Décrire la réplication logique et le décodage logique
Le paramètre wal_level vous permet de définir la quantité d’informations à écrire dans le journal. Il existe deux options : LOGICAL ou REPLICA. REPLICA est la valeur par défaut. Ce paramètre est défini au démarrage du serveur.
Haute disponibilité
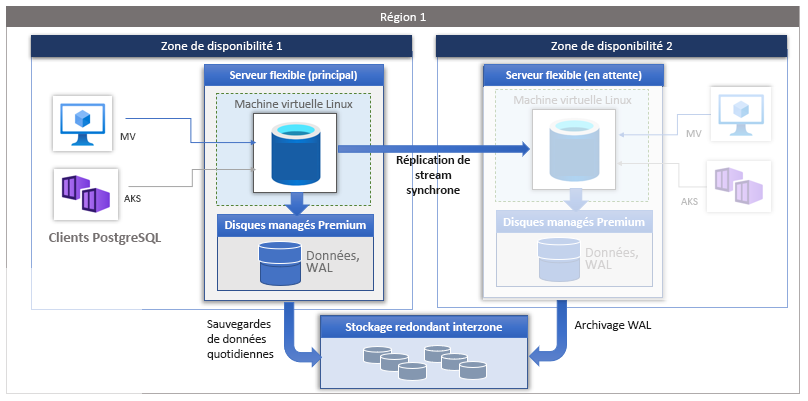
La haute disponibilité est un service Azure Database pour PostgreSQL, qui fournit un serveur de secours prêt à prendre le relais en cas de défaillance sur votre serveur actif. La haute disponibilité dans le serveur flexible Azure Database pour PostgreSQL utilise la réplication pour mettre à jour automatiquement le serveur de secours avec des modifications de données.
Lorsque vous configurez la haute disponibilité pour un serveur flexible Azure Database pour PostgreSQL, le serveur principal est placé dans une zone de disponibilité et un serveur de secours est créé dans une autre zone de disponibilité. Les données sont répliquées du serveur principal vers le serveur de secours à l’aide de la réplication de diffusion en continu PostgreSQL en mode synchrone.
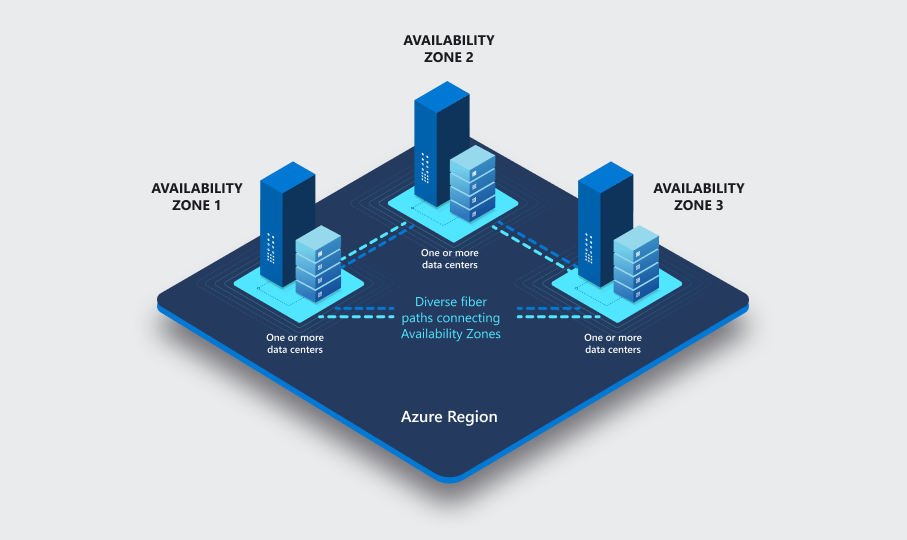
Chaque zone de disponibilité est constituée d’un ou plusieurs centres de données. Les zones de disponibilité ont leurs propres alimentations, systèmes de refroidissement, infrastructures réseau, etc., les rendant indépendantes les unes des autres. Trois copies des fichiers de données et des fichiers du journal WAL (write-ahead log) sont stockées sur un stockage localement redondant dans chaque zone de disponibilité, ce qui permet d’isoler physiquement les serveurs principaux et de secours. En cas de défaillance d’une zone de disponibilité, les deux autres continuent probablement de fonctionner. Les zones de disponibilité au sein d’une région sont connectées par des réseaux fibre rapides avec une latence aller-retour de moins de 2 millisecondes.
Notes
Toutes les régions ne disposent pas de zones de disponibilité.
Avec une haute disponibilité, les données sont dupliquées constamment lorsque la base de données est en cours d’utilisation, fournissant une copie à jour de l’original. En cas de panne, le réplica peut être utilisé à la place de l’original. La réplication a un serveur principal et un serveur de secours. Le serveur principal envoie les fichiers journaux WAL au serveur de secours, qui reçoit les fichiers journaux WAL.
