Indexer des données à partir de sources de données externes à l’aide d’Azure Data Factory
L’ajout de données externes qui ne résident pas dans Azure est un besoin courant dans la solution de recherche d’une organisation. Azure AI Search est flexible, car il permet de créer et de transmettre des données dans des index.
Envoyer des données dans un index de recherche à l’aide d’Azure Data Factory (ADF)
Une première approche est une option de code zéro pour envoyer (push) des données dans un index à l’aide d’ADF. ADF est fourni avec des connexions à près de 100 magasins de données différents. Avec des connecteurs tels que HTTP et REST qui vous permettent de connecter un nombre illimité de magasins de données. Ces magasins de données sont utilisés comme source ou cible (appelées récepteurs dans l’activité de copie) dans les pipelines.
Le connecteur d’index Recherche d’IA Azure peut être utilisé comme récepteur dans une activité de copie.
Créer un pipeline ADF pour envoyer des données dans un index de recherche
Les étapes à suivre pour utiliser et le pipeline ADF pour envoyer des données dans un index de recherche sont les suivantes :
- Créez un index Recherche d’IA Azure avec tous les champs dans lesquelles vous souhaitez stocker des données.
- Créez un pipeline avec une étape de copie des données.
- Créez une connexion de source de données à l’emplacement où résident vos données.
- Créez un récepteur pour vous connecter à votre index de recherche.
- Mappez les champs de vos données sources à votre index de recherche.
- Exécutez le pipeline pour envoyer (push) les données dans l’index.
Par exemple, imaginez que vous avez des données client au format JSON hébergés en externe. Vous souhaitez copier ces clients dans un index de recherche. Le json est au format suivant :
{
"_id": "5fed1b38309495de1bc4f653",
"firstName": "Sims",
"lastName": "Arnold",
"isAlive": false,
"age": 35,
"address": {
"streetAddress": "Sumner Place",
"city": "Canoochee",
"state": "Palau",
"postalCode": 1558
},
"phoneNumbers": [
{
"type": "home",
"number": "+1 (830) 465-2965"
},
{
"type": "home",
"number": "+1 (889) 439-3632"
}
]
}
Créer un index de recherche
Créez un service Recherche d’IA Azure et un index dans lequel stocker ces informations. Si vous avez terminé la Créer une solution Recherche d’IA Azure module, vous avez vu comment procéder. Suivez les étapes pour créer le service de recherche, mais arrêtez au point d’importer des données. Comme l’envoi de données vers un index n’a pas besoin de créer un indexeur ou un ensemble de compétences.
Créez un index et ajoutez ces champs et propriétés :

Pour le moment, vous devez d’abord créer l’index, car ADF ne peut pas créer d’index.
Créer un pipeline à l’aide de l’outil De copie de données ADF
Ouvrez le Azure Data Factory Studio, puis sélectionnez votre abonnement Azure et le nom de votre fabrique de données.

Sélectionnez ingérer.
Cliquez sur Suivant.
Remarque
Vous pouvez choisir de planifier le pipeline si vos données changent et que vous devez conserver votre index up-to-date. Pour cet exemple, vous allez importer les données une seule fois.
Créer le service lié source
Dans type de source, sélectionnez HTTP .
En regard de connexion, sélectionnez + Nouvelle connexion.
