Décrire Apache HBase
HBase est une base de données NoSQL open source basée sur Apache Hadoop. HBase fournit un accès aléatoire et une forte cohérence pour de vastes quantités de données non structurées et semi-structurées, dans une base de données sans schéma, organisée par familles de colonnes. Les clusters HDInsight 4.0 HBase sont fournis avec Apache HBase 2.1.6 et Apache Phoenix 5.
Du point de vue de l’utilisateur, HBase est similaire à une base de données. Les données sont stockées dans les lignes et colonnes d’une table et les données au sein d’une ligne sont regroupées par familles de colonnes. HBase est une base de données sans schéma dans le sens où ni les colonnes ni le type de données qui y sont stockées ne doivent être définis avant de pouvoir les utiliser. Le code open source peut être mis à l'échelle de façon linéaire pour gérer des pétaoctets de données dans des milliers de nœuds.
HBase possède les fonctionnalités suivantes qui le rendent unique
Lecture et écritures cohérentes
Opérations à faible latence
Partitionnement automatique
Basculement automatique du serveur de région
Intégration de Hadoop/HDFS/MapReduce
API client Java
Prend en charge Thrift et REST pour les serveurs frontaux non-java
Filtres de bloc et caches de blocs
Azure HDInsight HBase avec Apache Phoenix apporte les avantages supplémentaires suivants
SQL et aucune interface SQL
Planification de la capacité flexible
Distribution et réplication globales avec la mise en réseau Azure
Séparation du calcul et du stockage
Intégration étroite avec les fonctionnalités de sécurité d’entreprise HDInsight
Écritures accélérées de HDInsight HBase pour des lectures et des écritures à très faible latence.
Apache Phoenix pour l’interrogation SQL en temps réel
L’utilisation d’Azure HDInsight avec HBase vous permet d’exécuter des bases de données NoSQL à grande échelle. En tant qu’ingénieur de données pour un Contoso, vous devez être en mesure d’exécuter des tests d’évaluation pour comprendre les performances et la mise à l’échelle de HDInsight HBase avant d’utiliser la plateforme pour des scénarios de production critiques.
HBase sur HDInsight s’exécute avec la séparation du calcul et du stockage. Les clusters HDInsight HBase sont configurés de façon à stocker les données directement dans le stockage Azure, ce qui fournit une faible latence et une élasticité accrue en matière de choix de performances et de coût. Cette propriété permet aux clients de créer des sites Web interactifs qui fonctionnent avec des jeux de données volumineux. Pour créer des services qui stockent les données de capteur et de télémétrie à partir de millions de points de terminaison, et pour analyser ces données avec des tâches Hadoop. HBase et Hadoop sont de bons points de départ pour les projets Big Data dans Azure. Les services peuvent permettre aux applications en temps réel de fonctionner avec des jeux de données volumineux. Les implémentations de HDInsight HBase utilisent une architecture de montée en puissance parallèle de HBase pour fournir un partitionnement automatique de tables. Il fournit également une cohérence forte pour les lectures et les écritures, ainsi que pour le basculement automatique. Les performances sont optimisées par la mise en cache en mémoire des lectures et par des écritures en diffusion à débit élevé. Vous pouvez créer un cluster HBase au sein du réseau virtuel. Pour en savoir plus, voir Création de clusters HBase sur Azure Virtual Network.
