Résoudre les problèmes d’un réseau avec les métriques et les journaux de Network Watcher
Si vous voulez diagnostiquer un problème rapidement, vous devez comprendre les informations disponibles dans les journaux Azure Network Watcher.
Dans votre société d’ingénierie, vous voulez minimiser le temps nécessaire au personnel pour diagnostiquer et résoudre les problèmes de configuration réseau. Vous voulez être sûr qu’ils savent quelles informations sont disponibles et dans quels journaux.
Dans ce module, vous allez vous concentrer sur les journaux de flux, les journaux de diagnostic et l’analytique du trafic. Vous allez découvrir comment ces outils peuvent vous aider à résoudre les problèmes de réseau Azure.
Utilisation et quotas
Vous pouvez utiliser chaque ressource Microsoft Azure jusqu’à son quota. Chaque abonnement a des quotas distincts et l’utilisation fait l’objet d’un suivi par abonnement. Une seule instance de Network Watcher est nécessaire par abonnement et par région. Cette instance vous donne une vue de l’utilisation et des quotas, qui vous permet de voir si vous risquez d’atteindre un quota.
Pour voir les informations d’utilisation et de quota, accédez à Tous les services>Mise en réseau>Network Watcher, puis sélectionnez Utilisation et quotas. Vous voyez des données précises en fonction de l’utilisation et de l’emplacement des ressources. Des données pour les métriques suivantes sont capturées :
- Interfaces réseau
- Groupes de sécurité réseau (NSG)
- Réseaux virtuels
- Adresses IP publiques
Voici un exemple qui montre l’utilisation et les quotas dans le portail :

Journaux
Les journaux de diagnostic réseau fournissent des données précises. Vous utilisez ces données pour mieux comprendre les problèmes de connectivité et de performances. Il existe trois outils d’affichage des journaux dans Network Watcher :
- Journaux de flux NSG
- Journaux de diagnostic
- Traffic analytics
Examinons chacun de ces outils.
Journaux de flux NSG
Dans les journaux de flux NSG, vous pouvez voir des informations relatives au trafic IP entrant et sortant sur les groupes de sécurité réseau. Les journaux de flux montrent les flux entrants et sortants par règle en fonction de la carte réseau à laquelle le flux s’applique. Les journaux de flux NSG indiquent si le trafic a été autorisé ou refusé en fonction des informations à 5 tuples capturées. Ces informations incluent :
- Adresse IP source
- Port source
- Adresse IP de destination
- Port de destination
- Protocole
Ce diagramme montre le workflow suivi par le NSG (groupe de sécurité réseau).
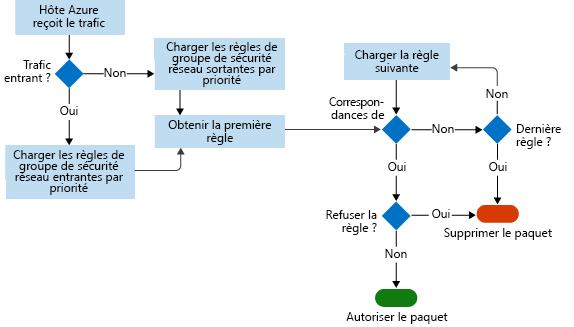
Les journaux de flux stockent les données dans un fichier JSON. Il peut être difficile d’obtenir des insights sur ces données en faisant des recherches manuelles dans les fichiers journaux, en particulier si vous avez un grand déploiement d’infrastructure dans Azure. Pour résoudre ce problème, utilisez Power BI.
Dans Power BI, vous pouvez visualiser les journaux de flux NSG de nombreuses façons. Par exemple :
- Émetteurs principaux (adresse IP)
- Flux par direction (entrant et sortant)
- Flux par décision (autorisé et refusé)
- Flux par port de destination
Vous pouvez également utiliser des outils open source pour analyser vos journaux, comme Elastic Stack, Grafana et Graylog.
Notes
Les journaux de flux NSG ne prennent pas en charge les comptes de stockage sur le portail classique Azure.
Journaux de diagnostic
Dans Network Watcher, les journaux de diagnostic constituent un emplacement central pour activer et désactiver les journaux pour les ressources réseau Azure. Ces ressources peuvent inclure des NSG, des adresses IP publiques, des équilibreurs de charge et des passerelles d’application. Après avoir activé les journaux qui vous intéressent, vous pouvez utiliser les outils pour interroger et visualiser les entrées des journaux.
Vous pouvez importer des journaux de diagnostic dans Power BI et d’autres outils pour les analyser.
Traffic analytics
Pour suivre de près l’activité des utilisateurs et des applications dans vos réseaux cloud, utilisez Traffic Analytics.
L’outil fournit des insights sur l’activité réseau dans les différents abonnements. Vous pouvez diagnostiquer les menaces de sécurité, comme les ports ouverts, les machines virtuelles communiquant avec des réseaux dangereux connus et les modèles de flux de trafic. Traffic Analytics analyse les journaux de flux NSG dans les régions et les abonnements Azure. Vous pouvez utiliser les données pour optimiser les performances réseau.
