Choisir la cible de calcul appropriée
Dans Azure Machine Learning, les cibles de calcul sont des ordinateurs physiques ou virtuels sur lesquels des travaux sont exécutés.
Comprendre les types de calcul disponibles
Azure Machine Learning prend en charge plusieurs types de calcul pour l’expérimentation, l’entraînement et le déploiement. En ayant plusieurs types de calcul, vous pouvez sélectionner le type de cible de calcul le plus approprié pour vos besoins particuliers.
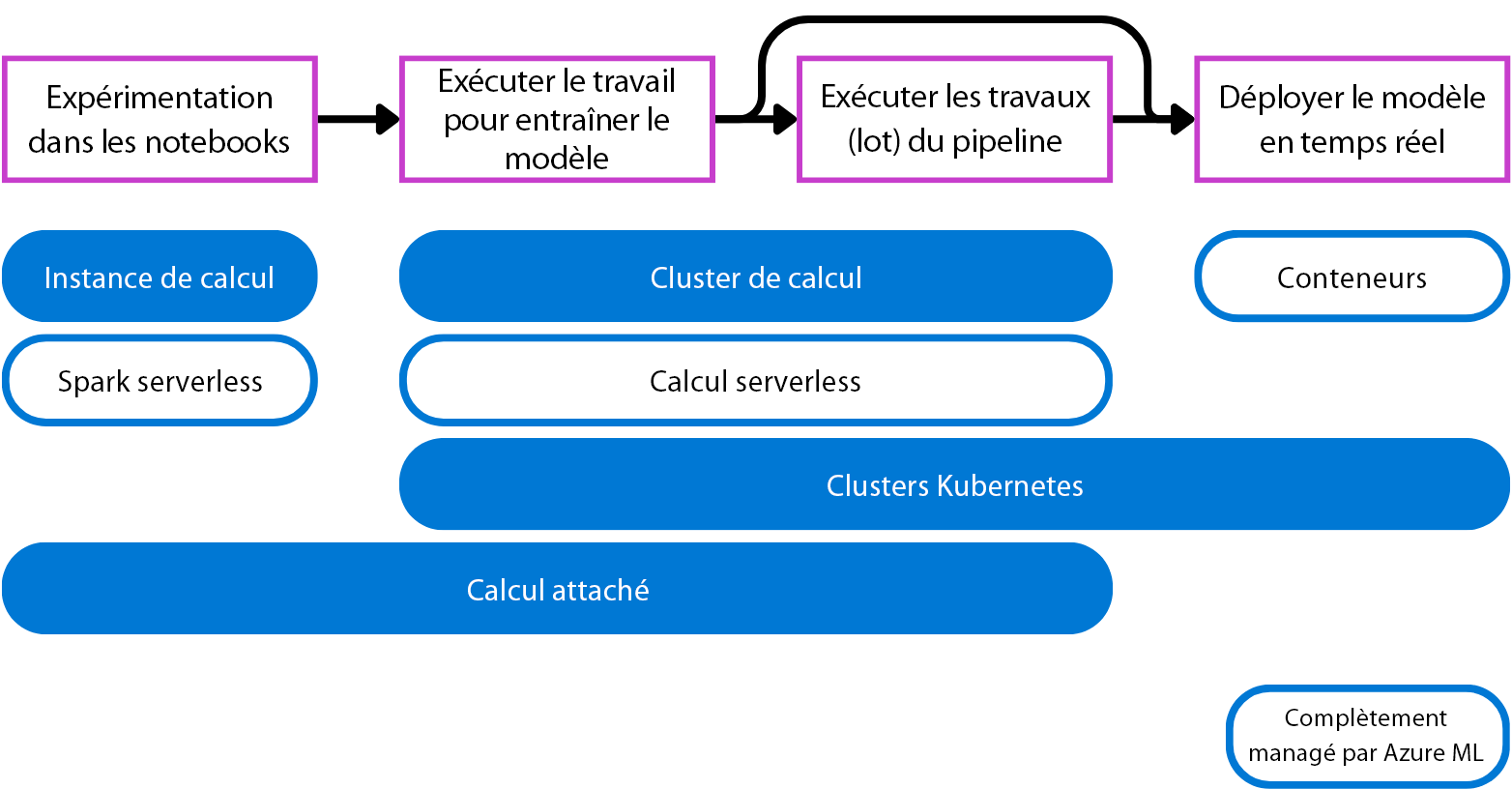
- Instance de calcul : se comporte de la même façon qu’une machine virtuelle et est principalement utilisée pour exécuter des notebooks. Idéal pour l’expérimentation.
