Indexer toutes les données à l’aide de l’API Push Recherche Azure AI
L’API REST est le moyen le plus souple de pousser des données dans un index Recherche Azure AI. Vous pouvez utiliser n’importe quel langage de programmation ou de manière interactive avec n’importe quelle application pouvant publier des requêtes JSON sur un point de terminaison.
Ici, vous allez voir comment utiliser l’API REST efficacement et explorer les opérations disponibles. Vous allez ensuite examiner le code .NET Core et voir comment optimiser l’ajout de grandes quantités de données via l’API.
Opérations d’API REST prises en charge
Il existe deux API REST prises en charge fournies par la recherche IA. API de recherche et de gestion. Ce module se concentre sur les API REST de recherche qui fournissent des opérations sur cinq fonctionnalités de recherche :
| Fonctionnalité | Operations |
|---|---|
| Index | Créer, supprimer, mettre à jour et configurer. |
| Document | Obtenir, ajouter, mettre à jour et supprimer. |
| Indexation | Configurer les sources de données et la planification sur des sources de données limitées. |
| Ensemble de compétences | Obtenir, créer, supprimer, lister et mettre à jour. |
| Carte de synonymes | Obtenir, créer, supprimer, lister et mettre à jour. |
Comment appeler l’API REST de recherche
Si vous souhaitez appeler l’une des API de recherche dont vous avez besoin :
- Utilisez le point de terminaison HTTPS (sur le port 443 par défaut) fourni par votre service de recherche. Vous devez inclure un paramètre api-version dans l’URI.
- L’en-tête de requête doit inclure un attribut api-key.
Pour rechercher le point de terminaison, ainsi que les paramètres api-version et api-key, accédez au portail Azure.

Dans le portail, accédez à votre service de recherche, puis sélectionnez l’Explorateur de recherche. Le point de terminaison de l’API REST se trouve dans le champ URL de la requête. La première partie de l’URL est le point de terminaison (par exemple https://azsearchtest.search.windows.net), tandis que la chaîne de requête montre le paramètre api-version (par exemple api-version=2023-07-01-Preview).

Pour rechercher le paramètre api-key à gauche, sélectionnez Clés. La clé d’administration primaire ou secondaire peut être utilisée si vous vous servez de l’API REST pour faire plus que juste interroger l’index. Si vous avez seulement besoin de rechercher un index, vous pouvez créer et utiliser des clés de requête.
Pour ajouter, mettre à jour ou supprimer des données dans un index, vous devez utiliser une clé d’administration.
Ajouter des données à un index
Utilisez une requête HTTP POST avec la fonctionnalité d’index dans ce format :
POST https://[service name].search.windows.net/indexes/[index name]/docs/index?api-version=[api-version]
Le corps de votre requête doit indiquer au point de terminaison REST l’action à entreprendre sur le document, sur quel document appliquer l’action et les données à utiliser.
Le document JSON doit être au format suivant :
{
"value": [
{
"@search.action": "upload (default) | merge | mergeOrUpload | delete",
"key_field_name": "unique_key_of_document", (key/value pair for key field from index schema)
"field_name": field_value (key/value pairs matching index schema)
...
},
...
]
}
| Action | Description |
|---|---|
| upload | Comme pour un upsert dans le langage SQL, le document sera créé ou remplacé. |
| merge | La fusion met à jour un document existant avec les champs spécifiés. La fusion échoue si aucun document n’est trouvé. |
| mergeOrUpload | La fusion met à jour un document existant avec les champs spécifiés et le charge si le document n’existe pas. |
| delete | Supprime l’ensemble du document, vous devez uniquement spécifier le key_field_name. |
Si votre requête réussit, l’API retourne un code d’état 200.
Remarque
Pour obtenir la liste complète de tous les codes de réponse et messages d’erreur, consultez Ajouter, mettre à jour ou supprimer des documents (API REST Recherche Azure AI)
Cet exemple JSON charge l’enregistrement client dans l’unité précédente :
{
"value": [
{
"@search.action": "upload",
"id": "5fed1b38309495de1bc4f653",
"firstName": "Sims",
"lastName": "Arnold",
"isAlive": false,
"age": 35,
"address": {
"streetAddress": "Sumner Place",
"city": "Canoochee",
"state": "Palau",
"postalCode": "1558"
},
"phoneNumbers": [
{
"phoneNumber": {
"type": "home",
"number": "+1 (830) 465-2965"
}
},
{
"phoneNumber": {
"type": "home",
"number": "+1 (889) 439-3632"
}
}
]
}
]
}
Vous pouvez ajouter autant de documents dans le tableau de valeurs que vous le souhaitez. Toutefois, pour des performances optimales, pensez à faire des lots de documents dans vos requêtes jusqu’à un maximum de 1 000 documents, ou 16 Mo en taille totale.
