Créer un cluster Spark
Vous pouvez créer un ou plusieurs clusters dans votre espace de travail Azure Databricks à partir du portail Azure Databricks.
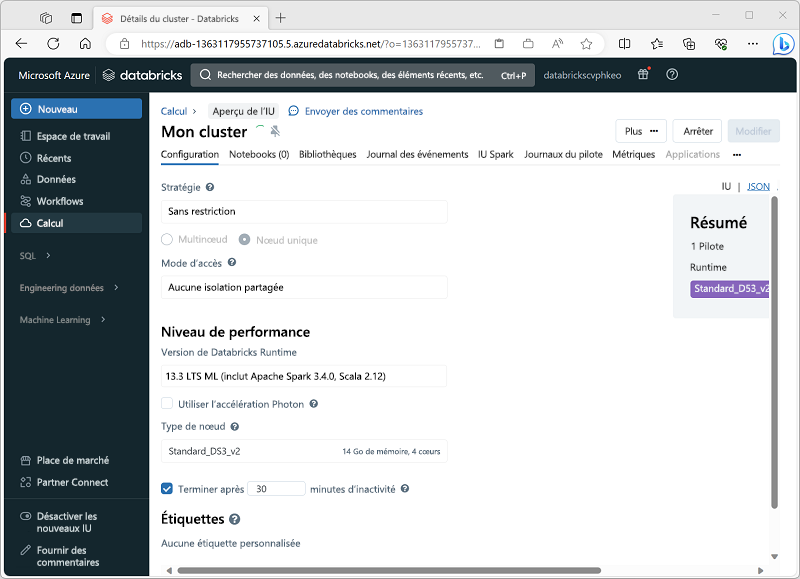
Quand vous créez le cluster, vous pouvez spécifier des paramètres de configuration, notamment :
- Nom du cluster.
- Mode du cluster, qui peut être :
- Standard : adapté aux charges de travail mono-utilisateurs qui nécessitent plusieurs nœuds worker.
- Concurrence élevée : adapté aux charges de travail où plusieurs utilisateurs utilisent simultanément le cluster.
- Nœud unique : adapté aux petites charges de travail ou aux tests, où un seul nœud worker est nécessaire.
- Version de Databricks Runtime à utiliser dans le cluster, qui dicte la version de Spark et des composants individuels de type Python, Scala et autres qui sont installés.
- Type de machine virtuelle utilisée pour les nœuds worker du cluster.
- Nombres minimal et maximal de nœuds worker dans le cluster.
- Type de machine virtuelle utilisée pour le nœud pilote dans le cluster.
- Indique si le cluster prend en charge la mise à l’échelle automatique pour redimensionner dynamiquement le cluster.
- Temps d’inactivité du cluster avant son arrêt automatique.
Comment Azure gère les ressources de cluster
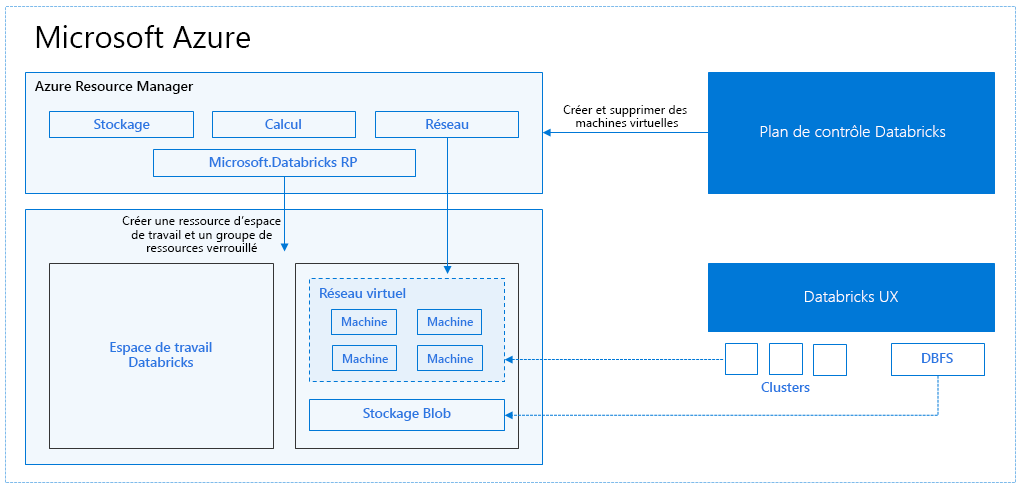
Quand vous créez un espace de travail Azure Databricks, une appliance Databricks est déployée comme ressource Azure dans votre abonnement. Quand vous créez un cluster dans l’espace de travail, vous spécifiez les types et tailles des machines virtuelles à utiliser pour les nœuds pilote et worker ainsi que d’autres options de configuration, mais Azure Databricks gère tous les autres aspects du cluster.
L’appliance Databricks est déployée sur Azure comme un groupe de ressources managé dans votre abonnement. Ce groupe de ressources contient les machines virtuelles pilote et worker, ainsi que d’autres ressources nécessaires, comme un réseau virtuel, un groupe de sécurité et un compte de stockage. Toutes les métadonnées, comme celles relatives aux travaux planifiés, sont stockées dans une base de données Azure avec géoréplication pour la tolérance de panne.
En interne, Azure Kubernetes Service (AKS) est utilisé pour exécuter les plans de contrôle et les plans de données Azure Databricks via des conteneurs s’exécutant sur la dernière génération de matériel Azure (machines virtuelles Dv3), avec des disques SSD NvMe qui fournissent une latence de 100 microsecondes sur des machines virtuelles Azure hautes performances avec performances réseau accélérées. Azure Databricks utilise ces fonctionnalités d’Azure pour améliorer encore davantage les performances Spark. Une fois que les services de votre groupe de ressources managé sont prêts, vous pouvez gérer le cluster Databricks dans l’interface utilisateur Azure Databricks et à travers diverses fonctionnalités, comme la mise à l’échelle automatique et l’arrêt automatique.
Remarque
Vous avez également la possibilité d’attacher votre cluster à un pool de nœuds inactifs pour réduire le temps de démarrage du cluster. Pour plus d’informations, consultez Pools dans la documentation Azure Databricks.