- Clusters de calcul : clusters multinœuds de machines virtuelles qui subissent un scale-up ou un scale-down automatique pour répondre à la demande. Il s’agit d’un moyen économique d’exécuter des scripts qui doivent traiter de grands volumes de données. Les clusters vous permettent également d’utiliser le traitement parallèle pour distribuer la charge de travail et réduire le temps nécessaire à l’exécution d’un script.
- Clusters Kubernetes : cluster basé sur la technologie Kubernetes, ce qui vous permet de mieux contrôler la façon dont le calcul est configuré et géré. Vous pouvez attacher votre cluster Azure Kubernetes (AKS) autogéré pour le calcul cloud, ou un cluster Arc Kubernetes pour les charges de travail locales.
- Calcul attaché : Vous permet d’attacher à votre espace de travail un calcul existant, comme des machines virtuelles Azure ou des clusters Azure Databricks.
- Calcul serverless : Un calcul à la demande, entièrement managé, que vous pouvez utiliser pour des travaux d’entraînement.
Remarque
Azure Machine Learning vous offre la possibilité de créer et de gérer votre propre calcul, ou d’utiliser le calcul complètement managé par Azure Machine Learning.
Quand utiliser chacun de ces types de calcul ?
En général, il existe certaines bonnes pratiques à respecter lorsque vous utilisez des cibles de calcul. Pour comprendre comment choisir le type de calcul approprié, plusieurs exemples sont fournis. N’oubliez pas que le type de calcul que vous utilisez dépend toujours de votre situation spécifique.
Choisir une cible de calcul pour l’expérimentation
Imaginez que vous êtes un scientifique des données à qui l’on a demandé de développer un nouveau modèle de Machine Learning. Vous aurez probablement un petit sous-ensemble des données d’entraînement avec lequel vous pouvez expérimenter.
Pendant l’expérimentation et le développement, vous préférerez peut-être travailler dans Jupyter Notebook. Une expérience de notebook tirera le meilleur parti d’un calcul en cours d’exécution continue.
Beaucoup de scientifiques des données sont familiarisés avec l’exécution de notebooks sur leur appareil local. Une alternative cloud gérée par Azure Machine Learning est une instance de calcul. Vous pouvez également opter pour le calcul serverless Spark pour exécuter du code Spark dans des notebooks, si vous souhaitez utiliser la puissance de calcul distribuée de Spark.
Choisir une cible de calcul pour la production
Après l’expérimentation, vous pouvez entraîner vos modèles en exécutant des scripts Python pour préparer la production. Les scripts seront plus faciles à automatiser et à planifier lorsque vous souhaitez réentraîner votre modèle en continu au fil du temps. Vous pouvez exécuter des scripts en tant que travaux (de pipeline).
Lorsque vous passez en production, vous souhaitez que la cible de calcul soit prête à gérer de grands volumes de données. Plus vous utilisez de données, plus le modèle Machine Learning est susceptible d’être performant.
Lorsque vous entraînez des modèles avec des scripts, vous souhaitez une cible de calcul à la demande. Un cluster de calcul effectue automatiquement un scale-up lorsque le script doit être exécuté, et un scale-down lorsque l’exécution du script est terminée. Si vous souhaitez une alternative que vous n’avez pas besoin de créer et de gérer, vous pouvez utiliser le calcul serverless d’Azure Machine Learning.
Choisir une cible de calcul pour le déploiement
Le type de calcul dont vous avez besoin lors de l’utilisation de votre modèle pour générer des prédictions varie selon que vous souhaitez des prédictions par lots ou en temps réel.
Pour les prédictions par lots, vous pouvez exécuter un travail de pipeline dans Azure Machine Learning. Les cibles de calcul telles que les clusters de calcul et le calcul serverless d’Azure Machine Learning sont idéales pour les travaux de pipeline, car elles sont à la demande et évolutives.
Lorsque vous souhaitez des prédictions en temps réel, vous avez besoin d’un type de calcul qui s’exécute en continu. Les déploiements en temps réel bénéficient donc d’un calcul plus léger (et donc plus économique). Les conteneurs sont parfaits pour les déploiements en temps réel. Lorsque vous déployez votre modèle sur un point de terminaison en ligne géré, Azure Machine Learning crée et gère des conteneurs pour vous permettre d’exécuter votre modèle. Vous pouvez également attacher des clusters Kubernetes pour gérer le calcul nécessaire pour générer des prédictions en temps réel.