Comment effectuer des tests d’évaluation dans HBase
Yahoo Le point de Référence Cloud Serving Yahoo ! (YCSB) est une spécification Open source et une suite de programmes permettant d’évaluer les performances relatives des systèmes de gestion de base de données NoSQL. Dans cet exercice, vous allez exécuter le test d’évaluation des performances de deux clusters HBase dont l’un est l’utilisation de la fonctionnalité d’écriture accélérée. Votre tâche consiste à comprendre les différences de performances entre les deux options. Conditions préalables pour l’exercice
Si vous souhaitez effectuer les étapes de l’exercice, vérifiez que vous disposez des éléments suivants :
- Abonnement Azure avec autorisation pour créer un cluster HDInsight HBase.
- Accès à un client SSH tel que Putty (Windows)/Terminal (livre Mac)
Approvisionner un cluster HDInsight HBase avec le Portail de gestion Azure
Pour approvisionner HDInsight HBase à l’aide de la nouvelle expérience sur le Portail de gestion Azure, effectuez les étapes ci-dessous.
Accédez au portail Azure. Connectez-vous à l’aide des informations d’identification de votre compte Azure.
Nous commençons par créer un compte de stockage d’objets BLOB de blocs Premium. Dans la page Nouveau, cliquez sur Stockage.
Dans la page Créer un compte de stockage, renseignez les champs ci-dessous.
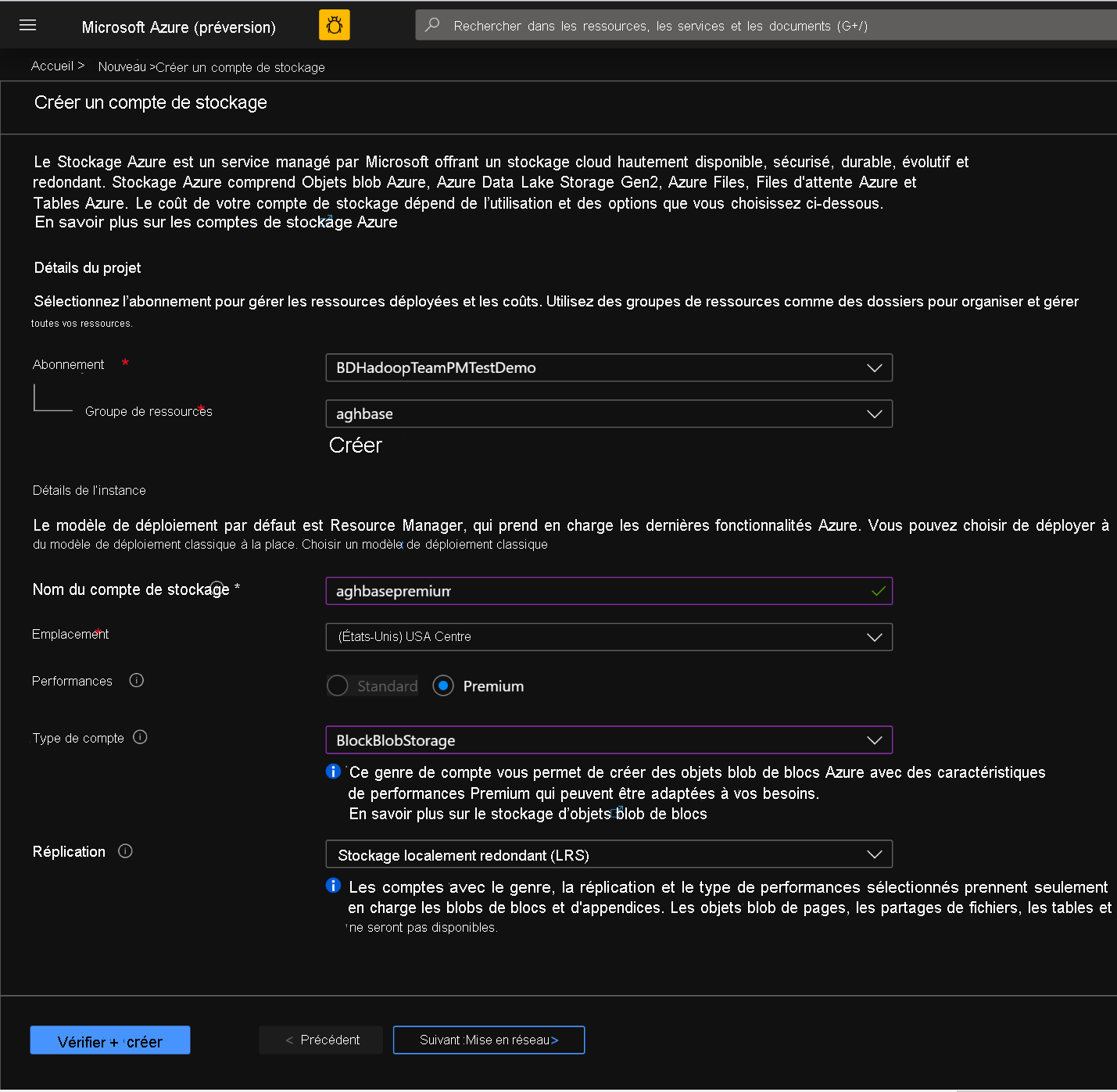
Abonnement: doit être renseigné automatiquement avec les détails de l’abonnement
Groupe de ressources: entrez un groupe de ressources pour la conservation de votre déploiement HDInsight HBase
Nom du compte de stockage: entrez un nom pour votre compte de stockage à utiliser dans le cluster Premium.
Région: entrez le nom de la région de déploiement (Assurez-vous que le cluster et le compte de stockage se trouvent dans la même région)
Performances: Premium
Genre de compte: BlockBlobStorage
Réplication : Stockage localement redondant (LRS)
Nom d'utilisateur de connexion du cluster : entrez le nom d’utilisateur de l’administrateur de cluster (par défaut : admin)
Laissez tous les autres onglets par défaut et cliquez sur Examiner+ créer pour créer le compte de stockage.
Une fois le compte de stockage créé, cliquez sur Clés d’accès à gauche et copiez key1. Nous utiliserons cette opération plus tard dans le processus de création du cluster.
