Explorer l’architecture de la solution
Avant de commencer, nous allons explorer l’architecture pour comprendre toutes les exigences. Faire passer un modèle en production signifie que vous devez mettre à l’échelle votre solution et collaborer avec d’autres équipes. Avec les scientifiques des données, les ingénieurs données et l’équipe d’infrastructure, vous avez décidé d’adopter l’approche suivante :
- Toutes les données seront stockées dans Stockage Blob Azure, qui sera géré par l’ingénieur données.
- L’équipe d’infrastructure créera les ressources Azure nécessaires, comme l’espace de travail Azure Machine Learning.
- Le scientifique des données se concentrera sur la boucle interne : développement et entraînement du modèle.
- L’ingénieur Machine Learning prendra le modèle entraîné et le déploiera dans la boucle externe.
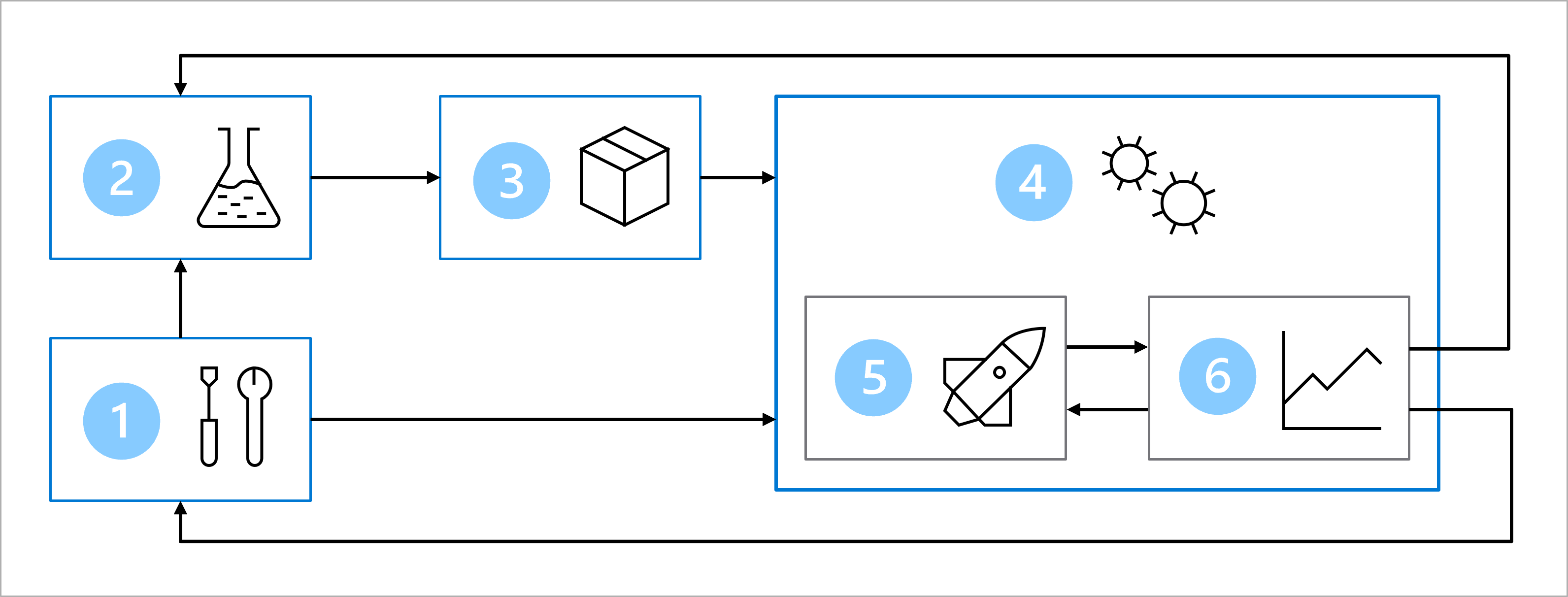
Avec l’équipe dans son ensemble, vous avez conçu une architecture pour réaliser des opérations de Machine Learning (MLOps).
Notes
Le diagramme est une représentation simplifiée d’une architecture MLOps. Pour obtenir une architecture plus détaillée, explorez les différents cas d’usage dans l’accélérateur de solution MLOps (v2).
L’objectif principal de l’architecture MLOps est de créer une solution robuste et reproductible. Pour ce faire, l’architecture inclut les éléments suivants :
- Installation : créer toutes les ressources Azure nécessaires pour la solution.
- Développement de modèle (boucle interne) : explorer et traiter les données pour entraîner et évaluer le modèle.
- Intégration continue : empaqueter et inscrire le modèle.
- Déploiement de modèle (boucle externe) : déployer le modèle.
- Déploiement continu : tester le modèle et le promouvoir dans un environnement de production.
- Monitoring : superviser les performances du modèle et du point de terminaison.
À ce stade de votre projet, l’espace de travail Azure Machine Learning est créé, les données sont stockées dans Stockage Blob Azure et l’équipe de science des données a entraîné le modèle.
Vous souhaitez passer de la boucle interne et du développement de modèle à la boucle externe en déployant le modèle en production. Par conséquent, vous devez convertir la sortie de l’équipe de science des données en un pipeline robuste et reproductible dans Azure Machine Learning.
