Explorer un flux de données Gen2 dans Microsoft Fabric
Dans Microsoft Fabric, vous pouvez créer un flux de données Gen2 dans la charge de travail Data Factory ou l’espace de travail Power BI, ou directement dans le lakehouse. Étant donné que notre scénario est axé sur l’ingestion des données, examinons l’expérience de la charge de travail Data Factory. Les flux de données Gen2 utilisent Power Query Online pour visualiser les transformations. Consultez une vue d’ensemble de l’interface :
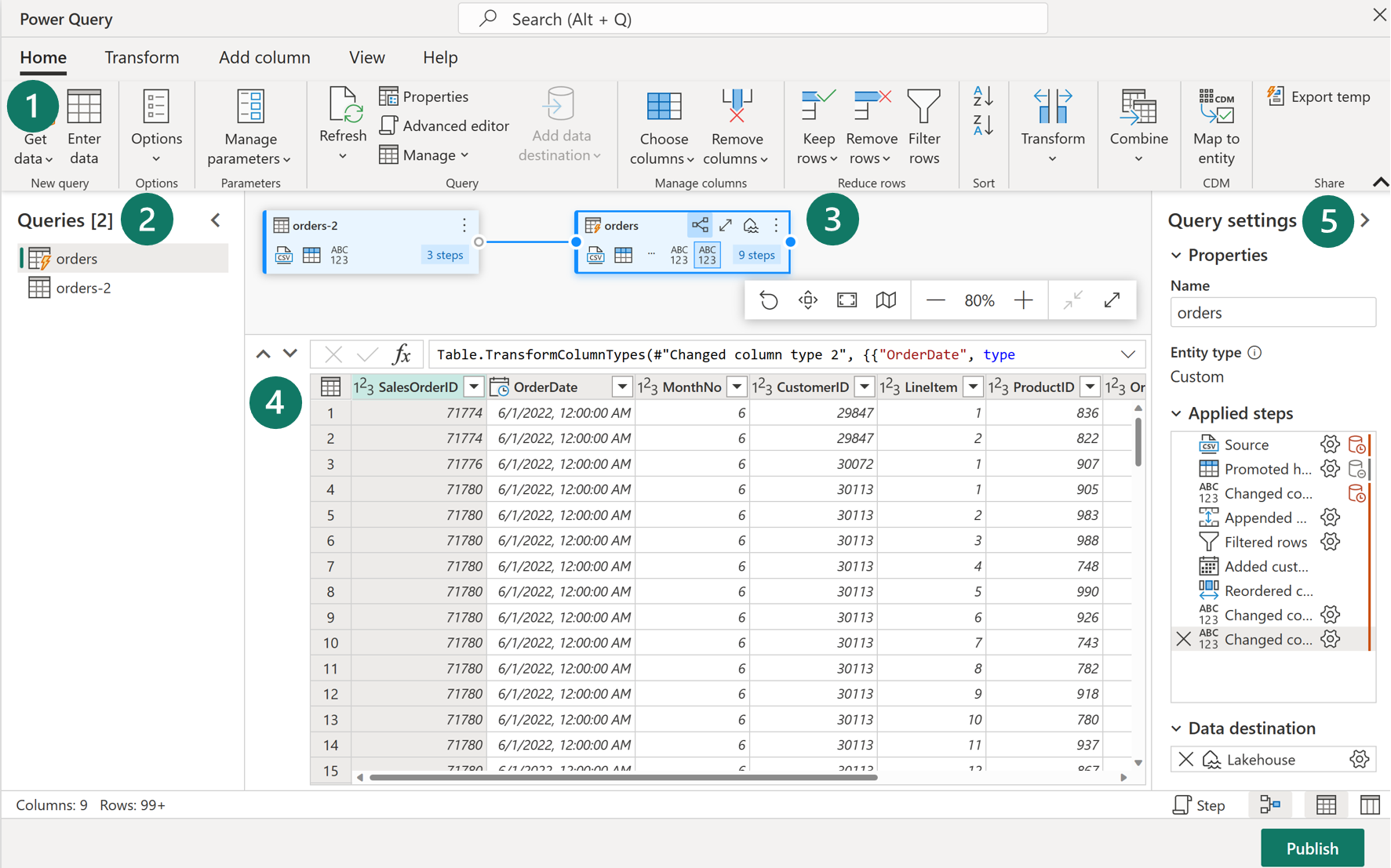
1. Ruban Power Query
Les flux de données (Gen2) prennent en charge un large éventail de connecteurs de source de données. Les sources courantes incluent les bases de données relationnelles cloud et locales, les fichiers plats ou Excel, SharePoint, SalesForce, Spark et les lakehouses Fabric. Il existe ensuite de nombreuses transformations de données possibles, telles que :
- Filtrer et trier les lignes
- Ajouter un tableau croisé dynamique et supprimer le tableau croisé dynamique
- Fusionner et ajouter des requêtes
- Fractionnement et fractionnement conditionnel
- Remplacer les valeurs et supprimer les doublons
- Ajouter, renommer, réorganiser ou supprimer des colonnes
- Calculatrice de classement et de pourcentage
- Choisir les N premières et N dernières valeurs
Vous pouvez également créer et gérer des connexions de sources de données, gérer des paramètres et configurer la destination des données par défaut dans ce ruban.
2. Volet Requêtes
Le volet Requêtes affiche les différentes sources de données, désormais appelées requêtes. Ces requêtes sont appelées tables lorsqu’elles sont chargées dans votre magasin de données. Vous pouvez dupliquer ou référencer une requête si vous avez besoin de plusieurs copies des mêmes données, telles que la création d’un schéma en étoile et le fractionnement de données en tables distinctes et plus petites. Vous pouvez également désactiver la charge d’une requête, au cas où vous n’avez besoin que de l’importation ponctuelle.
