Partitionner des fichiers de données
Le partitionnement est une technique d’optimisation qui permet à Spark d’obtenir les meilleures performances sur les nœuds Worker. Des gains de performances supplémentaires peuvent être obtenus lors du filtrage des données dans les requêtes en éliminant les E/S disque non nécessaires.
Partitionner le fichier de sortie
Pour enregistrer un dataframe en tant que jeu de fichiers partitionné, utilisez la méthode partitionBy lors de l’écriture des données.
L’exemple suivant crée un champ Year dérivé. Ensuite, il l’utilise pour partitionner les données.
from pyspark.sql.functions import year, col
# Load source data
df = spark.read.csv('/orders/*.csv', header=True, inferSchema=True)
# Add Year column
dated_df = df.withColumn("Year", year(col("OrderDate")))
# Partition by year
dated_df.write.partitionBy("Year").mode("overwrite").parquet("/data")
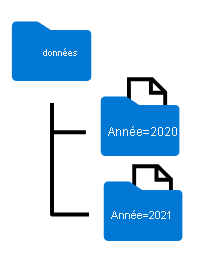
Les noms de dossiers générés lors du partitionnement d’un dataframe incluent le nom et la valeur de la colonne de partitionnement au format colonne=valeur, comme indiqué ici :
Remarque
Vous pouvez partitionner les données selon plusieurs colonnes, ce qui aboutit à une hiérarchie de dossiers pour chaque clé de partitionnement. Par exemple, vous pouvez partitionner la commande de l’exemple par année et par mois, afin que la hiérarchie de dossiers inclue un dossier pour chaque valeur des années, qui à son tour contient un sous-dossier pour chaque valeur des mois.
Filtrer des fichiers Parquet dans une requête
Lors de la lecture de données depuis des fichiers Parquet dans un dataframe, vous avez la possibilité d’extraire des données de n’importe quel dossier dans les dossiers hiérarchiques. Ce processus de filtrage est effectué en utilisant des valeurs explicites et des caractères génériques sur les champs partitionnés.
Dans l’exemple qui suit, le code suivant extrait les commandes client qui ont été passées en 2020.
orders_2020 = spark.read.parquet('/partitioned_data/Year=2020')
display(orders_2020.limit(5))
Notes
Les colonnes de partitionnement spécifiées dans le chemin de fichier sont omises dans le dataframe résultant. Les résultats produits par l’exemple de requête ne vont pas inclure la colonne Year : toutes les lignes seront de 2020.