Jeux de données de test et d’apprentissage
Les données utilisées pour effectuer l’apprentissage d’un modèle sont souvent appelées jeu de données de formation. Nous en avons déjà vu un exemple concret. Dans le monde réel malheureusement, nous ne savons pas à l’issue de la formation si notre modèle fonctionnera bien. Cette incertitude est due au fait que le jeu de données d’apprentissage peut être différent des données réelles.
Le surajustement
Un modèle est surajusté s’il fonctionne mieux sur les données de formation qu’avec d’autres données. Le nom fait référence au fait que le modèle est si bien ajusté qu’il a mémorisé les détails du jeu d’apprentissage, plutôt que de trouver des règles générales qui s’appliqueront à d’autres données. Le surajustement est courant mais pas souhaitable. En fin de compte, l’important est que le modèle fonctionne bien sur des données réelles.
Comment éviter le surajustement ?
Nous pouvons éviter de surajuster de plusieurs façons. La méthode la plus facile consiste à utiliser un modèle plus simple ou un jeu de données constituant une meilleure représentation du monde réel. Pour comprendre ces méthodes, prenons un scénario dans lequel les données réelles se présentent comme suit :
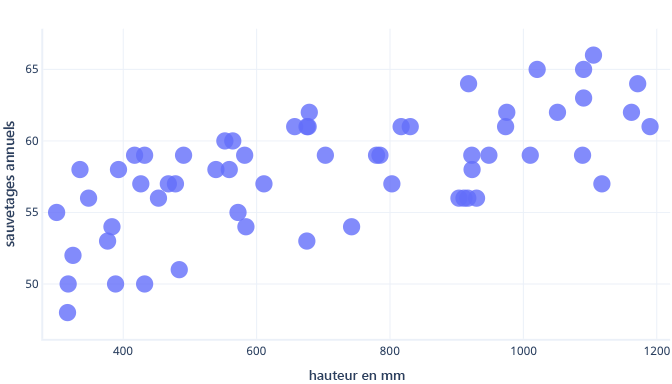
Supposons que nous collections des informations sur seulement cinq chiens et que nous fassions correspondre une courbe complexe à ce jeu de données d’apprentissage. L’ajustement est alors parfait :
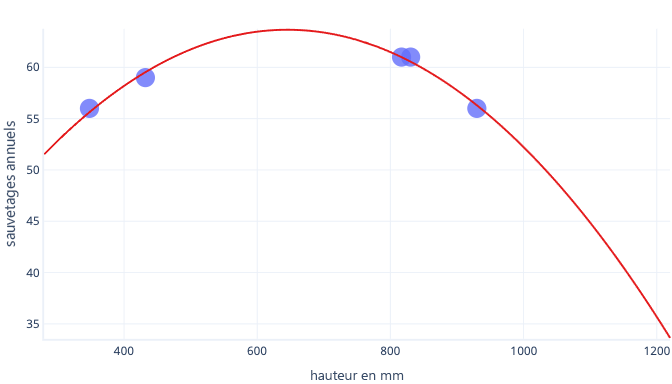
Lorsqu’il est utilisé dans le monde réel toutefois, ce modèle réalise des prédictions qui se révèlent incorrectes :
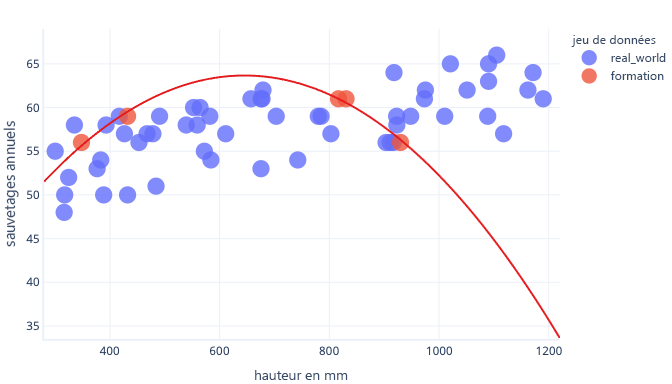
Avec un jeu de données plus représentatif et un modèle plus simple, la courbe d’ajustement s’avère proposer de meilleures prédictions, (même si elles ne sont pas parfaites) :
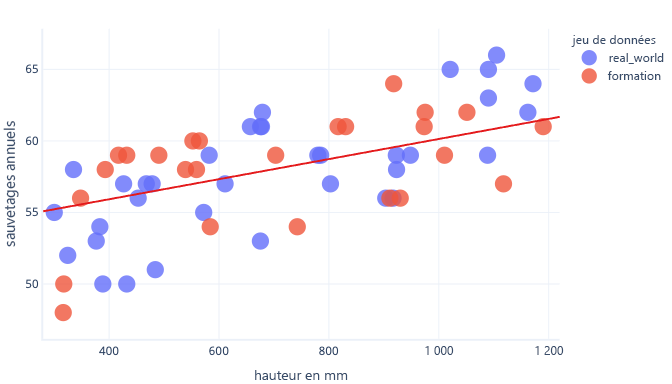
Un moyen complémentaire d’éviter le surajustement consiste à arrêter l’apprentissage une fois que le modèle a appris des règles générales, mais avant qu’il ne surinterprète les données. Il implique toutefois de détecter à quel moment un surajustement commence à se produire, ce qui est possible avec un jeu de données de test.
Le jeu de données de test
Un jeu de données de test, également appelé jeu de données de validation, consiste en un ensemble de données similaire au jeu de données d’apprentissage. Pour le créer, on fractionne généralement un grand jeu de données : une partie est appelée jeu de données d’apprentissage, l’autre jeu de données de test.
Le rôle du jeu de données d’apprentissage consiste à effectuer l’apprentissage du modèle, comme nous l’avons déjà vu. Le jeu de données de test, lui, sert à vérifier si le modèle fonctionne bien. Il ne contribue pas directement à l’apprentissage.
L’intérêt du jeu de données de test
L’intérêt d’un jeu de données de test est double.
Tout d’abord, si les performances du test cessent de s’améliorer pendant la formation, nous pouvons arrêter : il n’y a aucune raison de poursuivre. Nous risquerions ce faisant d’encourager le modèle à apprendre des détails sur le jeu de données d’apprentissage qui ne se trouvent pas dans le jeu de données de test, ce qui produirait un surajustement.
Deuxièmement, le jeu de données de test peut être utilisé après l’apprentissage. Cela nous permet de savoir si le modèle final a des chances de bien fonctionner une fois confronté à des données réelles qu’il n’a pas encore vues.
L’incidence sur les fonctions de coût
Lorsque l’on utilise à la fois un jeu de données d’apprentissage et un jeu de données de test, deux fonctions de coût sont calculées.
La première utilise le jeu de données d’apprentissage, comme nous l’avons vu précédemment. Elle est transmise à l’optimiseur et utilisée pour l’apprentissage du modèle.
La seconde fonction de coût est calculée à l’aide du jeu de données de test. Elle permet de vérifier si le modèle fonctionne bien dans le monde réel. Son résultat ne sert pas dans l’apprentissage du modèle. Pour le calculer, il faut suspendre l’apprentissage, regarder si le modèle se révèle performant sur un jeu de données de test, puis reprendre l’apprentissage.