Introduction
Le clustering est le processus de regroupement d’objets avec des objets similaires. Par exemple, dans l’image ci-dessous, nous avons une collection de coordonnées 2D qui ont été regroupées en trois catégories : en haut à gauche (jaune), en bas (rouge) et en haut à droite (bleu).
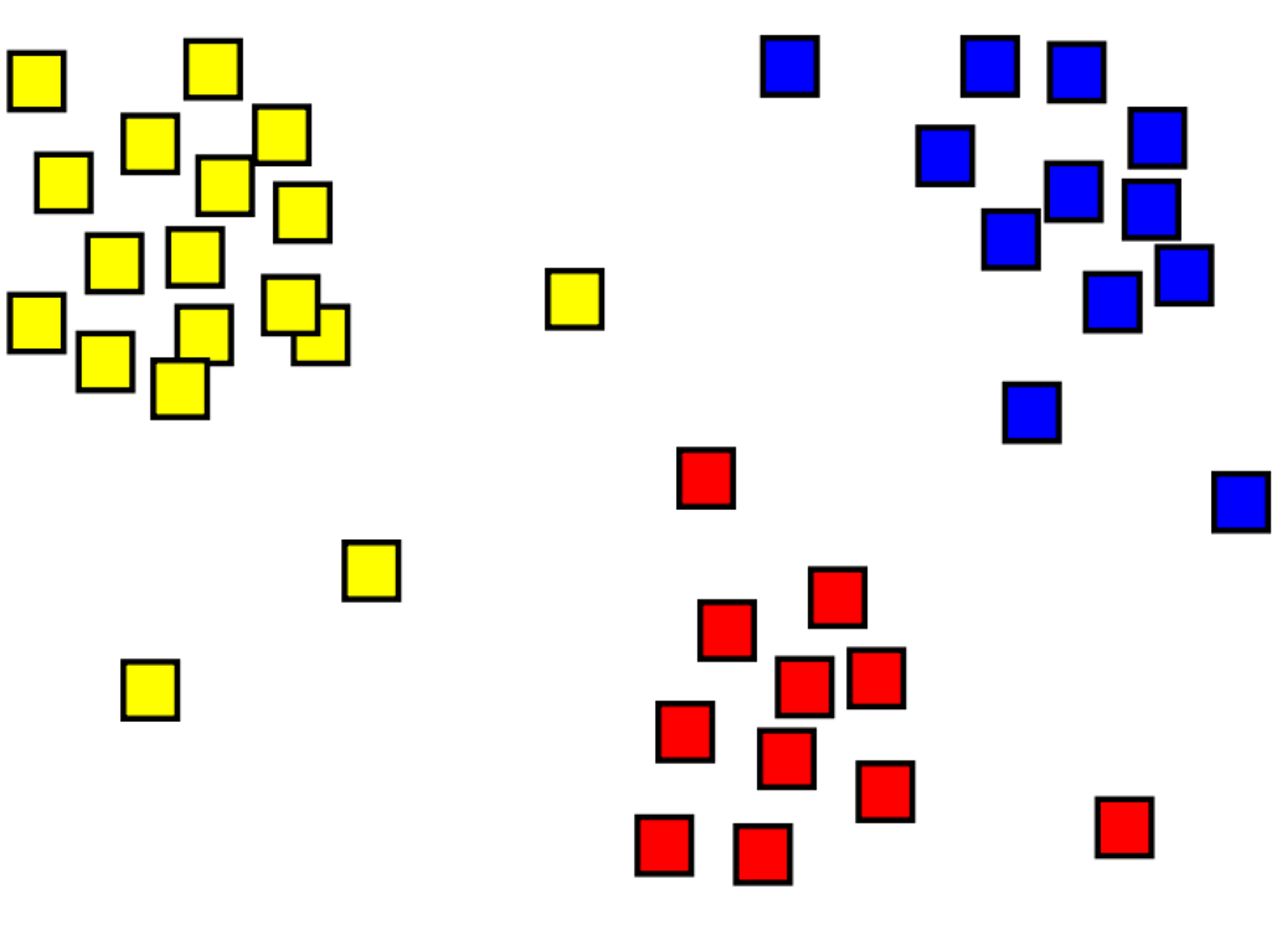
La principale différence entre les modèles de clustering et de classification est que le clustering est une méthode non supervisée, où la formation s’effectue sans étiquette. Les modèles de clustering identifient des exemples qui ont une collection de fonctionnalités similaire. Dans l’image précédente, les exemples qui se trouvent dans un emplacement similaire sont regroupés.
Le clustering est courant et utile pour l’exploration de nouvelles données où les schémas entre les points de données, comme les catégories générales, ne sont pas encore connus. Il est utilisé dans de nombreux champs qui doivent étiqueter automatiquement des données complexes, notamment l’analyse des réseaux sociaux, la connectivité du cerveau, le filtrage du courrier indésirable, etc.