Comment utiliser Apache Phoenix sur HDInsight HBase
Les clusters HBase sur HDInsight sont fournis avec Apache Phoenix. Apache Phoenix est une couche de base de données relationnelle massivement parallèle open source basée sur Apache HBase. Apache Phoenix vous permet d’utiliser des requêtes de type SQL sur HBase. Elle utilise des pilotes JDBC pour permettre aux utilisateurs de créer, supprimer et modifier des tables SQL. Vous pouvez également indexer, créer des vues et des séquences, et upsert des lignes individuellement et en bloc. Phoenix utilise une compilation native noSQL au lieu de MapReduce pour compiler les requêtes, ce qui permet de créer des applications à faible latence sur HBase. Phoenix ajoute des co-processeurs pour prendre en charge le code fourni par le client en cours d’exécution dans l’espace d’adressage du serveur, en exécutant le code colocalisé avec les données. Cette approche réduit le transfert de données client/serveur. Pour plus d’informations, consultez la documentation d’Apache Phoenix.
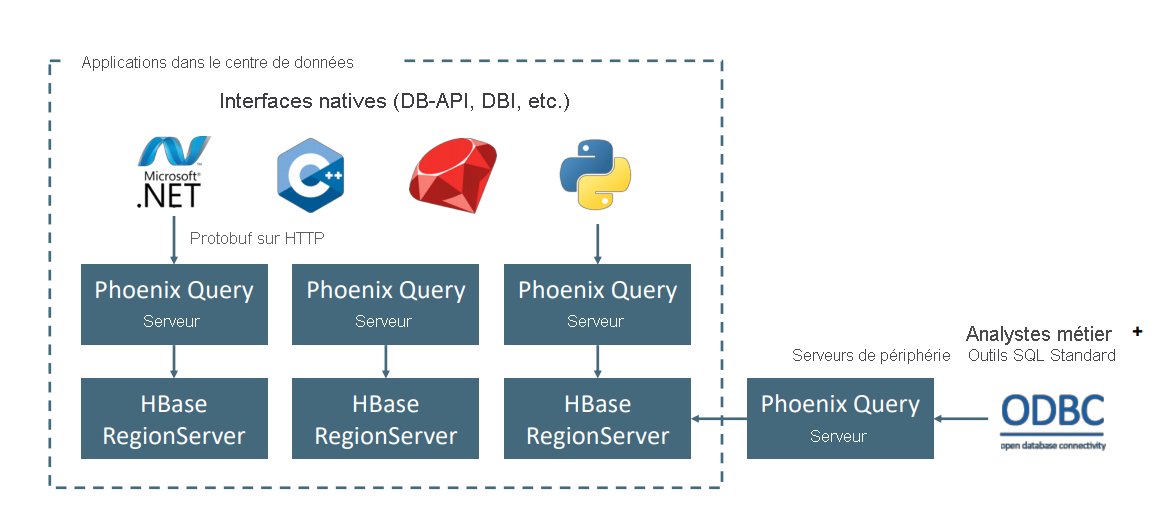
Apache Phoenix sur HDInsight HBase est généralement utilisé pour activer l’analyse libre-service et pour extraire des informations, comme illustré ci-dessous. Phoenix peut se connecter à n’importe quel outil décisionnel compatible ODBC et activer des analyses SQL ad hoc sur HBase.
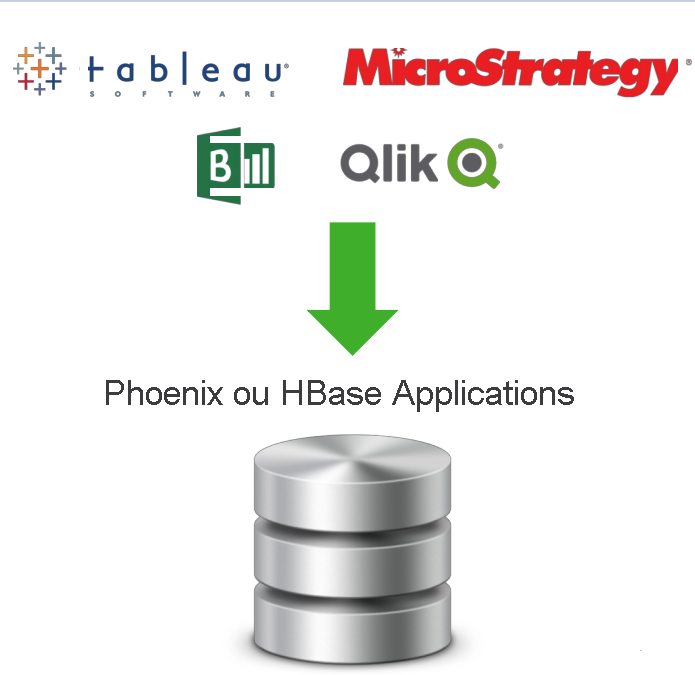
La combinaison d’Apache HBase et Phoenix peut être utilisée comme magasin de données pour les données mutables. Le moteur d’interrogation Apache Phoenix sur HBase est fourni avec certaines fonctionnalités importantes.