Commençons à présent à déployer un cluster HDInsight HBase avec des écritures accélérées. Sélectionnez Créer une ressource -> Analytics -> HDInsight
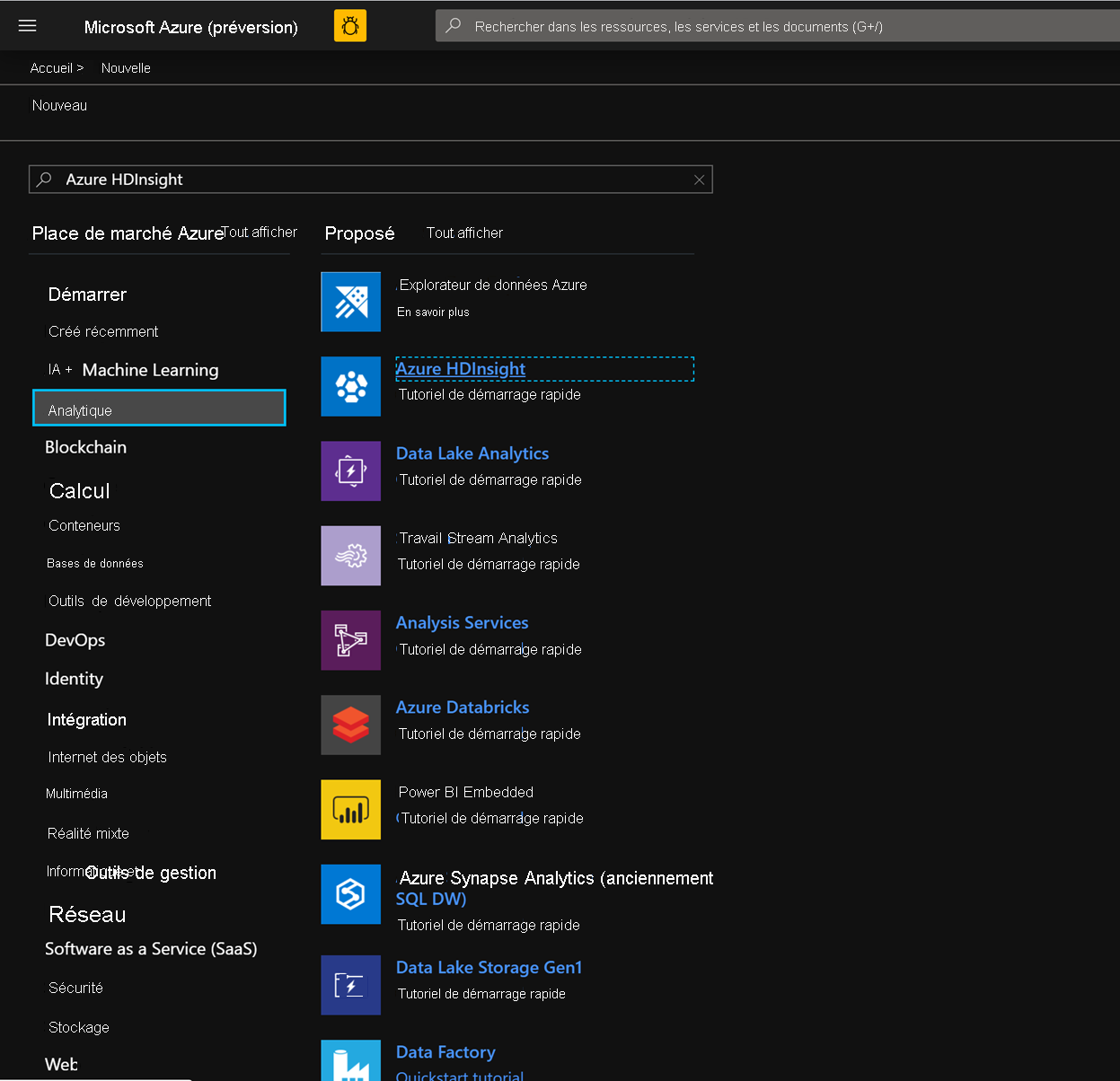
Sous l’onglet Notions de base, renseignez les champs ci-dessous en fonction de la création d’un cluster HBase.
Abonnement: doit être renseigné automatiquement avec les détails de l’abonnement
Groupe de ressources: entrez un groupe de ressources pour la conservation de votre déploiement HDInsight HBase
Nom du cluster: entrez le nom du cluster. Une coche verte s’affiche si le nom de cluster est disponible.
Région: entrez le nom de la région de déploiement
Type de cluster: type de cluster-HBase. Version- HBase 2.0.0(HDI 4.0)
Nom d'utilisateur de connexion du cluster : entrez le nom d’utilisateur de l’administrateur de cluster (par défaut : admin)
Mot de passe de connexion du cluster: entrez le mot de passe pour la connexion du cluster (par défaut : sshuser)
Confirmer le mot de passe de connexion du cluster: confirmez le mot de passe entré lors de la dernière étape
Nom d’utilisateur Secure Shell (SSH): entrez l’utilisateur de connexion SSH (par défaut : sshuser)
Utiliser le mot de passe de connexion du cluster pour SSH: cochez la case pour utiliser le même mot de passe pour les connexions SSH et les connexions Ambari
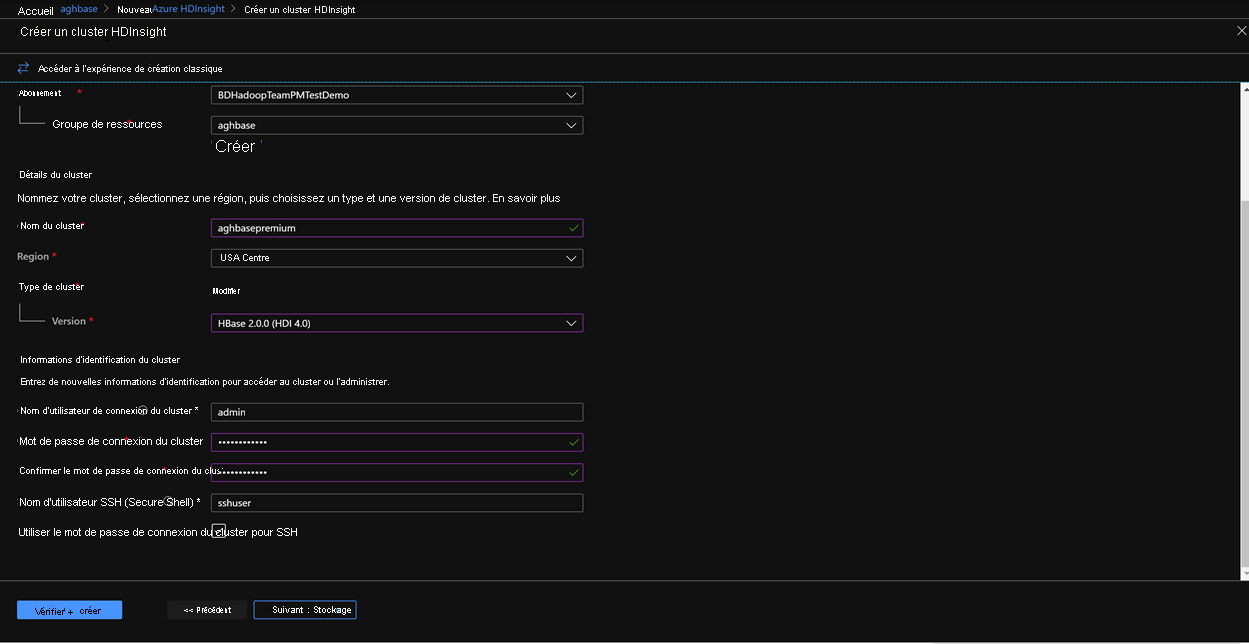
Cliquez sur Suivant : Stockage pour lancer l’onglet Stockage et renseignez les champs ci-dessous.