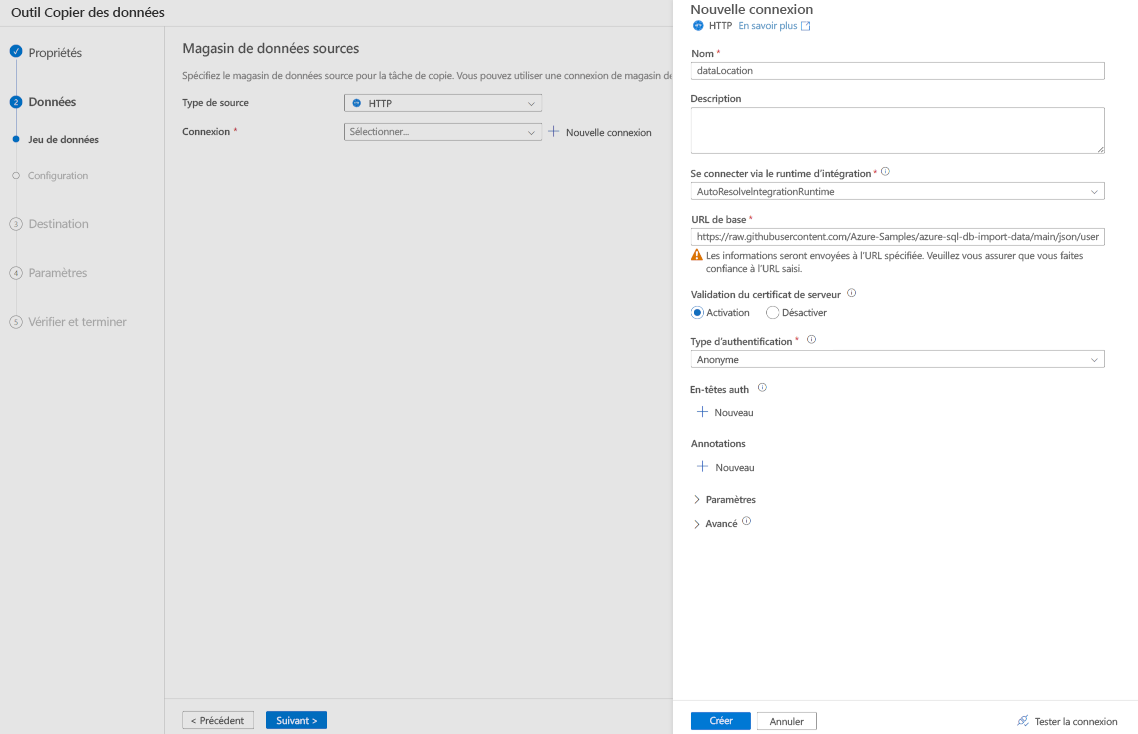
Dans le volet Nouvelle connexion, dans Nom entrez dataLocation.
Dans l’URL de base , entrez l’emplacement où réside votre fichier JSON, dans cet exemple, entrez https://raw.githubusercontent.com/Azure-Samples/azure-sql-db-import-data/main/json/user1.json.
Dans type d’authentification, sélectionnez anonyme .
Sélectionnez Créer.
Cliquez sur Suivant.
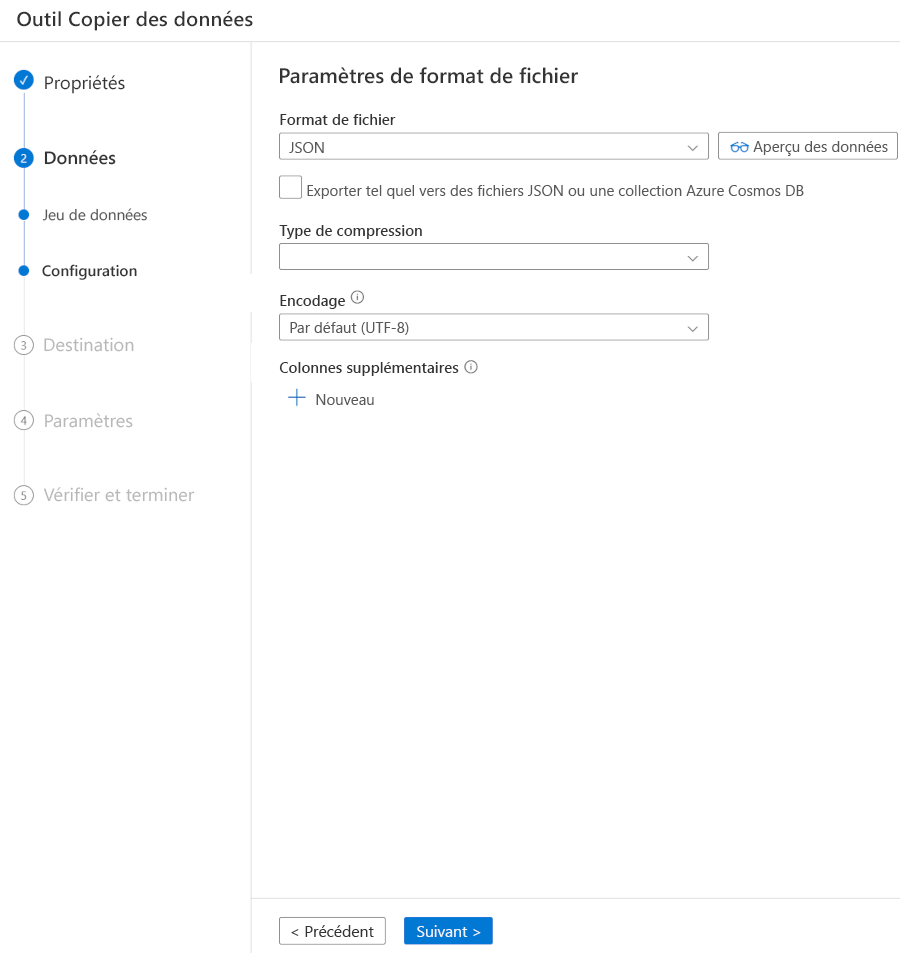
