Exercice - Nettoyer et préparer les données
Avant de préparer un jeu de données, vous devez comprendre son contenu et sa structure. Dans le labo précédent, vous avez importé un jeu de données contenant des informations sur les arrivées à l’heure d’une importante compagnie américaine. Ces données incluent 26 colonnes et des milliers de lignes, avec chaque ligne représentant un vol et contenant des informations comme l’origine, la destination et l’heure de départ planifiée du vol. Vous avez également chargé les données dans un notebook Jupyter et vous avez utilisé un script Python simple pour créer un DataFrame Pandas à partir de celui-ci.
Un DataFrame est une structure de données étiquetées à deux dimensions. Les colonnes d’un DataFrame peuvent être de différents types, tout comme les colonnes d’une feuille de calcul ou d’une table de base de données. C’est l’objet le plus couramment utilisé dans Pandas. Dans cet exercice, vous allez examiner de plus près le DataFrame et les données qu’il contient.
Revenez au notebook Azure que vous avez créé dans la section précédente. Si vous avez fermé le notebook, vous pouvez vous reconnecter au portail Microsoft Azure Notebooks, ouvrir votre notebook et utiliser Cellule –>Exécuter tout pour réexécuter toutes les cellules du notebook après son ouverture.
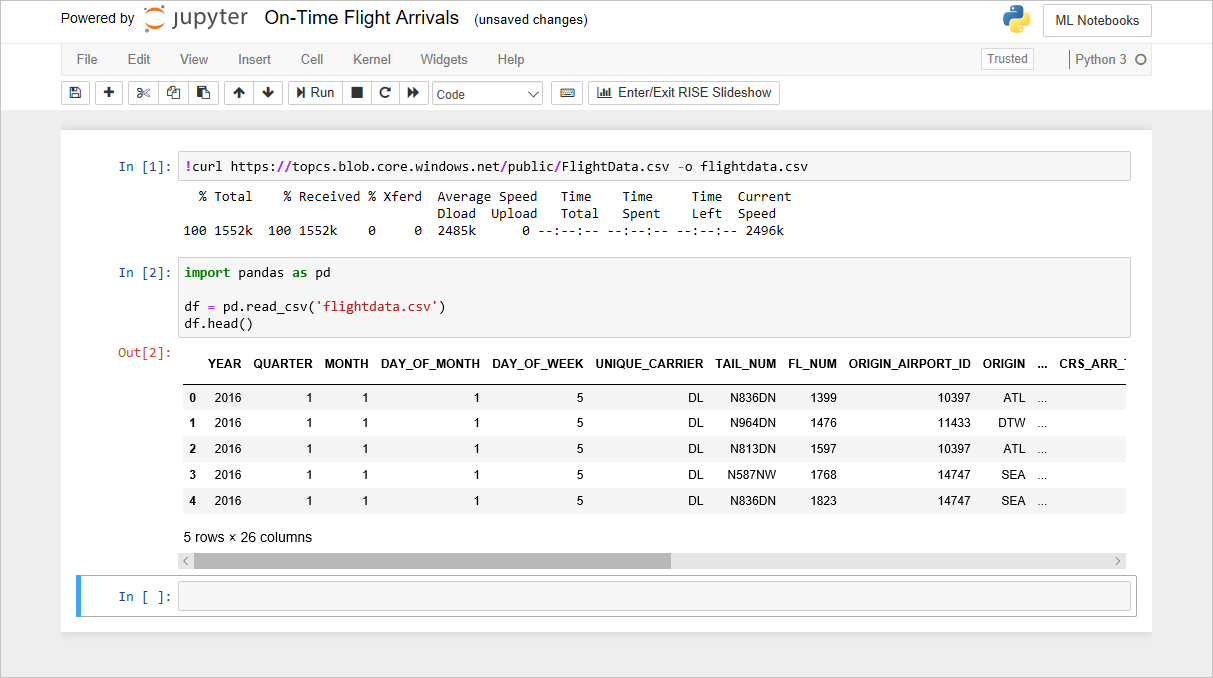
Le notebook FlightData
Le code que vous avez ajouté au notebook dans le labo précédent crée un DataFrame à partir de flightdata.csv et appelle DataFrame.head sur celui-ci pour afficher les cinq premières lignes. En général, une des premières choses que vous voulez savoir sur un jeu de données est le nombre de lignes qu’il contient. Pour obtenir un comptage, tapez l’instruction suivante dans une cellule vide à la fin du notebook et exécutez-la :
df.shapeVérifiez que le DataFrame contient 11 231 lignes et 26 colonnes :

Obtention du nombre de lignes et de colonnes