Utiliser .NET Core pour indexer les données
Pour des performances optimales, utilisez la dernière bibliothèque de client Azure.Search.Document, actuellement la version 11. Vous pouvez installer la bibliothèque de client avec NuGet :
dotnet add package Azure.Search.Documents --version 11.4.0
La façon dont votre index fonctionne est basée sur six facteurs clés :
- Niveau de service de recherche et nombre de réplicas et de partitions activés.
- Complexité du schéma d’index. Réduisez le nombre de propriétés (à rechercher, à choix multiples, à trier) de chaque champ.
- Nombre de documents dans chaque lot, la meilleure taille dépend du schéma d’index et de la taille des documents.
- Dans quelle mesure votre approche est multithread.
- Gestion des erreurs et limitation. Utilisez une stratégie de nouvelle tentative suite à une interruption exponentielle.
- Où résident vos données, essayez d’indexer vos données près de votre index de recherche. Par exemple, exécutez les chargements à partir de l’environnement Azure.
Calculer votre taille de lot optimale
Comme le calcul de la meilleure taille de lot est un facteur clé pour améliorer les performances, examinons une approche dans le code.
public static async Task TestBatchSizesAsync(SearchClient searchClient, int min = 100, int max = 1000, int step = 100, int numTries = 3)
{
DataGenerator dg = new DataGenerator();
Console.WriteLine("Batch Size \t Size in MB \t MB / Doc \t Time (ms) \t MB / Second");
for (int numDocs = min; numDocs <= max; numDocs += step)
{
List<TimeSpan> durations = new List<TimeSpan>();
double sizeInMb = 0.0;
for (int x = 0; x < numTries; x++)
{
List<Hotel> hotels = dg.GetHotels(numDocs, "large");
DateTime startTime = DateTime.Now;
await UploadDocumentsAsync(searchClient, hotels).ConfigureAwait(false);
DateTime endTime = DateTime.Now;
durations.Add(endTime - startTime);
sizeInMb = EstimateObjectSize(hotels);
}
var avgDuration = durations.Average(timeSpan => timeSpan.TotalMilliseconds);
var avgDurationInSeconds = avgDuration / 1000;
var mbPerSecond = sizeInMb / avgDurationInSeconds;
Console.WriteLine("{0} \t\t {1} \t\t {2} \t\t {3} \t {4}", numDocs, Math.Round(sizeInMb, 3), Math.Round(sizeInMb / numDocs, 3), Math.Round(avgDuration, 3), Math.Round(mbPerSecond, 3));
// Pausing 2 seconds to let the search service catch its breath
Thread.Sleep(2000);
}
Console.WriteLine();
}
L’approche consiste à augmenter la taille du lot et à surveiller le temps nécessaire pour recevoir une réponse valide. Le code boucle de 100 à 1 000, en étapes de 100 documents. Pour chaque taille de lot, il génère la taille du document, le temps pour obtenir une réponse et la durée moyenne par Mo. L’exécution de ce code donne des résultats qui ressemblent à ceci :
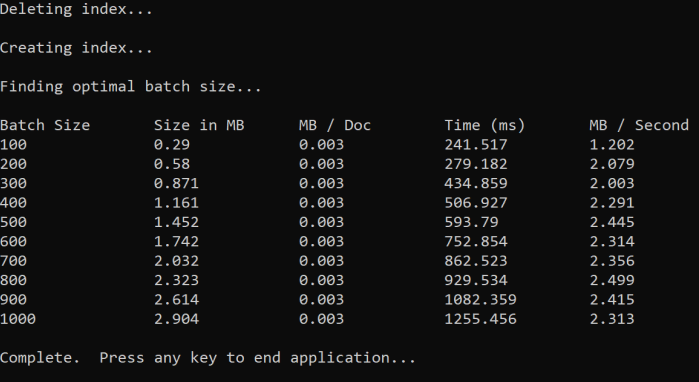
Dans l’exemple ci-dessus, la meilleure taille de lot pour le débit est de 2.499 Mo par seconde, 800 documents par lot.