Dans format de fichier, sélectionnez JSON .
Cliquez sur Suivant.


Créer le service lié cible
Dans type de destination, sélectionnez Recherche Azure. Sélectionnez ensuite + Nouvelle connexion.
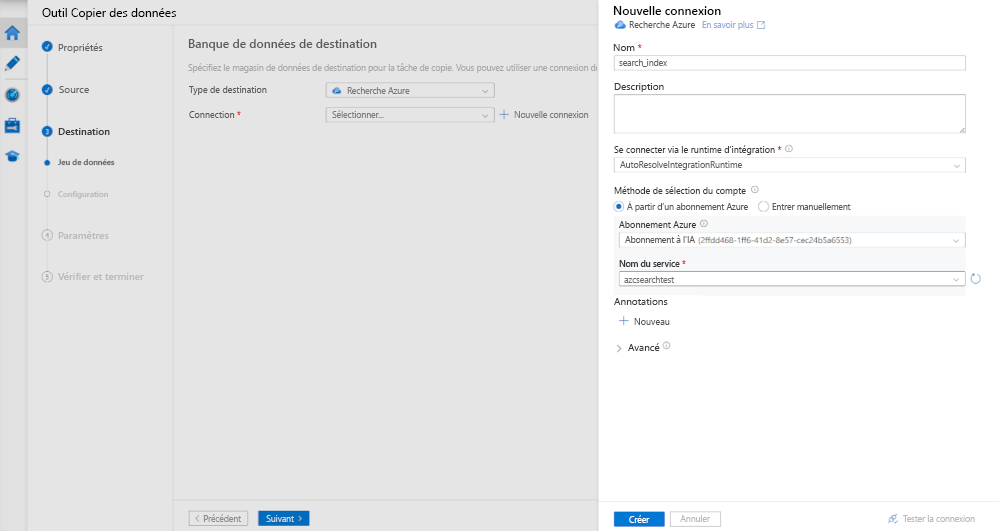
Dans le volet Nouvelle connexion, dans Nom entrez search_index.
Dans abonnement Azure, sélectionnez votre abonnement Azure.
Dans nom du service, sélectionnez votre service Recherche Azure AI.
Sélectionnez Créer.