Type de stockage principal: stockage Azure.
Méthode de sélection: choisir une case d’option Utiliser la touche d’accès
Nom du compte de stockage: entrez le nom du compte de stockage d’objets Blob de blocs Premium créé précédemment
Clé d’accès: entrez la clé d’accès key1 que vous avez copiée précédemment
Conteneur: HDInsight doit proposer un nom de conteneur par défaut. Vous pouvez choisir cette valeur ou créer un nom de votre choix.
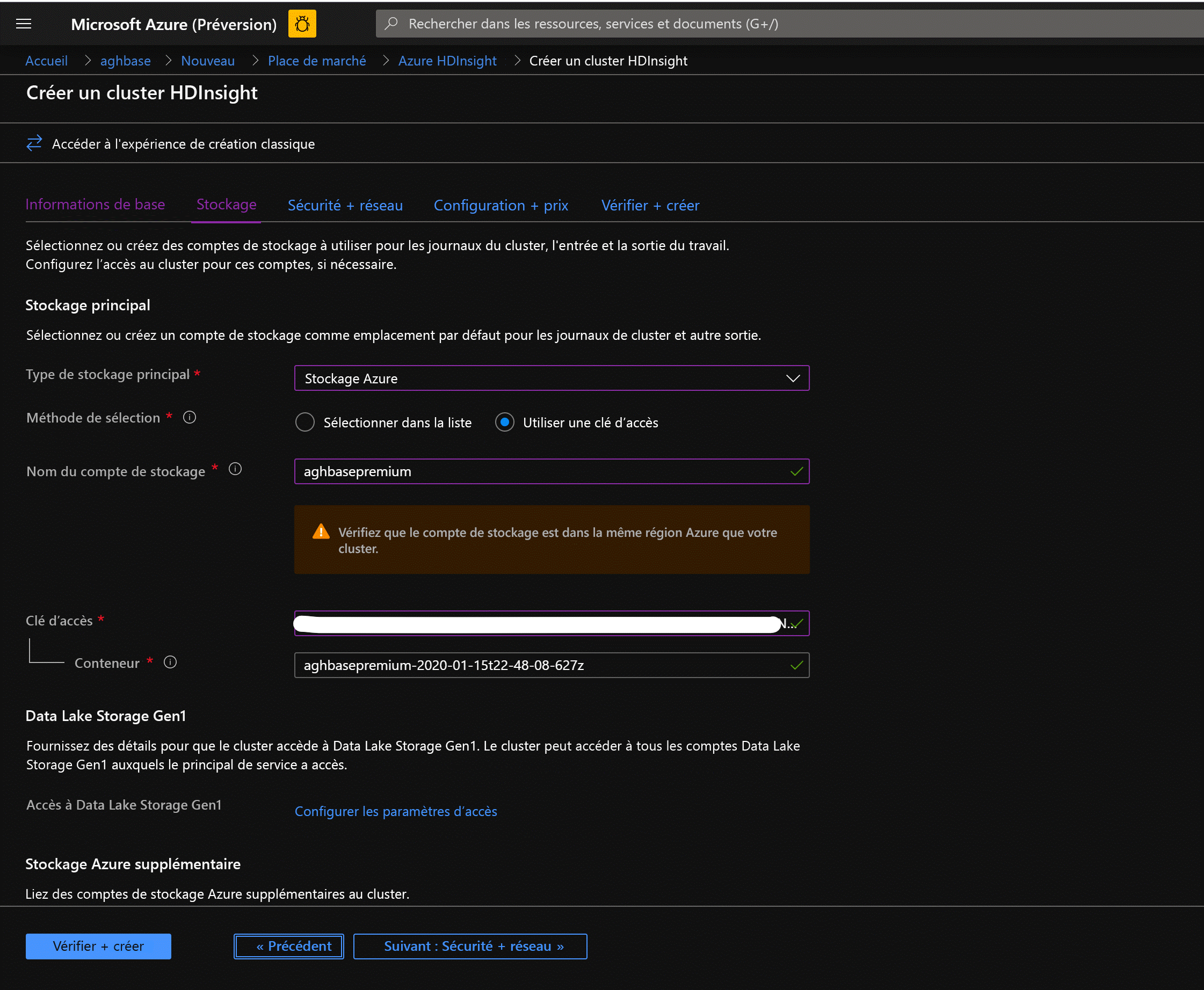
Laissez le reste des options intactes et faites défiler la liste pour activer la case à cocher Activer les écritures accélérées par HBase. (Notez que nous créerons par la suite un second cluster sans écritures accélérées à l’aide des mêmes étapes, mais avec cette case décochée.)
