark.microsoft.delta.optimizeWrite.enabled"))
Remarque
OptimizeWrite peut également être défini dans propriétés de table et pour des commandes d’écriture individuelles.
Optimize
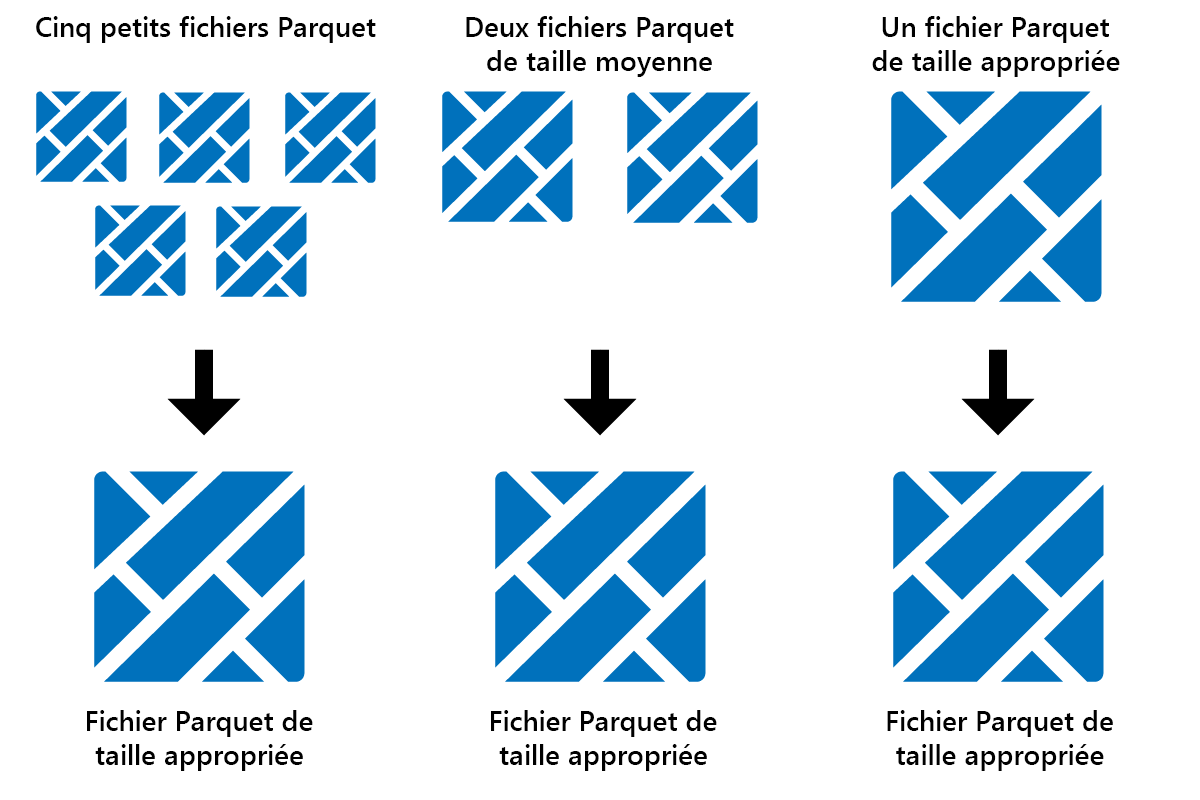
Optimize est une fonctionnalité de maintenance de table qui consolide les petits fichiers Parquet en moins de fichiers volumineux. Vous pouvez exécuter Optimize après le chargement de tables volumineuses, ce qui entraîne :
- moins de fichiers plus volumineux
- meilleure compression
- distribution efficace des données entre les nœuds
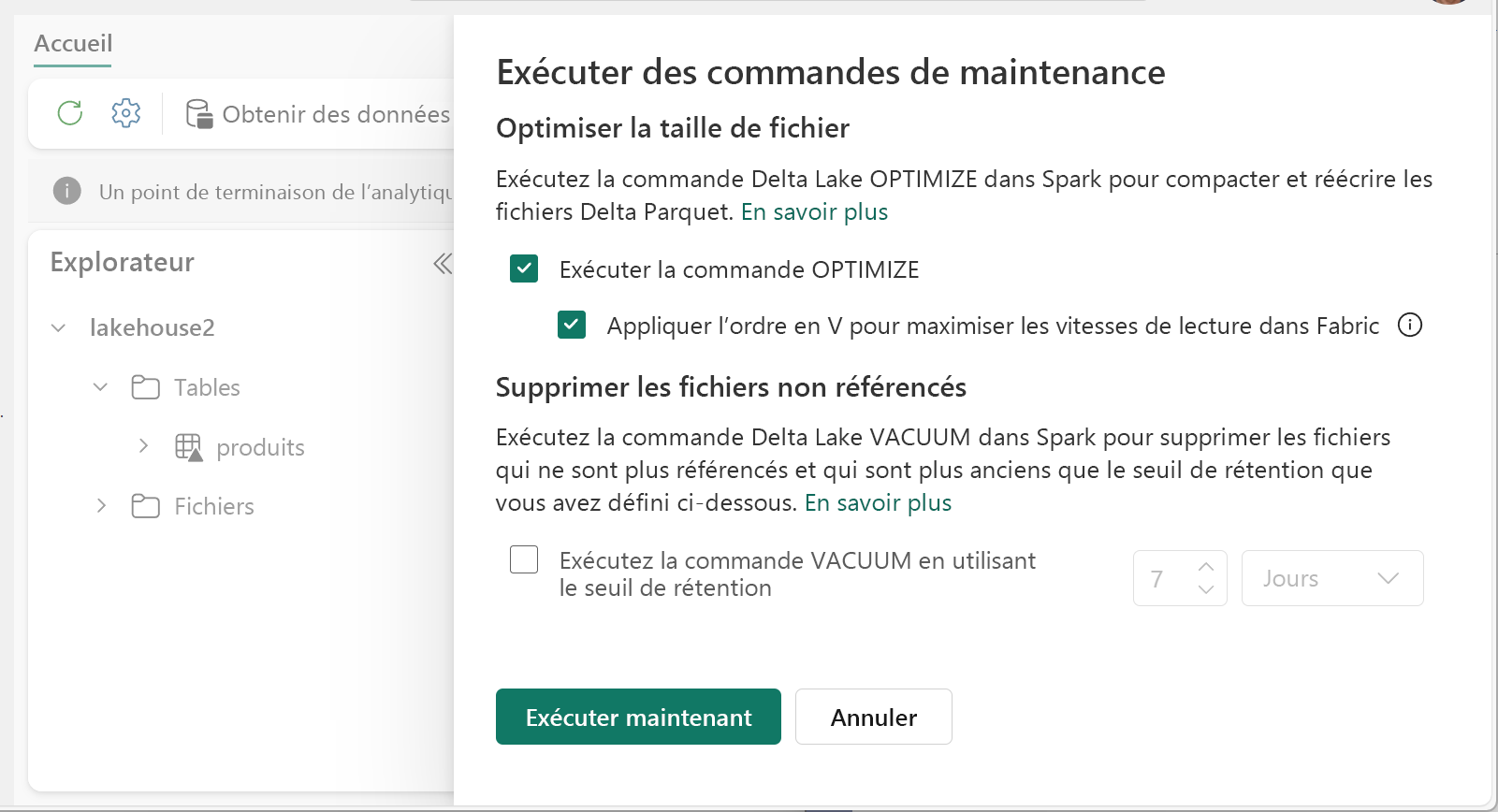
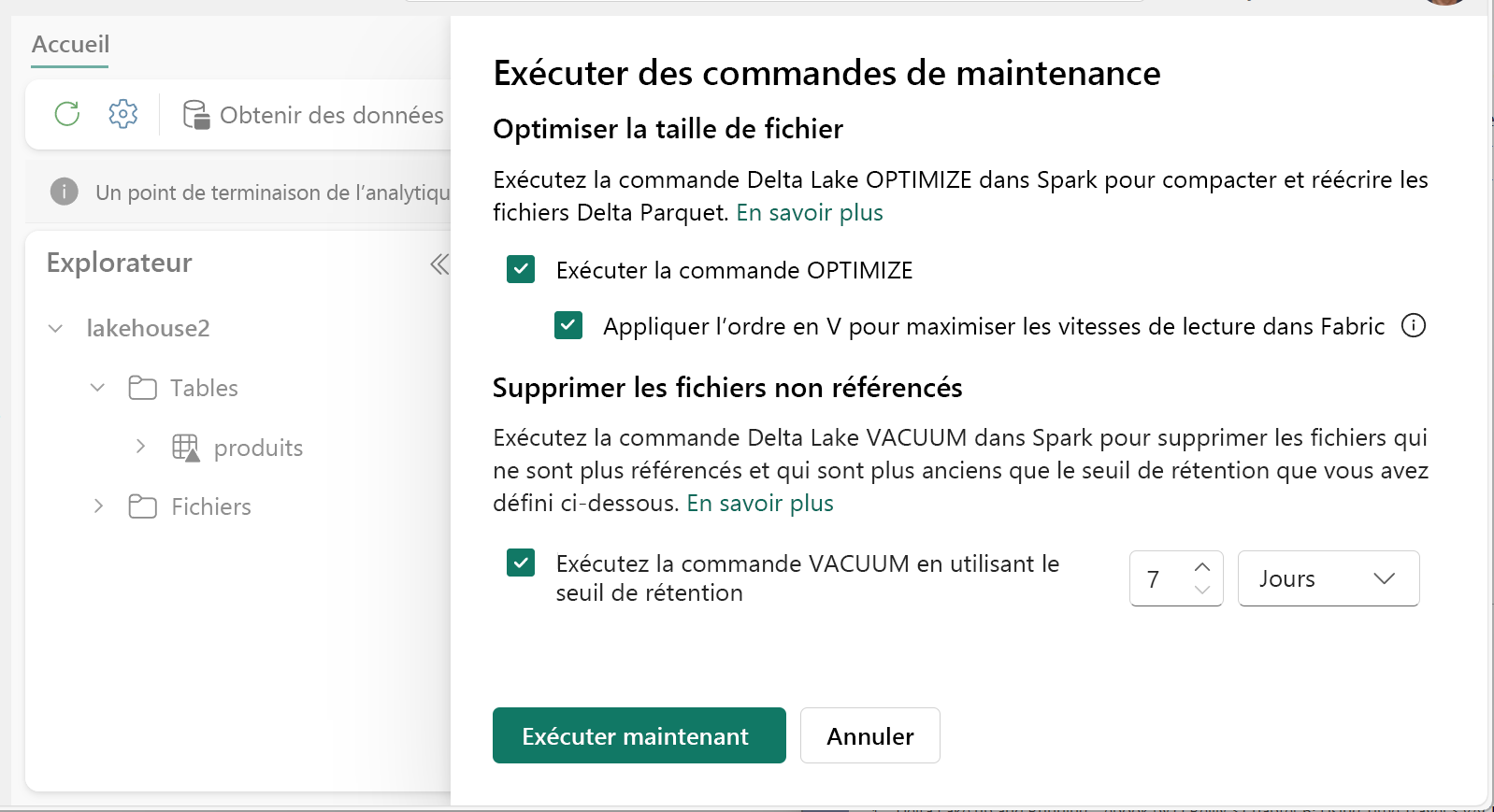
Pour exécuter Optimize :
- Dans l’explorateur Lakehouse, sélectionnez le menu ... en regard d’un nom de table et sélectionnez Maintenance.
- Sélectionnez Exécuter la commande OPTIMIZE.