Dans le volet magasin de données de destination, dans cible, sélectionnez l’index de recherche que vous avez créé.

Mapper les champs sources aux champs cibles
Cliquez sur Suivant.
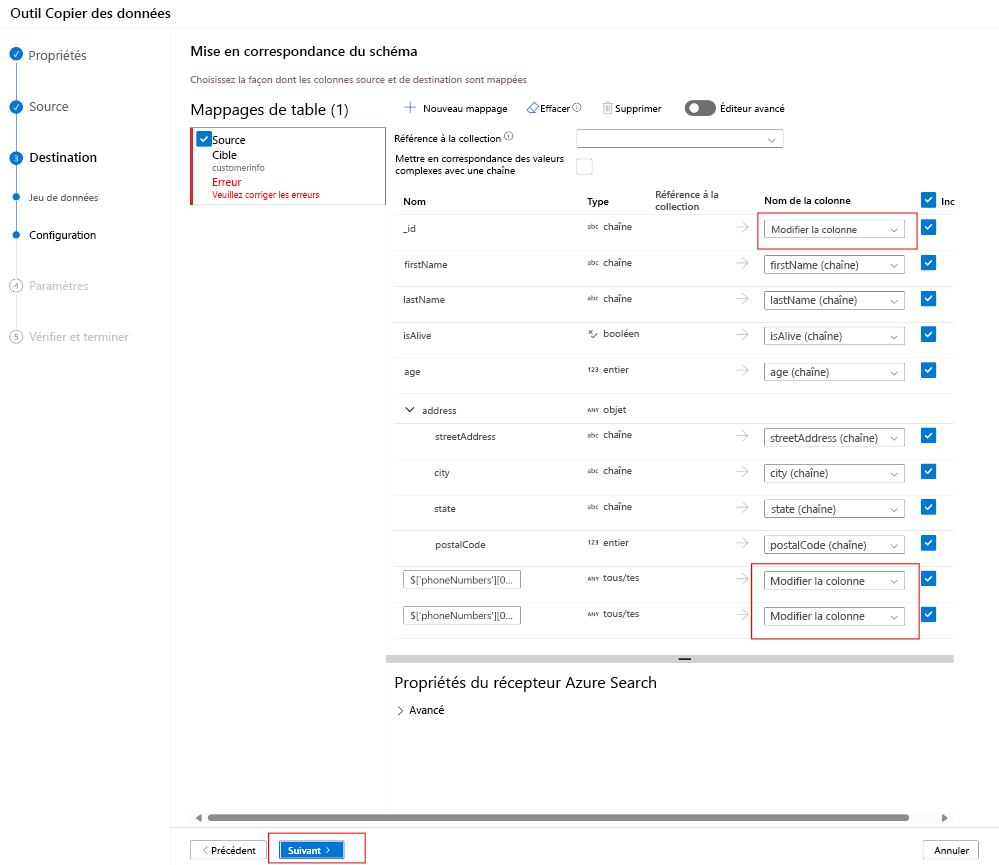
Si vous avez créé un index avec des noms de champs qui correspondent aux attributs JSON, ADF mappe automatiquement le JSON au champ de votre index de recherche.
Dans l’exemple ci-dessus, trois champs du document JSON doivent être mappés aux champs de l’index.
Mappez vos champs, puis sélectionnez suivant.
Dans le volet paramètres de, dans nom de tâche, entrez jsonToSearchIndex.
Cliquez sur Suivant.

Exécuter le pipeline pour envoyer (push) les données dans l’index
Dans le volet résumé , sélectionnez suivant .