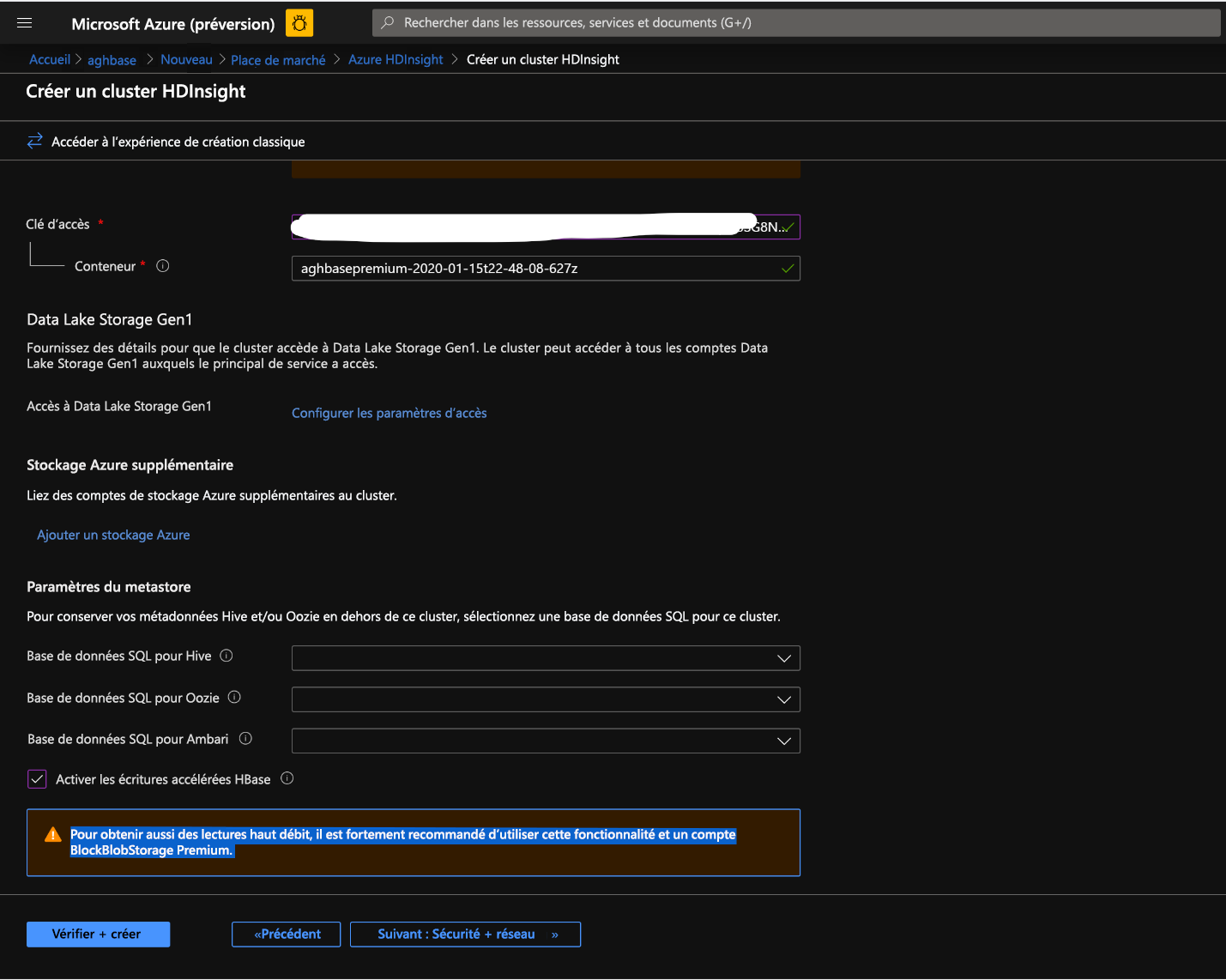
Laissez le panneau Sécurité + mise en réseau à ses paramètres par défaut sans aucune modification, puis accédez à l’onglet Configuration + tarification .
Dans l’onglet Configuration + tarification, notez que la section Configuration du nœud contient désormais un élément de ligne intitulé Disques Premium par nœud Worker.
Choisissez le nœud région à 10 et la taille du nœud à DS14v2(vous pouvez également choisir un nombre et une taille plus petits, mais assurez-vous que les deux clusters ont un nombre de nœuds identique et une référence SKU de machine virtuelle pour garantir la parité)
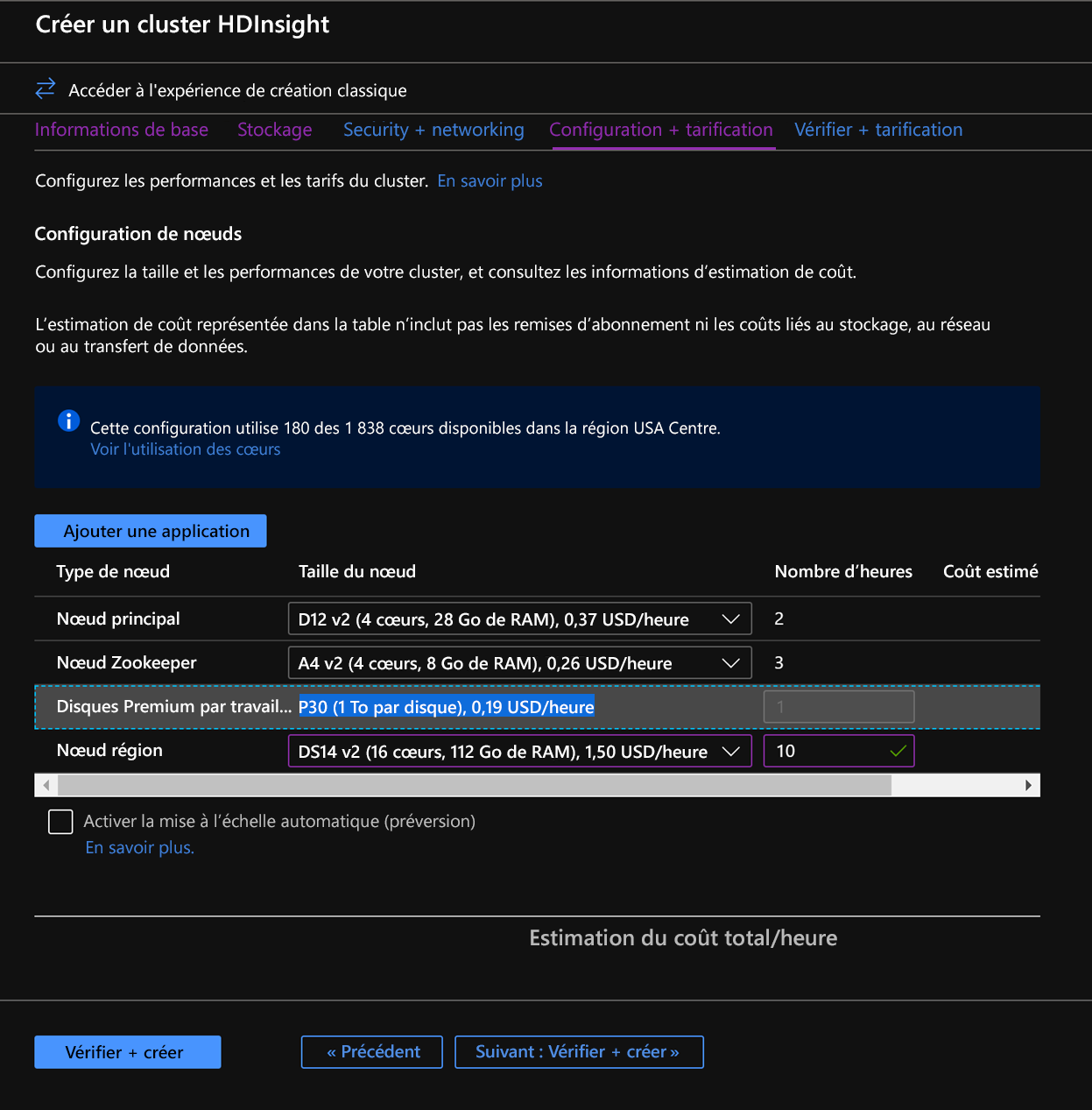
Cliquez sur Suivant : Vérifier + créer.