- Si vous le souhaitez, sélectionnez Appliquer V-order pour optimiser les vitesses de lecture dans Fabric.
- Sélectionnez Exécuter maintenant.
Fonction V-Order
Lorsque vous exécutez Optimize, vous pouvez éventuellement exécuter V-Order, qui est conçu pour le format de fichier Parquet dans Fabric. V-Order permet des lectures rapides, avec des temps d’accès aux données similaires à la mémoire. Elle améliore également l’efficacité des coûts, car elle réduit les ressources réseau, disque et processeur pendant les lectures.
V-Order est activé par défaut dans Microsoft Fabric et est appliqué à mesure que les données sont écrites. Il entraîne une petite surcharge d’environ 15 % rendant les écritures un peu plus lentes. Toutefois, V-Order permet des lectures plus rapides à partir des moteurs de calcul Microsoft Fabric, tels que Power BI, SQL, Spark et d’autres.
Dans Microsoft Fabric, les moteurs Power BI et SQL utilisent la technologie Microsoft Verti-Scan qui tire pleinement parti de l’optimisation V-Order pour accélérer les lectures. Spark et d’autres moteurs n’utilisent pas la technologie VertiScan, mais bénéficient toujours de l’optimisation V-Order pour des lectures environ 10 % plus rapides, parfois jusqu’à 50 %.
V-Order fonctionne en appliquant un tri spécial, la distribution de groupes de lignes, l’encodage de dictionnaire et la compression sur les fichiers Parquet. Il est conforme à 100 % au format Parquet open source et tous les moteurs Parquet peuvent le lire.
V-Order peut ne pas être bénéfique pour les scénarios gourmands en écriture, tels que la préparation de magasins de données, où les données ne sont lues qu’une ou deux fois. Dans ces situations, la désactivation de V-Order peut réduire le temps de traitement global pour l’ingestion des données.