Prenez maintenant un moment pour examiner les 26 colonnes du jeu de données. Elles contiennent des informations importantes, comme la date où le vol a eu lieu (YEAR, MONTH et DAY_OF_MONTH), l’origine et de destination (ORIGIN et DEST), les heures de départ et d’arrivée planifiées (CRS_DEP_TIME et CRS_ARR_TIME), la différence en minutes entre l’heure d’arrivée planifiée et l’heure d’arrivée réelle (ARR_DELAY), et si le vol a eu un retard de 15 minutes ou plus (ARR_DEL15).
Voici une liste complète des colonnes du jeu de données. Les heures sont exprimées en heure au format militaire sur 24 heures. Par exemple, 1130 correspond à 11 h 30 et 1500 correspond à 15 h 00.
Colonne Description YEAR Année où le vol a eu lieu QUARTER Trimestre où le vol a eu lieu (1-4) MONTH Mois où le vol a eu lieu (1-12) DAY_OF_MONTH Jour du mois où le vol a eu lieu (1-31) DAY_OF_WEEK Jour de la semaine où le vol a eu lieu (1=Lundi, 2=Mardi, etc.) UNIQUE_CARRIER Code de la compagnie aérienne (par exemple DL) TAIL_NUM Numéro d’immatriculation de l’avion FL_NUM Numéro de vol ORIGIN_AIRPORT_ID ID de l’aéroport d’origine ORIGIN Code de l’aéroport origine (ATL, DFW, SEA, etc.) DEST_AIRPORT_ID ID de l’aéroport de destination DEST Code de l’aéroport de destination (ATL, DFW, SEA, etc.) CRS_DEP_TIME Heure de départ planifiée DEP_TIME Heure de départ réelle DEP_DELAY Nombre de minutes de retard du départ DEP_DEL15 0=Départ retardé de moins de 15 minutes, 1=Départ retardé de 15 minutes ou plus CRS_ARR_TIME Heure d’arrivée prévue ARR_TIME Heure d’arrivée réelle ARR_DELAY Nombre de minutes de retard à l’arrivée ARR_DEL15 0=Arrivé avec moins de 15 minutes de retard, 1=Arrivé avec 15 minutes de retard ou plus CANCELLED 0=Le vol n’a pas été annulé, 1=Le vol a été annulé DIVERTED 0=Le vol n’a pas été dérouté, 1=Le vol a été dérouté CRS_ELAPSED_TIME Temps de vol planifié en minutes ACTUAL_ELAPSED_TIME Temps de vol réel en minutes DISTANCE Distance parcourue en miles
Le jeu de données inclut une distribution à peu près uniforme de dates tout au long de l’année, ce qui est important, car un vol partant de Minneapolis est moins susceptible d’être retardé en raison de tempêtes d’hiver en juillet qu’en janvier. Ce jeu de données est cependant loin d’être « propre » et prêt à être utilisé. Écrivons du code Pandas pour le nettoyer.