Dans l’onglet examiner et créer, vérifiez que l’option Écritures accélérées par HBase est activée dans la section Stockage .
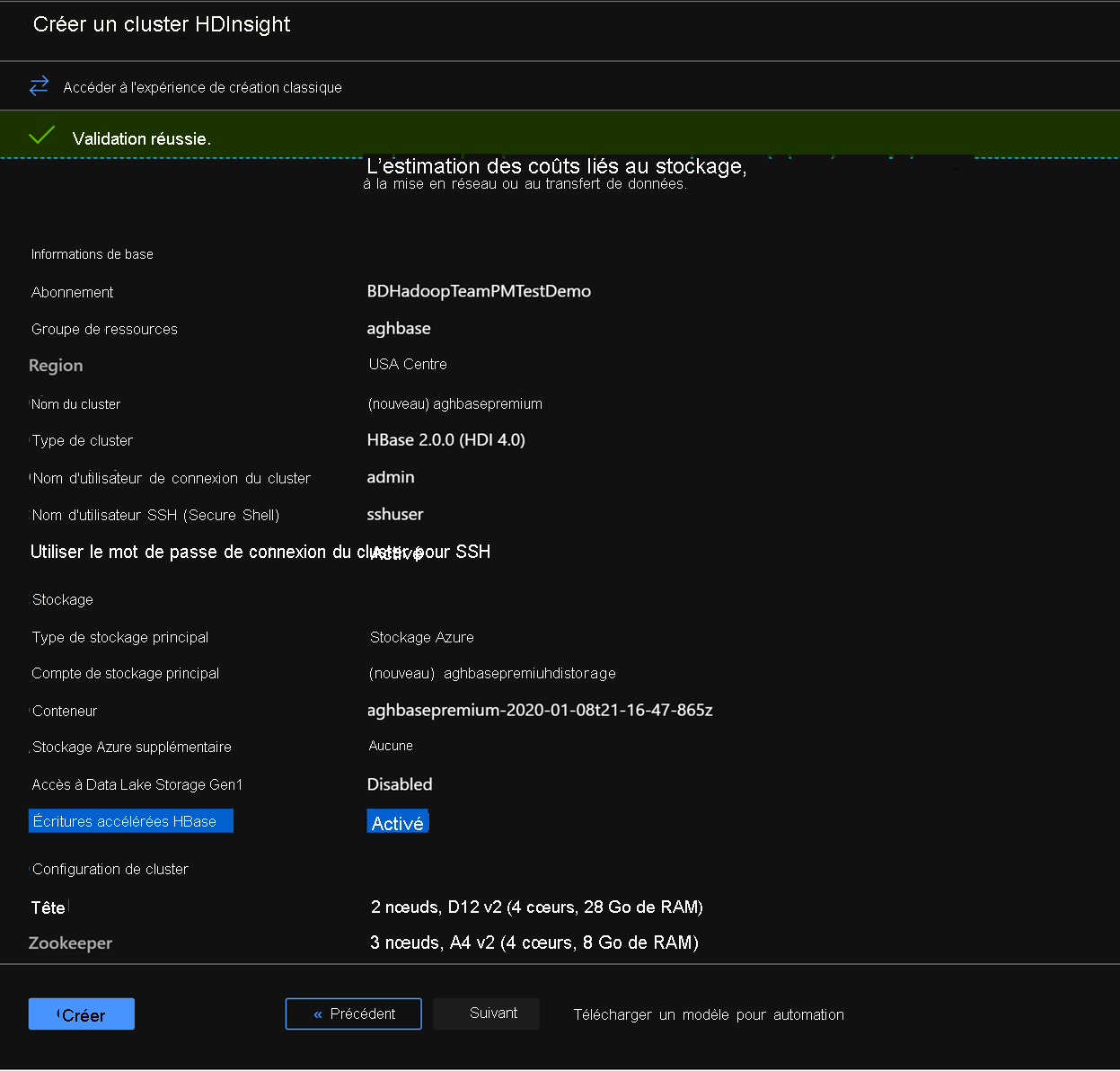
Cliquez sur Créer pour commencer le déploiement du premier cluster avec des écritures accélérées.
Répétez les mêmes étapes pour créer un deuxième cluster HDInsight HBase, cette fois sans écritures accélérées. Notez les modifications ci-dessous
Utiliser un compte de stockage d’objets blob normal recommandé par défaut
Conservez la case à cocher Activer les écritures accélérées désactivée sous l’onglet stockage.
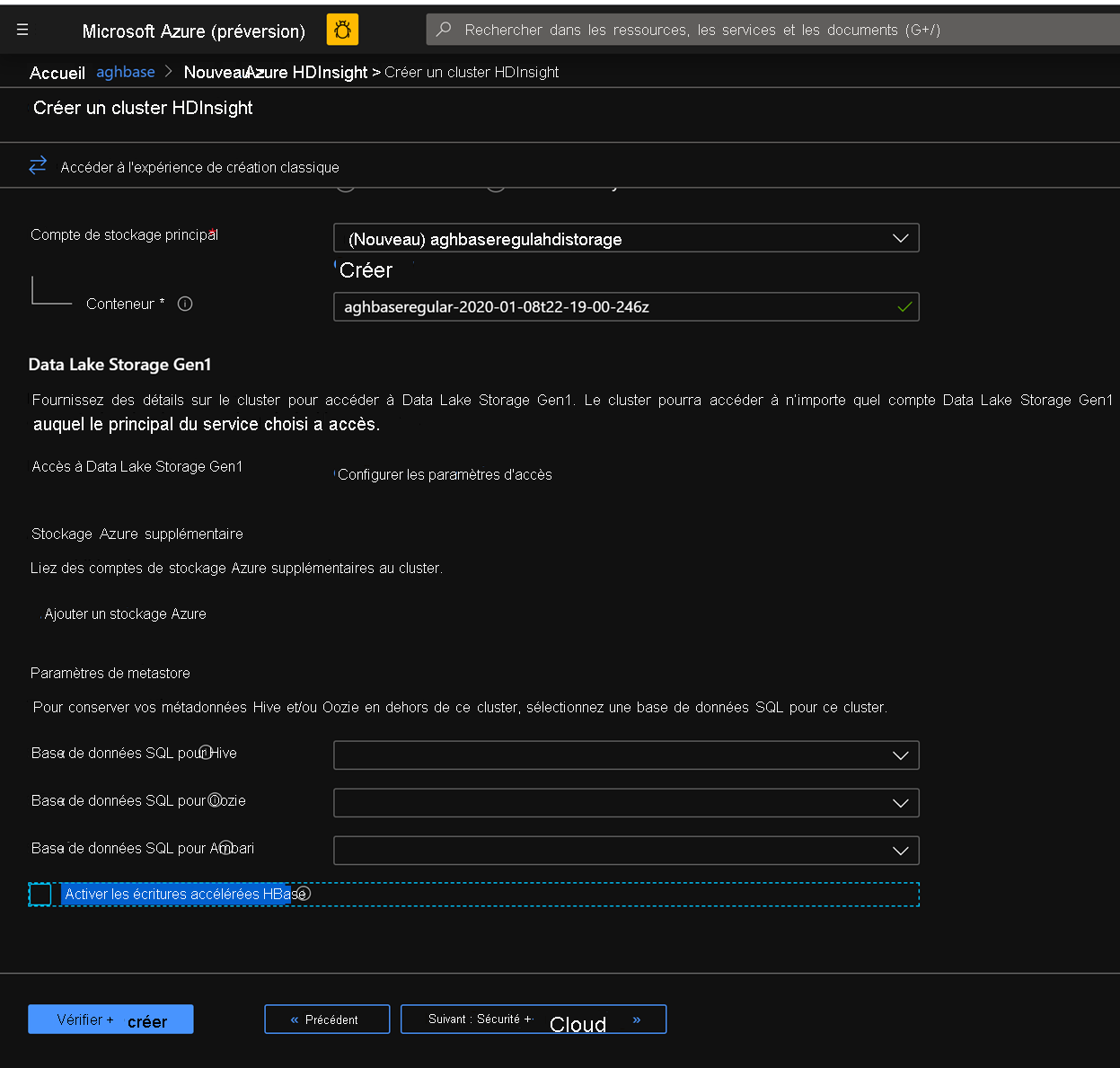
Dans l’onglet Configuration + tarificationpour ce cluster, notez que la section Configuration du nœud n’a pas de disques Premium par élément de ligne de nœud Worker.