Appliquez V-Order à des tables individuelles à l’aide de la fonctionnalité Maintenance de table en exécutant la commande OPTIMIZE.
Vacuum
La commande VACUUM vous permet de supprimer les anciens fichiers de données.
Chaque fois qu’une mise à jour ou une suppression est effectuée, un nouveau fichier Parquet est créé et une entrée est écrite dans le journal des transactions. Les anciens fichiers Parquet sont conservés pour permettre un voyage dans le temps, ce qui signifie que les fichiers Parquet s’accumulent au fil du temps.
La commande VACUUM supprime les anciens fichiers de données Parquet, mais pas les journaux des transactions. Lorsque vous exécutez VACUUM, vous ne pouvez pas voyager dans le temps avant la période de rétention.
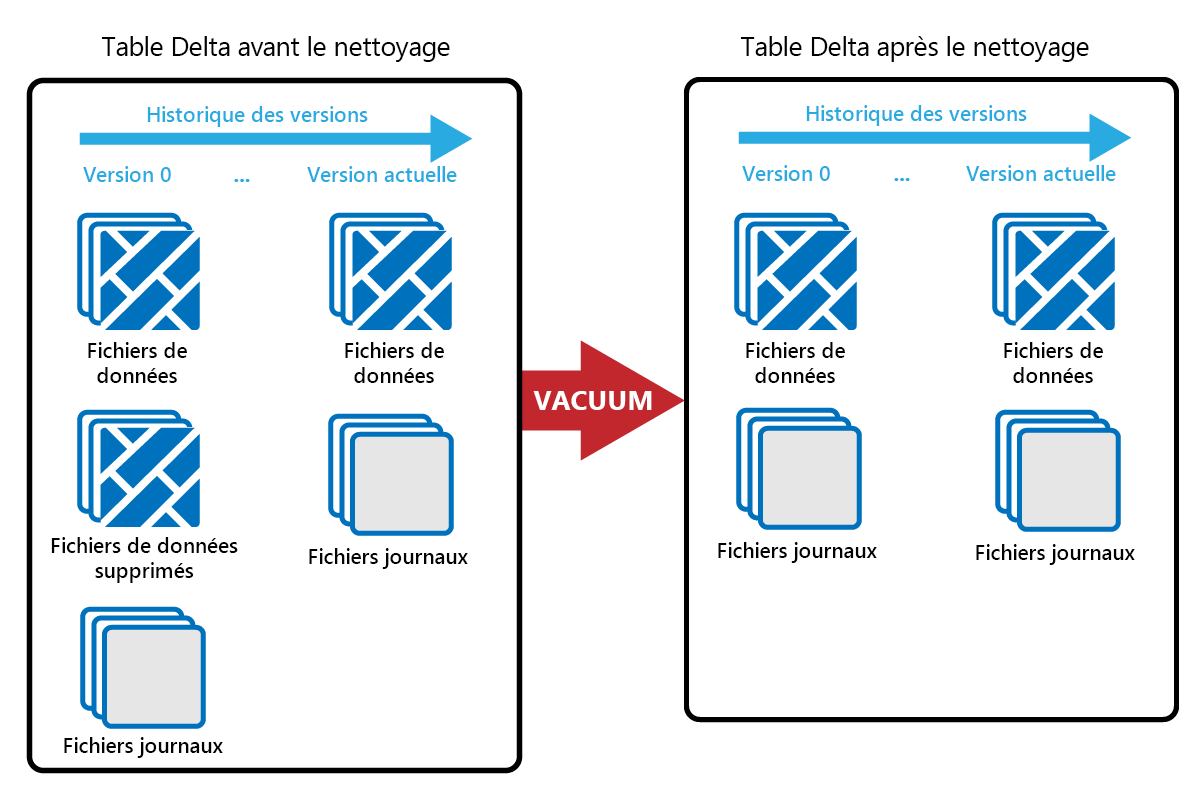
Les fichiers de données qui ne sont actuellement pas référencés dans un journal des transactions et qui sont antérieurs à la période de rétention spécifiée sont définitivement supprimés en exécutant VACUUM. Choisissez votre période de rétention en fonction de facteurs tels que :
- Exigences de conservation des données
- Taille des données et coûts de stockage
- Fréquence de modifications des données
- Exigences réglementaires
La période de rétention par défaut est de 7 jours (168 heures) et le système vous empêche d’utiliser une période de rétention plus courte.