Index secondaires
Les enregistrements dans HBase sont accessibles à l’aide de la clé de ligne principale à l’aide d’un index unique qui est vue lexicographique trié sur la clé de ligne principale. Si vous essayez d’accéder à des enregistrements de quelque manière que ce soit à partir de la ligne principale, cela entraînerait une analyse inefficace de toutes les données de la table HBase. Apache Phoenix vous permet de créer des index secondaires sur des colonnes et des expressions afin de créer d’autres clés de ligne pour autoriser les recherches de point ou les analyses de plage sur ce nouvel index. Pour plus d’informations, consultez la documentation sur les index secondaires Apache Phoenix.
La commande CREATE INDEX permet de créer des index secondaires dans HBase comme indiqué ci-dessous.
CREATE INDEX ix_purchasetype on SALTEDWEBLOGS (purchasetype, transactiondate) INCLUDE (bookname, quantity);
Les vues
La limitation du nombre de tables physiques dans HBase et, à son tour, la limitation du nombre de régions est une stratégie recommandée. Les vues de Phoenix aident à cette recommandation en autorisant la création de plusieurs tables virtuelles partageant la même table physique sous-jacente sur HBase. Pour plus d’informations, consultez la documentation d’Apache Phoenix.
À partir de la définition de table ci-dessous dans HBase.
CREATE TABLE product_metrics (
metric_type CHAR(1),
created_by VARCHAR,
created_date DATE,
metric_id INTEGER
CONSTRAINT pk PRIMARY KEY (metric_type, created_by, created_date, metric_id));
Vous pouvez définir la vue suivante.
CREATE VIEW mobile_product_metrics (carrier VARCHAR, dropped_calls BIGINT) AS SELECT * FROM product_metric WHERE metric_type = 'm';
Transactions
Bien que HBase fonctionne uniquement avec les transactions au niveau des lignes, Apache Phoenix active des transactions inter-tables et inter-lignes avec une prise en charge complète de l’ACID en s’intégrant à Apache tephra.
Pour plus d’informations, consultez la documentation des transactions Apache Phoenix.
L’exemple suivant crée une table nommée my_table, puis modifie la table pour activer les transactions.
CREATE TABLE my_table (k BIGINT PRIMARY KEY, v VARCHAR) TRANSACTIONAL=true;
ALTER TABLE my_other_table SET TRANSACTIONAL=true;
Tables « salted »
Le serveur de région hotspotting dans HBase peut se produire pendant les écritures séquentielles si les clés de ligne augmentent de manière monotone. Apache Phoenix peut atténuer le problème du hotspotting en fournissant un moyen de saler la clé de ligne avec un octet de salage pour une table particulière. Pour plus d’informations, reportez-vous à la documentation des tables salées Apache Phoenix.
CREATE TABLE Saltedweblogs (
transactionid varchar(500) Primary Key,
transactiondate Date NULL,
customerid varchar(50) NULL,
bookid varchar(50) NULL,
purchasetype varchar(50) NULL,
orderid varchar(50) NULL,
bookname varchar(50) NULL,
categoryname varchar(50) NULL,
invoicenumber varchar(50) NULL,
invoicestatus varchar(50) NULL,
city varchar(50) NULL,
state varchar(50) NULL,
paymentamount DOUBLE NULL,
quantity INTEGER NULL,
shippingamount DOUBLE NULL) SALT_BUCKETS=4;
Analyse d’évitement
Pour un ensemble de lignes donné, Apache Phoenix utilise l’analyse de saut de ligne pour l’analyse intra-lignes sur une analyse de plage pour améliorer les performances. L’Analyse d’évitement exploite le filtre HBase SEEK_NEXT_USING_HINT. Elle stocke des informations sur l’ensemble des clés/plages de clés qui sont recherchées dans chaque colonne. Elle prend ensuite une clé (qui lui est transmise lors de l’évaluation du filtre) et s’affiche si elle se trouve dans l’une des combinaisons ou dans la plage. Si ce n’est pas le cas, elle détermine la prochaine clé la plus élevée à sauter. Pour plus d’informations, consultez la documentation d’analyse d’évitement Apache Phoenix.
L’optimisation des performances sur Apache Phoenix est une fonctionnalité demandée facultative qui dépend principalement des performances d’optimisation des HBase sous-jacentes. L’optimisation des performances est un sujet complexe qui dépasse le cadre de ce cours. Toutefois, si vous êtes intéressé, vous pouvez consulter la documentation sur les meilleures pratiques en matière de performances d’Apache Phoenix.