Choisissez le nœud région à 10 et la taille du nœud à D14v2. (Notez également l’absence de types de machines virtuelles de la série DS comme précédemment). (vous pouvez également choisir un nombre et une taille plus petits, mais assurez-vous que les deux clusters ont un nombre de nœuds identique et une référence SKU de machine virtuelle pour garantir la parité)
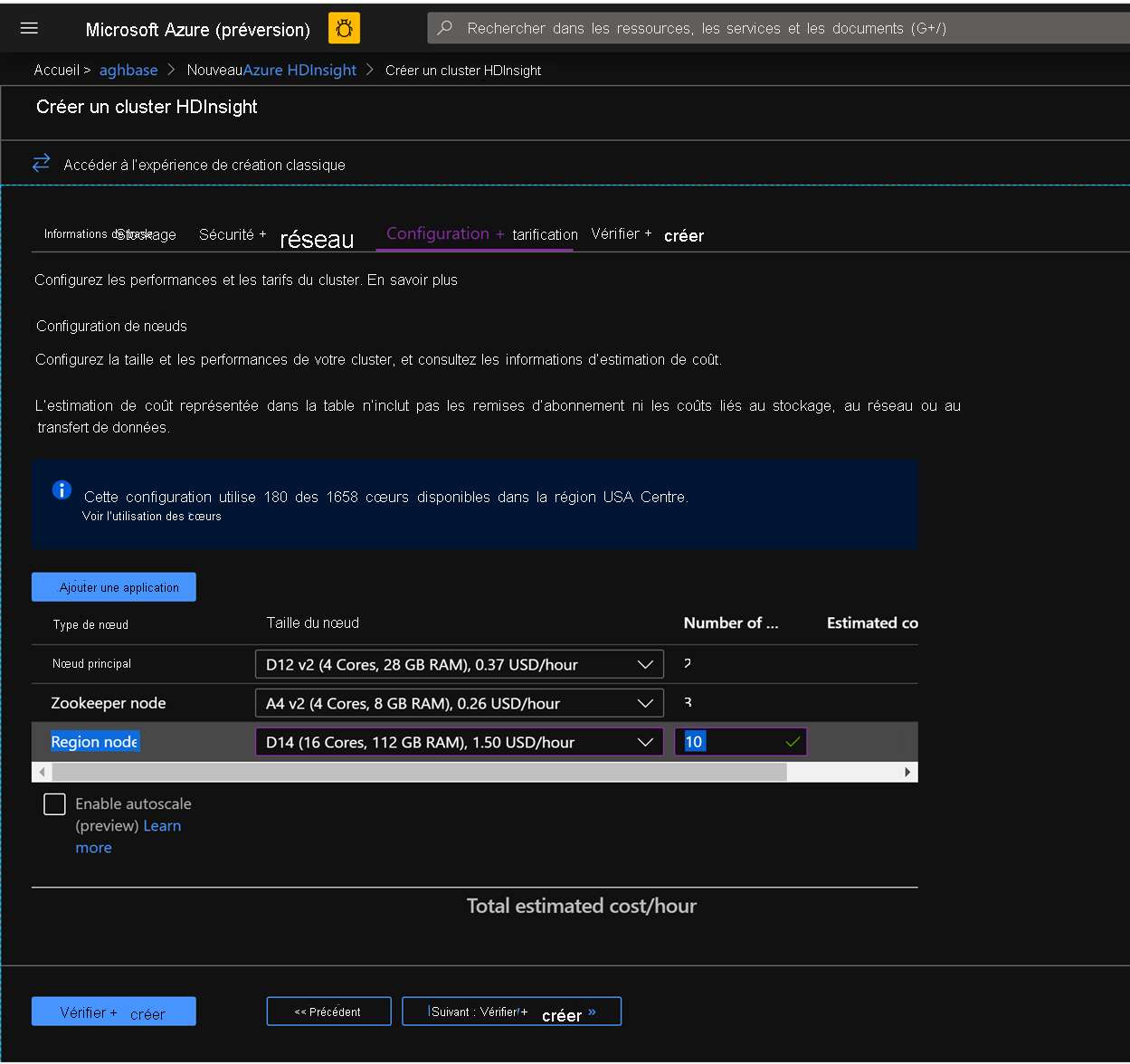
Cliquez sur Créer pour commencer le déploiement du premier cluster avec des écritures accélérées.
Maintenant que nous avons terminé avec les déploiements de cluster, dans la section suivante, nous allons configurer et exécuter des tests YCSB sur ces deux clusters.

Exécution des tests YCSB
Se connecter à HDInsight Shell
Les étapes de configuration et d’exécution des tests YCSB sur les deux clusters sont identiques.