Vous pouvez exécuter VACUUM sur une base ad hoc ou planifiée à l’aide de notebooks Fabric.
Exécutez VACUUM sur des tables individuelles à l’aide de la fonctionnalité de maintenance de table :
- Dans l’explorateur Lakehouse, sélectionnez le menu ... en regard d’un nom de table et sélectionnez Maintenance.
- Sélectionnez Exécuter la commande VACUUM à l’aide du seuil de rétention et définissez le seuil de rétention.
- Sélectionnez Exécuter maintenant.
Vous pouvez également exécuter VACUUM en tant que commande SQL dans un notebook :
%%sql
VACUUM lakehouse2.products RETAIN 168 HOURS;
VACUUM s’inscrit dans le journal des transactions Delta, ce qui vous permet d’afficher les exécutions précédentes dans DESCRIBE HISTORY.
%%sql
DESCRIBE HISTORY lakehouse2.products;
Partitionnement de tables Delta
Delta Lake vous permet d’organiser les données en partitions. Cela peut améliorer les performances en activant l’effacement des données, ce qui améliore les performances en ignorant les objets de données non pertinents en fonction des métadonnées d’un objet.
Considérez une situation dans laquelle de grandes quantités de données de ventes sont stockées. Vous pouvez partitionner les données de ventes par année. Les partitions sont stockées dans des sous-dossiers nommés « year=2021 », « year=2022 », etc. Si vous souhaitez uniquement signaler les données de ventes pour 2024, les partitions pour les autres années peuvent être ignorées, ce qui améliore les performances de lecture.
Toutefois, le partitionnement de petites quantités de données peut dégrader les performances, car il augmente le nombre de fichiers et peut aggraver le « problème de petits fichiers ».
Utilisez le partitionnement quand :
- Vous avez de très grandes quantités de données.
- Les tables peuvent être divisées en un petit nombre de partitions volumineuses.
N’utilisez pas le partitionnement lorsque :
- Les volumes de données sont petits.
- Une colonne de partitionnement a une cardinalité élevée, car cela crée un grand nombre de partitions.
- Une colonne de partitionnement entraînerait plusieurs niveaux.
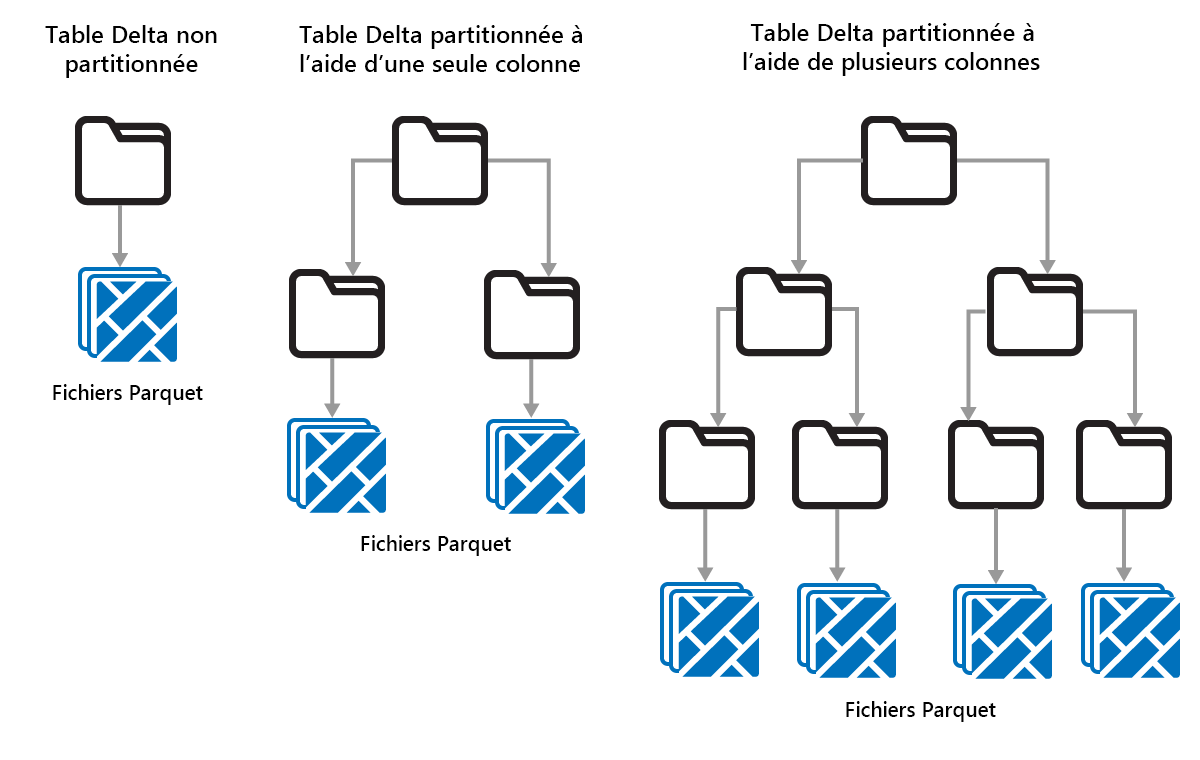
Les partitions sont une disposition des données fixe et ne s’adaptent pas à différents modèles de requête. Lorsque vous envisagez d’utiliser le partitionnement, réfléchissez à la façon dont vos données sont utilisées et à sa granularité.