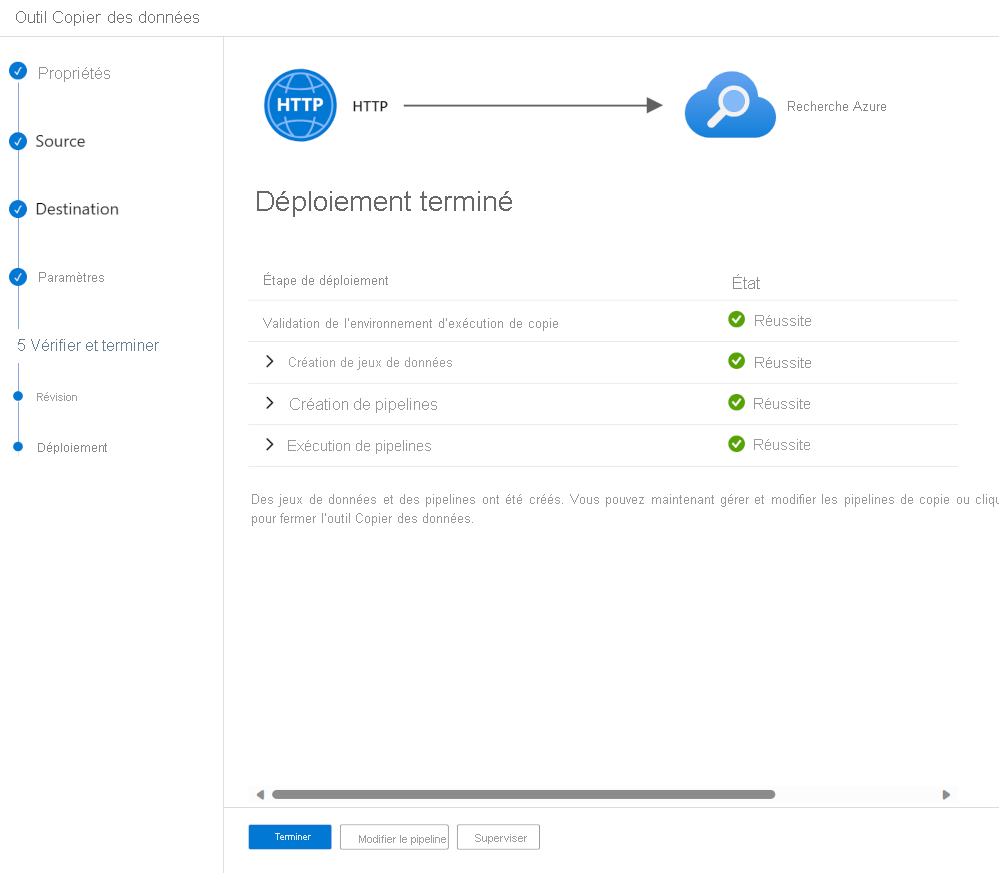
Une fois le pipeline validé et déployé, sélectionnez Terminer.

Le pipeline a été déployé et exécuté. Le document JSON a été ajouté à votre index de recherche. Vous pouvez utiliser le portail Azure et exécuter une recherche dans l’Explorateur de recherche. Vous devez voir les données JSON importées.

En suivant ces étapes, vous avez vu comment envoyer des données à un index. Le pipeline que vous avez créé par défaut fusionne les mises à jour dans l’index. Si vous avez modifié les données JSON et réexécutez le pipeline, l’index de recherche est mis à jour. Vous pouvez modifier le comportement d’écriture pour charger uniquement si vous souhaitez que les données soient remplacées chaque fois que vous exécutez votre pipeline.
Limitations de l’utilisation de la Recherche Azure AI intégrée en tant que service lié
Actuellement, le service lié Recherche IA Azure en tant que récepteur prend uniquement en charge les champs suivants :
| Type de données Recherche Azure AI |
|---|
| Chaîne |
| Int32 |
| Int64 |
| Double |
| Booléen |
| DataTimeOffset |
Cela signifie que Les complexTypes et les tableaux ne sont pas pris en charge actuellement. L’analyse du document JSON ci-dessus signifie qu’il n’est pas possible de mapper tous les numéros de téléphone du client. Seul le premier numéro de téléphone a été mappé.