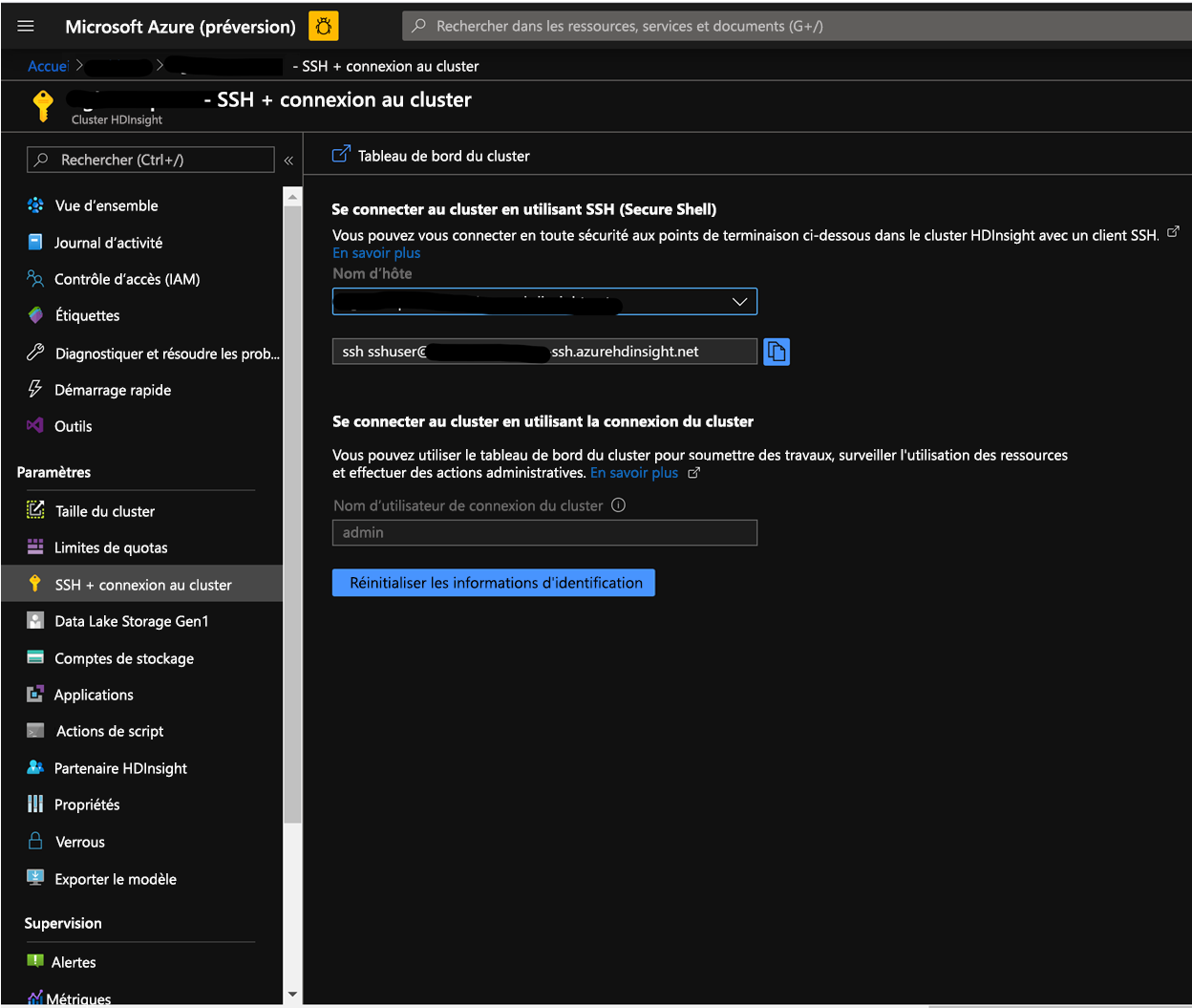
Sur la page cluster du Portail Azure, accédez à la connexion SSH + cluster et utilisez le nom d’hôte et le chemin SSH pour SSH dans le cluster. Le chemin d’accès doit avoir le format ci-dessous.
ssh <utilisateur_ssh>@<nom_cluster>.azurehdinsight.net
Créer la table
Exécutez les étapes ci-dessous pour créer les tables HBase, qui seront utilisées pour charger les jeux de données.
Lancez l’interpréteur de commandes HBase et définissez un paramètre pour le nombre de fractionnements de table. Définir les fractionnements de table (10 * nombre de serveurs de région)
Créer la table HBase, qui serait utilisée pour exécuter les tests
Ouvrir le shell HBase
hbase(main):018:0> n_splits = 100 hbase(main):019:0> create 'usertable', 'cf', {SPLITS => (1..n_splits).map {|i| "user#{1000+i*(9999-1000)/n_splits}"}} hbase(main):020:0> exit
Télécharger le référentiel YCSB
Télécharger le référentiel YCSB à partir de la destination ci-dessous
$ curl -O --location https://github.com/brianfrankcooper/YCSB/releases/download/0.17.0/ycsb-0.17.0.tar.gzDécompressez le dossier pour accéder au contenu
$ tar xfvz ycsb-0.17.0.tar.gzCela créerait un dossier ycsb-0.17.0. Déplacer dans ce dossier
Exécuter une charge de travail en écriture lourde dans les deux clusters
Utilisez la commande ci-dessous pour initier une charge de travail à forte écriture avec les paramètres ci-dessous.
workloads/workloada de travail : indique que la charge de travail/charge de travail d’ajout doit être exécutée
table: remplir le nom de votre table HBase créée précédemment
columnfamily: Renseignez la valeur du nom de columfamily HBase à partir de la table que vous avez créée
recordcount: nombre d’enregistrements à insérer (nous utilisons 1 million)
threadcount: nombre de threads (cela peut varier, mais doit rester constant d’une expérience à l’autre)
-cp /etc/hbase/conf: pointeur vers les paramètres de configuration de HBase
-s | tee-a: indiquez un nom de fichier pour écrire votre sortie.
bin/ycsb load hbase12 -P workloads/workloada -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloada.dat
Exécutez la charge de travail volumineuse en écriture pour charger 1 million lignes dans la table HBase précédemment créée.
Notes
Ignorez les avertissements qui peuvent s’afficher après l’envoi de la commande.