Un des aspects plus importants de la préparation d’un jeu de données pour une utilisation dans le machine learning est de sélectionner les colonnes de « caractéristiques » qui sont pertinentes pour le résultat que vous essayez de prédire, en excluant les colonnes qui n’affectent pas le résultat, qui pourraient le biaiser de manière négative ou qui pourraient produire de la multicolinéarité. Une autre tâche importante est d’éliminer les valeurs manquantes, en supprimant les lignes ou les colonnes qui les contiennent, ou en les remplaçant par des valeurs significatives. Dans cet exercice, vous éliminez les colonnes superflues et vous remplacez les valeurs manquantes dans les colonnes restantes.
Une des premières choses que les scientifiques des données regardent généralement dans un jeu de données est les valeurs manquantes. Il existe un moyen simple de rechercher les valeurs manquantes dans Pandas. Pour le voir, exécutez le code suivant dans une cellule à la fin du notebook :
df.isnull().values.any()Vérifiez que la sortie est « True », ce qui indique qu’il y a au moins une valeur manquante quelque part dans le jeu de données.

Recherche de valeurs manquantes
L’étape suivante consiste à trouver où sont les valeurs manquantes. Pour cela, exécutez le code suivant :
df.isnull().sum()Vérifiez que vous voyez la sortie suivante indiquant le nombre de valeurs manquantes dans chaque colonne :
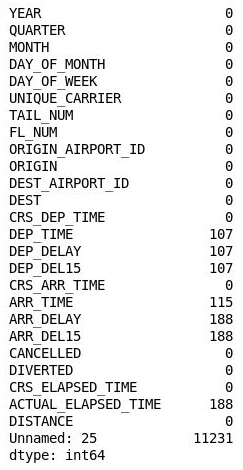
Nombre de valeurs manquantes dans chaque colonne
Curieusement, la 26ème colonne (« Unnamed : 25 ») contient 11 231 valeurs manquantes, ce qui est égal au nombre de lignes du jeu de données. Cette colonne a été créée par erreur, car le fichier CSV que vous avez importé contenait une virgule à la fin de chaque ligne. Pour éliminer cette colonne, ajoutez le code suivant dans le notebook et exécutez-le :
df = df.drop('Unnamed: 25', axis=1) df.isnull().sum()Inspecter la sortie et vérifiez que cette colonne 26 a disparu du DataFrame :
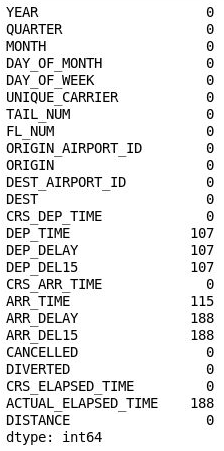
Le DataFrame avec la colonne 26 supprimée
Le DataFrame contient toujours un grand nombre de valeurs manquantes, mais certaines d’entre elles ne sont pas utiles, car les colonnes qui les contiennent ne sont pas pertinentes pour le modèle que vous créez. L’objectif de ce modèle est de prédire si un vol que vous envisagez de réserver est susceptible d’arriver à l’heure. Si vous savez que le vol est susceptible d’être en retard, vous pouvez choisir de réserver un autre vol.
L’étape suivante consiste donc à filtrer le jeu de données pour éliminer les colonnes qui ne sont pas pertinentes pour un modèle prédictif. Par exemple, le numéro d’immatriculation de l’avion a probablement peu d’impact sur l’arrivée à l’heure d’un vol et, au moment où vous réservez un billet, vous n’avez aucun moyen de savoir si un vol sera annulé, dérouté ou retardé. En revanche, l’heure de départ planifiée peut avoir beaucoup d’impact sur les arrivées à l’heure. En raison du système en étoile utilisé par la plupart des compagnies aériennes, les vols du matin ont tendance à être plus souvent à l’heure que les vols de l’après-midi ou du soir. En outre, dans certains grands aéroports, le trafic s’accumule pendant la journée, augmentant la probabilité que des vols ultérieurs soient retardés.