Cet outil nécessite Log Analytics. L’espace de travail Log Analytics doit exister dans une région prise en charge.
Scénarios de cas d’usage
Examinons à présent quelques scénarios de cas d’usage où les métriques et les journaux Azure Network Watcher peuvent être utiles.
Rapports sur les clients produits avec des performances lentes
Pour corriger les performances lentes, vous devez déterminer la cause racine du problème :
- Y a-t-il trop de trafic limitant le serveur ?
- La taille de machine virtuelle est-elle appropriée pour le travail ?
- Les seuils de scalabilité sont-ils définis de façon appropriée ?
- Des attaques malveillantes se produisent-elles ?
- La configuration du stockage des machines virtuelles est-elle correcte ?
Vérifiez d’abord que la taille de la machine virtuelle est appropriée pour le travail. Ensuite, activez Diagnostics Azure sur la machine virtuelle afin d’obtenir des données plus précises pour des métriques spécifiques, comme l’utilisation du processeur et l’utilisation de la mémoire. Pour activer les diagnostics de machine virtuelle via le portail, accédez à la Machine virtuelle, sélectionnez Paramètres de diagnostic, puis activez les diagnostics.
Supposons que vous avez une machine virtuelle qui s’exécute correctement. Cependant, les performances de la machine virtuelle se sont récemment dégradées. Pour déterminer si des goulots d’étranglement de ressources sont présents, vous devez examiner les données capturées.
Commencez par une plage de temps des données capturées avant, pendant et après l’apparition du problème pour obtenir une vue précise des performances. Ces graphiques peuvent également être utiles pour observer les différences de comportement de ressources au cours de la même période. Vous allez rechercher les éléments suivants :
- Goulots d’étranglement du processeur
- Goulots d’étranglement de la mémoire
- Goulots d’étranglement du disque
Goulots d’étranglement du processeur
Quand vous étudiez des problèmes de performances, vous pouvez examiner les tendances pour déterminer si elles affectent votre serveur. Pour identifier les tendances, depuis le portail, utilisez les graphes de supervision. Vous pouvez voir différents types de modèles dans le graphique de supervision :
- Pics isolés. Un pic est probablement lié à une tâche planifiée ou à un événement attendu. Si vous savez ce qu’est cette tâche, est-ce qu’elle s’exécute au niveau de performance nécessaire ? Si les performances sont correctes, vous n’aurez certainement pas besoin d’augmenter la capacité.
- Pics élevés et constants. Une nouvelle charge de travail risque d’être à l’origine de cette tendance. Activez la supervision dans la machine virtuelle pour déterminer quels processus provoquent la charge. L’augmentation de la consommation peut être due à un code inefficace ou à la consommation normale de la nouvelle charge de travail. Si la consommation est normale, le processus fonctionne-t-il au niveau de performance nécessaire ?
- Constant. Votre machine virtuelle a-t-elle toujours été comme cela ? Si oui, vous devez identifier les processus qui consomment la plupart des ressources et envisager d’augmenter la capacité.
- Augmentation régulière. Voyez-vous une augmentation constante de la consommation ? Si oui, cette tendance indique certainement un code inefficace ou un processus utilisant plus de charge de travail utilisateur.
Si vous observez une utilisation élevée du processeur, vous pouvez :
- Augmenter la taille de la machine virtuelle pour la mettre à l’échelle avec davantage de cœurs.
- Investiguer le problème plus en détail. Localiser l’application et le processus, puis résoudre le problème en conséquence.
Si vous effectuez un scale-up de la machine virtuelle et que le processeur fonctionne toujours à plus de 95 pour cent, est-ce que cela améliore les performances de l’application ou le débit de l’application jusqu’à un niveau acceptable ? Si ce n’est pas le cas, résolvez les problèmes de cette application individuelle.
Goulots d’étranglement de la mémoire
Vous pouvez voir la quantité de mémoire utilisée par la machine virtuelle. Les journaux vous aident à comprendre la tendance et si elle correspond au moment où vous voyez des problèmes. Vous ne devez avoir à aucun moment moins de 100 Mo de mémoire disponible. Regardez les tendances suivantes :
- Pics élevés et consommation constante. Une utilisation élevée de la mémoire n’est probablement pas à l’origine de mauvaises performances. Certaines applications, par exemple les moteurs de bases de données relationnelles, sont gourmandes en mémoire par conception. Toutefois, s’il existe plusieurs applications gourmandes en mémoire, vous risquez d’obtenir des performances médiocres, car une contention de la mémoire est source de segmentation et de pagination sur le disque. Ces processus ont un impact négatif sur les performances.
