Explorer l’architecture de la solution
Il est important de comprendre la solution dans sa globalité avant de procéder à l’implémentation pour avoir l’assurance que toutes les exigences sont respectées. Nous voulons également avoir la certitude que l’approche pour s’adapter facilement à l’avenir. L’objectif de cet exercice est de commencer à utiliser GitHub Actions comme outil d’orchestration et d’automatisation pour la stratégie d’opérations de machine learning (MLOps, machine learning operations) définie dans l’architecture de la solution.
Notes
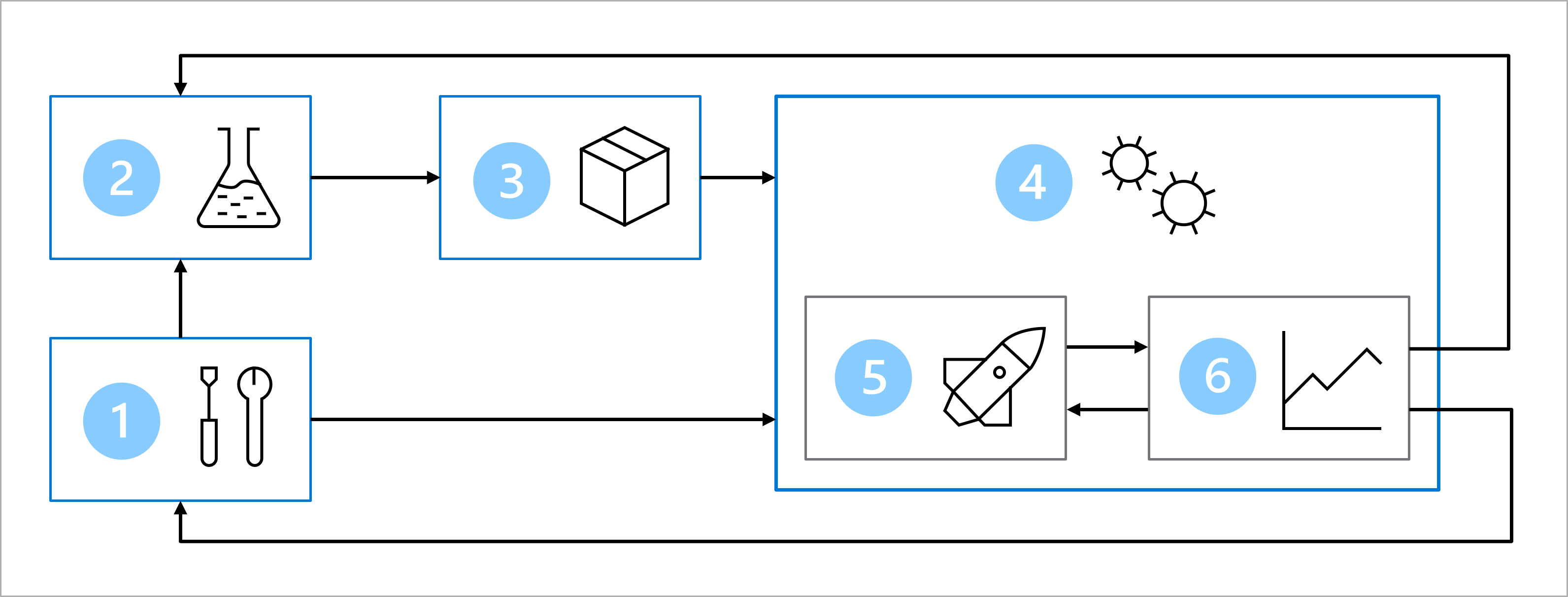
Le diagramme est une représentation simplifiée d’une architecture MLOps. Pour obtenir une architecture plus détaillée, explorez les différents cas d’usage dans l’accélérateur de solution MLOps (v2).
L’architecture comprend les éléments suivants :
- Installation : créer toutes les ressources Azure nécessaires pour la solution.
- Développement de modèle (boucle interne) : explorer et traiter les données pour entraîner et évaluer le modèle.
- Intégration continue : empaqueter et inscrire le modèle.
- Déploiement de modèle (boucle externe) : déployer le modèle.
- Déploiement continu : tester le modèle et le promouvoir dans un environnement de production.
- Monitoring : superviser les performances du modèle et du point de terminaison.
Plus précisément, nous allons automatiser la partie entraînement du développement de modèle (boucle interne), ce qui nous permettra finalement d’entraîner et d’inscrire rapidement plusieurs modèles pour le déploiement, dans des environnements de préproduction et de production.
L’espace de travail Azure Machine Learning, la capacité de calcul Azure Machine Learning et le dépôt GitHub ont tous été créés pour vous par l’équipe d’infrastructure.
En outre, le code permettant d’entraîner le modèle de classification est prêt pour la production et les données nécessaires à l’entraînement du modèle sont disponibles dans un stockage Blob Azure connecté à l’espace de travail Azure Machine Learning.
Avec votre implémentation, le passage d’une boucle interne à une boucle externe deviendra un processus automatisé s’exécutant chaque fois qu’un scientifique des données pousse un nouveau code de modèle sur le dépôt GitHub. Ceci permet la livraison continue de modèles Machine Learning aux consommateurs du modèle en aval comme l’application web qui utilisera le modèle de classification du diabète.