Dépôts et développement basé sur le tronc
De nombreux scientifiques des données préfèrent travailler avec Python ou R pour définir des charges de travail Machine Learning. Vous pouvez avoir des notebooks ou des scripts Jupyter pour préparer des données ou entraîner un modèle.
Travailler sur les éléments du code devient plus facile lorsque vous utilisez le contrôle de code source. Le contrôle de code source est la pratique consistant à gérer le code et à effectuer le suivi de tous les changements que votre équipe apporte au code.
Si vous utilisez des outils DevOps comme Azure DevOps ou GitHub, le code est stocké dans un dépôt, ou repo/repository en anglais.
Référentiel
Lors de la configuration du framework MLOps, un ingénieur Machine Learning crée probablement le dépôt. Que vous choisissiez d’utiliser Azure Repos dans Azure DevOps ou des dépôts GitHub, les deux utilisent des dépôts Git pour stocker votre code.
Il existe généralement deux façons de délimiter le dépôt :
- Mono-dépôt : Gardez toutes les charges de travail de machine learning au sein du même dépôt.
- Multi-dépôt : Créez un dépôt distinct pour chaque nouveau projet de machine learning.
L’approche que votre équipe préférera dépend de qui accédera à quoi. Si vous souhaitez garantir un accès rapide à tous les éléments de code, les mono-dépôts devraient mieux répondre aux besoins de votre équipe. Si vous voulez seulement accorder aux personnes l’accès à un projet si celles-ci travaillent activement dessus, il est possible que votre équipe préfère travailler avec plusieurs dépôts. Gardez à l’esprit que la gestion du contrôle d’accès peut créer davantage de surcharge.
Structurer votre dépôt
Quelle que soit l’approche que vous choisissez, il est recommandé de se mettre d’accord sur la structure de dossiers de niveau supérieur standard pour vos projets. Par exemple, vous pouvez avoir les dossiers suivants dans tous vos dépôts :
.cloud: contient le code spécifique au cloud comme les modèles pour créer un espace de travail Azure Machine Learning..ad/.github: contient des artefacts Azure DevOps ou GitHub comme les pipelines YAML pour automatiser les workflows.src: contient tout le code (scripts Python ou R) utilisé pour les charges de travail Machine Learning telles que le prétraitement des données ou l’entraînement de modèles.docs: contient les fichiers Markdown ou autres documentations utilisés pour décrire le projet.pipelines: contient les définitions de pipelines Azure Machine Learning.tests: contient les tests unitaires et d’intégration utilisés pour détecter les bogues et les problèmes dans votre code.notebooks: contient les notebooks Jupyter, essentiellement utilisés pour les expérimentations.
Notes
Les données d’entraînement ne doivent pas être incluses dans votre dépôt. Les données doivent être stockées dans une base de données ou un lac de données. Azure Machine Learning peut avoir un accès direct à une base de données ou un lac de données en stockant les informations de connexion comme magasin de données.
En ayant une structure standard que chaque projet utilise, les scientifiques des données et autres collaborateurs trouveront plus facilement le code sur lequel ils ont besoin de travailler.
Conseil
Retrouvez d’autres Bonnes pratiques pour structurer les projets de science des données.
Pour savoir comment travailler avec des dépôts en tant que scientifique des données, vous allez apprendre le développement basé sur le tronc.
Développement basé sur le tronc
La plupart des projets de développement logiciel utilisent Git comme système de contrôle de code source, utilisé à la fois par Azure DevOps et GitHub.
L’avantage principal de l’utilisation de Git est une collaboration facile sur le code tout en suivant également les changements qui sont apportés. Vous pouvez aussi ajouter des portes d’approbation pour vous assurer que seuls les changements qui ont été révisés et acceptés seront apportés au code de production.
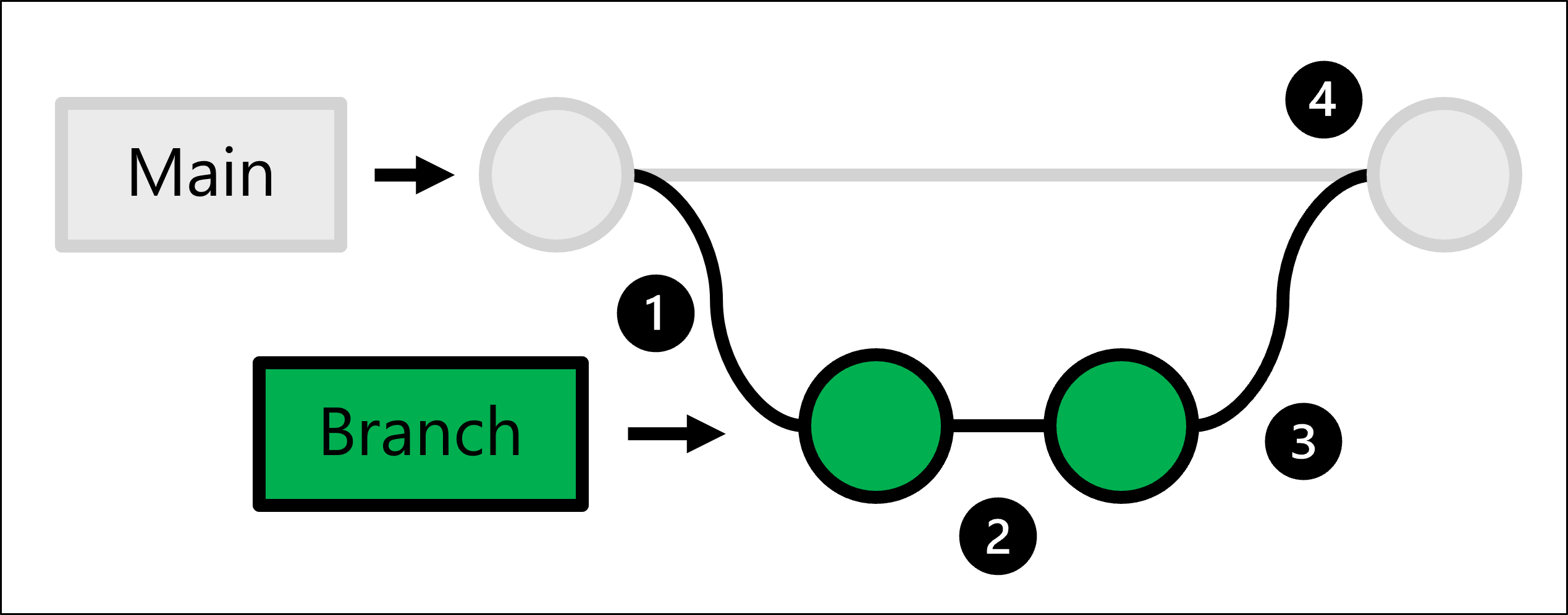
Pour accomplir tout cela, Git utilise le développement basé sur le tronc qui vous permet de créer des branches.
Le code de production est hébergé dans la branche main. Chaque fois que quelqu’un veut apporter un changement :
- Vous créez une copie complète du code de production en créant une branche.
- Dans la branche que vous avez créée, vous apportez vos changements et vous les testez.
- Une fois que les changements de votre branche sont prêts, vous pouvez demander à quelqu’un de les réviser.
- Si les changements sont approuvés, vous fusionnez la branche que vous avez créée avec le dépôt principal et le code de production sera mis à jour pour refléter vos changements.