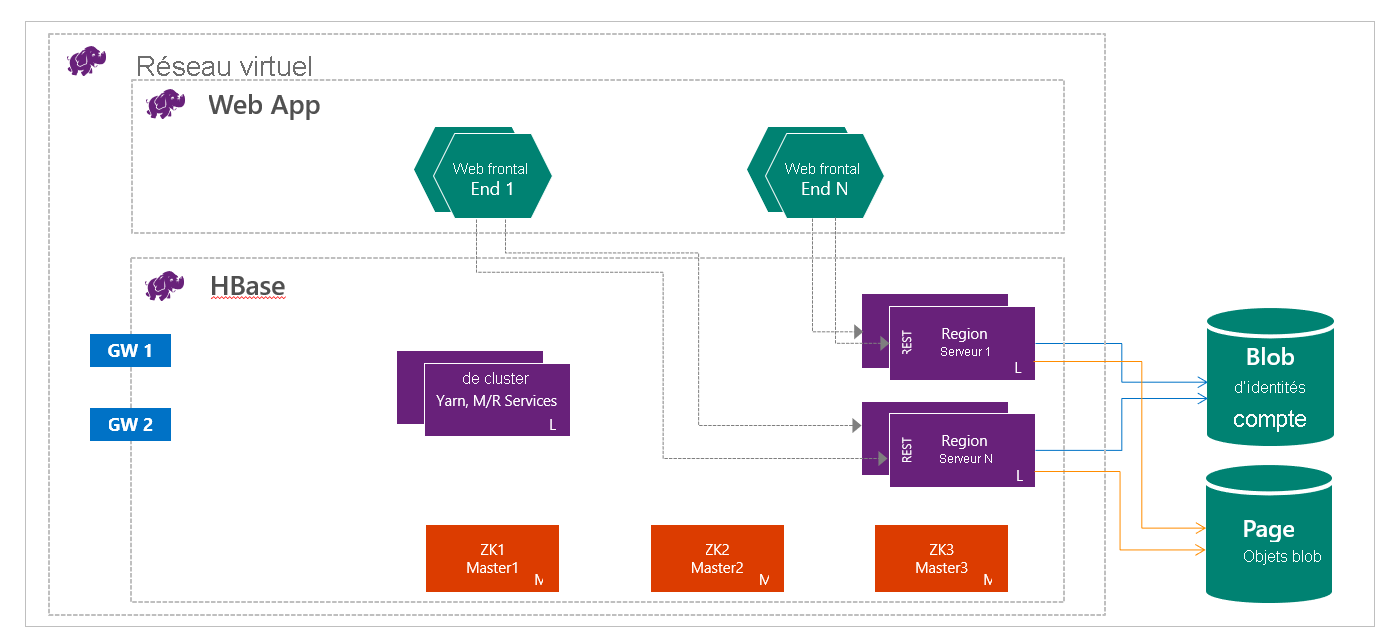
En tant qu’ingénieur de données, vous devez déterminer le type de cluster HDInsight le plus approprié à créer pour générer votre solution. Vous utilisez des clusters HBase dans HDInsight pour une base de données NoSQL qui se met à l’échelle de façon linéaire, permettant d’obtenir une grande quantité de débit, et fournit des lectures à faible latence et un stockage illimité à moindre coût.
Voici les principaux scénarios d’utilisation de HBase dans HDInsight.
stockage clé-valeur
HBase est généralement utilisé comme un magasin de clés-valeurs, et convient pour la gestion des systèmes de messagerie.
données de capteur
HBase est utile pour capturer des données collectées de façon incrémentielle à partir de différentes sources, notamment l’analytique sociale, les séries chronologiques, la mise à jour des tableaux de bord interactifs avec des tendances et des compteurs, et la gestion des systèmes de journaux d’audit.
requête en temps réel
Apache Phoenix est un moteur de requête SQL pour Apache HBase. Il est accessible en tant que pilote JDBC, et permet d’interroger et de gérer les tables HBase au moyen de SQL.
HBase en tant que plateforme
Les applications peuvent fonctionner par-dessus HBase, en l'utilisant comme banque de données. Exemples : Phoenix, OpenTSDB, Kiji et Titan. Les applications peuvent également s'intégrer à HBase. Exemples : Apache Hive, Apache Pig, Solr, Apache Flume, Apache Impala, Apache Spark, Ganglia et Apache Drill.
Dans HDInsight, HBase peut être utilisé en tant qu’application autonome ou déployé avec d’autres applications Big Data Analytics comme Spark, Hadoop, Hive ou Kafka.
Le modèle de données HBase stocke des données semi-structurées avec des types de données différents, en modifiant la taille des colonnes et la taille des champs. La disposition du modèle de données HBase facilite le partitionnement et la distribution des données dans le cluster. Le modèle de données HBase est constitué de plusieurs composants logiques : clés de ligne, famille de colonnes, nom de table, horodateur, etc.
Une clé de ligne est utilisée pour identifier de façon unique les lignes dans les tables HBase. Dans HDInsight, vous pouvez écrire les données dans HBase directement en utilisant plusieurs API disponibles, comme HBase REST, HBase RPC, Phoenix Query Server, le chargement en masse HBase, ou utiliser l’intégration de plusieurs frameworks de Big Data comme Apache Spark, Hive, etc.
Vous pouvez tirer parti de la fonctionnalité d'Écritures accélérées HBase pour activer un débit d’écriture élevé. Pour en savoir plus sur l’architecture HBase et les meilleures pratiques, consultez le livre HBase.