Exemples de résultats pour HDInsight HBase avec écritures accélérées
Exécutez la commande suivante :
```CMD $ bin/ycsb load hbase12 -P workloads/workloada -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloada.dat ```Lire les résultats :
```CMD 2020-01-10 16:21:40:213 10 sec: 15451 operations; 1545.1 current ops/sec; est completion in 10 minutes [INSERT: Count=15452, Max=120319, Min=1249, Avg=2312.21, 90=2625, 99=7915, 99.9=19551, 99.99=113855] 2020-01-10 16:21:50:213 20 sec: 34012 operations; 1856.1 current ops/sec; est completion in 9 minutes [INSERT: Count=18560, Max=305663, Min=1230, Avg=2146.57, 90=2341, 99=5975, 99.9=11151, 99.99=296703] .... 2020-01-10 16:30:10:213 520 sec: 972048 operations; 1866.7 current ops/sec; est completion in 15 seconds [INSERT: Count=18667, Max=91199, Min=1209, Avg=2140.52, 90=2469, 99=7091, 99.9=22591, 99.99=66239] 2020-01-10 16:30:20:214 530 sec: 988005 operations; 1595.7 current ops/sec; est completion in 7 second [INSERT: Count=15957, Max=38847, Min=1257, Avg=2502.91, 90=3707, 99=8303, 99.9=21711, 99.99=38015] ... ... 2020-01-11 00:22:06:192 564 sec: 1000000 operations; 1792.97 current ops/sec; [CLEANUP: Count=8, Max=80447, Min=5, Avg=10105.12, 90=268, 99=80447, 99.9=80447, 99.99=80447] [INSERT: Count=8512, Max=16639, Min=1200, Avg=2042.62, 90=2323, 99=6743, 99.9=11487, 99.99=16495] [OVERALL], RunTime(ms), 564748 [OVERALL], Throughput(ops/sec), 1770.7012685303887 [TOTAL_GCS_PS_Scavenge], Count, 871 [TOTAL_GC_TIME_PS_Scavenge], Time(ms), 3116 [TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.5517505152740692 [TOTAL_GCS_PS_MarkSweep], Count, 0 [TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 0 [TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.0 [TOTAL_GCs], Count, 871 [TOTAL_GC_TIME], Time(ms), 3116 [TOTAL_GC_TIME_%], Time(%), 0.5517505152740692 [CLEANUP], Operations, 8 [CLEANUP], AverageLatency(us), 10105.125 [CLEANUP], MinLatency(us), 5 [CLEANUP], MaxLatency(us), 80447 [CLEANUP], 95thPercentileLatency(us), 80447 [CLEANUP], 99thPercentileLatency(us), 80447 [INSERT], Operations, 1000000 [INSERT], AverageLatency(us), 2248.752362 [INSERT], MinLatency(us), 1120 [INSERT], MaxLatency(us), 498687 [INSERT], 95thPercentileLatency(us), 3623 [INSERT], 99thPercentileLatency(us), 7375 [INSERT], Return=OK, 1000000 ```Explorez le résultat du test. Voici quelques exemples d’observations issues des résultats ci-dessus :
- Le test a pris 538 663 (8,97 minutes) millisecondes pour s’exécuter
- Return=OK, 1000000 indique que toutes les entrées (1 million) ont été correctement écrites, * *
- Le débit d’écriture était de 1 856 opérations par seconde
- 95 % des insertions ont une latence de 3 389 millisecondes
- Quelques insertions ont pris plus de temps, peut-être ont-elles été bloquées par les serveurs de région en raison de la charge de travail élevée
Exemples de résultats pour HDInsight HBase avec écritures accélérées
Exécutez la commande suivante :
$ bin/ycsb load hbase12 -P workloads/workloada -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloada.datLire les résultats :
2020-01-10 23:58:20:475 2574 sec: 1000000 operations; 333.72 current ops/sec; [CLEANUP: Count=8, Max=79679, Min=4, Avg=9996.38, 90=239, 99=79679, 99.9 =79679, 99.99=79679] [INSERT: Count=1426, Max=39839, Min=6136, Avg=9289.47, 90=13071, 99=27535, 99.9=38655, 99.99=39839] [OVERALL], RunTime(ms), 2574273 [OVERALL], Throughput(ops/sec), 388.45918828344935 [TOTAL_GCS_PS_Scavenge], Count, 908 [TOTAL_GC_TIME_PS_Scavenge], Time(ms), 3208 [TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.12461770760133055 [TOTAL_GCS_PS_MarkSweep], Count, 0 [TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 0 [TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.0 [TOTAL_GCs], Count, 908 [TOTAL_GC_TIME], Time(ms), 3208 [TOTAL_GC_TIME_%], Time(%), 0.12461770760133055 [CLEANUP], Operations, 8 [CLEANUP], AverageLatency(us), 9996.375 [CLEANUP], MinLatency(us), 4 [CLEANUP], MaxLatency(us), 79679 [CLEANUP], 95thPercentileLatency(us), 79679 [CLEANUP], 99thPercentileLatency(us), 79679 [INSERT], Operations, 1000000 [INSERT], AverageLatency(us), 10285.497832 [INSERT], MinLatency(us), 5568 [INSERT], MaxLatency(us), 1307647 [INSERT], 95thPercentileLatency(us), 18751 [INSERT], 99thPercentileLatency(us), 33759 [INSERT], Return=OK, 1000000Comparer les résultats :
Paramètre Unité Avec écritures accélérées Sans écritures accélérées [OVERALL], RunTime(ms) Millisecondes 567478 2574273 [OVERALL], Throughput(ops/sec) Opérations/sec 1770 388 [INSERT], Operations Nombres d’opérations 1000000 1000000 [INSERT], 95thPercentileLatency(États-Unis) Microsecondes 3623 18751 [INSERT], 99thPercentileLatency (États-Unis) Microsecondes 7375 33759 [INSERT], Return=OK Nombre d’enregistrements 1000000 1000000 Voici quelques exemples d’observations qui peuvent être apportées aux comparaisons :
- [OVERALL], RunTime(ms) : durée totale d’exécution en millisecondes
- [OVERALL], Throughput(ops/sec) : nombre d’opérations/s. sur tous les threads
- [INSERT], Operations : nombre total d’opérations d’insertion, avec les latences moyenne, min, max, 95e et 99e centile associées ci-dessous
- [INSERT], 95thPercentileLatency (États-Unis) : 95 % des opérations INSERT ont un point de données inférieur à cette valeur
- [INSERT], 99thPercentileLatency (États-Unis) : 99 % des opérations INSERT ont un point de données inférieur à cette valeur
- [INSERT], Return = OK : Record OK indique que toutes les opérations d’insertion ont réussi avec le nombre en regard
Envisagez d’essayer une plage d’autres charges de travail pour effectuer des comparaisons. Voici quelques exemples :
Lecture principalement (95 % de lecture et 5 % d’écriture) : workloadb
bin/ycsb run hbase12 -P workloads/workloadb -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p operationcount=100000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloadb.datLecture seule (100 % de lecture et 0 % d’écriture) : workloadc
bin/ycsb run hbase12 -P workloads/workloadc -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p operationcount=100000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloadc.dat