Utiliser Spark dans les notebooks
Vous pouvez exécuter de nombreux types d’applications différents sur Spark, notamment du code dans des scripts Python ou Scala, du code Java compilé en tant qu’archive Java (JAR) et bien d’autres. Spark est couramment utilisé dans deux types de charge de travail :
- Travaux de traitement par lots ou en streaming pour ingérer, nettoyer et transformer des données, souvent exécutées dans le cadre d’un pipeline automatisé.
- Sessions d’analytique interactive pour explorer, analyser et visualiser des données.
Exécution de code Spark dans des notebooks
Azure Databricks comprend une interface de notebook intégrée pour utiliser Spark. Les notebooks offrent un moyen intuitif de combiner du code avec des notes Markdown, couramment utilisées par les scientifiques des données et les analystes Données. L’expérience des notebooks intégrée dans Azure Databricks s’apparente à l’expérience des notebooks Jupyter, plateforme de notebooks open source populaire.
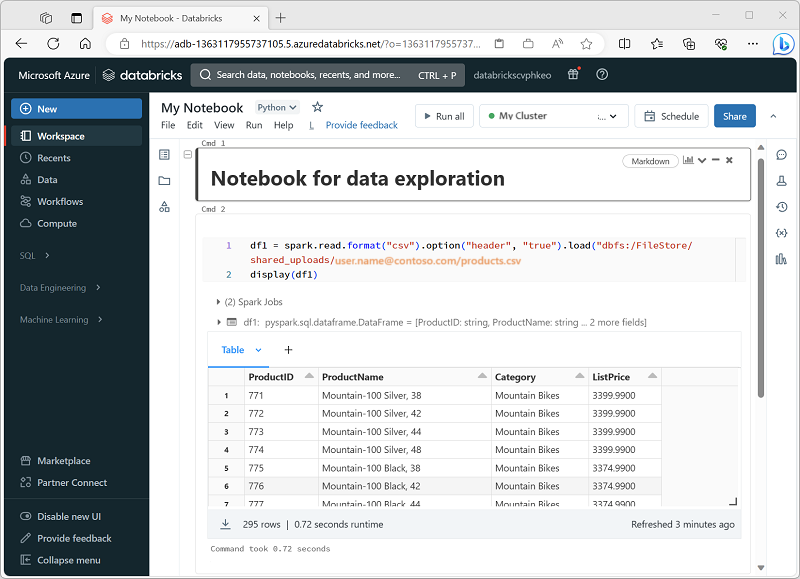
Les notebooks se composent d’une ou plusieurs cellules, chacune contenant du code ou des notes markdown. Les cellules de code des notebooks ont certaines fonctionnalités qui peuvent vous aider à être plus productifs, notamment :
- Coloration syntaxique et prise en charge des erreurs.
- Autocomplétion du code.
- Visualisations interactives des données.
- Possibilité d’exporter les résultats.
Conseil
Pour en savoir plus sur l’utilisation de notebooks dans Azure Databricks, consultez l’article Notebooks dans la documentation Azure Databricks.