Explorer l’architecture de la solution
Pour cerner l’objectif que nous souhaitons atteindre, nous allons revoir l’architecture des opérations de machine learning (MLOps, machine learning operations).
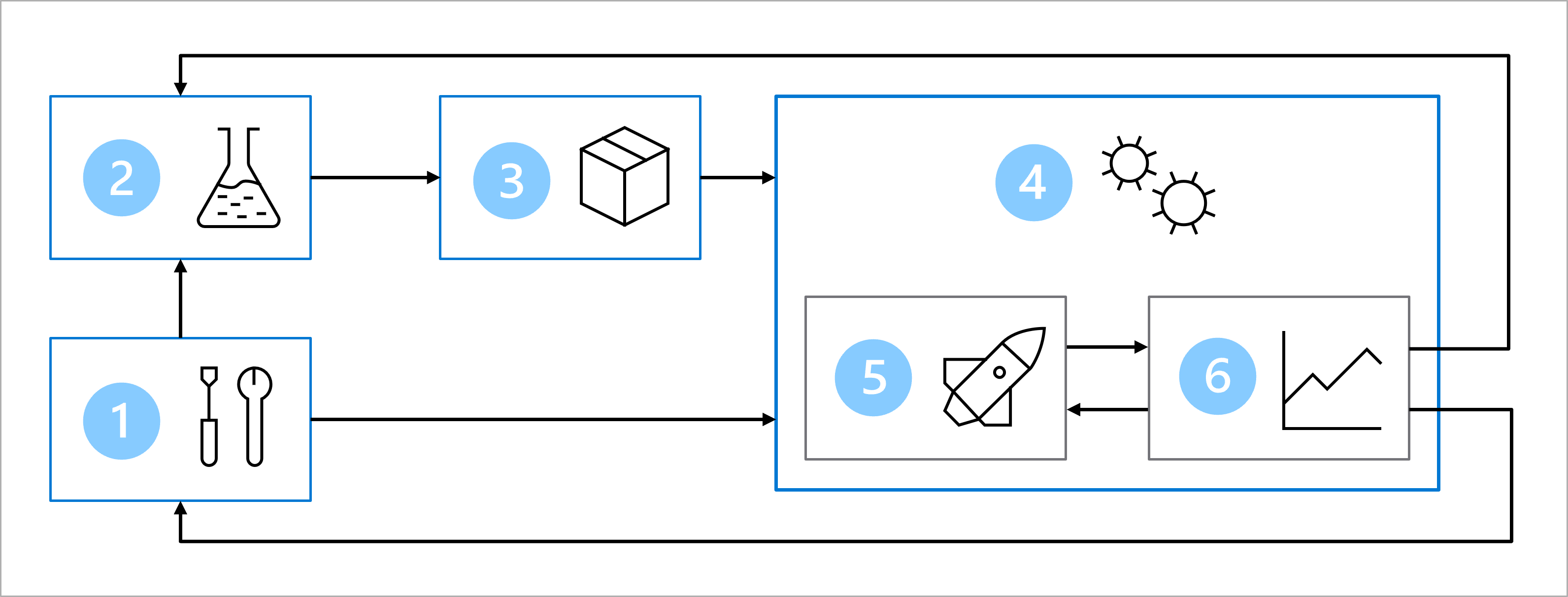
Imaginez que vous avez convenu de l’architecture suivante avec l’équipe de science des données et de développement pour entraîner, tester et déployer le modèle de classification du diabète :
Notes
Le diagramme est une représentation simplifiée d’une architecture MLOps. Pour obtenir une architecture plus détaillée, explorez les différents cas d’usage dans l’accélérateur de solution MLOps (v2).
L’architecture comprend les éléments suivants :
- Installation : créer toutes les ressources Azure nécessaires pour la solution.
- Développement de modèle (boucle interne) : explorer et traiter les données pour entraîner et évaluer le modèle.
- Intégration continue : empaqueter et inscrire le modèle.
- Déploiement de modèle (boucle externe) : déployer le modèle.
- Déploiement continu : tester le modèle et le promouvoir dans un environnement de production.
- Monitoring : superviser les performances du modèle et du point de terminaison.
L’équipe de science des données est responsable du développement du modèle. L’équipe de développement est chargée de l’intégration du modèle déployé à l’application web utilisée par les praticiens pour évaluer si un patient souffre de diabète. Vous avez pour responsabilité de faire passer le modèle du développement au déploiement.
Vous attendez de l’équipe de science des données qu’elle propose constamment des modifications des scripts utilisés pour entraîner le modèle. À chaque modification du script d’entraînement, vous devez réentraîner le modèle et le redéployer sur le point de terminaison existant.
Vous souhaitez permettre à l’équipe de science des données d’expérimenter le modèle sans modifier le code prêt pour la production. Vous souhaitez également avoir la certitude que tout code nouveau ou mis à jour fera automatiquement l’objet des contrôles de qualité convenus. Après avoir vérifié le code pour entraîner le modèle, vous allez utiliser le script d’entraînement mis à jour pour entraîner un nouveau modèle et le déployer.
Pour suivre les modifications et vérifier votre code avant de mettre à jour le code de production, il est nécessaire de travailler avec des branches. Vous avez convenu de ce qui suit avec l’équipe de science des données : chaque fois qu’elle souhaite apporter une modification, elle crée une branche de fonctionnalité pour créer une copie du code et apporte ses modifications à la copie.
N’importe quel scientifique des données peut créer une branche de fonctionnalité et travailler dans cette branche. Après avoir mis à jour le code, quand l’équipe souhaite en faire le nouveau code de production, elle doit créer une demande de tirage (pull request). Dans la demande de tirage, les modifications proposées sont visibles pour les autres personnes, qui peuvent ainsi réviser le code et discuter des modifications.
Chaque fois qu’une demande de tirage est créée, vous pouvez vérifier automatiquement si le code fonctionne et si la qualité du code est à la hauteur des standards de votre organisation. Quand le code réussit les contrôles de qualité, le scientifique des données en chef doit réviser les modifications et approuver les mises à jour pour que la demande de tirage puisse être fusionnée et que le code de la branche primaire puisse être mis à jour en conséquence.
Important
Personne ne doit être autorisé à pousser (push) des modifications sur la branche primaire. Pour protéger votre code, en particulier le code de production, il est recommandé de veiller à ce que la branche primaire ne puisse être mise à jour que par le biais de demandes de tirage qui doivent être approuvées.