3. Affichage Diagramme
L’affichage Diagramme vous permet de voir comment les sources de données sont connectées et les différentes transformations appliquées. Par exemple, votre flux de données se connecte à une source de données, duplique la requête, supprime les colonnes de la requête source, puis désactive la requête dupliquée. Chaque requête est représentée par une forme avec toutes les transformations appliquées et reliée par une ligne pour la requête dupliquée. Vous pouvez activer ou désactiver cette vue.
4. Volet Aperçu des données
Le volet Aperçu des données affiche uniquement un sous-ensemble de données pour vous permettre de voir quelles transformations vous devez effectuer et comment elles affectent les données. Vous pouvez également interagir avec le volet d’aperçu en faisant glisser des colonnes et en les déposant pour changer l’ordre ou en cliquant avec le bouton droit sur les colonnes pour filtrer ou apporter des modifications. L’aperçu des données affiche toutes vos transformations pour la requête sélectionnée.
5. Volet Paramètres de la requête
Le volet Paramètres de requête inclut les Étapes appliquées. Chaque transformation est représentée par une étape, dont certaines sont automatiquement appliquées lorsque vous connectez la source de données. Selon la complexité des transformations, plusieurs étapes peuvent être appliquées pour chaque requête. La plupart des étapes ont une icône d’engrenage qui vous permet de modifier l’étape, sinon vous devez supprimer et répéter la transformation.
Chaque étape dispose également d’un menu contextuel lorsque vous cliquez avec le bouton droit pour pouvoir renommer, réorganiser ou supprimer les étapes. Vous pouvez également afficher la requête de la source de données lorsque vous vous connectez à une source de données qui prend en charge le pliage des requêtes.
Même si cette interface visuelle est utile, vous pouvez également afficher le code M par le biais de l’éditeur avancé.
