Démarrage Azure AI Vision
La capacité des systèmes informatiques à traiter du texte écrit et imprimé est un domaine de l’IA au croisement de la vision par ordinateur et du traitement du langage naturel. Des fonctionnalités de vision sont nécessaires pour « lire » le texte, pour qu’ensuite des fonctionnalités de traitement en langage naturel en extraient le sens.
L’OCR est la base du traitement du texte dans les images et utilise des modèles Machine Learning qui sont entraînés à reconnaître des formes spécifiques comme des lettres, des chiffres, de la ponctuation ou d’autres éléments de texte. Une grande partie des premières tâches de mise en œuvre de ce type de fonctionnalité était effectuée par les services postaux pour assurer le tri automatique du courrier en fonction des codes postaux. Depuis lors, la technologie de lecture de texte a évolué, et nous avons des modèles qui détectent du texte imprimé ou manuscrit dans une image et le lisent ligne par ligne et mot par mot.

Moteur OCR d’Azure AI Vision
Le service Azure AI Vision a la possibilité d’extraire du texte lisible par un ordinateur à partir d’images. L’API Read d’Azure AI Vision est le moteur OCR qui alimente l’extraction de texte à partir d’images, de fichiers PDF et TIFF. L’OCR pour les images est optimisée pour les images générales qui ne sont pas des documents, ce qui facilite l’incorporation de l’OCR dans vos scénarios d’expérience utilisateur.
L’API Read, également connue sous le nom de moteur OCR Read, utilise les derniers modèles de reconnaissance et est optimisée pour les images qui contiennent une quantité importante de texte ou un bruit visuel considérable. Il peut déterminer automatiquement le modèle de reconnaissance à utiliser en tenant compte du nombre de lignes de texte, des images contenant du texte et de l'écriture manuscrite.
Le moteur OCR prend un fichier image et identifie les cadres englobants, ou coordonnées, où se trouvent les éléments dans une image. Dans OCR, le modèle identifie les cadres englobants autour de tout ce qui semble être du texte dans l’image.
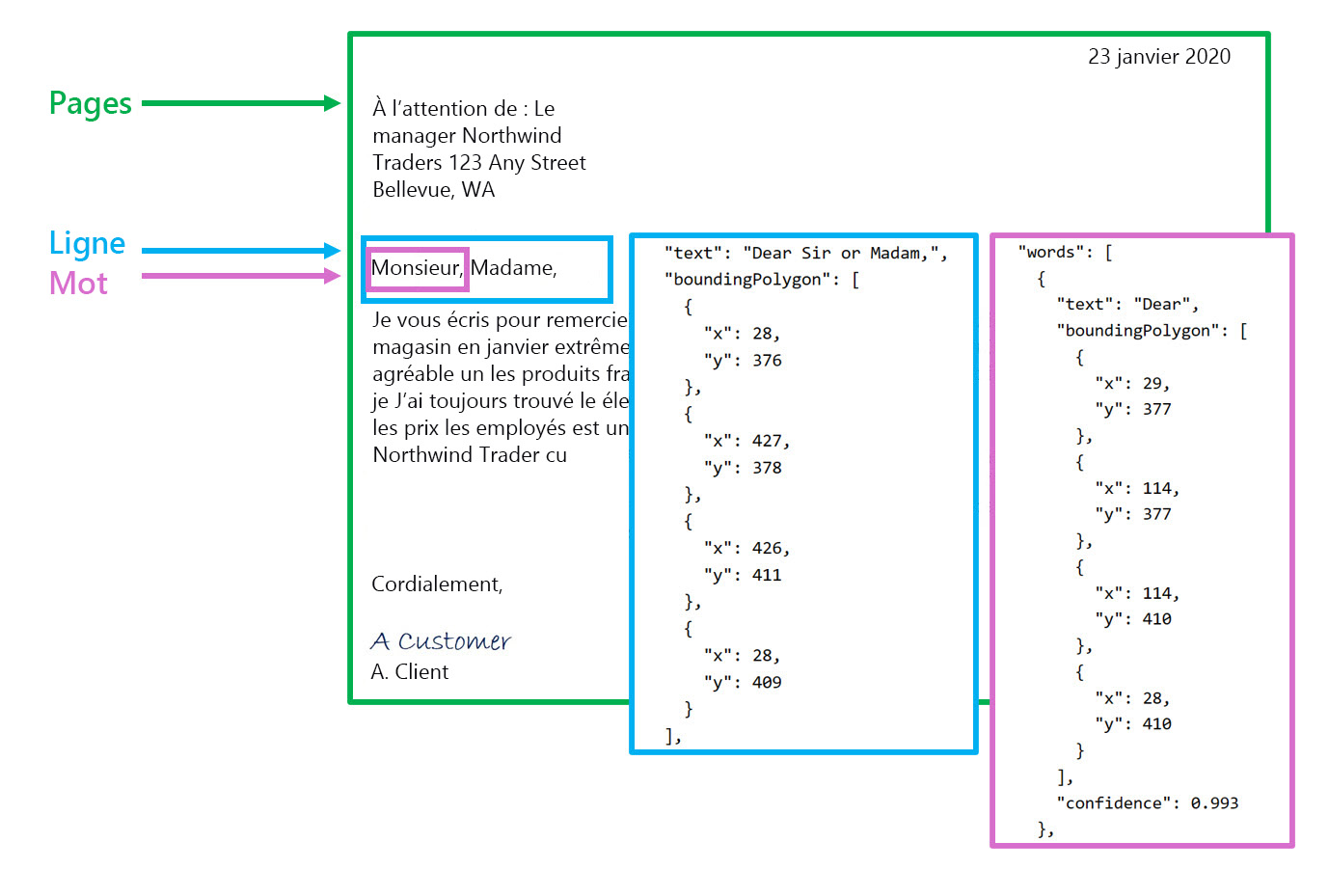
Faire un appel à l’API Read renvoie des résultats, classés selon la hiérarchie suivante :
- Pages - Une pour chaque page de texte, notamment des informations sur le format et l’orientation de la page
- Lignes - Les lignes de texte sur une page
- Mots : mots d’une ligne de texte, y compris les coordonnées du cadre englobant et le texte lui-même.
Chaque ligne et chaque mot comprennent les coordonnées du cadre englobant, indiquant sa position sur la page.