Pandas fournit un moyen simple d’exclure les colonnes dont vous ne voulez pas. Exécutez le code suivant dans une nouvelle cellule à la fin du notebook :
df = df[["MONTH", "DAY_OF_MONTH", "DAY_OF_WEEK", "ORIGIN", "DEST", "CRS_DEP_TIME", "ARR_DEL15"]] df.isnull().sum()La sortie montre que le DataFrame inclut désormais seulement les colonnes pertinentes pour le modèle, et que le nombre de valeurs manquantes est considérablement réduit :
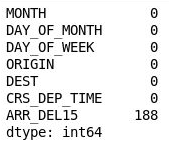
Le DataFrame filtré
La seule colonne qui contient maintenant des valeurs manquantes est la colonne ARR_DEL15, qui utilise 0 pour identifier les vols arrivés à l’heure et 1 pour les vols arrivés en retard. Utilisez le code suivant pour afficher les cinq premières lignes avec des valeurs manquantes :
df[df.isnull().values.any(axis=1)].head()Pandas représente les valeurs manquantes par
NaN, qui est l’acronyme de Not a Number (Pas un nombre). La sortie montre que des valeurs sont en effet manquantes dans la colonne ARR_DEL15 :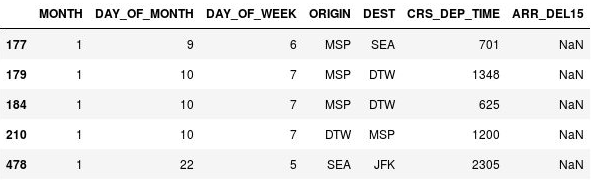
Lignes avec des valeurs manquantes
La raison pour laquelle des valeurs sont manquantes dans ARR_DEL15 pour ces lignes est que celles-ci correspondent toutes à des vols qui ont été annulés ou déroutés. Vous pouvez appeler dropna sur le DataFrame pour supprimer ces lignes. Mais dans la mesure où un vol annulé ou dérouté vers un autre aéroport peut être considéré comme étant « en retard », utilisons la méthode fillna pour remplacer les valeurs manquantes par des 1.
Utilisez le code suivant pour remplacer les valeurs manquantes de la colonne ARR_DEL15 par des 1 et pour afficher les lignes 177 à 184 :
df = df.fillna({'ARR_DEL15': 1}) df.iloc[177:185]Vérifiez que les
NaNdans les lignes 177, 179 et 184 ont bien été remplacés par des 1 indiquant que les vols sont arrivés en retard :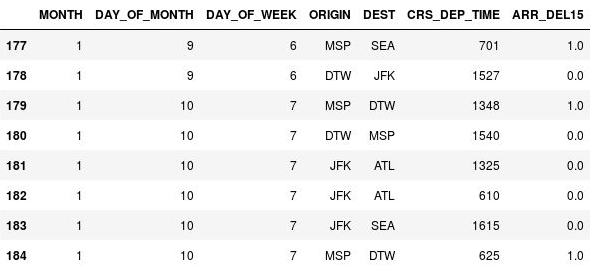
NaN remplacés par des 1
Le jeu de données est maintenant « propre », dans le sens où les valeurs manquantes ont été remplacées et où la liste des colonnes a été réduite à celles qui sont les plus pertinentes pour le modèle. Vous n’en avez cependant pas encore terminé. Il reste du travail afin de préparer le jeu de données à être utilisé pour du machine learning.
La colonne CRS_DEP_TIME du jeu de données que vous utilisez représente les heures de départ planifiées. La granularité des nombres dans cette colonne peut avoir un impact négatif sur la précision dans un modèle Machine Learning : elle contient en effet plus de 500 valeurs uniques. Ceci peut être résolu à l’aide d’une technique appelée compartimentage ou quantification. Que se passe-t-il si vous divisez chaque nombre figurant dans cette colonne par 100, en arrondissant le résultat à l’entier le plus proche ? 1030 deviendrait 10, 1925 deviendrait 19 et ainsi de suite, et vous auriez alors un maximum de 24 valeurs discrètes dans cette colonne. Intuitivement, ceci a du sens, car cela importe probablement peu qu’un vol parte à 10 h 30 ou à 10 h 40. Cela importe par contre beaucoup s’il part à 10 h 30 ou à 17 h 30.
