Évaluer les modèles de classification
La précision de la formation d’un modèle de classification est bien moins importante que le fonctionnement de ce modèle quand des données nouvelles, non encore exploitées sont fournies. Après tout, nous effectuons l’apprentissage des modèles pour qu’ils puissent être utilisés sur les nouvelles données que nous trouvons dans le monde réel. Ainsi, une fois que nous entraîné un modèle de classification, nous évaluons son fonctionnement sur un ensemble de données nouvelles, non encore exploitées.
Dans les unités précédentes, nous avons créé un modèle qui prédit si un patient a du diabète ou pas en fonction de son niveau de glycémie. À présent, quand nous l’appliquons à des données qui ne faisaient pas partie du jeu d’entraînement, nous obtenons les prédictions suivantes.
| x | y | ŷ |
|---|---|---|
| 83 | 0 | 0 |
| 119 | 1 | 1 |
| 104 | 1 | 0 |
| 105 | 0 | 1 |
| 86 | 0 | 0 |
| 109 | 1 | 1 |
Rappelez-vous que x fait référence au niveau de glycémie, y fait référence au fait que le patient soit réellement diabétique, et ŷ fait référence à la prédiction du modèle en ce qui concerne la possibilité qu’il soit diabétique ou pas.
Simplement calculer le nombre de prédictions correctes est parfois trompeur ou trop simpliste pour nous permettre de comprendre les types d’erreurs qu’il fera dans le monde réel. Pour obtenir des informations plus détaillées, nous pouvons compiler les résultats dans une structure appelée une matrice de confusion, comme ceci :
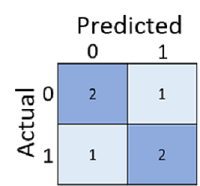
La matrice de confusion indique le nombre total de cas dans lesquels :
- Le modèle a prédit 0 et l’étiquette réelle est 0 (vrais négatifs, en haut à gauche)
- Le modèle a prédit 1 et l’étiquette réelle est 1 (vrais positifs, en bas à droite)
- Le modèle a prédit 0 et l’étiquette réelle est 1 (faux négatifs, en bas à gauche)
- Le modèle a prédit 1 et l’étiquette réelle est 0 (faux positifs, en haut à droite)
Les couleurs des cellules d’une matrice de confusion font souvent l’objet de variations, les valeurs plus élevées ayant une teinte plus foncée. Il est ainsi plus facile de voir une tendance diagonale forte de haut en bas à gauche, en mettant en surbrillance les cellules où la valeur prédite et la valeur réelle sont identiques.
À partir de ces valeurs de base, vous pouvez calculer une plage d’autres métriques qui peuvent vous aider à évaluer les performances du modèle. Par exemple :
- Exactitude : (TP+TN)/(TP+TN+FP+FN). Sur toutes les prédictions, combien étaient correctes ?
- Rappel : TP/(TP+FN). Sur tous les cas qui sont positifs, combien le modèle en a-t-il identifiés ?
- Précision : TP/(TP+FP). Sur tous les cas prédits positifs par le modèle, combien sont réellement positifs ?