Que sont les modèles de classification ?
Les modèles de classification permettent de prendre des décisions ou d’affecter des éléments à des catégories. Contrairement aux modules de régression, qui produisent des nombres continus, comme des hauteurs ou des poids, les modèles de classification produisent des résultats booléens (true ou false) ou des décisions de catégorie, comme apple, banana ou cherry.
Il existe de nombreux types de modèles de classification. Certains fonctionnent de manière similaire aux modèles de régression classiques, tandis que d’autres sont fondamentalement différents. L’un des meilleurs modèles à apprendre en premier s’appelle la régression logistique.
Qu’est-ce que la régression logistique ?
La régression logistique est un type de modèle de classification qui fonctionne de manière similaire à la régression linéaire. La différence entre cette méthode et la régression linéaire réside dans la forme de la courbe. Alors que la régression linéaire simple permet d’ajuster une ligne droite aux données, les modèles de régression logistique permettent d’ajuster une courbe en forme de s :
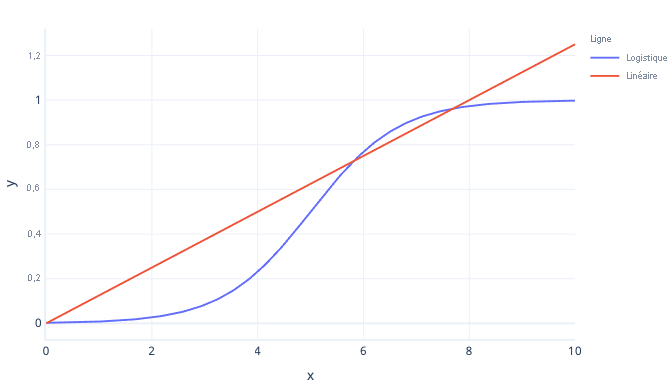
La régression logistique est plus adaptée à l’estimation des résultats booléens que la régression linéaire, car la courbe logistique produit toujours une valeur comprise entre 0 (false) et 1 (true). Tout ce qui se situe entre ces deux valeurs peut être considéré comme une probabilité.
Supposons, par exemple, que nous essayons de prédire si une avalanche aura lieu aujourd’hui. Si notre modèle de régression logistique nous donne la valeur de 0,3, il estime que la probabilité d’une avalanche est de 30 %.
Conversion de sorties en catégories
Comme la régression logistique produit ces probabilités, plutôt que de simples valeurs vrai/faux, nous devons prendre des mesures supplémentaires pour convertir le résultat en une catégorie. Le moyen le plus simple d’effectuer cette conversion est d’appliquer un seuil. Par exemple, dans le graphique suivant, notre seuil est fixé à 0,5. Le seuil signifie que toute valeur y inférieure à 0,5 est convertie en valeur fausse (case inférieure gauche) et que toute valeur supérieure à 0,5 est convertie en valeur vraie (case supérieure droite).
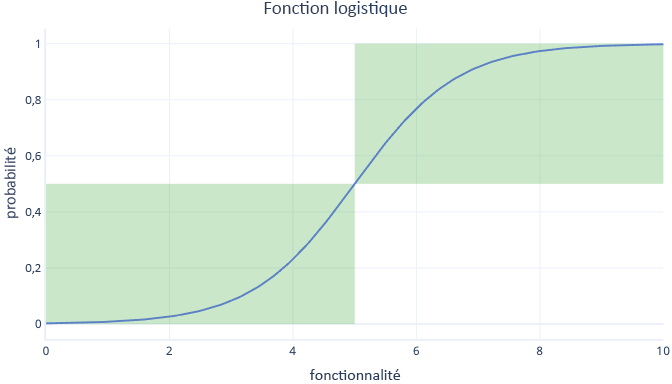
En regardant le graphique, vous pouvez voir que lorsque l’élément est inférieur à 5, la probabilité est inférieure à 0,5, et est donc convertie en valeur fausse. Les valeurs de caractéristiques supérieures à 5 donnent des probabilités supérieures à 0,5, et sont donc converties en valeurs true (vrai).
Il est à noter que la régression logistique ne doit pas se limiter à un résultat vrai/faux : elle peut aussi être utilisée quand il existe trois résultats potentiels ou plus, comme rain, snow ou sun. Ce type de résultat nécessite une configuration légèrement plus complexe, appelée régression logistique multinomiale. Bien que cet aspect ne soit pas abordé dans les prochains exercices, cela vaut la peine de le prendre en compte dans les situations où vous devez faire des prédictions qui ne sont pas binaires.
Il convient également de noter que la régression logistique peut utiliser plusieurs caractéristiques d’entrées : nous y reviendrons bientôt.