Implémenter une stratégie de nouvelle tentative d’interruption exponentielle
Si votre index commence à limiter les requêtes en raison de surcharges, il répond avec un état 503 (demande rejetée en raison d’une charge importante) ou 207 (des documents ont échoué dans le lot). Vous devez gérer ces réponses, l’interruption est une bonne stratégie. L’interruption signifie suspendre pendant quelques temps avant de retenter votre requête. Si vous augmentez cette durée pour chaque erreur, votre interruption devient exponentielle.
Examinez ce code :
// Implement exponential backoff
do
{
try
{
attempts++;
result = await searchClient.IndexDocumentsAsync(batch).ConfigureAwait(false);
var failedDocuments = result.Results.Where(r => r.Succeeded != true).ToList();
// handle partial failure
if (failedDocuments.Count > 0)
{
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
else
{
Console.WriteLine("[Batch starting at doc {0} had partial failure]", id);
Console.WriteLine("[Retrying {0} failed documents] \n", failedDocuments.Count);
// creating a batch of failed documents to retry
var failedDocumentKeys = failedDocuments.Select(doc => doc.Key).ToList();
hotels = hotels.Where(h => failedDocumentKeys.Contains(h.HotelId)).ToList();
batch = IndexDocumentsBatch.Upload(hotels);
Task.Delay(delay).Wait();
delay = delay * 2;
continue;
}
}
return result;
}
catch (RequestFailedException ex)
{
Console.WriteLine("[Batch starting at doc {0} failed]", id);
Console.WriteLine("[Retrying entire batch] \n");
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
Task.Delay(delay).Wait();
delay = delay * 2;
}
} while (true);
Le code fait le suivi des documents ayant échoué dans un lot. Si une erreur se produit, il attend un délai, puis double le délai pour l’erreur suivante.
Enfin, il existe un nombre maximal de nouvelles tentatives et, si ce nombre maximal est atteint, le programme ferme.
Utiliser le threading pour améliorer les performances
Vous pouvez effectuer le chargement des documents en combinant la stratégie d’interruption ci-dessus avec une approche de threading. Voici quelques exemples de code :
public static async Task IndexDataAsync(SearchClient searchClient, List<Hotel> hotels, int batchSize, int numThreads)
{
int numDocs = hotels.Count;
Console.WriteLine("Uploading {0} documents...\n", numDocs.ToString());
DateTime startTime = DateTime.Now;
Console.WriteLine("Started at: {0} \n", startTime);
Console.WriteLine("Creating {0} threads...\n", numThreads);
// Creating a list to hold active tasks
List<Task<IndexDocumentsResult>> uploadTasks = new List<Task<IndexDocumentsResult>>();
for (int i = 0; i < numDocs; i += batchSize)
{
List<Hotel> hotelBatch = hotels.GetRange(i, batchSize);
var task = ExponentialBackoffAsync(searchClient, hotelBatch, i);
uploadTasks.Add(task);
Console.WriteLine("Sending a batch of {0} docs starting with doc {1}...\n", batchSize, i);
// Checking if we've hit the specified number of threads
if (uploadTasks.Count >= numThreads)
{
Task<IndexDocumentsResult> firstTaskFinished = await Task.WhenAny(uploadTasks);
Console.WriteLine("Finished a thread, kicking off another...");
uploadTasks.Remove(firstTaskFinished);
}
}
// waiting for the remaining results to finish
await Task.WhenAll(uploadTasks);
DateTime endTime = DateTime.Now;
TimeSpan runningTime = endTime - startTime;
Console.WriteLine("\nEnded at: {0} \n", endTime);
Console.WriteLine("Upload time total: {0}", runningTime);
double timePerBatch = Math.Round(runningTime.TotalMilliseconds / (numDocs / batchSize), 4);
Console.WriteLine("Upload time per batch: {0} ms", timePerBatch);
double timePerDoc = Math.Round(runningTime.TotalMilliseconds / numDocs, 4);
Console.WriteLine("Upload time per document: {0} ms \n", timePerDoc);
}
Ce code utilise des appels asynchrones à une fonction ExponentialBackoffAsync qui implémente la stratégie d’interruption. Vous appelez la fonction à l’aide de threads, par exemple, le nombre de cœurs dont dispose votre processeur. Lorsque le nombre maximal de threads a été utilisé, le code attend qu’un thread se termine. Il crée ensuite un nouveau thread jusqu’à ce que tous les documents soient chargés.