En veillant à ce que tout le code soit stocké en tant que scripts et en exécutant les scripts en tant que travaux Azure Machine Learning, vous simplifierez l’automatisation de l’entraînement du modèle et le réentraînement du modèle à l’avenir.
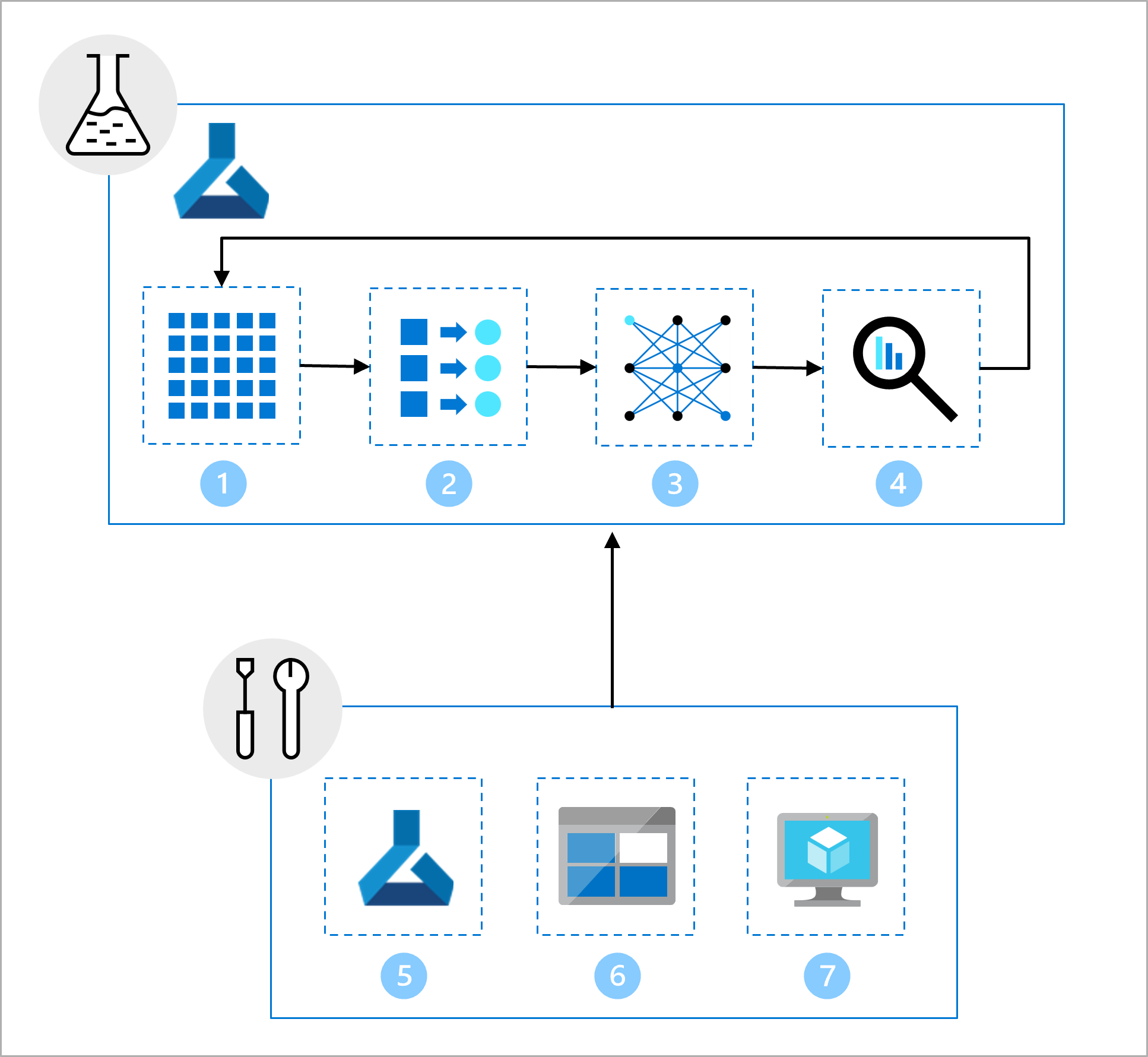
L’équipe de science des données a travaillé sur le développement de modèle. Elle vous donne un notebook Jupyter qui inclut les tâches suivantes :
- Lire et explorer les données.
- Effectuer l’ingénierie de caractéristiques.
- effectuer l’apprentissage du modèle ;
- Évaluer le modèle.
Dans le cadre de l’installation, l’équipe d’infrastructure a créé :
- Un espace de travail de développement (dev) Azure Machine Learning qui peut être utilisé par l’équipe de science des données pour l’exploration et l’expérimentation.
- Une ressource de données dans l’espace de travail, qui fait référence à un dossier du Stockage Blob Azure qui contient les données.
- Des ressources de calcul nécessaires pour exécuter des notebooks et des scripts.
Votre première tâche MLOps consiste à convertir le travail des scientifiques des données afin de pouvoir facilement automatiser le développement du modèle. Alors que l’équipe de science des données a travaillé dans un notebook Jupyter, vous devez utiliser des scripts et les exécuter à l’aide de travaux Azure Machine Learning. L’entrée du travail sera la ressource de données créée par l’équipe d’infrastructure, qui pointe vers les données résidant dans Stockage Blob Azure, connectée à l’espace de travail Azure Machine Learning.