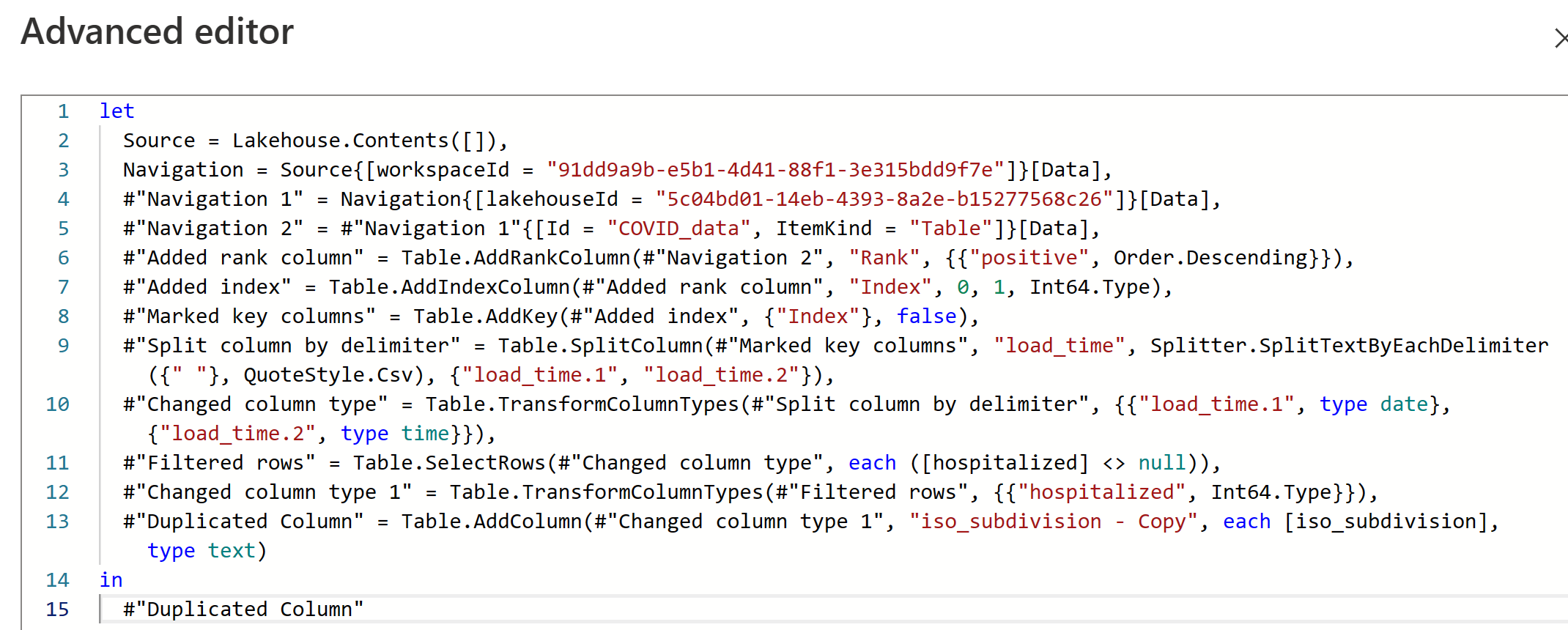
Dans le volet Paramètres de requête, vous pouvez voir une option Destination des données pour placer vos données dans l’un des emplacements suivants de votre environnement Fabric :
- Lakehouse
- Entrepôt
- Base de données SQL
Vous pouvez également charger votre flux de données dans Azure SQL Database, Azure Data Explorer ou Azure Synapse Analytics.
Les flux de données Gen2 fournissent une solution à faible niveau de code ou sans code pour ingérer, transformer et charger des données dans vos magasins de données Fabric. Les développeurs Power BI sont familiarisés et peuvent rapidement commencer à effectuer des transformations en amont pour améliorer la performance de leurs rapports.
Remarque
Pour plus d’informations, consultez la documentation sur Power Query pour optimiser vos flux de données.