En outre, les ORIGIN et DEST du jeu de données contiennent des codes d’aéroport qui représentent des valeurs de catégorie pour le machine learning. Ces colonnes doivent être converties en colonnes discrètes contenant des variables d’indicateur, parfois appelées variables « factices ». En d’autres termes, la colonne ORIGIN, qui contient cinq codes d’aéroport, doit être convertie en cinq colonnes, une par aéroport, chaque colonne contenant des 1 et des 0 qui indiquent si un vol provenait de l’aéroport que la colonne représente. La colonne DEST doit être gérée d’une façon similaire.
Dans cet exercice, vous allez « compartimenter » la colonne CRS_DEP_TIME et utiliser la méthode get_dummies de Pandas pour créer des colonnes d’indicateurs à partir des colonnes ORIGIN et DEST.
Utilisez la commande suivante pour afficher les cinq premières lignes du DataFrame :
df.head()Notez que la colonne CRS_DEP_TIME contient des valeurs comprises entre 0 et 2359 représentant des heures au format militaire.
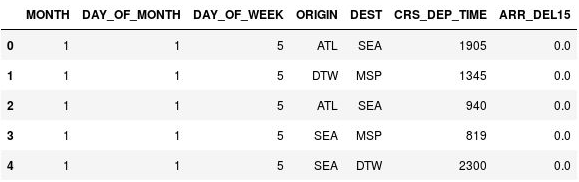
Le DataFrame avec des heures de départ non compartimentées
Utilisez les instructions suivantes pour compartimenter les heures de départ :
import math for index, row in df.iterrows(): df.loc[index, 'CRS_DEP_TIME'] = math.floor(row['CRS_DEP_TIME'] / 100) df.head()Vérifiez que les nombres dans la colonne CRS_DEP_TIME sont maintenant dans une plage de 0 à 23 :
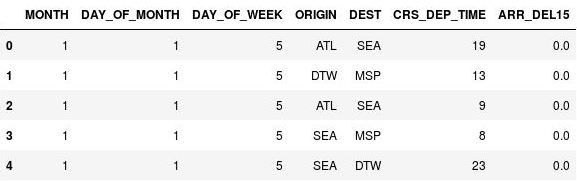
Le DataFrame avec des heures de départ compartimentées
Utilisez maintenant les instructions suivantes pour générer des colonnes d’indicateurs à partir des colonnes ORIGIN et DEST, tout en supprimant ces deux colonnes elles-mêmes :
df = pd.get_dummies(df, columns=['ORIGIN', 'DEST']) df.head()Examinez le DataFrame résultant et notez que les colonnes ORIGIN et DEST ont été remplacées par des colonnes correspondant aux codes d’aéroport présents dans les colonnes d’origine. Les nouvelles colonnes ont des 1 et des 0, qui indiquent si un vol donné provenait ou était à destination de l’aéroport correspondant.
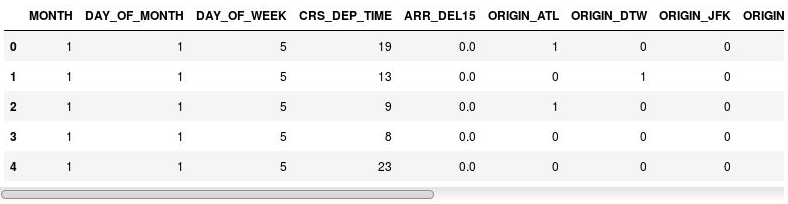
Le DataFrame avec des colonnes d’indicateurs
Utilisez la commande File ->Save and Checkpoint pour enregistrer le notebook.
Le jeu de données est très différent de ce qu’il était au début, mais il est maintenant optimisé pour le Machine Learning.