- Augmentation régulière de la consommation. Cette tendance peut être liée au démarrage d’une application. C’est courant quand des moteurs de base de données démarrent. Toutefois, cela risque aussi d’être le signe d’une fuite de mémoire dans une application.
- Utilisation du fichier de pagination ou d’échange. Vérifiez si vous utilisez le fichier de pagination Windows de façon intensive ou le fichier d’échange Linux, situé sur /dev/sdb.
Pour résoudre une utilisation élevée de la mémoire, envisagez ces solutions :
- Pour une diminution immédiate de l’utilisation du fichier de pagination, augmentez la taille de la machine virtuelle pour ajouter de la mémoire, puis supervisez-la.
- Investiguer le problème plus en détail. Localisez l’application ou le processus à l’origine du goulot d’étranglement et résolvez le problème. Si vous connaissez l’application, déterminez si vous pouvez limiter l’allocation de mémoire.
Goulots d’étranglement du disque
Les performances réseau peuvent également être liées au sous-système de stockage de la machine virtuelle. Vous pouvez examiner le compte de stockage pour la machine virtuelle dans le portail. Pour identifier les problèmes liés au stockage, examinez les métriques de performances dans les diagnostics du compte de stockage et les diagnostics de la machine virtuelle. Recherchez les tendances clés quand des problèmes surviennent dans un intervalle de temps spécifique.
- Pour rechercher des dépassements de délai d’expiration de Stockage Azure, utilisez les métriques ClientTimeOutError, ServerTimeOutError, AverageE2ELatency, AverageServerLatency et TotalRequests. Si vous voyez des valeurs dans les métriques TimeOutError, c’est qu’une opération d’E/S a pris trop de temps et a dépassé le délai d’expiration. Si vous constatez une augmentation de AverageServerLatency en même temps que TimeOutErrors, il peut s’agir d’un problème de plateforme. Ouvrez un incident auprès du support technique Microsoft.
- Pour vérifier la limitation du stockage Azure, utilisez la métrique de compte de stockage ThrottlingError. Si vous voyez une limitation, c’est que vous atteignez la limite d’IOPS du compte. Vous pouvez vérifier ce problème en examinant la métrique TotalRequests.
Pour résoudre les problèmes d’utilisation et de latence élevées du disque :
- Optimisez les E/S de la machine virtuelle pour mettre à l’échelle les limites du disque dur virtuel.
- Augmentez le débit et réduisez la latence. Si vous constatez que vous avez une application sensible à la latence et que vous avez besoin d’un débit élevé, migrez vos disques durs virtuels vers le Stockage Premium Azure.
Règles de pare-feu de machine virtuelle bloquant le trafic
Pour résoudre un problème de flux de groupe de sécurité réseau, utilisez l’outil de vérification du flux IP de Network Watcher et la journalisation du flux NSG pour déterminer si un groupe NSG ou une route définie par l’utilisateur (UDR) interfère avec le flux du trafic.
Exécutez la vérification du flux IP et spécifiez la machine virtuelle locale et la machine virtuelle distante. Une fois que vous avez sélectionné Vérifier, Azure effectue un test logique sur les règles en place. Si le résultat est que l’accès est autorisé, utilisez les journaux de flux NSG.
Dans le portail, accédez aux groupes NSG. Sous les paramètres des journaux de flux, sélectionnez Activé. Réessayez alors de vous connecter à la machine virtuelle. Utilisez l’analytique du trafic de Network Watcher pour visualiser les données. Si le résultat est que l’accès est autorisé, c’est qu’il n’existe pas de règle de groupe de sécurité réseau bloquante.
Si vous avez atteint ce point et que vous n’avez pas encore diagnostiqué le problème, la machine virtuelle distante est probablement la cause. Désactivez le pare-feu sur la machine virtuelle distante et retestez la connectivité. Si vous pouvez vous connecter à la machine virtuelle distante avec le pare-feu désactivé, vérifiez les paramètres du pare-feu distant. Réactivez ensuite le pare-feu.
Incapacité des sous-réseaux front-end et back-end à communiquer
Par défaut, tous les sous-réseaux peuvent communiquer dans Azure. Si deux machines virtuelles sur deux sous-réseaux ne peuvent pas communiquer, il doit y avoir une configuration qui bloque les communications. Avant de vérifier les journaux de flux, exécutez l’outil de vérification du flux IP de la machine virtuelle front-end vers la machine virtuelle back-end. Cet outil effectue un test logique sur les règles du réseau.
S’il en résulte qu’un NSG sur le sous-réseau back-end bloque toutes les communications, reconfigurez ce NSG. Pour des raisons de sécurité, vous devez bloquer certaines communications avec le front-end parce que celui-ci est exposé à l’Internet public.
En bloquant la communication vers le back-end, vous limitez la surface d’exposition en cas d’attaque de programme malveillant ou de sécurité. Cependant, si le groupe NSG bloque tout, c’est qu’il n’est pas configuré correctement. Activez les protocoles et les ports spécifiques nécessaires.