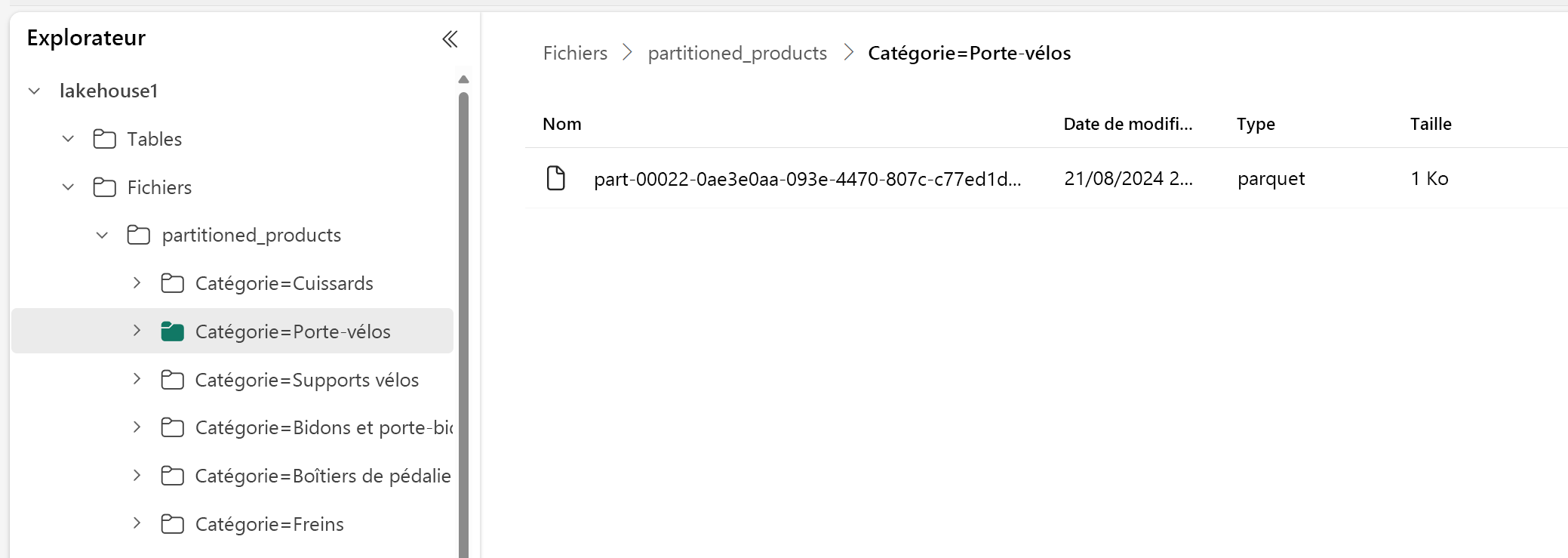
Dans cet exemple, un DataFrame contenant des données de produit est partitionné par catégorie :
df.write.format("delta").partitionBy("Category").saveAsTable("partitioned_products", path="abfs_path/partitioned_products")
Dans l’explorateur Lakehouse, vous pouvez voir que les données sont une table partitionnée.
- Il existe un dossier pour la table, appelé « partitioned_products ».
- Il existe des sous-dossiers pour chaque catégorie, par exemple « Category=Bike Racks », etc.
Nous pouvons créer une table partitionnée similaire à l’aide de SQL :
%%sql
CREATE TABLE partitioned_products (
ProductID INTEGER,
ProductName STRING,
Category STRING,
ListPrice DOUBLE
)
PARTITIONED BY (Category);