Le serveur de secours retourne au serveur principal des informations telles que le dernier journal WAL (write-ahead log) qu’il a écrit, la dernière position vidée sur le disque, etc. Pour définir la fréquence minimale du récepteur WAL afin de renvoyer un rapport, définissez le paramètre wal_receiver_status_interval. Le paramètre max_replication_slots définit le nombre maximal d’emplacements de réplication que le serveur peut prendre en charge. Lorsque wal_level est défini sur REPLICA, max_replication_slots doit être au moins un, mais la plage de valeurs autorisée est comprise entre 0 et 262 143.
Le paramètre max_wal_senders définit le nombre maximal de processus d’expéditeur WAL.
Le serveur principal et le serveur de secours sont surveillés en permanence et les actions appropriées sont prises pour résoudre les problèmes, notamment le déclenchement d’un basculement vers le serveur de secours. Voici des listes d’états de haute disponibilité redondante interzone :
- Initialisation : Le processus de création d’un serveur de secours est en cours.
- Réplication : La réplication de données est dans un état stable et intègre.
- Sain : le serveur de secours est mis à jour par le serveur principal.
- Basculement : Le serveur de base de données principal est en cours de basculement vers le serveur de secours.
- Suppression du serveur de secours : Lors du processus de suppression du serveur de secours.
- Non activé : la haute disponibilité redondante interzone n’est pas activée.
Vous pouvez ajouter la haute disponibilité pour un serveur de base de données existant. Si vous activez ou désactivez la haute disponibilité sur un serveur actif, effectuez l’opération lors d’une période de faible activité.
À partir du portail Azure :
- Accédez à votre serveur Azure Database pour PostgreSQL.
- Dans la section Vue d’ensemble, sélectionnez votre Configuration actuelle. La section Calcul + stockage s’affiche.
- Sous Haute disponibilité, activez la case à cocher Haute disponibilité (redondant interzone) pour activer la haute disponibilité. La haute disponibilité n’est pas prise en charge pour le niveau burstable.
Il est important de noter que la haute disponibilité est une option de récupération d’urgence. Vous ne pouvez pas utiliser le serveur de secours à d’autres fins, par exemple autoriser l’accès aux bases de données en lecture seule. Toutefois, vous pouvez configurer la réplication entre deux serveurs Azure Database pour PostgreSQL à l’aide d’un modèle d’éditeur et d’abonné. Cette configuration gère deux serveurs avec des données répliquées entre eux. Vous disposez ensuite d’un accès complet au serveur abonné et pouvez utiliser les bases de données à n’importe quel effet. Vous allez découvrir cette configuration dans l’exercice à la fin de ce module.
Décodage logique
Le décodage logique utilise également les données envoyées au journal en écriture anticipée. Comme son nom l’indique, il décode les entrées dans le journal d’écriture anticipée pour les rendre compréhensibles. Toutes les modifications INSERT, UPDATE et DELETE sont disponibles pour le décodage logique.
Le décodage logique peut être utilisé pour l’audit, l’analyse ou toute autre raison pour laquelle vous pourriez souhaiter connaître les modifications et leurs dates de survenue.
Le décodage logique extrait les modifications de toutes les tables de la base de données. Il diffère de la réplication, car il ne peut pas envoyer ces modifications à d’autres instances PostgreSQL. Au lieu de cela, une extension PostgreSQL fournit un plugin de sortie pour diffuser les modifications.
Le décodage logique permet au contenu du journal en écriture anticipée d’être décodé dans un format facile à comprendre, qui peut être interprété sans connaissance de la structure de la base de données. Azure Database pour PostgreSQL prend en charge le décodage logique en utilisant l’extension wal2json, qui est installé sur les serveurs Azure Database pour Postgres.
D’autres extensions peuvent être utilisées, comme l’extension pglogical, qui permet la réplication de diffusion logique.
Pour utiliser le décodage logique, dans Paramètres du serveur, définissez :
- wal_level sur LOGICAL
- max_replication_slots = 10
- max_wal_senders = 10
Le serveur doit être redémarré une fois ces modifications effectuées.
Pour utiliser l’extension pglogical à partir du portail Azure :
- Accédez à votre serveur Azure Database pour PostgreSQL.
- Sélectionnez Paramètres du serveur et recherchez shared_preload_libraries. Dans la zone de liste déroulante, sélectionnez pglogical.
- Recherchez azure.extensions. Dans la zone de liste déroulante, sélectionnez pglogical.
- Pour appliquer les modifications, redémarrez le serveur.
Vous devez également accorder les autorisations de l’utilisateur administrateur pour la réplication :
ALTER ROLE <adminname> WITH REPLICATION;
Pour plus d’informations, consultez la documentation en ligne documentation sur l’extension pglogical.
Le décodage logique envoie les modifications de données sous la forme d’un flux appelé emplacement de réplication logique.
- Chaque emplacement a un plug-in de sortie, que vous pouvez définir.
- Chaque emplacement fournit des modifications d’une seule base de données, mais une base de données peut avoir plusieurs emplacements.
- Chaque modification de données est normalement émise une fois par emplacement.
- Si PostgreSQL redémarre, un emplacement doit émettre à nouveau des modifications (que le client doit gérer).
- Les emplacements doivent être surveillés. Les emplacements non consommés conservent tous les fichiers WAL pour ces changements non consommés. Cette situation peut entraîner le stockage complet ou un bouclage des ID de transaction.