Intégrer des requêtes Apache Spark et Hive LLAP
Dans la leçon précédente, nous avons vu deux façons d’interroger des données statiques stockées dans un cluster Interactive Query : avec Data Analytics Studio et avec un bloc-notes Zeppelin. Mais que se passe-t-il si vous souhaitez diffuser des données immobilières actualisées dans vos clusters à l’aide de Spark, pour pouvoir ensuite les interroger à l’aide de Hive ? Comme Hive et Spark ont deux metastores différents, ils ont besoin d’un connecteur pour établir un pont entre les deux ; ce pont est assuré par Apache Hive Warehouse Connector (HWC). La bibliothèque Hive Warehouse Connector vous permet de travailler plus facilement avec Apache Spark et Apache Hive en prenant en charge des tâches telles que le déplacement de données entre des DataFrames Spark et des tables Hive, et en dirigeant également les données de diffusion en continu Spark dans des tables Hive. Nous n’allons pas configurer le connecteur dans ce scénario, mais il est important de savoir que vous avez cette possibilité.
Apache Spark dispose d’une API de diffusion en continu structurée qui fournit des fonctionnalités de diffusion en continu non disponibles dans Apache Hive. À partir de HDInsight 4.0, Apache Spark 2.3.1 et Apache Hive 3.1.0 proposent des metastores distincts, ce qui peut nuire à l'interopérabilité. Le connecteur d'entrepôt Hive facilite l'utilisation simultanée de Spark et de Hive. La bibliothèque Hive Warehouse Connector charge des données à partir de démons LLAP dans des exécuteurs Spark en parallèle, ce qui offre une alternative plus efficace et plus évolutive que l’utilisation d’une connexion JDBC standard de Spark à Hive.
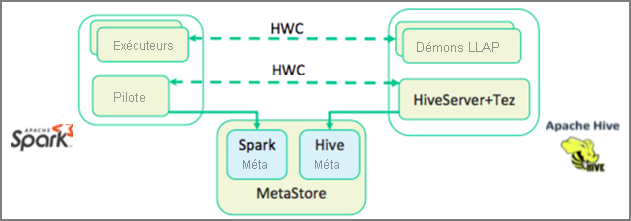
Voici quelques-unes des opérations prises en charge par le connecteur d'entrepôt Hive :
- Description d’une table
- Création d’une table pour des données au format ORC (Optimized Row Columnar)
- Sélection de données Hive et récupération d'un DataFrame
- Écriture par lots d'un DataFrame vers Hive
- Exécution d'une instruction de mise à jour Hive
- Lecture des données d’une table à partir de Hive, transformation de ces données dans Spark, puis leur écriture dans une nouvelle table Hive
- Écriture d'un flux DataFrame ou Spark vers Hive à l'aide de HiveStreaming
Une fois que vous avez déployé un cluster Spark et un cluster Interactive Query, vous pouvez configurer les paramètres du cluster Spark dans Ambari, un outil Web inclus dans tous les clusters HDInsight. Pour ouvrir Ambari, accédez à https://servername.azurehdinsight.net dans votre navigateur Internet où servername est le nom de votre cluster Interactive Query.
Ensuite, pour écrire des données de diffusion en continu Spark dans les tables, vous devez créer une table Hive et commencer à y écrire des données. Exécutez ensuite des requêtes sur vos données de diffusion en continu. Vous pouvez utiliser n’importe quel langage parmi les suivants :
- spark-shell
- PySpark
- spark-submit
- Zeppelin
- Livy