Visualiser les données avec Spark
L’une des méthodes les plus intuitives pour analyser les résultats des requêtes de données consiste à les visualiser sous forme de graphiques. Les notebooks dans Azure Synapse Analytics fournissent des fonctionnalités graphiques simples dans l’interface utilisateur, et quand cette fonctionnalité ne fournit pas ce dont vous avez besoin, vous pouvez utiliser l’une des nombreuses bibliothèques graphiques Python pour créer et afficher des visualisations de données dans le notebook.
Utilisation de graphiques de notebooks intégrés
Lorsque vous affichez un dataframe ou exécutez une requête SQL dans un notebook Spark dans Azure Synapse Analytics, les résultats s’affichent sous la cellule de code. Par défaut, les résultats sont restitués sous forme de tableau, mais vous pouvez également remplacer l’affichage des résultats par un graphique et utiliser les propriétés du graphique pour personnaliser la façon dont le graphique visualise les données, comme illustré ici :
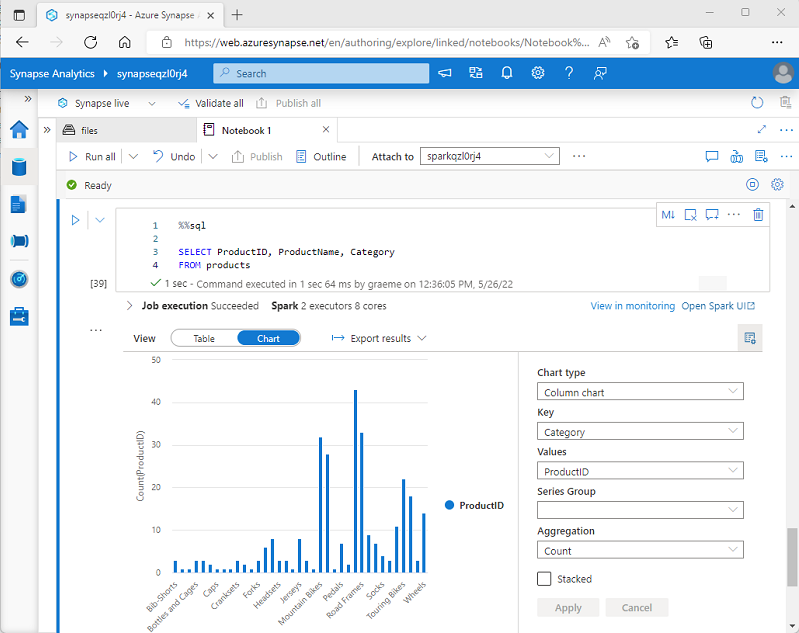
La fonctionnalité graphique intégrée dans les notebooks est utile lorsque vous travaillez avec les résultats d’une requête qui n’inclut pas de regroupements ou d’agrégations existants, et que vous souhaitez synthétiser rapidement les données visuellement. Lorsque vous souhaitez avoir plus de contrôle sur la mise en forme des données ou pour afficher les valeurs que vous avez déjà agrégées dans une requête, pensez à utiliser un package de graphiques pour créer vos propres visualisations.
Utilisation de packages de graphiques dans le code
Il existe de nombreux packages de graphiques que vous pouvez utiliser pour créer des visualisations de données dans le code. En particulier, Python prend en charge une grande sélection de packages, dont la plupart repose sur la bibliothèque Matplotlib de base. La sortie d’une bibliothèque graphique peut être restituée dans un notebook, ce qui facilite la combinaison du code pour ingérer et manipuler des données avec des visualisations de données inline et des cellules Markdown pour fournir des commentaires.
Par exemple, vous pouvez utiliser le code PySpark suivant pour agréger des données de produits hypothétiques explorées précédemment dans ce module et utiliser Matplotlib pour créer un graphique à partir des données agrégées.
from matplotlib import pyplot as plt
# Get the data as a Pandas dataframe
data = spark.sql("SELECT Category, COUNT(ProductID) AS ProductCount \
FROM products \
GROUP BY Category \
ORDER BY Category").toPandas()
# Clear the plot area
plt.clf()
# Create a Figure
fig = plt.figure(figsize=(12,8))
# Create a bar plot of product counts by category
plt.bar(x=data['Category'], height=data['ProductCount'], color='orange')
# Customize the chart
plt.title('Product Counts by Category')
plt.xlabel('Category')
plt.ylabel('Products')
plt.grid(color='#95a5a6', linestyle='--', linewidth=2, axis='y', alpha=0.7)
plt.xticks(rotation=70)
# Show the plot area
plt.show()
La bibliothèque Matplotlib demande que les données se trouvent dans un dataframe Pandas plutôt que dans un dataframe Spark afin que la méthode toPandas soit utilisée pour les convertir. Le code crée ensuite une figure avec une taille spécifiée et trace un graphique à barres avec une configuration de propriété personnalisée avant de montrer le tracé obtenu.
Le graphique produit par le code devrait ressembler à l’image suivante :
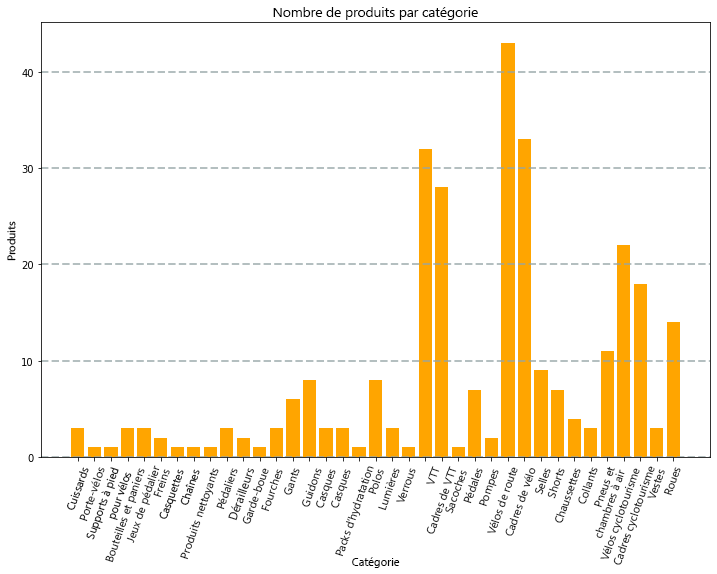
Vous pouvez utiliser la bibliothèque Matplotlib pour créer de nombreux types de graphiques ; ou, si vous préférez, vous pouvez utiliser d’autres bibliothèques telles que Seaborn pour créer des graphiques hautement personnalisés.